
Mask-RCNN模型在图像篡改中的应用
2021-06-18 02:44张麒麟林清平通讯作者
信息记录材料 2021年5期
张麒麟,林清平,肖 蕾(通讯作者)
(空军预警学院 湖北 武汉 430000)
1 引言
随着科技的快速发展,手机、平板电脑等电子设备和各种图像编辑软件的普及,存储和传输数字图像变得十分便捷。但随之也带来不少问题,其中对图像进行不正当的加工和处理便是一大问题。被恶意篡改的图像经过传播,会影响人们对客观事物的评价,甚至危害社会和国家安全。近年来由于图像造假事件造成的一系列事件发人深省,针对数字图像可能面临着被随意篡改和伪造的风险,如何保证数字图像的真实性,对伪造图像进行认证将是一项非常重要的课题。针对图片篡改检测的算法,以往主要是针对JPEG格式图像的压缩特性进行检测,如DCT算法[1]和BLK算法,这些算法虽然对部分剪贴图片能有效检测,但极易受图像压缩、转码等处理的影响。
为此,我们提出了一个基于深度学习的图像篡改检测系统,由噪声图像生成、全图滤镜检测、篡改区域检测三个子系统构成。噪声图像生成是基于信噪比原理,依据图片本身存在的噪声,突出其中差异生成噪声特征图像。全图滤镜检测是依据图像像素之间的高维关联,用CNN提取其中特征,检测图片可能存在的滤镜。篡改区域检测是依据双流Mask-RCNN网络构架,从RGB和噪声两个层面并行检测图片的篡改痕迹,并对篡改区域进行精确到像素级的标识。
2 Mask-RCNN检测网络
Mask-RCNN[2]是何凯明基于以往的Faster-RCNN[3]架构提出的新的卷积网络。Mask-RCNN与Faster-RCNN同样采用了Two--Stage的结构,该网络结构同时完成了两项任务,即准确识别目标和完成高质量的语义分割。Mask-RCNN的设计思路就是在原有的Faster-RCNN基础上进行扩展,增添一个预测分割MASK的分支对目标的位置信息进行并行预测。我们将Mask-RCNN这一优秀的特性应用到篡改区域检测中,并针对图像检测的需求引入噪声检测机制和双流结构,解决了以往算法检测效果和区域划分难以共同实现的难题,实现了像素级篡改检测。
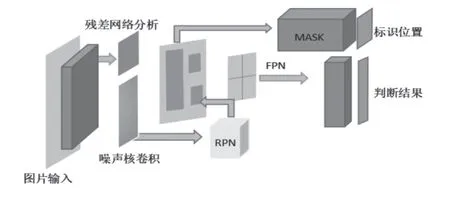
图1 Mask-RCNN检测网络模型
如图1,改进后Mask-RCNN 的网络结构图中主要有四个部分:残差网络卷积层、RPN(区域建议网络推荐)、噪声核卷积层、ROI Align(区域特征聚集)。主要流程如下:先将图片集传入检测网络,经过残差网络分析和噪声卷积核处理得到图像的feature maps(图像特征),并利用RPN对生成的feature maps做目标区域推荐生成区域推荐,最终将其分类生成判断结果。
2.1 残差网络卷积层
待检测图像中物体是以不同的scale(图片的比例)和size(图片的大小)出现的,故数据集无法捕获所有这些数据。因此,本层采用了ResNet50(残差神经网络)+FPN。这样可以较好地提取图片特征。FPN不是仅仅具有横向连接,也能实现纵向连接卷积层,它们使用一个简单的MergeLayer(把若干个层合并成一个层)来组合两者。这样的设计让图像的特征能够被充分发掘并使不同深度的特征的影响更加均匀。
2.2 RPN层
顾名思义就是区域推荐的网络,用于帮助网络推荐感兴趣的区域,也是传统Mask-RCNN中重要的一部分。通过固定锚点与滑窗确定特征区域对应的图像位置,生成一个全连接特征。然后在这个特征后产生两个分支的全连接层,用全连接层实现上一层特征到两个分支的特征映射,帮助后续mask确定像素点位置。
2.3 噪声核卷积层
主要利用截取SRM滤波中间过程[4],得到多种滤波核卷积后的图像,突出显示图像噪声方面的特征。本层接受卷积层的中间输出,经本层处理后的图像天然与下一级原始卷积图像形成类似上采样的结果,将输出结果与相同层数的原始卷积图像在FPN层中用进行特征融合,实现双流架构的引入,使噪声特征更加突出地作为图像篡改特征的一部分。
2.4 ROI Align层
ROI Align(区域特征聚集)层通过取消量化操作,采取双线性内插值的方法获得坐标数值为浮点数的像素点上的图像数值,从而将整个特征聚集过程转化为一个连续的操作。在Faster RCNN中,有两次整数化的过程:region proposal的xywh通常是小数,为了计算简便一般做整数化处理。将处理后的图像边界平均分割成个单元,对生成的单元的边界整数化。
通过以上两次整数化后的图像中的候选框位置和初始回归的位置存在一定的偏差,影响目标检测或者语义分割的准确性。ROI Align方法通过取消整数化操作,保留了小数来避免出现以上问题。改进后的流程如下:
(1)对图像中各个候选区域进行遍历,候选区域的边界不做整数化处理。
(3)对每个单元使用双线性插值的方法计算四个固定坐标位置,将获得的图像数值进行最大池化操作。
经过以上改进的ROI Align处理可以提高模型的准确性。
3 对比实验与结果分析
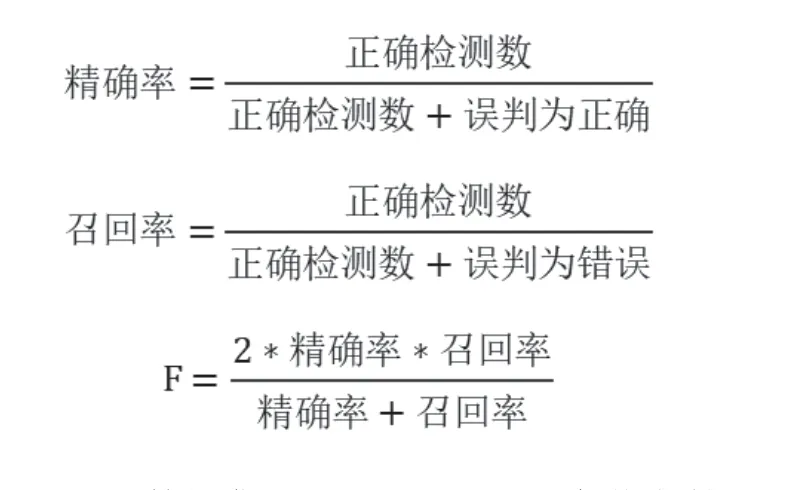
本文选取精确率、召回率和评分参数作为对比部分的参考评价,其中,精确率、召回率、评分的计算如下。
测试数据集CASIA v1.0是一个著名的用于图像篡改检测的数据集,包含丰富的真实图像和篡改图像。但为避免受到CASIA v1.0数据集的限制,实验部分采用十折交叉验证法来对实验效果进行客观的评估。
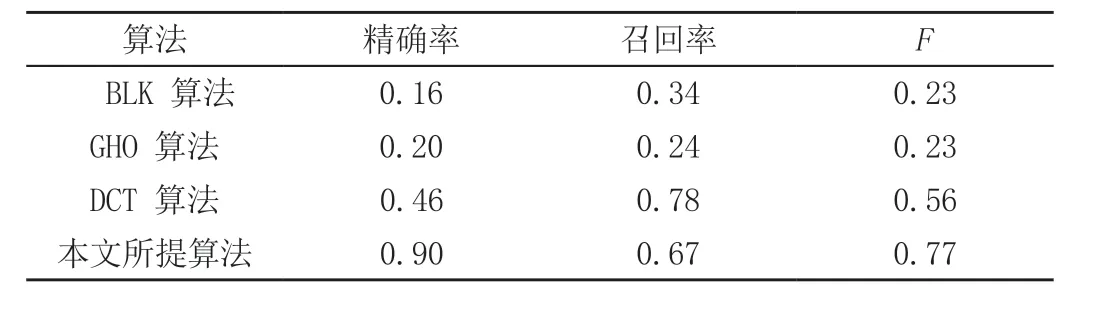
表1 本文所提算法及3种对比算法的检测结果精确率、召回率和F的平均值
通过表1可以看出,本文所提出的算法在精确率和F度量的平均值上大大优于其他三种算法,分别达到了0.76和0.72;召回率的平均值虽然略低于普通Faster-RCNN算法,但是仍然远高于ELA算法和U-Net算法,不过有研究表明:在不牺牲准确率的前提下,很难达到很高的召回率。在大规模数据集合中这两者是相互制约的,无法同时达到高的准确率和召回率,所以本文所提的算法在精确率、召回率和F的平均值方面是明显优于其他三种算法的。通过检测的实际效果也可以看出,普通Faster-RCNN算法、ELA算法和U-Net算法虽然都大致检测出了被篡改的区域,但是精度都比较低,错误检测的区域较多,反观本文所提的算法可以很明显地看出本文所提的算法在检测的实际效果上仍然优于其他三种算法。总的来看本文所提的算法在各方面都优于其他三种用于实验对比的算法。
此外,将图像检测算法应用于大量图片时,运行速度是极为重要的指标,为此,我们对同一批图片检测的速度进行了对比,结果如表2。

表2 本文所提算法及3种对比算法的检测运行时间
通过本文所提的算法及3种对比算法的检测运行时间的实测结果可以明显看出,本文所提的算法在运行时间上也有一定的改进。在保证了较好的准确率、召回率和F度量的前提下,本文所提的算法在运行时间上仍有较大的优势,具有运行速度快的特点,适用于大批量图片检测。
综上所述,我们所提出的算法的丰富特征使其在图像篡改的检测上有着较为优秀的效果。通过上面三个表的详细分析可以看出,本算法在执行速度、准确率、召回率等方面都优于现有的算法。在当前的图像篡改检测领域,本文提出的图像篡改检测系统有着较为明显的优势。
4 结语
本文设计实现了一个基于深度学习的双流Mask-RCNN框架进行篡改图像的检测,详细阐述了双流Mask-RCNN模型的构架,通过实验证明了其合理性和优越性。
双流Mask-RCNN与单一深度学习方法相比,具有更好的鲁棒性和更先进的性能。多通道的输入使图片的转码和压缩不易影响篡改特征,双流相互印证能够更加精确地定位篡改区域和能够检测多种尺寸的图片,不再受限于普通RCNN算法的图片输入大小限制,能够输出精确到像素级的篡改区域。
采取双流Mask-RCNN能从更多角度分析图片的修改痕迹信息,帮助用户更好地甄别图片真伪性。
猜你喜欢
中小学校长(2022年7期)2022-08-19
北京航空航天大学学报(2021年9期)2021-11-02
冶金设备(2020年2期)2020-12-28
数学年刊A辑(中文版)(2020年3期)2020-10-27
高原山地气象研究(2020年3期)2020-07-16
中小学校长(2019年10期)2019-11-07
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
中学生数理化·八年级物理人教版(2017年9期)2017-12-20
噪声与振动控制(2015年4期)2015-01-01
