
文本情感分析方法研究综述
2021-06-23 09:40杨文忠
计算机工程与应用 2021年12期
王 婷,杨文忠
1.新疆大学 软件学院 软件工程技术重点实验室,乌鲁木齐830046
2.新疆大学 信息科学与工程学院,乌鲁木齐830046
随着信息技术的快速发展,互联网已经与人们的日常生活密不可分,同时信息也开始呈现出爆炸式的增长。2019年2月,根据《中国互联网发展状况统计报告》可知,截止2018年12月,我国网民规模达8.29亿,新增网民5 653万,互联网普及率达59.6%[1],可见网络已成为人们现代生活中的重要组成部分。关于国务院印发的《新一代人工智能发展规划》[2]中指出,人工智能的迅速发展将深刻改变人类社会生活、改变世界。
伴随着网民数量的增长,越来越多的信息在网上出现。网民可以在微博等公共平台上发布对于各类事件的看法,表达自己的情感态度:在舆情分析方面,通过对热点事件进行情感剖析,寻找情感原因,对政府了解民意,预防危害事件的发生具有一定的意义;在情感对话方面,情感机器人可以抚慰心灵,充当情感陪护的角色;在商品和服务评论分析方面,对评价对象和评价表达进行抽取,识别评论中的情感倾向性,对消费者挑选商品,商家改进商品/服务具有一定的辅助作用。因此在现阶段,人工智能不断进步,通过情感计算实现有效的情感分析,是一个有巨大意义的任务。
1 文本情感分析介绍
文本情感分析又称意见挖掘,是指对带有情感色彩的主观性文本进行分析,挖掘其中蕴含的情感倾向,对情感态度进行划分。文本情感分析作为自然语言处理的研究热点,在舆情分析、用户画像和推荐系统中有很大的研究意义。文本情感分析的过程如图1所示,包括原始数据的获取、数据的预处理、特征提取、分类器以及情感类别的输出。

图1 文本情感分析过程
原始数据的获取一般是通过网络爬虫获取相关数据,如新浪微博内容、推特语料、各大电商网站的评论等;数据预处理是指进行数据清洗去除噪声,常见的方法有去除无效字符和数据、统一数据类别(如中文或简体)、使用分词工具进行分词处理、停用词过滤等;特征提取根据使用的方法不同,会有不同的实现方法,在依赖不同的工具获得文本的数值向量表征时,常见的方法有词频计数模型N-gram和词袋模型TF-IDF,而深度学习方法的特征提取一般都是自动的;分类器输出得到文本的最终情感极性,常见的分类器方法有SVM和softmax。
2 文本情感分析方法介绍
根据使用的不同方法,将情感分析方法分为:基于情感词典的情感分析方法、基于传统机器学习的情感分析方法、基于深度学习的情感分析方法。更进一步的方法划分如图2所示。
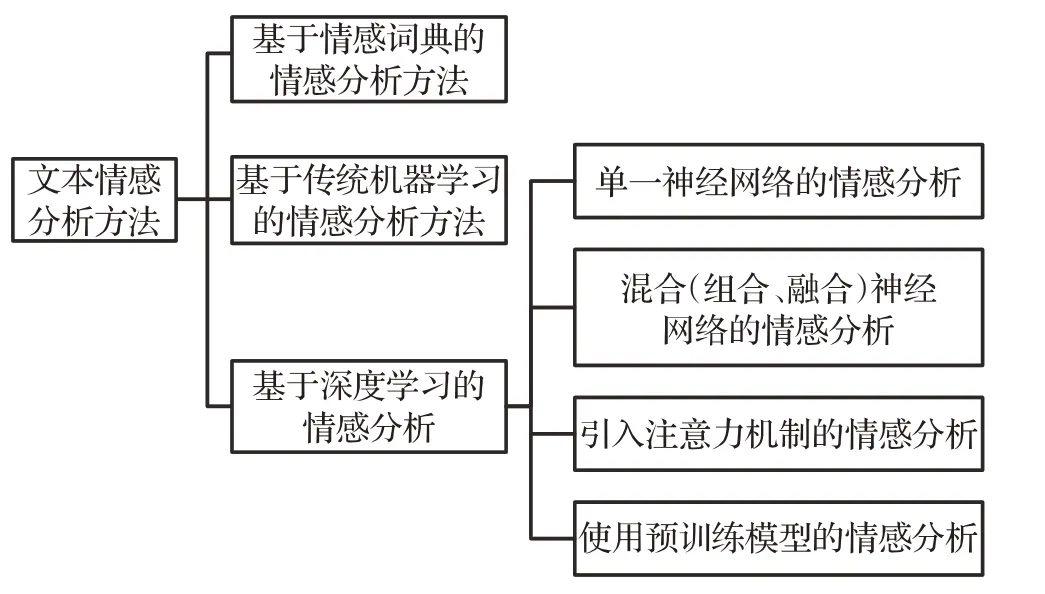
图2 情感分析方法分类
2.1 基于情感词典的情感分析方法
基于情感词典的方法,是指根据不同情感词典所提供的情感词的情感极性,来实现不同粒度下的情感极性划分,该方法的一般流程如图3所示,首先是将文本输入,通过对数据的预处理(包含去噪、去除无效字符等),接着进行分词操作,然后将情感词典中的不同类型和程度的词语放入模型中进行训练,最后根据情感判断规则将情感类型输出。现有的情感词典大部分都是人工构造,按照划分的不同粒度,现有的情感分析任务可以划分为词、短语、属性、句子、篇章等级别。人工构建情感词典需要花费很大的代价,需要阅读大量的相关资料和现有的词典,通过总结概括含有情感倾向的词语,并对这些词语的情感极性和强度进行不同程度的标注。对于情感词典的构建,国外最早的是SentiWordNet[3]情感词典,它根据WordNet将含义一致的词语合并在一起,并赋予词语正面或者负面的极性分数,情感极性分数可以如实反应用户的情感态度。与英文情感词典不同,中文情感词典主要有NTUSD[4]、How Net[5]、情感词汇本体库[6]组成。这三类情感词典中分别包含不同数量的褒义词和贬义词,许多情感分析研究者对这三类情感词典进行大量学习和使用。

图3 基于情感词典的情感分析方法一般流程
栗雨晴等人[7]提出一种基于双语词典的多类情感分析模型,有效解决了现有的情感词典多基于单一语言的问题;Cai等人[8]通过构建一种基于特定域的情感词典,来解决情感词存在的多义问题,通过实验表明,将SVM和GBDT两种分类器叠加在一起,效果优于单一的模型;柳位平等人[9]利用中文情感词建立一个基础情感词典用于专一领域情感词识别,还在中文词语相似度计算方法的基础上提出了一种中文情感词语的情感权值的计算方法,该方法能够有效地在语料库中识别及扩展情感词集并提高情感分类效果;Rao等人[10]用三种剪枝策略来自动建立一个用于社会情绪检测的词汇级情感词典,此外,还提出了一种基于主题建模的方法来构建主题级词典,其中每个主题都与社会情绪相关,在预测有关新闻文章的情绪分布,识别新闻事件的社会情绪等问题上有很大的帮助。
现有的基于情感词典的情感分析方法都是建立在流行的中文或英文等语言上,因此有学者在其他语言领域做了研究,有学者[11]建立一种大型西班牙语情感词典的方法,用于情感的主观性分析;Nguyen等人[12]提出了一种将情感词典的方法运用在越南语中,通过从越南语文本中挖掘民意,来提高情感分类的准确性,有效解决创建越南语词典情感分类方法的问题;Wu等人[13]利用网络资源建立第一个俚语词汇情感词典,有效分析俚语的社交媒体内容的情感极性。
为有效解决中文情感词典的数据量、口语化词语少的问题,赵妍妍等人[14]提出一种面向微博的大规模情感词典的方法,该方法在微博情感分类的性能上和基线方法相比提高了1.13%;Xu等人[15]通过构建一个包含基本情感词、场景情感词和多义情感词的扩展的情感词典,有效实现了文本的情感分类;Cai等人[16]利用Apriori算法对基于上下文的情感歧义词进行扩展,扩展后的情感词典由情感对象、情感词、情感极性三元组组成,通过构造的情感歧义词词典来实现细粒度的情感定向分析;王科等人[17]对情感词典自动构建方法进行了综述,将情感词典自动构建方法总结为三类:基于知识库的方法、基于语料库的方法、基于知识库和语料库结合的方法,并通过对现有的中英文情感词典进行归纳总结,分析了情感词典自动构建方法存在的问题等;Xu等人[18]构造了一个扩展的情感词典,该情感词典包含基本情感词、领域情感词和多义情感词,利用扩展的情感字典和设计的情感评分规则,实现了文本的情感分类。实验结果表明,作者提出的基于扩展情感字典的情感分析方法具有一定的可行性和准确性。
基于情感词典的方法可以准确反映文本的非结构化特征,易于分析和理解。在这种方法中,当情感词覆盖率和准确率高的情况下,情感分类效果比较准确。但这种方法仍然存在一定的缺陷:基于情感词典的情感分类方法主要依赖于情感词典的构建,但由于现阶段网络的快速发展,信息更新速度的加快,出现了许多网络新词,对于许多类似于歇后语、成语或网络特殊用语等新词的的识别并不能有很好的效果,现有的情感词典需要不断地扩充才能满足需要;情感词典中的同一情感词可能在不同时间、不同语言或不同领域中所表达的含义不同,因此基于情感词典的方法在跨领域和跨语言中的效果不是很理想;在使用情感词典进行情感分类时,往往考虑不到上下文之间的语义关系。因此对基于情感词典的方法还需要更多的学者进行充分的研究。
随着信息技术的快速发展,涌现出了越来越多的网络新词,原有的情感词典对于词形词性的变化问题不能很好解决,在情感分类时存在灵活度不高的问题;情感词典中的情感词数量也存在限制,因此需要不断地扩充情感词典来满足对情感分析的需要,对于情感词典的扩充需要花费大量的时间和资源。为提高情感分类的准确性,有研究者对基于传统机器学习的方法进行了研究,取得了不错的结果。
2.2 基于传统机器学习的情感分析方法
机器学习是一种通过给定的数据训练模型,通过模型预测结果的一种学习方法。该方法研究至今,已经取得了诸多有效的成果。基于机器学习的情感分析方法是指通过大量有标注的或无标注的语料,使用统计机器学习算法,抽取特征,最后在进行情感分析输出结果。基于机器学习的情感分类方法主要分为三类:有监督、半监督和无监督的方法。
在有监督方法中,通过给定带有情绪极性的样本集,可以分类得到不同的情感类别。有监督的方法对数据样本的依赖程度较高,在人工标记和处理数据样本上花费的时间较多。常见的有监督的方法有:KNN、朴素贝叶斯、SVM。在半监督方法中,通过对未标记的文本进行特征提取可以有效地改善文本情感分类结果,这种方法可以有效解决带有标记的数据集稀缺的问题。在无监督方法中,根据文本间的相似性对未标记的文本进行分类,这种方法在情感分析中使用较少。
通过对有监督的机器学习方法梳理,许多研究者在情感分析方面取得了不错的成果。唐慧丰等人[19]通过使用几种常见的机器学习方法(SVM、KNN等)对中文文本的情感分类进行了实验比较,考虑到不同的特征选择方法、文本特征表示方法、特征选择机制、数据集的规模和文本的特征数量对情感分类的影响,通过大量的对比实验发现采用BiGrams特征表示方法、信息增益特征选择方法和SVM方法时,在大量训练集和适量的特征选择时情感分类效果可以达到最优;在短文本和多级情感分类问题中,有监督的机器学习方法也取得了不错的效果,杨爽等人[20]提出了一种基于SVM的多级情感分类研究,通过在情感、词性、语义等特征上实现情感的五级分类,通过实验结果表明,该方法对情感的分类的准确率为82.4%,F值为82.10%;Li等人[21]提出一种基于多标签最大熵(MME)模型用于短文本情感分类,实验表明该方法在相关数据集(微博、推特、BBC论坛博客等评论)上的准确率可达86.06%;在快速追踪公众的情绪变化,衡量公众利益方面,情感分析也起到一定的作用,Xue等人[22]用机器学习的方法LDA(潜在的狄利克雷分布)来实现对2020年3月1日至4月21日期间与COVID-19相关的2 200万条Twitter信息中的突出的主题及其情感的识别。
除了对微博和推特等公共社交媒体的研究,Pang等人用[23]三种机器学习的方法(朴素贝叶斯、最大熵分类和支持向量机)在有关电影评论的数据集上进行情感分类的判断,实验结果表明在支持向量机方法中可以达到82.9%的准确性;还有研究者[24]使用机器学习分类算法(LSTM、SVM等)对药物评论的情感进行分析,将药物的数量分为三类(阳性、阴性和中性),通过实验在测试数据集上取得了不错的结果;许多研究者通过对有监督的机器学习方法的融合研究,在情感分析方面也取得了不错的效果,Kamal等人[25]提出了一个基于规则和机器学习方法相结合的情绪分析系统来识别特征-意见对其情感极性,来实现在不同电子产品中用户的评价来实现用户的情感极性的划分;有研究者[26]使用贝叶斯网络分类器对两个西班牙语数据集进行情感分析(2010年智利地震和2017年加泰罗尼亚独立公投),通过大量的训练实例,和其他机器学习方法(支持向量机和随机森林)对比发现,能更有效地预测情感极性。
在有监督的机器学习方法基础上,许多研究者对半监督的机器学习方法进行研究,并取得了大量成果。有研究者对微博用户的立场检测进行研究,立场检测即判断用户对于给定目标是赞成还是反对的态度,Liu等人[27]采用有监督和半监督机器学习方法实现了对微博用户的立场检测,通过在SVM、朴素贝叶斯和随机森林等不同的分类器上进行实验对比,得到了显著的效果;为解决推文中主客观内容的不平衡的问题,Yu等人[28]提出了一种基于半监督机器学习方法用于推文情绪分类,实验结果表明该方法的召回率约为60%;Jiang等人[29]提出一种基于表情符号的情绪空间模型ESM(Emotion Space Model)的半监督情感分类方法,该方法利用表情符号从未标记的数据中构建词向量,相比于基线方法效果较好。
基于传统机器学习的情感分类方法主要在于情感特征的提取以及分类器的组合选择,不同分类器的组合选择对情感分析的结果有存在一定的影响,这类方法在对文本内容进行情感分析时常常不能充分利用上下文文本的语境信息,因此其分类准确性有一定的影响。表1为基于机器学习方法的情感分析的实验结果。
因此,为解决在情感分析问题中存在忽略上下文语义的问题,许多研究者对基于深度学习的情感分析方法进行了深入研究,取得了许多成果。
2.3 基于深度学习的情感分析方法
通过对基于深度学习的情感分析方法细分,可以分为:单一神经网络的情感分析方法、混合(组合、融合)神经网络的情感分析方法,引入注意力机制的情感分析和使用预训练模型的情感分析。
2.3.1 单一神经网络的情感分析
2003年Bengio等人[30]提出了神经网络语言模型,该语言模型使用了一个三层前馈神经网络来建模。神经网络主要由输入层、隐藏层、输出层构成。在该网络的输入层的每个神经元代表一个特质,隐藏层层数及隐藏层神经元是由人工设定,输出层代表分类标签的个数,一个基本的三层神经网络如图4所示。语言模型的本质就是根据上下文信息来预测下一个词的内容,而不依赖人工标注语料,由此可以发现语言模型的优势就是能从大规模的语料中学习丰富的知识。这种方法能够有效解决基于传统情感分析方法中忽略上下文语义的问题。
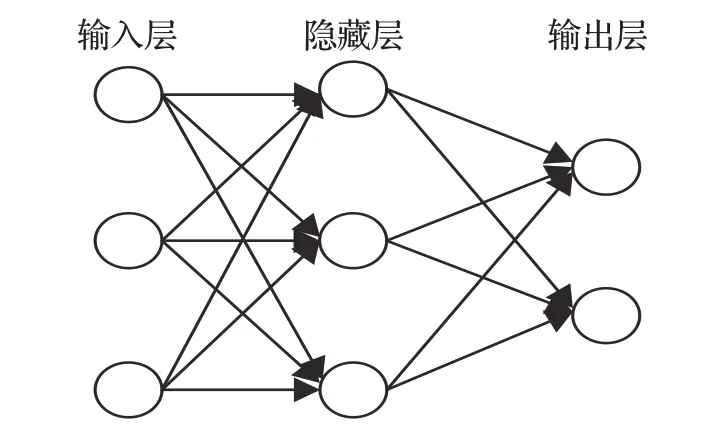
图4 基本的三层神经网络
典型的神经网络学习方法有:卷积神经网络(Convolutional Neural Network,CNN)、递归神经网络(Recurrent Neural Network,RNN)[31]、长短时记忆(Long Short-Term Memory,LSTM)网络等。
许多研究者通过对神经网络的研究,在情感分析的任务中取得了不错的结果。长短期记忆网络(LSTM)是一种特殊类型的递归神经网络(RNN),在处理长序列数据和学习长期依赖性方面效果不错。为了加快模型的训练速度,减少计算量和计算时间,Gopalakrishnan等人[32]提出了六种不同参数的精简LSTM模型来实现对共和党辩论推特数据集上的情感分析,通过实验证明不同参数设置和模型层数设置均会对实验结果产生影响;Fei等人[33]提出了一种基于长短时记忆的多维话题分类模型,该模型由长短时记忆(LSTM)细胞网络构成,可以实现对向量、数组和高维数据的处理,实验结果表明该模型的平均精度达91%,最高可以达到96.5%;通过对社交媒体和网络论坛中的信息进行情感分析,可以有效获取公众意见。因此,对于新冠病毒(COVID-19)的研究就变得很有意义,Jelodar等人[34]通过使用LSTM方法对COVID-19的评论进行情感分类,研究结果对COVID-19的相关问题的指导和决策有一定的影响意义。
为解决传统CNN方法中忽略文本潜在主题的问题,Zhou等人[35]提出一种基于CNN的多样化限制玻尔兹曼机(RBM)方法来对文本中句子的顺序潜在主题建模,来达到情感分类的效果;Li等人[36]提出了一种基于卷积神经网络(CNN)的中文微博系统意见摘要算法,该模型通过应用CNN自动挖掘相关特征来进行情感分析,通过一个混合排序函数计算特征间的语义关系,该方法在四个评价指标上(准确率、召回率、精度、AUC)优于传统的分类方法(SVM、随机森林、逻辑回归),对微博数据的情感预测的准确性达到86%;Wang等人[37]提出了一种将递归神经网络和条件随机场相结合的联合模型,将其整合到一个统一的框架中,用于对方面词和意见词的提取。该模型同时学习高级判别特征,并在方面词和意见词之间进行信息的双重传播。在SemEval Challenge 2014数据集上的实验结果表明,该模型比几种基准方法更具有优越性。

表1 基于机器学习方法的情感分析的实验结果
2.3.2 混合(组合、融合)神经网络的情感分析
除了对单一神经网络的方法的研究之外,有不少学者在考虑了不同方法的优点后将这些方法进行组合和改进,并将其用于情感分析方面。
在充分考虑到循环神经网络和卷积结构的优点,Madasu等人[38]提出了一种顺序卷积注意递归网络(SCARN),通过与传统的CNN和LSTM方法相比较,SCARN具有更好的性能;罗帆等人[39]利用联合循环神经网络和卷积神经网络,提出一种多层网络模型HRNN-CNN,该模型使用两层的RNN对文本建模,并将其引入句子层,实现了对长文本的情感分类;Xing等人[40]通过引入一个新的参数化卷积神经网络用于方面级情感分类,该方法使用了参数化过滤器(PF-CNN)和参数化门机制(PG-CNN),在emEval 2014 datasets数据集上取得较高的准确性,可以达到90.58%;Jiang等人[41]提出了一种基于分句极性和卷积神经网络融合的情感分类方法,首先利用神经网络对构成原句的多个分句的情感极性进行计算,然后利用极性融合规则对输出的分句情感极性进行合并,来计算原句的情感极性,实验表明,在SST-1和SST-2数据集上的分类精度分别达到48.6%和87.8%,取得了较好的结果;考虑到普通时间卷积网络对文本进行单向特征提取时不能充分捕捉文本特征,对文本的分析能力较弱,韩建胜等人[42]提出一种基于双向时间卷积网络(Bi-TCN)的情感分析模型。该模型使用单向多层空洞因果卷积结构分别对文本进行前向和后向特征提取,将两个方向的序列特征融合后进行情感分类,实验证明,与单向时间卷积网络情感分析模型相比,双向时间卷积网络模型在四个中文情感分析数据集上的准确率分别提高了2.5%、0.25%、2.33%和2.5%;为充分利用语法信息,Lai等人[43]提出了一个基于语法的图卷积网络(GCN)模型来增强对微博语法结构多样性的理解,此外,在实验中对微博的情感进行细粒度分类,包括快乐、悲伤、喜欢、愤怒、厌恶、恐惧和惊讶,该模型的F-measure达到82.32%,比最先进的算法高出5.90%。实验结果表明,该模型能有效提高情感检测的性能,此外作者注解了一个新的中国情感分类数据集(https://github.com/zhanglinfeng1997/Sentiment-Analysis-via-GCN),并向其他研究者开放以供研究。
除了实现对长文本的情感分类问题,也有研究者将混合神经网络方法用于短文本情感分类问题,杜永萍等人[44]提出一种基于CNN-LSTM神经网络的情感分类方法,在短文本评论中对含有隐含的语义的短文本评论中的情感倾向性识别取得不错的效果;为充分利用情感分析任务中的情感信息,李卫疆等人[45]提出一种基于多通道双向长短期记忆网络的情感分析模型(Multichannels Bi-directional Long Short Term Memory network,Multi-Bi-LSTM),该模型对情感分析任务中现有的语言知识和情感资源进行建模,生成不同的特征通道,让模型充分学习句子中的情感信息,通过在中文COAE2014数据集、英文MR数据集和SST数据集进行实验,取得了比普通Bi-LSTM、结合情感序列特征的卷积神经网络以及传统分类器更好的性能。
和使用基于情感词典和传统机器学习的情感分析方法相比,采用神经网络的方法在文本特征学习方面有显著优势,能主动学习特征,并对文本中的词语的信息主动保留,从而更好地提取到相应词语的语义信息,来有效实现文本的情感分类。由于深度学习概念的提出,许多研究者不断对其探索,得到了不少的成果,因此基于深度学习的文本情感分类方法也在不断扩充。
2.3.3 引入注意力机制的情感分析
在神经网络的基础上,2006年,Hinton等人率先提出了深度学习的概念,通过深层网络模型学习数据中的关键信息,来反映数据的特征,从而提升学习的性能。基于深度学习的方法是采用连续、低维度的向量来表示文档和词语,因此能有效解决数据稀疏的问题;此外,基于深度学习的方法属于端到端的方法,能自动提取文本特征,降低文本构建特征的复杂性。深度学习方法除了在语音和图像领域取得了显著的成果以外,还在自然语言处理领域取得了重大进展,如机器翻译、文本分类、实体识别等,对文本情感分析方法的研究属于文本分类的一个小分支。
注意力机制(attention mechanism)最早的应用是在视觉图像领域,在文献[46]中,研究者在RNN模型上使用了注意力机制来实现图像分类,随后,Bahdanau等人[47]通过将注意力机制应用在机器翻译任务中,这也意味着注意力机制开始应用到自然语言处理领域中。2017年Google机器翻译团队[48]提出用Attention机制代替传统RNN方法搭建了整个模型框架,并提出了多头注意力(Multi-head attention)机制,如图5所示,其中Q、K、V首先经过一个线性变换,然后输入到放缩点积Attention(Scaled Dot-Product attention)中,进行h次计算,即多头。然后将h次的放缩点积Attention结果进行拼接,再进行一次线性变换得到的值作为多头Attention的结果。通过实验证明在将该方法用于WMT2014语料中的英德和英法任务上效果不错,训练速度优于主流模型。

图5 多头注意力机制
注意机制能够扩展神经网络的能力,允许近似更加复杂函数,即关注输入的特定部分。通过在神经网络中使用这种机制,可以有效提升自然语言处理任务的性能。
Da’U等人[49]提出了一种基于注意力的神经网络(SDRA)的深度感知推荐系统,该系统能够捕捉产品的不同方面以及用户对不同方面产品的潜在情感,从而提高推荐系统的性能,此外,作者还引入了协同注意机制,以更好地对用户-项目交互进行细粒度建模,从而提高预测性能;Yang等人[50]首次提出一种将目标层注意和上下文层注意交替建模的协同注意机制,通过将目标转移到关键词的上下文表示来实现方面情感分析,在SemEval 2014数据集和Twitter数据集上的实验表明,该方法优于传统带有注意力机制的神经网络方法;Pergola等人[51]提出一种基于话题依赖的注意模型,该方法通过使用注意力机制来实现对单词和句子的局部主题嵌入,用于情绪分类和主题提取问题,并取得了不错的效果;刘发升等人[52]提出了一种将注意力机制和句子排序的双层CNN-BiLSTM的模型,该方法能有效解决在深度学习方法应用在情感分析时没有很好地解决文本特征和输入优化的问题,通过实验证明该方法在情感分类精度上有所提高,能有效用于一般的情感分类任务;顾军华等人[53]提出一种基于卷积注意力机制的模型(CNN_attention_LSTM)用于提取文本的局部最优情感和捕捉文本情感极性转移的语义信息,该方法首先使用卷积操作提取文本注意力信号,将其加权融合到Word-Embedding文本分布式表示矩阵中,突出文本关注重点的情感词与转折词,然后使用长短记忆网络LSTM来捕捉文本前后情感语义关系,最后采用softmax线性函数实现情感分类通过实验表明,该方法在带有情感转折词的文本中,能够更好地捕获文本的情感倾向,提高情感分类精度;陈珂等人[54]针对情感词典不能有效考虑到上下文语义信息,循环神经网络获取整个句子序列信息有限以及在反向传播时可能存在梯度消失或梯度爆炸的问题,提出一种基于情感词典和Transformer的文本情感分析方法,该方法充分地利用了情感词典的特征信息,还将与情感词相关联的其他词融入到该情感词中以帮助情感词更好地编码,此外,该方法对不同情感词的不同位置进行研究,发现句子中的单词顺序和距离对句子中情感的影响,通过在NLPCC2014数据集中进行实验发现该方法比一般神经网络具有更好的分类效果。
除了上述研究者通过对显示文本的情感进行研究以外,还有部分学者通过对含有隐式情感词的文本进行了研究。隐式文本的情感分析目前还处于起步阶段,和含有显式情感词的文本相比,隐式文本的情感分析具有一定的难度,赵容梅等人[55]利用卷积神经网络对文本进行特征提取,再使用LSTM提取文本中的上下文信息,并通过添加注意力机制来实现对隐式文本的情感分析,最后通过实验在公开的数据集上可以达到77%的准确率;潘东行等人[56]提出了一种结合上下文语义和融合注意力机制的情感分析方法,该方法首先使用Word2vec方法进行特征提取,在通过结合不同的分类模型(TextCNN、LSTM、BiGRU),最后通过融合注意力机制的方法来有效实现对隐式文本的情感分析;Wei等人[57]提出一种基于多极性正交注意的BiLSTM模型用于隐式情感分析,与传统的单一注意力机制的模型相比,该方法可以有效识别词语和情感倾向之间的差异,并在实验中得到了验证。
通过在深度学习的方法中加入注意力机制,用于情感分析任务的研究,能够更好地捕获上下文相关信息,提取语义信息,防止重要信息的丢失,可以有效提高文本情感分类的准确率。现阶段的研究更多的是通过对预训练模型的微调和改进,从而更有效地提升实验的效果。
2.3.4 使用预训练模型的情感分析
预训练模型是指用数据集已经训练好的模型。通过对预训练模型的微调,可以实现较好的情感分类结果,因此最新的方法大多是使用预训练模型,最新的预训练模型有:ELMo、BERT、XL-NET、ALBERT等。
Peters等人[58]在2018年的NAACL会议(The North American Chapter of the Association for Computational Linguistics,计算机语言学协会北美分会)上提出一个新方法ELMo,该方法使用的是一个双向的LSTM语言模型,由一个前向和一个后向语言模型构成,目标函数就是取这两个方向语言模型的最大似然值。和传统词向量方法相比,这种方法的优势在于每一个词只对应一个词向量。ELMo利用预训练好的双向语言模型,然后根据具体输入从该语言模型中可以得到上下文依赖的当前词表示(对于不同上下文的同一个词的表示是不一样的),再当成特征加入到具体的NLP有监督模型里。在相关实验中表明,通过加入这种方法,实验结果平均提升了2%。
2018年10月谷歌公司提出一种基于BERT[59]的新方法,它将双向的transformer机制用于语言模型,充分考虑到单词的上下文语义信息。在模型的输入方面BERT使用了WordPiece embedding作为词向量,并加入了位置向量和句子切分向量。许多研究者通过对BERT模型的微调训练,在情感分类中取得了不错的效果;有研究者[60]通过BERT模型来实现细粒度的情感分析任务,并通过在Stanford Sentiment Treebank(SST)[61]数据集上实验,在SST-2数据集上(二分类标签)可以达到94.7%的准确性,在SST-5数据集上(五分类标签)可以达到84.2%的准确性;Araci等人[62]提出一种基于BERT的FinBERT语言模型来处理金融领域的任务,通过对BERT模型的微调,分类的准确率提高了15%;Xu等人[63]通过结合通用语言模型(ELMo和BERT)和特定领域的语言理解,提出DomBERT模型用于域内语料库和相关域语料库中的学习,在用于基于方面的情感分析任务上的实验证明该方法的有效性以及广阔的应用前景;为解决快速准确地从大量负面金融文本中挖掘出关键信息,Zhao等人[64]提出了一种基于BERT的情感分析和关键实体检测方法,并将其应用于在线金融文本挖掘和社交媒体舆情分析。实验结果表明,在两个财务情绪分析和关键实体检测数据集(2019年CCF大数据与计算智能大赛子任务和2019年CCKS2面向金融领域的事件主体抽取子任务)上该方法性能普遍高于SVM、LR、NBM和BERT;Sun等人[65]提出一种新的ABSA(Aspect-Based Sentiment Analysis,基于方面的情绪分析)方法,通过微调预先训练的BERT模型将ABSA任务转化为句子对分类任务,取得了不错的结果;Hu等人[66]提出一种基于方面的硬选择的情感分析方法,通过给定的意见片段的开始和结束位置,选择两个位置之间的词进行情绪预测利用预先训练好的BERT模型来学习句子和方面之间的深层关联,以及句子中的长期依赖关系,并通过自批判强化学习进一步检测意见片段,该方法在处理多向句时的效果明显更好;为有效捕获到基于句子组成结构的复合情感语义,Yin等人[67]提出一种基于BERT的变体方法SentiBERT,该方法包含三个模块:BERT、基于注意网络的语义组合模块、短语和句子的情感预测因子,通过实验证明该方法效果明显优于基线方法。
大量的研究者对基于transform模型的变体BERT模型的研究多侧重于英语,有研究者提出[68]一种用于波斯语的单语BERT(ParsBERT)模型用于情感分析、文本分类等,通过在大量数据集上实验证明该方法优于多语言BERT模型和其他方法;Delobelle等人[69]将BERT模型用于荷兰语,并进行了鲁棒优化来训练得到Bob-BERT荷兰语模型,通过实验对比发现,和现有的基于BERTbased荷兰语言模型相比,BobBERT方法得到了较好的结果。有研究者发现现有的基于BERT的情感分析方法大都只利用BERT的最后一个输出层,而忽略了中间层的语义知识,因此Song等人[70]通过对BERT的中间层进行研究,提高BERT的细化性能在基于方面的情感分析中,并通过实验证明了该方法的有效性;又有研究者通过对BERT模型进行改进,Lan等人[71]提出了ALBERT模型,该模型的优势在于缩小了整体的参数量,加快了训练速度,增加了模型效果;曾诚等人[72]提出一种结合预训练模型ALBERT_CRNN的方法用于视频网站的弹幕文本情感分析,在三个手工爬取的视频网站的数据集(哔哩哔哩、爱奇艺、腾讯视频)上的情感分类的准确度分别达到94.3%、93.5%、94.8%,均优于传统方法。
通过和传统方法相比,使用语言模型预训练的方法充分利用了大规模的单语语料,可以对一词多义进行建模,使用语言模型预训练的过程可以被看作是一个句子级别的上下文词表示。通过对大规模语料预训练,使用一个统一的模型或者将特征加到一些简单的模型中,在很多NLP任务中取得了不错的效果,说明这种方法在缓解对模型结构的依赖问题上有明显的效果。表2列举了基于深度学习方法的文本情感分析中的实验结果。
未来对于自然语言处理的任务的研究将会更多,尤其是文本的情感挖掘方面。其中最新的情感分析方法大多基于对预训练模型的微调,并取得了较好的效果。因此,可以预知未来的情感分析方法将更加专注于研究基于深度学习的方法,并且通过对预训练模型的微调,实现更好的情感分析效果。
2.4 情感分析方法对比
通过将情感分析方法分为:基于情感词典的情感分析方法、基于传统机器学习的情感分析方法、基于深度学习的情感分析方法,将其不同优缺点总结如表3所示。
3 文本情感分析方法应用
现阶段对于情感分析的研究已经很充分,并且在许多场景中也能得到应用,如商品评论,社交媒体等。
谢治海等人[73]提出一种基于影视情感类型与强度的自回归票房预测模型,同时还构建了面向票房预测的影评情感可视分析系统MRS-VIS。通过该系统可以有效地对电影上映前后的影评情感进行多角度的分析,在对电影票房的预测方面有一定的准确性和可靠性;王建成等人[74]提出一种基于神经主题模型用于对话情感分析,对话情感分析可以识别出一段对话中的每个句子的情感极性,因此在电商客服数据中发挥着很大的作用,作者通过在电商客服对话数据上的实验结果表明该方法的有效性;梁士利等人[75]通过构建金融情感词典及改进的贝叶斯算法,实现了对股票市场的情感数据的有效分析,在和基线方法比较中发现,该方法的准确率可以达到90.6%,能达到较好的预测结果,从而有效完成了对股票市场的分析预测;沈瑞琳等人[76]提出一种多任务学习框架,将情感分析和谣言检测这两个任务结合起来学习,利用情感分析任务辅助谣言检测,在公开的微博数据集中取得了不错的效果;陈亚茹等人[77]提出一种融合自注意力机制和BiGRU网络的情感分析模型用于微博文本的情感分析,通过在三个微博数据集上的实验表明,该方法有效地提高了情感分类的准确率;宋双永等人[78]以阿里小蜜为例,对情感分析技术在应用于智能客服系统中进行了全面介绍,包括相关的情感分析算法的模型原理,以及其在智能客服系统中的应用场景的实际落地的使用方式及其效果,表明情感分析技术在客服机器人中起到的重要作用;陈兴蜀等人[79]利用分布式爬虫技术,分布式数据库系统,SnowNLP情感分析模型和K-Means文本聚类算法,对2020年1月1日至2月29日期间共计6万条新浪微博及1.5万条微博热门评论的内容进行情感分析,对与“新冠肺炎疫情”相关话题展开舆情分析,可以发现在不同时间段,不同地区网民的情感波动不同,饱含的情感值也不同,如在疫情严重的地区,网民的评论较多,情感值偏低。

表2 基于深度学习方法的情感分析中的实验结果

表3 文本情感分析方法对比
这些应用使得对于情感分析的研究变得更加有实际意义,科学研究真正实现落地,实现其价值的最大化。

表4 常见情感词典介绍

表5 常见显式情感数据集介绍
4 文本情感分析数据集及评价指标
现有的基于情感分析的方法的研究过程中,在基于情感词典的方法中有大量公开的情感词典供研究者使用,在基于传统机器学习方法和基于深度学习的方法中有研究者使用公开发表的数据集,也有研究者通过构建新数据集,划分不同的标签来实现对于情感的分类。数据集中的数据来自不同的主题和来源,数据集的大小也不同,数据集的大小对实验结果也会有不同的影响。
4.1 情感词典
通过对情感词典中的情感词载入进行训练,来实现对文本中的情感词有效识别,从而达到情感分类的效果,因此情感词典扮演着重要的作用,表4列出了研究者常用的情感词典。
4.2 显式情感数据集
在情感分析的研究中,数据资源是至关重要的一部分,针对不同研究方法,不同的研究学者使用不同的语料库来实现不同程度的情感分类。表5是对常见的显式情感分析的中英文数据集的简单介绍。图6为weibo_senti_100k数据集中部分内容。
4.3 隐式情感数据集

图6 weibo_senti_100k数据集
现有的情感分析方法多基于显示文本的研究,即在句子中含有直接表达情感的词语,也有研究者[55-57]通过对隐式文本的情感进行研究,因此需要使用不含有显式情感词的隐式数据集。SMP2019数据集(数据集下载地址:http://conference.cipsc.org.cn/smp2019/smp_ecisa_SMP.html)是由第八届全国社会媒体处理大会“拓尔思杯”中文隐式情感分析测评发布的数据集,该数据集由山西大学提供,数据来源主要包括微博、旅游网站、产品论坛,主要领域/主题包括但不限于:春晚、雾霾、乐视、国考、旅游、端午节等,数据集中包含的显示情感词文本已经通过大规模情感词典进行过滤处理,处理后的数据集中将隐式情感句进行了部分标注,分为褒义隐式情感(1)、贬义隐式情感(2)和不含情感倾向的句子(0)。该数据集的测试集和训练集中的数据量的详细划分如表6所示。图7为SMP2019数据集中部分内容。

表6 SMP2019数据集划分

图7 SMP2019数据集
4.4 评价指标
具体实验中常用到的评价指标有准确率、精确度(P)、召回率(R)、准确率(Acc)以及F1值,其中各个评价指标的计算公式如下所示:
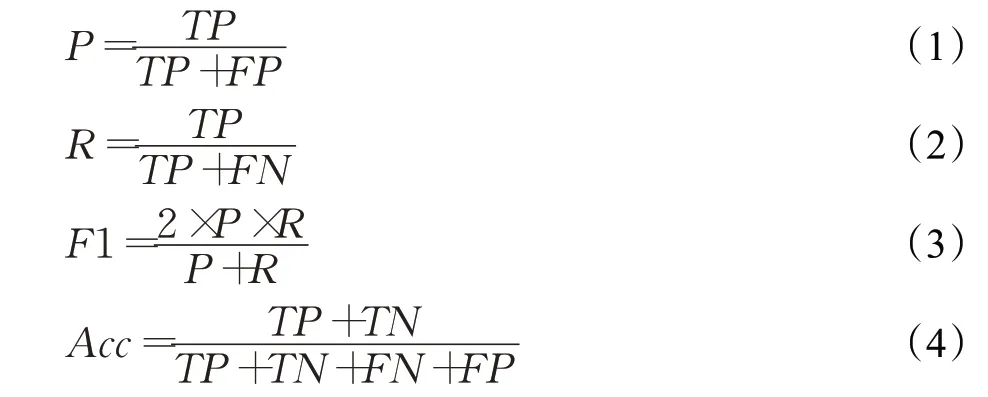
TP代表将正类样本预测为正类的数量,FN代表将正类样本预测为负类的数量,FP代表将负类样本预测为正类的数量,TN代表将负类样本预测为负类的数量。
5 情感分析子任务
5.1 反讽检测
通过研究发现,在社交媒体中存在许多反讽或讽刺的现象,而这些语句中表达的情感往往与语句表面的意思不一致,通过对反讽语句的研究,提取其深层语义特征,对于情感分析的研究也很有帮助。
Chaudhary等人[84]通过对情感分析过程和决策过程进行改进,并在Twitter上爬取数据,在四个机器学习方法的实验中取得了不错的效果,线性SVC(accuracy=83%,f1-score=0.81)、Naïve Bayes(accuracy=74%,f1-score=0.73)、logistic回归(accuracy=83%,f1-score=0.81)和随机森林分类器(accuracy=80%,f1-score=0.77);卢欣等人[85]研究发现,微博评论中存在大量反讽语句,而以往的情感分析任务并没有考虑到,因此作者通过构建一种融合语言特征的卷积神经网络的反讽情感识别方法,并通过实验证明该方法优于传统的机器学习方法;有作者[86]发现以往的对于讽刺检测的研究多是利用自然语言处理技术进行,并未考虑其语境,用户的表达习惯等,因此通过一种双通道卷积神经网络来分析目标文本的语义,以及其情感语境,还利用注意力机制来提取用户的表达习惯,通过在多个数据集上的实验证实该方法的有效性,并能够有效提升讽刺检测任务的性能。
5.2 隐式情感分析
隐式情感分析是情感分析领域较为特殊的部分,由于缺乏情感词,情感表达较为模糊,是现阶段研究的难点,通过对现阶段隐式情感分析的文献梳理,发现现有的研究非常有限。
Zuo等人[87]发现以往的图卷积网络(Graph Convolutional Network,GCN)在用于情感分析问题的研究时,不能有效地利用上下文文本的语境信息,或者常常会忽略短语间的依赖关系,所以在此基础上提出一种新的上下文特定的异构图卷积网络(CsHGCN),通过实验证实该模型能有效识别句子中的目标情感;杨善良等人[88]在图卷积注意力神经网络(Graph Attention Convolutional Neural Network)的基础上构建文本和词语的异构图谱,使用图卷积网络对隐式情感语句进行建模,操作传播语义信息,通过注意力机制提取语句中对情感分析重要的语句特征,通过在SMP2019中文隐式情感分析评测数据集上验证了模型的有效性,能取得91.7%的准确率。
5.3 多模态情感分析
现阶段,许多社交媒体中的评论内容往往不仅仅是文字或图片,传统的基于文本的情感分析方法不能很好解决这一类的问题,因此,多模态情感分析方法旨在融合不同模态的特征来进行情感极性的判断。
Huang等人[89]提出了一种新的图像文本情感分析模型,即深度多模态关注融合(Deep Multimodal Attention Fusion,DMAF),利用视觉和语义内容之间的区别特征和内在相关性,利用混合融合框架进行情感分析。先利用两种独立的单模态注意模型,分别学习视觉模态和文本模态,然后,提出了一种基于中间融合的多模态注意力模型,利用视觉特征和文本特征之间的内在关联进行联合情感分类。最后,采用一种后期融合方案,将三种注意模型结合起来进行情感预测。在弱标记和人工标记的数据集上进行了大量的实验,证明了该方法的有效性。
Haish等人[90]提出了一种文本、音频和视频的多模态情感分析融合方法。和以往特征级或决策级融合的方法相比,该方法使用基于注意力的深度神经网络来促进特征和决策级的特征融合,该网络通过两个阶段的融合来有效利用三种模式(文本、音频和视频)的信息,在多模态数据集中证明了该方法的有效性。
5.4 面向方面级情感分析
基于方面的情感分析(Aspect-Based Sentiment Analysis,ABSA)是情感分析(Sentiment Analysis,SA)中一个具有挑战性的子任务,它旨在识别针对特定方面的细粒度意见极性。
Chen等人[91]提出了一种基于神经网络的新框架来识别评论中方面目标的情感。该框架采用了多注意机制来捕捉远距离下的情感信息,通过与递归神经网络的非线性结合,增强了模型的表达能力,能处理更加复杂的语义问题。在四个数据集上(两个数据集来自SemEval2014(餐馆和笔记本电脑的评论)、twitter数据集、中文新闻评论数据集)验证了该模型的性能。
Xue等人[92]发现以往的预测方法大多采用长、短期记忆和注意机制来预测相关目标的情绪极性,这些方法往往比较复杂,需要更多的训练时间。所以提出将之前的方法归纳为两个子任务:方面-类别情感分析(ACSA)和方面-项情感分析(ATSA)。还提出了一种基于卷积神经网络和门控机制的模型,该模型更加准确和有效。该方法首先通过新的门控单元Tanh-ReLU根据给定的方面或实体有选择地输出情感特征;这个体系结构比现有模型中使用的注意层要简单得多;其次,该模型的计算在训练过程中很容易并行化,因为卷积层不像LSTM层那样有时间依赖性,门控单元也是独立工作,最后通过在SemEval数据集上的实验验证了该模型的有效性。
阿拉伯语由于其复杂的结构,加上其资源的缺乏,为情感分析任务带来了许多挑战。有学者通过对面向阿拉伯语方面的情感分析作为研究方向,Heikal等人[93]采用卷积神经网络(CNN)和长短期记忆(LSTM)模型相结合的集成模型对阿拉伯语推文的情感进行预测。在阿拉伯语情感推文数据集(ASTD)上,该模型F1得分为64.46%,优于最先进的深度学习模型;有研究者[94]利用两种不同的长短期记忆神经网络用于对阿拉伯酒店评论的基于方面的情感分析的研究。第一种是字符级双向LSTM以及条件随机场分类器(Bi-LSTM-CRF)用于方面意见目标表达式(选票)提取,第二种是一个面向LSTM方面情绪极性分类的aspect-OTEs作为情绪极性标识。该方法使用阿拉伯酒店评论的参考数据集进行评估,结果表明,该方法在两种任务上都优于基线研究,分别提高了39%和6%。
6 结语
现阶段,越来越多的人在社交媒体上发表自己的观点看法,表达情感,通过分析他们的情感极性可以判断他们的态度。特别是在对于政治立场、网络购物等问题的评论的情绪分析十分有必要。通过对情感极性的判断,来预测将来可能要发生的事情。网络评论、微博、博客等社交媒体中的文本,蕴含着大量的情感和情绪,情感分析是对文本中的情感进行计算,对情绪进行挖掘,因此是一个十分有意义的挑战。情感分析不仅涉及到自然语言处理领域,还涉及到计算机科学、管理学科以及社会学科的交叉融合。
本文通过对现阶段国内外关于文本情感分析的问题的研究,对不同方法进行分类,总结介绍了各种方法所取得的成果,还对通用的数据集以及实验的评价指标进行简单的介绍,对文本情感分析方法的应用简要介绍,以及现阶段情感分析方法中的子任务研究进行简单概述。通过对情感词典的情感分析方法、基于传统机器学习的情感分析方法、基于深度学习的情感分析方法对比,可以发现基于情感词典的情感分析方法和基于传统机器学习的情感分析方法中存在的问题,基于深度学习的方法的优势。可以预测在未来的自然语言处理领域中,文本数据的规模不断扩大,将深度学习用于情感分析是未来的研究趋势。
从不同方法的发展趋势来看,未来文本情感分析的研究需要关注以下方面:
(1)通过对比不同的研究方法可以发现,现有的对于情感分析的研究方法多基于单一领域,如社交网络媒体平台weibo、酒店评论等,在个性化推荐中如何将多个领域的内容结合,进行情感分类,实现更好的推荐效果,并实现在提高模型的泛用性能,都是未来值得研究和探索的工作方向。
(2)大部分对于情感分析的研究多用于显式的文本情感分类问题,采用含有明显情感词的数据集,而对于某些隐式词的检测和分类效果不佳。现阶段对于隐式情感分析的研究还处于起步阶段,不是很充分,未来可以通过构建隐式情感词词典,或者通过使用更好的深度学习方法来更深层次地提取语义相关信息来实现更好的情感分类效果。
(3)对于复杂语句的情感分析研究需要进一步完善,当带有情感倾向的网络用语、歇后语、成语等越来越频繁地出现,尤其在文本中含有反讽或隐喻类的词时,情感极性的检测就会存在难度,这也需要进一步研究。
(4)多模态情感分析也是近来的研究热点,如何将多个模态中的情感信息进行提取和融合,是大家主要研究的方向,当多个模态中的情感表达不一致时,该如何权重不同模态中的情感信息也是需要考虑的;以及是否能考虑外部语义信息,这对情感分析的准确性是否有帮助,也是需要有大量的研究。
(5)在情感分析的子任务中,也能发现大多研究是基于简单二分类情感分析,实现多分类,更加细粒度的情感分析也是将来的研究热点。
(6)预训练模型是现阶段的研究热点,它能有效解决传统方法中存在的问题,如不能并行化计算的限制等,还能有效捕获词语之间的相互关系,并且通过微调就能在下游任务中实现较好的效果,但也会存在模型参数量大,训练时间较长的问题。如何在模型的参数量小,有效缩短训练时间的前提下,达到好的分类效果,也会是值得研究的方向。
通过对不同的文本情感分析方法进行总结和归纳,对不同方法进行对比和简单介绍,并总结了相应的优缺点,并对未来的对文本情感分析方面继续研究的学者提供一定的指导和建议。
情感分析是一项相当有意义的研究工作,有着广泛的应用前景,在将来会有更多有效的方法和成果。同时也希望本文能对文本情感分析领域研究的学者给予一定的帮助。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
重型机械(2020年2期)2020-07-24
文苑(2019年24期)2020-01-06
文苑(2019年24期)2020-01-06
电子制作(2019年19期)2019-11-23
中国航海(2019年2期)2019-07-24
重型机械(2016年1期)2016-03-01
大连工业大学学报(2015年4期)2015-12-11
海军航空大学学报(2015年4期)2015-02-27
中关村(2014年5期)2014-05-15
