
基于近红外光谱技术的天麻产地鉴别方法*
2021-06-24 13:49白庆旭候英杨盼盼李伟林昕苏霁玲徐娟刘祥义
西部林业科学 2021年3期
白庆旭,候英,杨盼盼,李伟,林昕,苏霁玲,徐娟,刘祥义
(1.西南林业大学 天麻研究院,云南 昆明 650224;2.云南焯耀科技有限公司,云南 昆明 650220)
天麻(GastrodiaelataBl.)为兰科(Orchidaceae)天麻属(GastrodiaR.Br.)植物的干燥块茎,别名神草、赤箭、鬼督邮等,是一味传统、名贵的中药材,具有镇静、抗癫痫、镇痛、活血、抗氧化、增智健脑等功效[1-3]。天麻在我国入药已有2 000余年的历史,首次是以赤箭之名记载于《神农本草经》[4],并且列为上品,之后的历代中药书籍均有相关记载,现已列为药食同源物质。最早以山东泰安为天麻主要产区,后由于自然环境变化及社会因素,其主要产地更替为陕西汉中、云南昭通、安徽六安、湖北宜昌等地[5]。不同产地的天麻有效成分含量有明显差异,质量相差悬殊,而仅从外观上不易分辨,导致市面上以次充好的现象时有发生。目前对天麻产地鉴别的方法主要是HPLC指纹图谱[6]、非线性化学指纹图谱[7]、电化学指纹图谱[8]等方法,但存在需对天麻样品进行分离提取,处理过程复杂,耗时长,所需试剂多等问题。
近年来,随着化学计量学与计算机的发展,近红外光谱技术也迅速发展,而且具有环保、高效、成本低、对样品无破坏、无需化学试剂等优点。如:张敏等[9]将不同产地的鸡血藤(Kadsurainterior)用近红外漫反射光谱法进行采集,运用一阶导数,矢量归一化对其光谱图进行预处理,并用因子法建立定性鉴别模型,模型能有效鉴别不同产地的鸡血藤;杨海龙等[10]采集3个产地的山楂(CrataeguspinnatifidaBunge)近红外光谱,用标准正态变量变换(SNV)和Savitzky-Golay(SG)平滑预处理方法,判别分析算法(DA)对3个产地的山楂进行了鉴别;唐艳等[11]采用微分处理,多元散射校正(MSC),Norris Derivative(ND)平滑处理等方法对西洋参(Panaxquinquefolius)图谱进行预处理,在全波段采用正交偏最小二乘判别分析算法(OPLS-DA),建立西洋参产地的定性模型;李莉等[12]通过多种预处理方法,结合聚类分析、主成分分析、SIMCA 等算法分别对不同产地骆驼蓬(PeganumharmalaL.)建模进行评价,结果采用MSC,矢量归一化,全波长预处理方法,结合SIMCA 算法识别能力最佳,该方法可以用于骆驼蓬的产地鉴别;马天翔等[13]采用NIRDRS指纹图谱技术,结合二阶导数光谱,相似度分析,主成分分析对不同产地锁阳(CynomoriumsongaricumRupr.)进行鉴别。
天麻中包含天麻素、天麻苷元、氨基酸、巴利森苷、天麻多糖等有机物,而这些有机物含有丰富的N-H、C-H、O-H等含氢基团,这些含氢基团振动的倍频与合频吸收在近红外光谱区有响应。利用这一原理,采集天麻样品的近红外光谱,可以获得大量的特征信息,以期将近红外光谱技术用于天麻的产地鉴别。
1 材料与方法
1.1 材料
各地天麻样品88个(云南昭通30个,省内非昭通28个,省外30个),经西南林业大学天麻研究院刘祥义教授鉴定,样品来源详见表1。

表1 样品编号及产地Tab.1 The number and sources of samples

续表1
1.2 仪器与软件
AntarisⅡ傅立叶变换近红外光谱仪(美国Thermo Fisher公司);PTF 100型中药粉碎机(济南乐瑞医疗器械有限公司;101-2ES 电热鼓风干燥箱(北京市永光明医疗仪器有限公司);60目不锈钢筛网(北中西泰安公司);SIMCA-P+11.0软件(瑞典Umetrics公司);RESULT 3.0光谱采集软件;TQ Analyst 8.6软件;WEKA 3.6.6软件。
1.3 实验方法
1.3.1 样品预处理
用自来水把不同产地收集天麻样品清洗干净,洗净后用蒸馏水冲洗3次,切成2 mm的薄片、放入蒸锅中蒸制3~5 min,将蒸制好的天麻薄片放入烘箱中温度调至60 ℃烘干,烘干后取出放入中药粉碎机粉碎,过60目筛网,筛网上样品放入粉碎机再次粉碎,直至全部可过筛,将样品存至密封袋备用。
1.3.2 采集近红外光谱
将制好的天麻样品放入平衡箱平衡1.5 h,使样品含水量在10%到12%,将15 g样品放入采样杯,混匀压紧。利用配备RESULT 3.0光谱采集软件的AntarisⅡ傅里叶变换近红外光谱仪采集天麻光谱。天麻光谱的采集方式为积分球漫反射模式,分辨率为8 cm-1,扫描范围为10 000~ 4 000 cm-1,次数为64次。为减小实验误差,每个样本重复测定3次,取平均光谱[14-15],见图1。

图1 样品原始光谱Fig.1 The original spectrum of samples
1.3.3 训练集和验证集的选择
将不同产地的样品随机分为训练集和验证集,其比例为3∶1,并对其进行分类赋值(表2)。训练集用于建立天麻产地的定性模型,验证集用于验证定性模型对天麻样品的预测能力。

表2 样品分类及数量Tab.2 Classification and quantity of samples
1.3.4 近红外光谱预处理
近红外光谱受多方面因素影响,如样品颗粒尺寸、光程、温度、仪器采集时间等,会对模型准确性造成影响,因此需要对光谱进行一定的预处理[16-19]。本研究采用标准正态变量变换(SNV)与一阶微分光谱(first derivative spectrum,FD)、二阶微分光谱(second derivative spectrum,SD)、原始光谱(original spectrum,O),Savitzky-Golay(SG)和Norris Derivative(ND)两种平滑方法相互组合的方法(表3),探索适合天麻产地鉴别的光谱预处理方法。

表3 光谱预处理方法Tab.3 Pre-treatment method of spectrum
1.3.5 特征波段的选择
PCA-MD模型选择经过最佳预处理的训练集的方差光谱,选取方差较大的波段进行分析,见图2。PLS-DA模型通过变量重要性图(variable importance plot,VIP),选择自变量对因变量影响大于1的波段[20]。
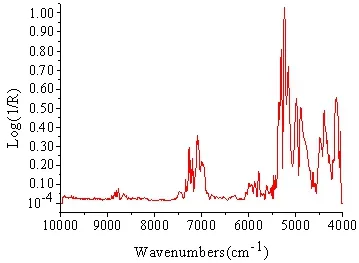
图2 方差光谱Fig.2 Variance spectrum
1.3.6 主成分数的选择
主成分数采用内部交互验证法筛选,主成分数的选择对模型预测能力有很大影响。主成分过少,会因光谱信息遗漏导致拟合不足;主成份过大,模型会包含过多的噪音,出现过拟合现象,当交互验证均方根误差(RMSECV)最小时,对应主成分数最佳[21]。
1.3.7 定性模型建立与评价
通过训练集的内部交叉验证来判断模型的质量,RMSECV越小,稳健性越好,准确率越高,模型的可信度越高。用验证集的外部验证来判断模型的预测能力,Q2越大,说明模型预测能力越好。
2 结果与分析
2.1 PCA-MD
2.1.1 主成分分析
选择表3中最优预处理方法SNV+SD+ND处理光谱,根据方差光谱(图2)选择方差大的波段(4 050~6 100 cm-1,6 800~7 500 cm-1),根据主成分贡献率及累计贡献率选择主成分,选择贡献率大于1%的主成分,并满足累计贡献率大于70%的原则,选择6个主成分数,结果见表4。用PCA-MD算法进行建模,对3种产地的天麻进行主成分分析(图3)。其中1为昭通天麻,2为省内非昭通天麻,3为省外天麻。通过对前3个主成分进行分析可以看出3个产地的天麻明显成簇聚集,呈现出较为明显的区域分布特征,说明相同产地的天麻有一定的相似性,不同产地的天麻有明显的差异;1、2分布相对集中,3的分布较分散,说明昭通天麻、省内非昭通的天麻相似度高,成分差异相对较小,省外天麻成分差异较大,这与采集的省外天麻产地众多有关。1与2、3的距离较远,而2、3虽然可以分开,但距离很近,说明昭通天麻与省内非昭通和省外的天麻成分相差较大,而省内非昭通与省外的天麻相比,虽然成分也有差异,但差异并不十分明显。

表4 主成分及贡献率Tab.4 Principal components and contribution rate

图3 主成分得分的3D展示
2.1.2 马氏距离
对主成分进行分析,可以得知相同产地的天麻之间,不同产地的天麻之间的一些关系,但要想将这些关系表达清楚,还需要一些数据的引入,马氏距离(mahalanobis distance,MD)这一统计量可以有效地反映类内与类间的关系。类内马氏距离小,说明样品相似度高,类间马氏距离大,说明两产地样品差异大,反之亦然。根据极限中心定理和3δ原则[22],用马氏距离确定不同产地天麻的类内与类间的控制阈值(表5、表6)。对验证集的22个样品进行外部验证,所有样品均在控制阈值内,全部可以进行判别,2个样品判别错误,整体准确率达到90.91%,见表7。

表5 马氏距离平均值Tab.5 Average value of Mahalanobis distance

表6 类内马氏距离控制阈值Tab.6 Class Mahalanobis distance control threshold

表7 外部验证结果Tab.7 External validation results
2.2 PLS-DA
选择SNV+SD+ND预处理方法,根据VIP法选择VIP值大于1的波段,用此法最终选择波段并不连续,由许多波段累加组合,主要长波段为4 045~6 036、6 907~7 463 cm-1,其余为小波段。按主成分特征值大于1,累计贡献率大于70%的原则[20],选择4个主成分数,显著性均为R1(表8),用PLS-DA算法进行建模(图4)。由图4可看出1、2、3可明显分开,对PLS-DA得分图进行分析,该模型自变量累计解释能力(R2X)=0.764,因变量累计解释能力(R2Y)=0.903,Q2=0.851,RMSECV=0.192 6。表示4个主成分对自变量变异的解释能力为76.4%,对因变量变异的解释能力为90.3%,对不同产地天麻的预测能力为85.1%,交叉验证均方根误差为0.192 6,可以看出模型具有良好的解释能力和预测能力并且有较好的稳健性。为了验证PLS-DA模型的可靠性,对模型进行置换检验,X矩阵不变,将Y矩阵变量随机排列200次得到置换检验验证图(图5)。模型可靠性与拟合直线的斜率,直线与Y轴的截距有关,斜率越大,截距越小,可靠性越高,图中两直线R2=0.202小于0.3,Q2=-0.337小于0,且两条直线斜率都较大,说明未出现过拟合现象。并对模型进行交叉验证方差分析(CV-ANOVA),结果显示F=49.62,P=0,表明该模型在统计上显著有效。对验证集的22个样品进行外部验证,根据Galtier判别准则[23],除70号判别错误外,其余均判别正确,整体准确率达到95.45%,见表9。
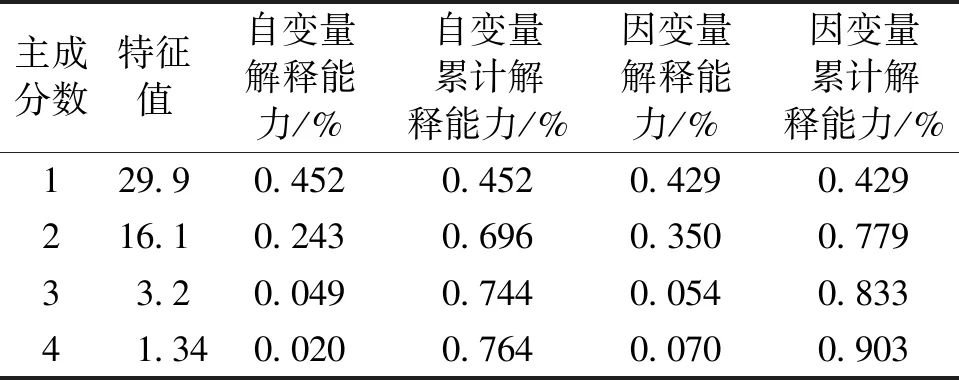
表8 主成分数的选择Tab.8 The choice of the number of principal component

图4 PLS-DA散点3D模型Fig.4 Scatter 3D plot PLS-DA

图5 置换检验的验证直观效果Fig.5 Plot of replacement test
3 结论与讨论
用TQ软件采集不同产地天麻样品的近红外光谱,对天麻光谱进行SNV+SD+ND预处理,用方差法选取4 050~6 100、6 800~7 500 cm-1波段的光谱,结合PCA-MD算法进行建模,提取模型的马氏距离,主成分累计贡献率对模型进行评估,结果显示模型较好,根据极限中心定理和3δ原则对验证集进行预测,判别正确率为90.91%。在原预处理光谱的基础上,用SIMCA软件VIP法选取主要波段为4 045~6 036、6 907~7 463 cm-1,其余为零散波段的光谱,建立PLS-DA模型,提取模型的R2X,R2Y,Q2,RMSECV对模型进行评估,结果显示模型良好,并对模型进行置换检验和CV-ANOVA,验证模型无过拟合现象,且在统计上显著有效,根据Galtier判别准则对验证集进行预测,判别正确率达到95.45%。通过比较,PLS-DA模型在天麻产地鉴别上优于PCA-MD模型,可以更为准确的鉴别天麻产地,为天麻产地鉴别提供了一种新的方法。
猜你喜欢
数学物理学报(2022年2期)2022-04-26
数学物理学报(2021年3期)2021-07-19
数学物理学报(2020年6期)2021-01-14
发明与创新·小学生(2020年1期)2020-08-13
数学年刊A辑(中文版)(2020年1期)2020-05-19
发明与创新(2020年3期)2020-01-06
中成药(2018年6期)2018-07-11
天然产物研究与开发(2016年11期)2016-06-15
西南学林(2014年0期)2014-11-12
西南学林(2014年0期)2014-11-12
