
基于深度学习的行人属性识别综述
2021-06-18 06:47武阳阳
西安邮电大学学报 2021年2期
刘 颖,武阳阳,李 娜
(1.西安邮电大学 通信与信息工程学院,陕西 西安 710121;2.西安邮电大学 电子信息现场勘验应用技术公安部重点实验室,陕西 西安 710121;3.西安邮电大学 陕西省无线通信与信息处理技术国际联合研究中心,陕西 西安 710121)
随着社会对公共安防问题的重视提升,智能视频分析在安防领域中发挥着越来越重要的作用。在监控视频中,行人往往是安防事件的主体,若能在海量的监控视频中有效地利用好行人属性信息,便会提升安防应对能力,减少人力成本。属性信息是指可以表征行人外观的特征,包括性别、身高和衣着等信息。对属性的研究通常分为两个方向:其一,使用属性作为中间特征表示层,用于辅助其他任务的实现。例如,通过属性进行目标检测[1]或利用属性识别提升人脸验证功能[2],目前属性多用于行人检测[3-5]、行人重识别[6-11]和行为识别[12-13]等任务中;其二,是专注于自然场景下摄像头中行人属性信息的识别[14-16]。传统的属性识别是通过先提取手工标注的特征,如颜色、纹理特征等,再利用支持向量机或马尔可夫随机场等分类器,进行属性分类。随着深度学习的快速发展,越来越多的学者把深度学习运用到行人属性识别的领域,已成为目前该领域的主流研究方法。然而,在复杂的监控视频中有效地识别出属性的细粒度特征,对于计算机视觉而言是一项极具挑战性的任务[17-18]。
行人属性识别方法主要分为基于传统机器学习和深度学习的两类方法。传统方法包括特征提取和分类器两个重要组成部分。如文献[19]选取了颜色特征、纹理特征以及方向梯度直方图(Histogram of Oriented Gradient,HOG)特征,通过机器学习中的K临近算法(K-Nearest Neighbor,KNN)对特征进行分类。传统机器学习的主要缺点是在训练前需要进行特征工程,增加了工作量,也不能保证特征选取的合理性。深度学习网络可以自动学习图像的特征,从而进行端到端的分类学习,应对复杂监控场景下行人外观变化,改善传统机器学习应用于行人属性识别中存在的问题。将深度学习和传统机器学习相结合,可在马尔可夫随机场下训练核、带高斯核的马尔可夫随机场以及带随机森林的马尔可夫随机场进行属性识别[20]。现有的基于深度学习的行人属性识别分法大多采用卷积神经网络(Convolutional Neural Network,CNN),虽然该网络能更有效地提取出属性的细粒度特征,但是不能对属性和行人图像连续性建模,因此,识别准确度较高的循环神经网络(Recurrent Neural Network,RNN)架构被提出。
通过总结基于深度学习的行人属性识别领域中已有的研究进展,分析对比不同算法的优缺点。介绍常用的行人属性识别数据库及评价指标,并对行人属性识别技术的发展趋势进行展望,指出该领域的未来研究方向。
1 基于深度学习的行人属性识别方法
基于深度学习的行人属性识别方法大致可分为常规网络、部件分割、注意力机制和序列检测等4类。下面介绍4类方法的基本原理。
1.1 基于常规网络的方法
基于常规网络的方法是行人属性识别方法中最基础的方法,该类方法比传统机器学习方法的识别率明显提高。常用的卷积神经网络有LeNet[21]、AlexNet[22]、计算机视觉组[23](Visual Geometry Group,VGG)、ResidualNetwork[24]、GoogleNet[25]和Dense Network[26]等。这些网络有很强的特征表示能力,图像的不同特征可以由多个不同的卷积核提取出来。图1为一个简单的行人属性识别过程。将监控场景中提取的行人样本输入端到端的CNN中提取图像特征,输出的特征向量长度与需要识别的属性数目相同,经过交叉熵损失函数对网络参数进行更新与训练,最后输出多个行人属性标签。
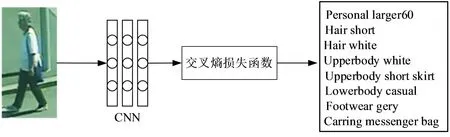
图1 行人属性识别过程
DeepSAR和DeepMAR两个对比网络均共享主干网络,包含5个卷积层和3个全连接层[27]。DeepSAR网络被用于单独预测每个属性,DeepMAR网络则考虑到属性之间的关联性,利用带有权重的交叉熵损失函数进行预测,其计算表达式为
(1)
其中:

He[28]等人采用残差网络[24]作为共享网络,使用自适应加权的损失函数进行所有属性的预测任务,其计算表达式为
(2)
其中:λj为第j个属性的权重值;Ii为训练的第i个图像;Lij为第i个图像的第j个属性的真实标签;φi(Ii;Θ)为经过网络操作Θ.<·>的每个图像的属性预测,Θ为神经网络参数。每K次迭代更新权重,但关键问题是很难衡量哪个任务最重要。损失函数的改进说明新的损失函数对于行人属性识别任务是很有必要的。
上述方法均是采用将整幅图像输入到基础网络中提取属性特征,并没有考虑到图像中的复杂背景对行人细粒度特征的影响,依然没有解决根本问题。Zhou等[29]考虑到了这个问题,将弱监督目标检测技术引入到行人属性识别任务中,该方法不仅可以预测属性的存在性标签,还可以对属性进行定位,为进一步的识别提供位置信息。
1.2 基于部件分割的方法
基于部件分割的方法是将行人分成几个部位进行识别,从而可以更好地提取颜色和纹理特征[30]。Zhu等[31]将整个行人图像分成15部分,分别送入到同一个CNN提取特征,采用相应的局部部分进行特征融合,从而判断是否具有某个属性。例如,对于头发属性的判断,只需要选择肩以上的部分特征融合即可。
该类方法主要是结合局部和全局特征识别属性的细粒度特征。基于部件分割的行人属性识别网络训练流程如图2所示。行人属性识别的焦点集中在图像中行人区域的部分,把行人图像分割后,输入到局部特征提取网络中,再和全局网络提取的特征融合训练,以达到抑制嘈杂背景干扰的目的,提高行人属性识别的准确率。

图2 基于部件分割的行人属性识别网络训练流程
Zhang等[32]提出了一种用于深度属性建模的部件对齐网络,用poslets[33]检测出可能的行人部位,然后将网络提取的所有特征叠加起来,为每个属性训练一个线性支持向量机(Support Vector Machine,SVM)分类器,一定程度上缓解了遮挡问题。文献[34]则对人体姿势进行估计,产生人体关键点。根据人体关键点信息,利用卷积神经网络自适应的产生边界框,将身体全局图像转换为部分区域图像,全局特征和不同的局部特征相结合可学习到强大的特征表示。端到端的局部和全局的卷积神经网络[35]强调了位置和边缘信息,此方法的目的主要是让背景和目标分离,只关注行人,减少背景对行人特征提取的影响。此外,还有将部件和序列检测结合起来进行行人属性识别的方法,在几个常用行人属性识别数据集上实验,也都取得了不错的识别效果[36-38]。
1.3 基于注意力机制的方法
基于注意力机制的方法就是关注于感兴趣的区域,选择一个具有代表性的局部特征进行下一步的跟踪。
细粒度特征在很多任务中可见,如图像识别、语义分割等,人们会针对于自己的问题从各个方向寻找解决办法。文献[39-41]是从特征融合角度进行改进的方法。现阶段,深度学习已成为特征提取的首选方法。在实际问题中,图像的细粒度特征分布复杂,划分的部件不一定适合其他图像,这样实现起来的效果肯定会不理想。文献[42-46]从网络结构上关注行人的细粒度属性。如Liu[42]等人为解决图像多尺度的问题提出HPNet网络,该网络能够捕捉从低级到高层语义级的多个关注点,主要过程是先用主网络(M-net)提取全局特征,再用多方向注意网络(AF-net)提取多个分支的不同语义特征,最后进行特征融合。
卷积神经网络虽然在识别性能上有明显提高,但还是存在一些客观问题。例如,训练样本中数据的类别不平衡,将会使网络模型的效果下降,考虑到这一不可忽视的问题,Sarafianos等[45]使用注意力聚合机制进行行人属性识别,通过引入网络对不同层的信息聚合帮助模型学习到更多具有判别性的特征,并且对属性的不平衡进一步研究,用带有加权变量的focal损失函数在处理属性不平衡上有着更好的性能。还有一些将空间注意、标签注意和行人注意联合起来学习的基于注意力的行人属性分析[47]也取得了不错的结果。
1.4 基于序列预测的方法
利用深度学习找到对应位置上的属性识别方法,是属于多标签分类的问题,而多标签分类问题表现出很强的标签依赖关系[48]。使用RNN可以显式地建模标签依赖关系,利用长短时记忆(Long Short-Term Memory,LSTM)网络可在一定程度上减轻RNN存在的梯度消失问题。LSTM的结构如图3所示。LSTM单元接收上一时刻的输出隐藏状态和当前输入,通过输入门、遗忘门以及输出门更新状态,并输出当前结果。其中:遗忘门决定上一时刻的信息是否需要遗忘;输入门决定当前时刻的信息是否需要保留;输出门用于控制有多少信息从忆单元传递到下一时刻的隐藏状态。

图3 LSTM单元结构
因此,有方法采用基于CNN-LSTM的编码-解码框架,建立属性与LSTM模型之间的相互依赖性和相关性。此方法用于行人属性识别任务上的过程如图4所示。

图4 基于序列预测的行人属性识别过程
Wang[49]等提出将CNN和LSTM结合,为了充分挖掘属性上下文信息和属性之间的关系,采用序列对序列模型处理此问题。首先,把给定的行人分割成m条水平带,形成区域序列,然后利用LSTM网络以顺序的方式编码。此方法在PETA数据集上取得了85.67%的识别准确率。Zhao[37]等则是先把属性按位置分组,比如头部属性包括发长、眼镜和帽子等,再采用人体关键点检测技术,融合全局和局部特征,利用LSTM对属性组中的空间和语义相关性进行建模。该混合框架在PETA数据集上取得了86.7%的识别率。为了更好地利用属性的空间相关性,Xin等[46]采用了(Convolutional Long Short-Term Memory ,ConvLSTM)网络,相比于LSTM,此网络在建立时空关系上有更好的效果。通过卷积神经网络提取特征图,再将提取的特征映射逐个组地输入到ConvLSTM中,并产生基于属性的注意力映射。基于循环神经网络的方法能够很好地利用属性标签和时间相关性对行人图像特征建模,但其识别准确率还有待提高。
2 数据集和评价指标
行人属性识别方法性能的评估,需要在行人属性数据集上分析比较。数据集在行人属性识别中发挥着重要的作用,常用的行人属性识别数据集有PETA(PEdesTrian Attribute)、RAP、PA-100K和Market-1501。下面介绍以上4个数据集以及衡量属性识别效果的常用评价指标,并对部分方法在PETA和RAP数据集中的实验结果进行分析对比。
2.1 数据集的介绍
PETA[19]数据集是2014年发布,由10个公开的小规模数据集构成,数据集图像如图5(a)所示。整个数据集由19 000幅图像组成,分辨率从17×39到169×365不等,共包含8 705个人,每个行人样本分为61个二进制和4个多类属性,其中,训练集有9 500个图像,1 900张用于验证和7 600张用于测试。但是,PETA数据集中一个人的样本仅通过随机选取注释一次,共享相同的属性,导致其他一些属性被忽略。虽然这种方法在一定程度上是合理的,但并不十分适用于视觉感知检测。
RAP[50]数据集来自真实的室内监视场景,数据集包含26个摄像头拍摄的图像,如图5(b)所示,其包含41 585个样本,分辨率范围从36×92到344×554不等,其中,有33 268幅图像用于训练,剩下的用于测试。每个样本图像含有69个二进制属性和3个多类别属性,共72个细粒度属性。此数据集对不同身体部位进行标注,对属性的标注比较详细。
PA-100K[42]数据集由598个真实的室外监控摄像头采集到的图像构成,如图5(c)所示,其包括100 000幅行人图像,分辨率从50×100到758×454不等,目前是行人属性识别的最大数据集。整个数据集被随机分成训练、验证和测试集,比例为8∶1,由26个属性组成,标签为0或1,分别表示是否存在相应的属性。
Market-1501[51]数据集是由清华大学一家超市前的6个摄像头收集,如图5(d)所示。在这个数据集中有1 501个行人和32 668个带注释的边界框。训练集有751个人,12 936张图片,测试集有750人,19 732张图像,分别对应于12 936和19 732幅图像。此数据集中的每个图像都带有27个属性的注释。

图5 4个数据集的行人图像示例
由行人属性识别的数据集可知,来自实真实监控摄像头下的行人图像的背景是很复杂的,除了图像的分辨率低等问题,还有姿势大幅度变化、光线变化、遮挡以及视角变化等复杂环境中非可控因素,如图6所示。图6(a)中行人姿势变化容易导致属性漏检或误捡。图6(b)中光线变化导致拍摄过程中视图颜色对比度差别大,容易错误识别属性。图6(c)中行人明显存在部分遮挡的情况,容易混淆目标。图6(d)由于拍摄视角的变化,行人所在位置不在整个图像的正中央,行人不是图像的主体,这就要求行人检测框能够灵活、准确地检测出行人。图6(e)是摄像机分辨率低,无法提取更多的细粒度特征,这种情况下需要对图像清晰化处理。

图6 复杂环境中的非可控因素
2.2 评估指标
衡量行人属性识别能力的两个指标为基于标签的评价指标[20]和基于样本的评价指标[53]。基于标签的评价方式是先分别计算每个属性正样本和负样本识别对的比例,再将二者平均作为每一个属性的准确度,所有样本的平均精度作为评价指标。但是,此评价准则独立地对待每个属性,忽略了在多属性识别问题中属性间的相关性。
基于样本的评价方式是根据每个样本对分对属性和分错属性的关系,分别计算准确率、精确率、召回率和F1-score等4个评价标准。
2.3 行人属性识别方法特点总结
基于常规网络、基于注意力机制、基于部件识别和基于序列检测等4类行人属性识别方法的技术和特点,如表1所示。

表1 4类行人属性识别方法的特点总结
表2对比了文献[27]、文献[37]、文献[44]和文献[52]等4种方法的各个评价指标。由表2可以看出,文献[37]方法平均精度值表现最好,该方法将部件分割和序列检测结合起来,在PETA和RAP这两个数据集上表现较均衡。在所有的评估标准中,4种方法在PETA数据集上的识别率比RAP数据集上的略高一些。不同场景下的数据集,存在明显差异,因此,需要提出适合于不同场景数据集的算法。

表2 典型方法性能对比结果
3 结语
对基于深度学习的行人属性方法以及近几年的研究热点进行了综述,并分析对比了基于常规网络、部件分割、注意力机制以及序列检测等4类方法的优缺点,表明虽然行人属性识别技术在几个大规模的数据集上取得了进展,但仍有一些实际性问题需要解决。因此,对行人属性识别方法未来研究方向展望如下。
1)基于深度学习的行人属性识别方法的数据集标注很重要。现有的数据集标注存在标注不明和标注错误的现象,将会影响行人属性识别技术的发展。如果在标注中考虑到位置信息,对不同位置的属性进行详细标注,利用人体部位信息,设计出更合适的网络,将会提升识别效果。
2)深度学习模型虽然能使算法精度得到提升,但针对于细粒度属性的识别,还需要设计特定行人属性识别网络架构。无论是基于部件的方法还是注意力方法,都是希望在属性特定位置上识别出来,这些位置信息将会回传给属性识别网络,怎样去融合这些结构,需要更多的研究。而加深深度神经网络,虽然性能得到提升,但是计算量的增加和模型参数更新时的繁琐问题,势必影响训练时的效率,仍需找到高速、有效的算法弥补上述不足。
猜你喜欢
成都信息工程大学学报(2021年3期)2021-11-22
中学生数理化(高中版.高考理化)(2021年5期)2021-07-16
意林(2021年5期)2021-04-18
中学生数理化(高中版.高考理化)(2020年11期)2020-12-14
扬子江(2019年1期)2019-03-08
软件导刊(2018年2期)2018-03-10
现代电子技术(2018年1期)2018-01-20
电脑知识与技术(2017年26期)2017-11-20
小天使·一年级语数英综合(2017年6期)2017-06-07
科技资讯(2017年7期)2017-05-06
