
基于DeeplabV3+的无人机遥感影像识别
2021-06-21 06:01赖丽琦
林业调查规划 2021年3期
赖丽琦
(浙江农林大学 信息工程学院,浙江 杭州 311300)
近些年来,随着无人机航拍技术日渐成熟,无人机航拍影像正在被越来越广泛地应用于各个领域。作为高空卫星遥感影像的补充,无人机航拍影像以其获取方便,成像分辨率高,受大气因素干扰小的优点[1],在小区域遥感应用方面拥有较大的前景[2-4],基于无人机的林业资源信息获取已成为一种研究热点。林志玮等[5]利用DenseNet,FC-DenseNet对无人机遥感影像中的不同树种进行细分,其分类精度均达80%以上,最高精度为87.54%;杨建宇等[6]使用SegNet对遥感影像中农村建筑物进行分割,得到了优于传统机器学习方法的结果;刘文萍等[7]提出一种改进的DeeplabV3+模型,编码器中将主干网络替换为ResNet+,增加联合上采样模块,调整 ASPP 模块,解码器中融合更多浅层特征。该模型对无人机影像的不同土地类型进行了较好地细分,得到效果更好的分类与分割结果;宋建辉等[8]利用基于迁移学习的DeeplabV3+模型进行无人机地物场景语义分割,平均交并比达75.45%;戴鹏钦等[9]使用Resnet-Unet对结合了植被因子的遥感影像进行识别,结合最优尺度的面向对象分割结果可以对其结果进行修正,有效去除了“椒盐噪声”,提高了树种分类精度;滕文秀等[10]采用超像素法结合语义分割模型对无人机影像进行识别,该方法较单一模型收敛更快,精度更高。
传统机器学习方法通常沿用了卫星遥感图像的处理思路,需要人为选取特征变量,工程量大,而且特征变量的选取对精度的影响较大[11,12],深度学习领域中的语义分割方法具有较好的鲁棒性和分类分割效果,能较好地避免特征选择对精度的影响,为无人机影像分割与分类提供了新思路[13]。
本文以无人机获取的植被覆盖影像为研究对象,使用传统图像分割模型随机森林(Random Forest)和语义分割模型SegNet,U-Net,DeeplabV3+对影像进行识别分割,并对DeeplabV3+模型进行改进,探讨不同模型的指标优劣,以期得到最佳分割模型,为无人机植被影像精准识别提供参考。
1 材料与方法
1.1 数据采集
使用六旋翼无人机DJI Matrice 600 Pro,最大载重5.5 kg,最大飞行高度500 m。搭载相机型号为Zenmuse X5,有效像素1 600万,分辨率4608×3 456,镜头焦距15 mm,等效焦距30 mm。
影像拍摄地点位于临安区榧子山附近的青山湖绿道,拍摄时天气良好,受天气影响较小,相机镜头保持垂直向下。
1.2 数据集的建立
根据拍摄地点无人机影像,结合青山湖地区植被分布情况,根据《中国植被》所提出的植被生活型划分为4种植被类型,即乔木、草本、灌木、禾本类草本,将道路,水体等其他物体统一归为背景。为提升模型的收敛速度,减少运算量,将图像裁剪为512像素×512像素,使用labelme进行图像像素级别标注并生成标签图。通过旋转,翻转,倾斜,弹性变换,透视,裁剪,缩放等不同操作对数据进行增广,共获得 4 500 张图像,按照7∶3的比例划分为训练集和验证集。图1(a)为其中一幅样本图及其数据增广图,图1(b)为对应的标签图。

图1 数据增广与标签图Fig.1 Data augmentation and label map
1.3 分割方法
1.3.1随机森林
随机森林(Random Forest)由Breiman[14]于2001年提出,是指利用多棵决策树对样本进行训练并预测的一种算法,属于监督分类方法。其通常包含多个决策树,输出的类别是由个别决策树输出的类别的众树来决定的。随机森林方法实现简单,精度高,具有较好的抗过拟合能力。
1.3.2SegNet
SegNet是一个由Encoder和Decoder组成的对称网络[15,16]。其中Encoder使用的是微调过的VGG16中的前13层卷积网络结构。SegNet的创新就在于其Encoder的每一个Max-pooling过程中保存其池化索引(最大值的Index),在Decoder层使用这些得到的索引来做非线性上采样,对经过上采样的特征图进行卷积操作产生密集特征图(Feature maps),送入softmax分类器中进行分类。SegNet改善了边界划分,减少了端到端训练的参数量,模型较小,对内存要求较低。
1.3.3U-net
U-net[17]包括两部分,分别为特征提取和上采样部分。由于网络结构像U型,所以叫U-net网络。与传统FCN网络不同,U-net采用了完全不同的特征融合方式:拼接(Concatenate),U-net网络的每个卷积层得到的特征图都会拼接到对应的上采样层,从而实现对每层特征图均有效使用到后续计算中。这样做的好处是结合了低级特征图中的特征,从而可以使得最终所得到的特征图中既包含了高维度的特征,也包含很多低维度的特征,实现了不同尺度下特征的融合,能有效提高模型的结果精确度,在小样本集上也能获得较为出色的表现,常用于医疗影像分割。
1.3.4DeeplabV3+
DeeplabV3+是Deeplab[18]系列网络的第四代产品。DeeplabV3+为了融合多尺度信息,其引入了语义分割常用的encoder-decoder形式。在Encoder-Decoder 架构中,引入可任意控制编码器提取特征的分辨率,通过空洞卷积平衡精度和耗时。DeeplabV3+与SegNet、U-net相比,其最大的改进之处就是引入了空洞卷积,空洞卷积加大了感受野,而且并不会造成信息损失,使得每个卷积输出均包含了更大范围的信息,并且DeeplabV3+将深度可分离卷积应用于ASPP和解码器,以替换所有的最大池化(Max-pooling)操作,有效减少了参数数量,提升模型训练速度。DeeplabV3+模型结构见图2。

图2 DeeplabV3+模型结构Fig.2 Structure of DeeplabV3+ model
1.3.5改进的DeeplabV3+
本文提出的分割方法基于DeeplabV3+语义分割模型,并对主干网络进行了替换,采用加入扩张卷积的MobilenetV2作为主干网络,进一步减少模型参数量,使模型更加轻量化。
相比原始DeeplabV3+使用的Xception+网络,MobileNetV2网络可以大幅度缩减参数量,并且可以用较少的运算量得到较高的精度。在相同显存大小的情况下,可以使用更大的batch size来训练模型。同时,轻量化的网络结构显著降低了模型权重文件大小和模型预测速度。改进的DeeplabV3+模型结构见图3。
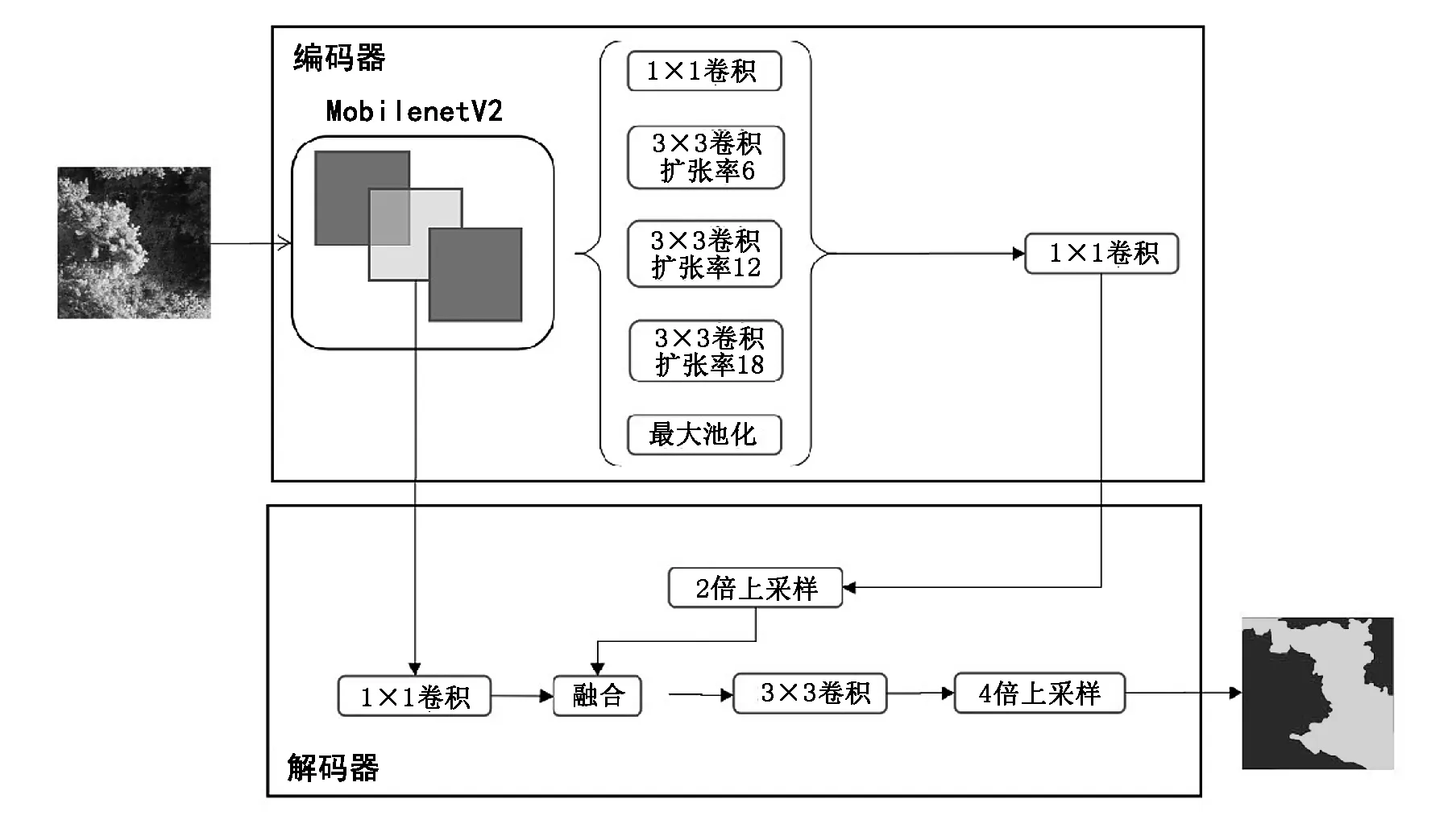
图3 改进的DeeplabV3+模型结构Fig.3 Structure of improved DeeplabV3+ model
2 实验结果与分析
2.1 实验环境与模型训练
使用Keras构建深度学习模型,处理器为i7-8750H,显卡为GTX1080TI。按照7:3的比例随机划分训练集与验证集。模型以3幅图像为一个批次进行完整迭代。以交叉熵作为损失函数;以验证集损失函数值Val_loss为监控对象,当Val_loss经过7个epoch不下降时,自动降低1/2学习率;当Val_loss经过40个eopch不下降时,认为模型已经收敛,提前结束训练。
除图像原始特征外,还使用32组不同参数组合的Gabor滤波器获取图像纹理特征,使用Roberts,Sobel等算子获取边缘特征,最后加入高斯、中值滤波器等,共获取42个特征进行随机森林模型训练。
2.2 评价指标
基于混淆矩阵基础评估模型精度。采用的评价指标有PA(Pixel Accuracy),MIOU(Mean Intersection Over Union),Precision(精确率)以及Recall(召回率)。具体计算公式为:
(1)
(2)
(3)
(4)
其中,假定数据集中有n+1类(0~n),0通常表示背景。真正(TP)和真负(TN)表示原本为i类同时预测为i类,假正(FP)和假负(FN)表示原本为i类被预测为j类。如果第i类为正类,当i!=j时,使用Pii表示原本为i类同时预测为i类,Pij表示原本为i类被预测为j类,则Pii表示TP,Pjj表示TN,Pij表示FP,Pji表示FN。
2.3 实验结果
2.3.1未改进模型实验结果对比
不同模型在数据集上的表现如表1所示。

表1 不同模型指标对比
从表1中可以看到,传统机器学习模型Random Forest表现较差,在训练集和验证集上的表现较深度学习模型有所差距。U-net表现略好于SegNet,在验证集上的MIOU比SegNet高出2.41%;DeeplabV3+的平均交并比MIOU达到66.43%,比U-net高出2.94%,其他指标也都优于SegNet和U-Net的表现。可以得出结论:DeeplabV3+模型在本次实验中表现最好,空洞卷积的引入使得模型的感受野加大,能够获取更多上下文信息,使得模型的MIOU较其他模型有很大提升。
DeeplabV3+模型的部分指标如图4所示。
从图4可以看到,模型的指标曲线均在80个epoch左右趋于平缓,到120个epoch时模型已达到收敛。

图4 Indicators of DeeplabV3+ model Fig.4
2.3.2改进模型实验结果
本文提出的改进的DeeplabV3+模型与原始DeeplabV3+模型对比效果见表2,以验证集指标作为评估指标。模型1为原始DeeplabV3+模型,模型2为本文提出的改进模型。
从表2中可以看出,模型2各项指标较模型1均有所提升。模型2在模型1基础上,Accuracy提升1.07%,Precision提升2.22%,Recall提升0.19%,MIOU提升4.46%。实验结果表明,改进模型能够获得更好的分类与分割效果。与原模型相比,改进模型在各项性能指标上均有所改善,且MIOU有明显提升。

表2 模型指标对比
模型各项参数指标如表3所示。
从表3可知。与模型1相比,使用MobilenetV2作为主干网络后,模型2的参数个数从41,254,101降到2,766,933,仅为模型1的6.71%,更少的参数使模型训练更快,更加轻量化;单epoch训练时长从485s降到363s,总训练Epoch次数从158次降到125次,训练时长也有明显缩短。
两个模型部分预测结果如图5所示。

图5 两种模型分割效果对比Fig.5 Comparison of the segmentation results of two models
由图5可以看出,模型1误分割情况较多,在边界分割上效果并不理想。模型2误分割情况有所改善,在植被覆盖图像上的分割分类精度较高,能够对边界进行更好地划分,具有更好的鲁棒性和实用性。但仍存在一定“椒盐噪声”,存在进一步优化的可能。
3 结论与讨论
针对现有林地覆盖数据获取方法耗时慢、成本高、工程量大等问题,基于深度学习方法,提出一种面向无人机航拍影像的语义分割方法。结果表明,基于深度学习的语义分割方法能够在植被识别任务上取得一定成果。
1)使用语义分割模型以及传统图像分割模型分别对研究区无人机影像进行识别分割,表明语义分割模型在图像分割上的表现要优于传统图像分割模型,可应用于无人机航拍影像识别;在语义分割模型中,DeeplabV3+表现最好,在验证集上的像素准确率为93.64%,精确率为94.28%,召回率为93.96%,平均交并比为66.43%。
2)本文提出的改进DeeplabV3+模型在验证集上的像素准确率为94.71%,查准率为96.50%,召回率为94.15%,平均交并比为70.89%,相比原始DeeplabV3+模型像素准确率提高了1.07%,精确率提高了2.22%,召回率提高了0.19%,平均交并比MIOU提高了4.46%,得到了更高的分割与分类效果。训练时长为原模型的78.76%,参数量仅为原模型的6.74%,具有一定的适用性和实用价值。
3)本实验无人机航拍高度固定为20 m,后续可使用不同航拍高度图像进行对比实验,分析不同航拍高度对分割精度的影响[19]。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
北京航空航天大学学报(2021年9期)2021-11-02
时代邮刊·下半月(2020年9期)2020-09-23
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
金桥(2018年6期)2018-09-22
小学生优秀作文(低年级)(2018年6期)2018-05-19
北京航空航天大学学报(2018年1期)2018-04-20
陕西画报(2017年1期)2017-02-11
长江学术(2016年4期)2016-03-11
