
面向云网融合的数据中心能效评估方法
2021-06-17 14:03龙赛琴黄金娜李哲涛裴廷睿夏元清
计算机研究与发展 2021年6期
龙赛琴 黄金娜 李哲涛 裴廷睿 夏元清
1(湘潭大学计算机学院 湖南湘潭 411105)
2(物联网与信息安全湖南省重点实验室(湘潭大学) 湖南湘潭 411105)
3(智慧网络湖南省国际科技创新合作基地(湘潭大学) 湖南湘潭 411105)
4(北京理工大学自动化学院 北京 100081)
(saiqinlong@xtu.edu.cn)
随着5G、云计算等新兴技术的大规模推广和应用,人类社会正加速进入数字化时代[1-2],智慧城市[3]的愿景以及社会生活水平的提高都对网络和计算提出了更高的要求[4],云网融合将助力互联网和新基建进入一个新的阶段,毋庸置疑,数据中心行业将由于云网融合的发展而更加繁荣.据报告显示[5],从2010—2019年,全球数据中心的总空间和容量都翻了一番,预计2020—2030年,数据中心空间将以每年13.8%的速度增长.科技是一把双刃剑,云网融合也不例外.一方面,云网融合给互联网的发展带来了新的机遇;另一方面,云网融合推动数据中心行业蓬勃发展的背后是其巨大的能源消耗.
信息和通信技术(ICT)行业目前消耗全球约7%的电力,预计到2030年将增长到13%[6].2018年,全球数据中心的耗电量约为205TWh,占全球耗电量的1%.此外,数据中心的碳排放量也令人瞠目,包括数据中心在内的ICT行业占全球二氧化碳排放量的2%.据统计,整个ICT行业增长最快的便是数据中心的碳足迹[7].数据中心规模的扩大和能耗的增加,不仅给数据中心运营商带来了巨大的能耗成本,也使整个地球面临沉重的环境压力,数据中心的能效研究已经成为近年来学术界和工业界关注的热点问题.
为了降低数据中心的能源消耗,有必要为数据中心的能源管理提供更科学的指标[8],能效指标是衡量数据中心能源效率的标准.《美国数据中心利用率报告》指出,有必要扩大对数据中心性能指标的研究,以更好地捕获效率,识别和理解需要改进的领域[9].因此,制定合理的数据中心能效评估标准是提高数据中心能效需要解决的首要问题,它不仅可以帮助数据中心运营商优化设施,为数据中心的设计和运维提供依据,降低运营费用,增强竞争力,还可以为不同数据中心之间的能效比较提供统一的标准,为互联网行业提供一个良好的能效评估竞争机制.
在数据中心能效评估问题上,单一的指标难以全面地衡量数据中心的能效,部分指标只能粗略地反映整个数据中心的能效,或者只能衡量某个局部,而不能全面且客观地反映数据中心整体的能效.数据中心是一个复杂而强大的系统,它需要多个指标从不同的角度评估其能源效率.目前,数据中心迫切需要一个整体框架,用一套统一的度量标准来评估能效,并发现数据中心在能效提升上潜在的缺陷.虽然在已有的研究工作[10-12]中有过这种尝试,但目前还没有被广泛认可的数据中心能效评估指标体系[7,13-15],也没有包含解释性指标和方法以评估数据中心可持续性等方面的通用监管框架[16-17].
基于数据中心能效评估的现状,本文提出采用云模型评估方法,将数据中心的多个能效指标整合在一起.本文讨论的前提是,能效指标值是在统一、标准化的测量方法下获得的.决定数据中心能效的因素从多个方面被考量,且该方法能够指导如何提高数据中心的能效.本文的贡献有3个方面:
1)研究了多指标能效评估方法,并考虑了混合加权方法为数据中心能效指标赋权,使数据中心能效评估结果更加科学.
2)提出了基于云理论的数据中心多指标融合的能效评估方法,巧妙地将能效评估结果由定量转化为定性.利用云模型的特点证明了评估结果的可信度,对比实验结果表明,该方法是科学可靠的.
3)利用灰色关联法分析了影响数据中心能效评估结果的重要因素,对数据中心能效的提高具备指导意义.
1 相关理论
本文中多指标融合的原理是从多个维度出发以全面评估数据中心的能效,通过建立多指标分析过程将复杂的总体问题转换为多个细小的问题,从而提高评估结果的有效性和可靠性.
云模型是一种不确定性识别模型,基于概率统计和模糊理论实现了定性概念与定量数据的转换.普通的云模型已被证明具有通用性和适应性[18],已逐渐发展成为具有完善理论的认知模型,它在时间序列预测[19]、空间数据挖掘[20]、综合评估[21]以及其他领域[22-23]都得到了广泛应用.利用云模型能够有效地完成数据中心能效分级过程中定量和定性的转换.
在数据中心的多指标能效评估中要考虑的不确定性有2类:1)随机性.不同数据中心的服务类型有差异且客户端存在动态且多变的用户行为,数据中心能效指标相关数据的监测与采集也存在一定的困难.2)模糊性.能效分级的概念是存在模糊性的,数据中心本身的复杂性等特性也都决定了数据中心能效无法精准评估.随机性与模糊性不可避免地与数据中心的能效评估联系在一起.利用云模型从多个维度对数据中心的能效进行评估,不仅克服了单一指标的不足,也兼顾了数据中心能效评估存在的随机性与模糊性问题.
云模型主要由期望值(Ex)、熵(En)、超熵(He)这3个云数字特征组成,这3个特征值被用来描述整体概念.一个数字特征为(15,4,0.3)的正向云模型如图1所示:

Fig.1 Standard normal cloud model图1 标准正态云模型
云模型的定义为:假设有一个用精确数值表示的定量论域Z,C是Z上的一个定性概念,如果论域Z中的随机数x∈Z,且x是有稳定倾向的定性概念C的一个随机实现,样本值x满足x~Normrnd(Ex,En′2),并且x对C的隶属度满足He2),那么x在Z上的分布称为云.
虽然云模型评估充分利用了云模型所包含的信息,但是它没有考虑实际评估中不同指标对数据中心综合能效的影响,考虑到数据中心能效指标的重要性存在一定差异,有必要将指标权重与云模型相结合.赋权通常有2种方法:主观赋权和客观赋权.主观赋权是基于人们对事物的理解、经验和知识,结合具体的判断规则,为不同的指标设定权重,存在一定的主观性.客观赋权是根据数据样本来获得相应的权重,存在脱离实际情况的风险.本文采用了主客观相结合的方法为数据中心指标设定权重,弱化单一赋权方法的不足.层次分析法(AHP)[24]是美国匹兹堡大学运算学家Saaty教授早在20世纪70年代初提出的一种主观赋权方法,它是对定性问题进行定量分析的一种灵活实用的多标准制定方法.熵权法[25]是一种有效的客观赋权方法,被广泛应用于工程技术、社会经济等领域.这2种方法的结合被称为最优赋权法.
由于得到能效评估的等级结果同现有的方法一样都仅能起到监管作用,而不能确定影响数据中心能效的薄弱环节,对于能效的改进缺乏意义,因此引入了灰色关联方法对能效评估的结果进行分析,从而利用评估结果来改进能效.此外,灰色关联分析适用于小样本评估,尤其适用于不易获得的数据.数据中心往往由于测量上的困难缺乏有效的数据,因此应用灰色关联分析法到数据中心的能效评估中极具优势.
灰色关联方法[26-28]通过研究数据关联性大小(母序列与特征序列之间的关联程度),通过关联度(即关联性大小)度量数据之间的关联程度.在系统发展过程中,如果2个因素的变化趋势一致,则同步变化程度越高,即2个因素的相关性越高,反之相关性越低.因此,灰色关联方法可以帮助研究人员分析不同能效指标对评估结果的影响程度,从而对数据中心的能效进行有针对性的改进.
2 云-灰色关联能效评估模型
本文中将能源效率分为5个等级,即高能效(等级Ⅰ)、较高能效(等级Ⅱ)、中等能效(等级Ⅲ)、较低能效(等级Ⅳ)和低能效(等级Ⅴ).因为数据中心是极其复杂的,难以对数据中心的能效评估做极其精确的要求,分级更有利于数据中心行业的规划和监管.根据模型计算结果确定数据中心能效等级,具体的评估过程如图2所示:
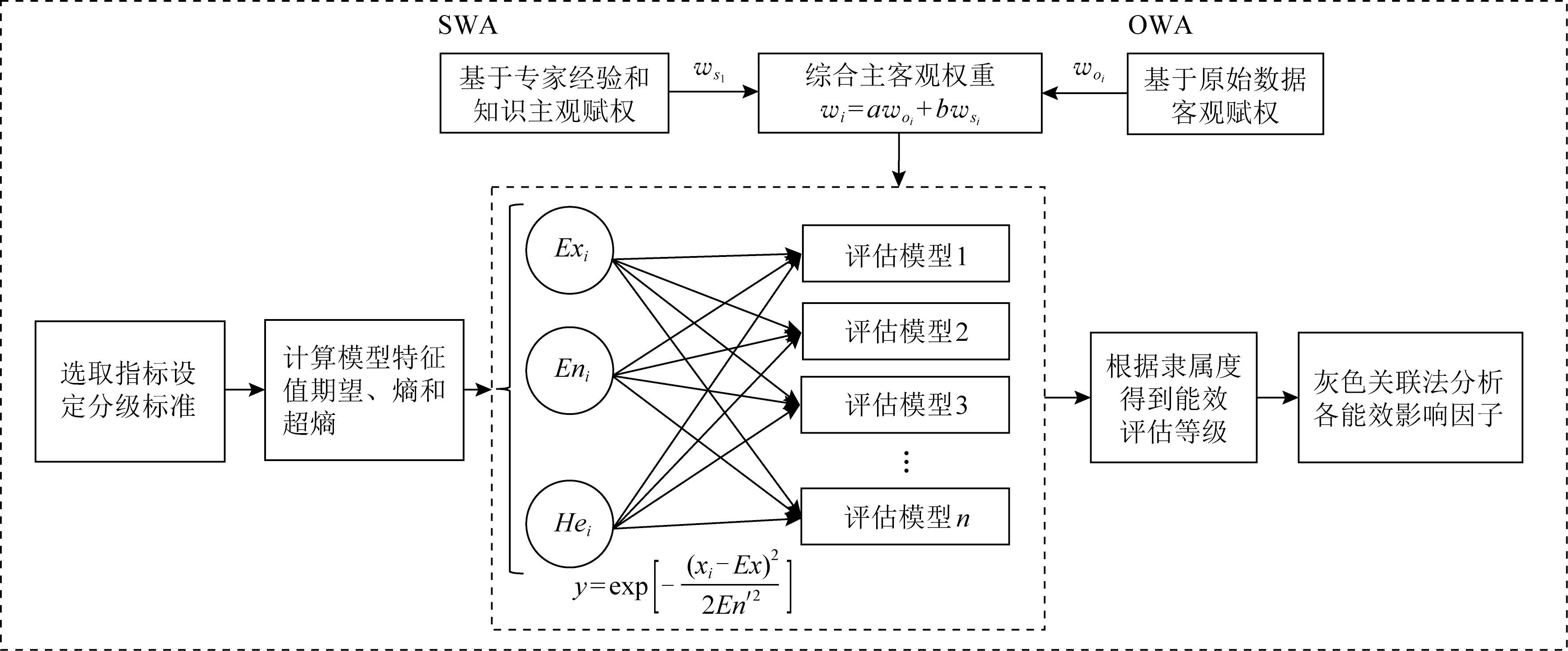
Fig.2 Energy efficiency evaluation model of data center图2 数据中心能效评估模型
首先,选取指标建立能效评估体系C={c1,c2,…,c n},其中n表示指标的个数,为每一个能效指标设置相应的能效分级标准L={Ⅰ,Ⅱ,Ⅲ,Ⅳ,Ⅴ}.根据分级标准对应的双边边界,确定云模型的特征值,即期望(Ex)、熵(En)和超熵(He),得到用于评估各个指标的云模型.
在计算样本的隶属度之前,有必要先确定指标的权重w=(w1,w2,…,w n),n是指标个数.在综合了主客观权重得到综合权重w i之后,计算出综合隶属度U p,k(样本p属于等级k的隶属度).将样本数据代入能效评估模型,样本数据和权重被综合到隶属度模型中计算得到综合隶属度,计算得到的max{U p,k}对应相应的能效等级.最后,基于综合隶属度和各能效指标分析各能效因子对数据中心能效评估结果的影响.
2.1 数据中心能效指标的选择
数据中心的能耗大致分为2部分:IT设备的能耗和基础架构的能耗.通常,数据中心中最耗能的部分是IT设备,其次是冷却系统和其他辅助设备.典型数据中心的电力分配如图3所示:

Fig.3 Power delivery in a typical data center图3 典型数据中心的电力分配
数据中心的电力来源通常来自电网或备用发电机,输入到数据中心的能量将转换到它驱动的组件上,这些转换由于效率低而导致能量耗损.在某些数据中心与其他业务并不独立分开的企业,数据中心的能源消耗与办公室及生产消耗是没有严格区分的,因此,数据中心的能耗极为复杂.
目前研究人员已经研发了数百个数据中心的能效指标[29-30],美国的技术报告[31]提供了与现有数据中心相关的能耗测量指标的相关列表,这些指标从不同的粒度衡量数据中心的能源效率.由绿色电网开发的电力使用效率[32](power usage effectiveness,PUE)指标得到了国际上的广泛认可,但它比较粗略,并不能完全揭示数据中心的能效.具体来说,由于计算资源的低效利用而造成的能源浪费还没有得到广泛的研究.因此,PUE能否继续领导能效是令人质疑的[33-36].数据中心行业还引入了不同的性能指标来衡量和比较数据中心的性能和效率,如数据中心单位能源的性能(data center performance per energy)、ASHRAE性能指标[37],以及其他可用于评估整个数据中心或数据中心的各个子组件(散热、IT、电源)的指标.这些子组件与总能源使用,如水使用或碳排放以及子系统效率(例如温度分布)有关[38].数据中心能效指标的选择应遵循7个原则:
1)指标是可测量的,并且需要独立于硬件设备.如果它们无法测量,至少可以精确地估计.
2)指标是独立的,不同指标之间没有重叠.
3)指标是全面的,指标应该能够体现其衡量的功能系统能效,能够整合数据中心的所有能效影响因素.
4)指标应以优化数据中心能源效率为导向,反映数据中心能源效率,并有可追溯的优化方向.
5)指标的测量不能消耗过多的资源,同时又不能影响正常的业务.
6)指标的度量尺度和粒度需要满足实际的评估需求.
7)指标可以有效地度量多个数据中心的性能,并且是可推广的.
基于上述7个原则选取了5个数据中心能效指标,这5个指标涵盖了影响数据中心能耗的各个方面,能够综合评估数据中心的能效.这5个指标如下:
1)供电负载系数(powersupply load factor,PLF).PLF是数据中心供配电系统的耗电与IT设备耗电量的比值.

其中,Ppower是供配电系统的耗电量,PIT是IT设备消耗的电量.
2)制冷负载系数(cooling load factor,CLF).CLF被定义为数据中心的制冷设备功耗与IT设备功耗的比值.制冷是数据中心能源消耗的主要来源之一,降低冷却能耗是提高数据中心能源效率的关键.
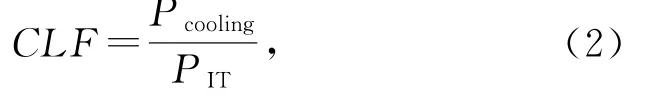
其中,Pcooling是制冷设备所消耗的能源.
3)其他因素的能源使用效率(other power usage effectiveness,o PUE).o PUE是指除主要设备外所消耗的能源,例如IT设备、制冷设备及供配电设备的照明、消防、监控等.

其中,Pother是辅助设备例如照明所消耗的能源.
4)二氧化碳使用效率(CO2usage effectiveness,CUE).CUE是一个衡量数据中心碳足迹的可持续性指标.对于使用电网发电的数据中心,CUE被定义为二氧化碳排放与IT设备使用能源的比值[39].

其中,CO2emission是数据中心的二氧化碳排放量,Annual kWh IT load是IT设备一年的能耗.通常根据二氧化碳排放因子CEF和PUE值计算出来.
5)服务器电力使用效率(server power usage effectiveness,sPUE).sPUE是IT设备消耗的电力与服务器消耗的电力的比值.

其中,Pserver是服务器所消耗的电量.
2.2 能效指标赋权
对能效指标进行主观赋权需要一定的专家知识和经验,对客观现实进行主观判断使专家意见和客观事实有效地结合起来.本文的主观赋权法原理来自层次分析法.首先,将主观定性的判断转化为定量的数值,元素的相对重要性是用数学方法计算的,由于指标都在同一层次上,因此没有对指标进行分层.将所选取的能效评价指标两两比较,根据1~9标度法创建评判矩阵A.
根据矩阵运算的知识,可以将各因子的权重系数看作一个特征向量,如果最大的值是λmax,那么特征向量w s能够根据式(6)得到.特征向量w s中的元素w s1,w s2,…,w sn就是主观权重.

一致性指标CI计算为

其中,n为矩阵的大小.n对应唯一的随机一致性指标,可以通过查表得到,如表1所示.表1中RI表示随机一致性指标.

Table 1 Random Consensus Index表1 随机一致性指标
一致性比率CR计算为

当CR<0.1时,可以认为所构造的比较矩阵是完全一致的,所得到的权值是合理的;否则主观赋值权重存在不一致问题,需要调整矩阵元素直到CR<0.1.
如果能够通过一致性检验,那么求得的特征向量即为各能效指标的权重向量.能效指标的主观权重计算如算法1所示.
算法1.主观赋权算法(SWA).
输入:评分矩阵A、随机一致性指标RI;
输出:主观权重w s、一致性比率CR.
①计算评分矩阵A的大小n;
②计算评分矩阵A的特征值λmax;
③计算特征值对应的特征向量w s;
④根据式(7)计算一致性指标CI;
⑤根据式(8)计算一致性比率CR;
⑥输出权重结果w s、一致性比率CR.
客观赋权法是通过数学方法确定权重的一种方法,它考虑了原始数据之间的关系.它的判断结果不依赖于人的主观判断,具有较强的数学理论基础.本文中客观赋权法采用的是熵权法,熵权法根据测量值的可变性来确定目标权重.
如果度量的信息熵较小,说明度量的变化程度较大,能够提供的信息更多.在综合评估中具有更重要的作用和更大的权重.相反,一个度量的信息熵越小,表示该度量提供的信息越少,权重也就越小.
由于不同指标的维度不同,首先必须对指标数据进行标准化处理.有2种类型的度量标准,正向指标(数值越大越好)和逆向指标(数值越小越好).标准化方法见文献[40].
假设有m个数据中心和n个指标,x ij代表第j个数据中心的第i个指标(j=1,2,…,m;i=1,2,…,n),在计算熵值之前,需要对样本数据进行归一化[25].根据信息论中信息熵的定义,数据的信息熵计算为

其中,P ij表示第j个数据中心第i个指标值的占比,P ij计算为
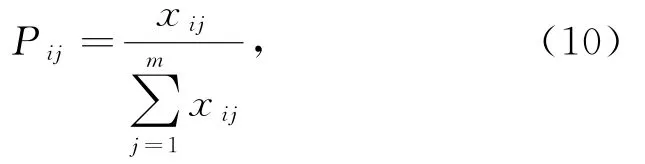
基于熵值法的权重为
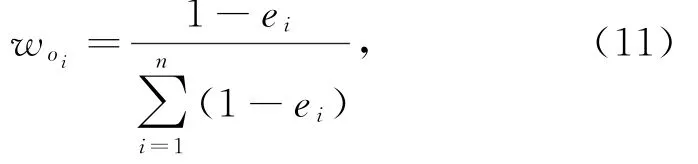
其中,e i表示第i个指标的熵值.
客观权重的计算如算法2所示.
算法2.客观赋权算法(OWA).
输入:样本数据X;
输出:客观权重w o.
①对数据进行无量纲化处理;
②for每一个样本do
③ 根据式(9)计算能效指标的熵值e i;
④end for
⑤for每一个指标do
⑥ 根据式(11)计算权重w oi;
⑦end for
⑧输出客观权重的结果w o.
利用加法集成法[41],综合性权重w i计算为
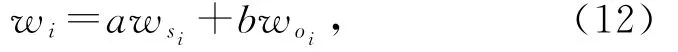
2.3 云评估模型
多指标融合原理是将云模型计算得到的隶属度与权重相结合.在每个(Ex,En,He)云模型中,Ex表示某一云数据中心能效水平的期望值,可以理解为云模型的重心;En表示该指标定性概念的不确定性;He为云生成过程中数据中心能效指标的超熵,表示熵的不确定性.

等级边界处的值是从一个级别到另一个级别的转换值,它应该同时属于2个等级且均有50%的可能性,因此式(14)成立:
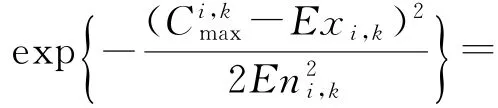
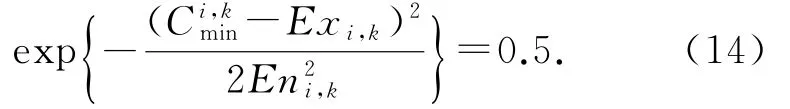
将式(13)代入式(14),那么:
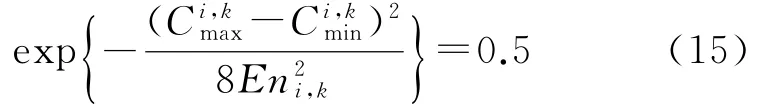
化简,即可得到:
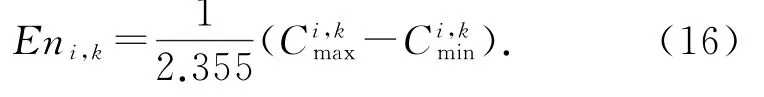
He i,k作为熵值不确定性的度量,通常是根据实际情况结合经验取值.本文中考虑实际情况并反复实验最终确定He=0.000 1.如果取值过大,隶属度的随机性也会越大,评估结果不稳定.如果取值过小,则云滴的离散度过小,不符合实际情况.产生一个随 机 数 满 足它 满 足 正 态 分 布,输入样本数据x得到每个样本各指标c i在等级k处指标的隶属度为

将各能效指标的权重进行组合,计算综合隶属度:
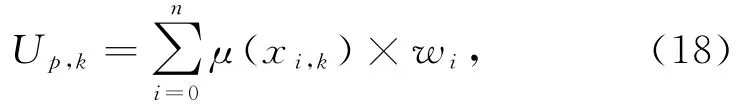
其中,n为能效指标的总数.样本p的每个指标隶属等级k的隶属度根据式(17)计算得到.w i是根据式(12)计算得到的混合权重.对每一个样本p,每一个等级都有一个隶属度结果U={U p,1,U p,2,…,U p,k}.b k是等级j的分值,相应的评估等级的分值为{1,2,…,k},采用加权平均法得到综合评价分数r为
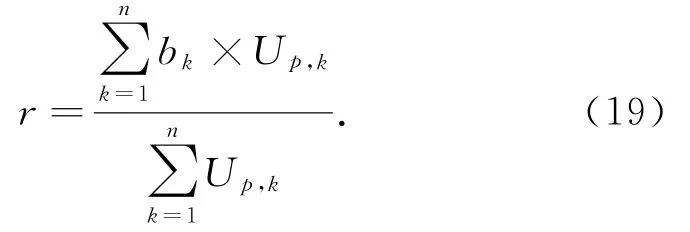
由于正态分布函数的参与,定量度量与正态云隶属度的计算过程具有一定的随机因素.因此,综合评价得分的期望值E r x为
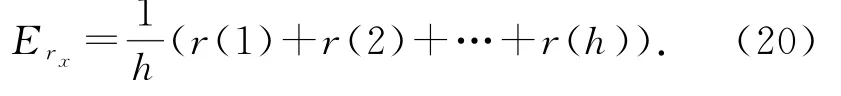
熵值E r h为
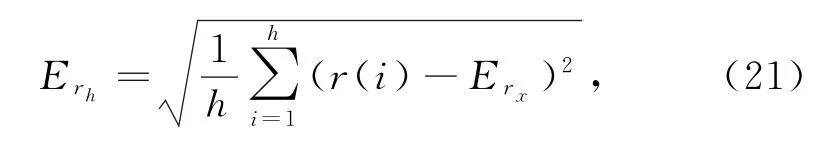
其中,h是计算次数,r(i)是第i次计算得到的综合评估分数.期望值为最能代表数据中心能效评估水平的评估得分.熵是评价结果离散度的度量,数值越大,评估结果越分散.能效评估的可信度因子θ为

θ值越大,评估结果的可信度越小;反之,评估结果的可信度越高.当评估结果可信时,样本p所属的级别K∗可以根据最大隶属度原则确定:

具体步骤总结如算法3所示.
算法3.云评估算法(CEA).
输入:样本数据X、分级标准;
输出:最大隶属度U p,k、可信度因子θ.
②调用算法1和2得到综合权重w i;
③fori=1:h/∗h为计算次数∗/
④ for每一个样本do
⑤ for每一个指标do
⑥ 根据式(13)计算期望Ex i,k;
⑦ 根据式(16)计算熵En i,k;
⑧ 为He i,k赋常量值;
⑩ 根据式(17)计算隶属度μ(x i,k);
⑪ end for
⑫ end for
⑬ 根据式(19)计算综合评判分数r(i);
⑮ end for
⑯取h次计算得到的E′r x结果的均值E r x;
⑰根据式(20),(21)计算综合评判分数的熵E r h;
⑱根据式(22)计算可信度因子θ;
⑲输出最终的最大隶属度U p,k,θ.
2.4 灰色关联分析
利用灰色关联分析方法分析特征序列与参考序列之间的关系.以云模型的综合隶属度作为参考序列,采用灰色关联分析法对云模型能效评估结果进行分析.灰色关联法分析的算法如算法4所示.
算法4.灰色关联算法(GRA).
输入:样本数据X;
输出:输出关联系数ξi(j)和关联度r i.
①初始化:算法CEA得到的隶属度为x0(j);
②fori=1:n/∗n为指标个数∗/
③ forj=1:m/∗m为样本数∗/
④λij=x0(j)-x i(j);
⑤ end for
⑥end for
⑪输出关联系数ξi(j)和关联度r i.
灰色关联分析同样要对数据进行无量纲化处理.对于m个数据中心的n个指标,对于某个特征序列X i={x i(j)|i=1,2,…,n,j=1,2,…,m},参考序列为X0={x0(j)|j=1,2,…,m},它用于判断评估等级的综合隶属度.灰色相关系数的计算方法为
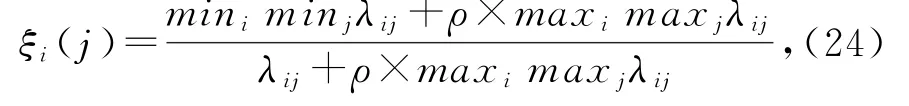
其中,λij=|x0(j)-x i(j)|,x i(j)代表第j个数据中心的第i个指标值.ξi(j)是第j个数据中心的第i个指标相对于参考指标的关联系数,ρ是一个分辨系数,ρ∈[0,1].ρ越小,关联系数间差异越大,区分能力越强.通常ρ=0.5.每个指标c i的关联度r i是关联系数的平均值,可以计算为

其中,m是数据中心样本的个数,ξi(j)是第j个数据中心第i个指标的能效评估结果的关联系数.
3 能效评估案例分析
3.1 数据来源
施耐德开发了一系列电力权衡工具[42].电力权衡工具是基于数据和科学的简单交互式工具,它使得在数据中心规划期间改变参数,试验场景变得很容易.本文使用一组权衡工具模拟具有不同配置的6个数据中心,具体的配置如表2所示.
根据专家的经验和调研及数据分布情况,对所选的5个指标(PLF,CLF,oPUE,CUE,sPUE)进行分级,分级结果如表3所示.

Table 2 Data Center Configuration表2 数据中心配置
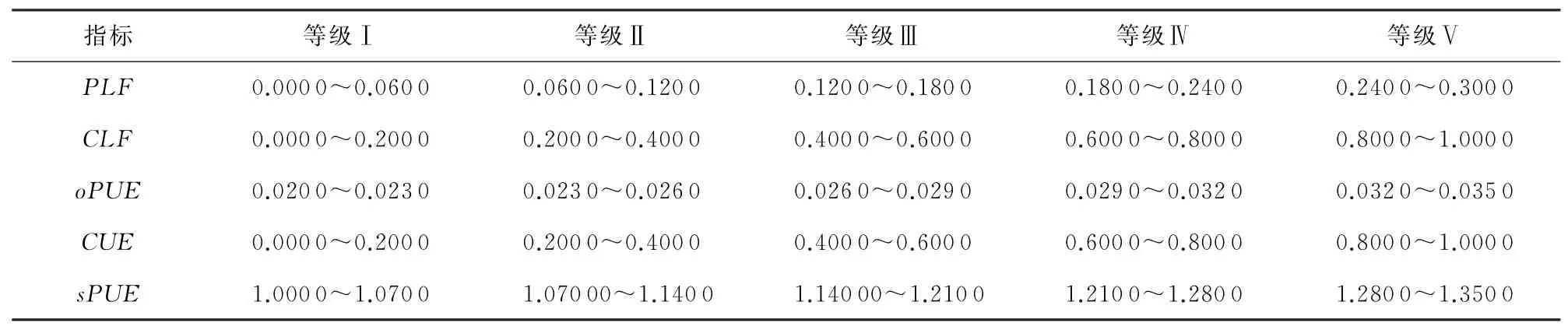
Table 3 Data Center Energy Efficiency Metric Classification表3 数据中心能效指标分级
结合能效评级标准,各指标对应的能效评级云图如图4~8所示.根据配置工具获得的数据,计算出数据中心评估指标体系中每个指标的具体数据,如表4所示.
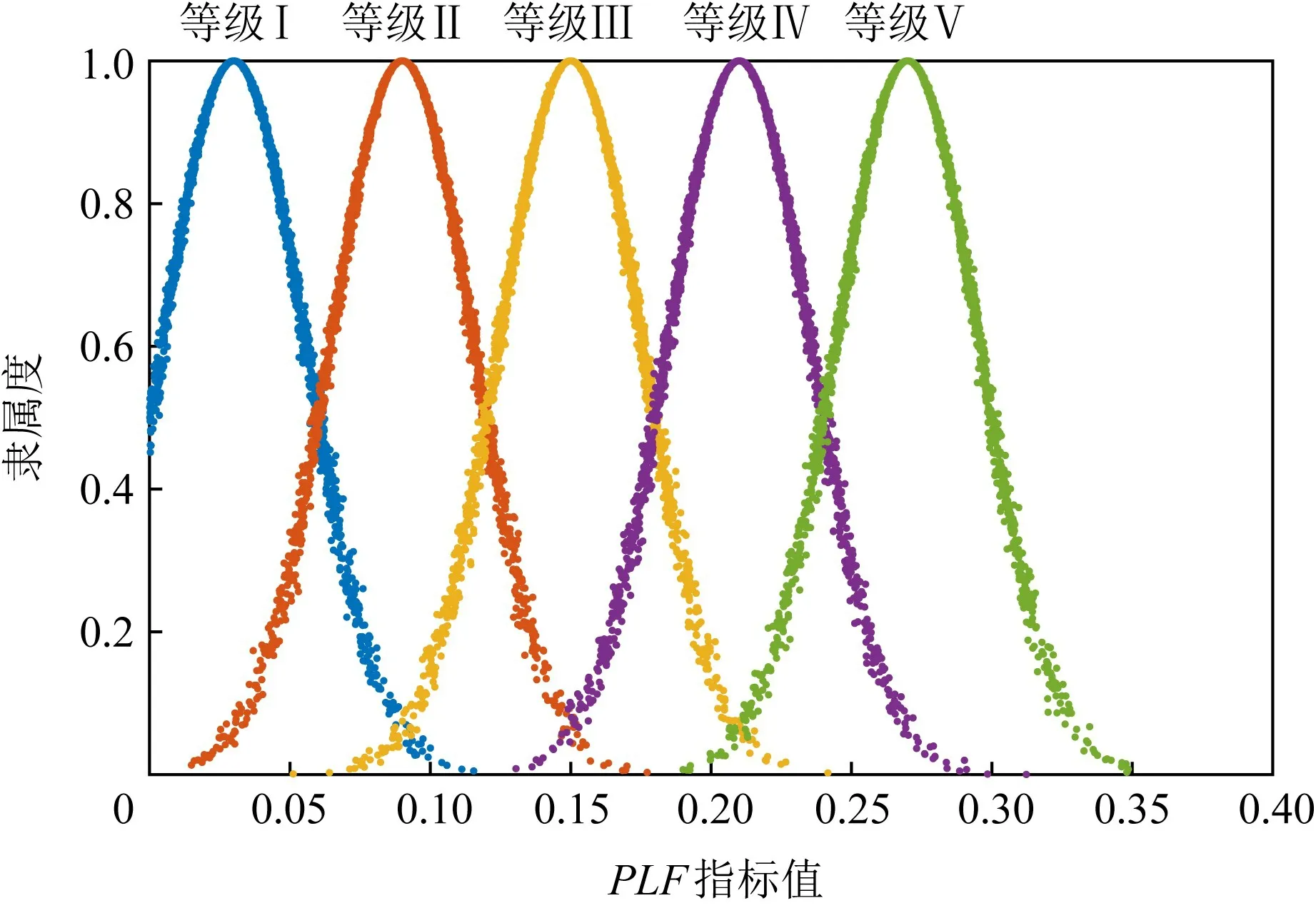
Fig.4 The cloud model of PLF图4 PLF的云模型

Fig.5 The cloud model of CLF图5 CLF的云模型

Fig.6 The cloud model of oPUE图6 o PUE的云模型

Fig.7 The cloud model of CUE图7 CUE的云模型

Fig.8 The cloud model of sPUE图8 sPUE的云模型
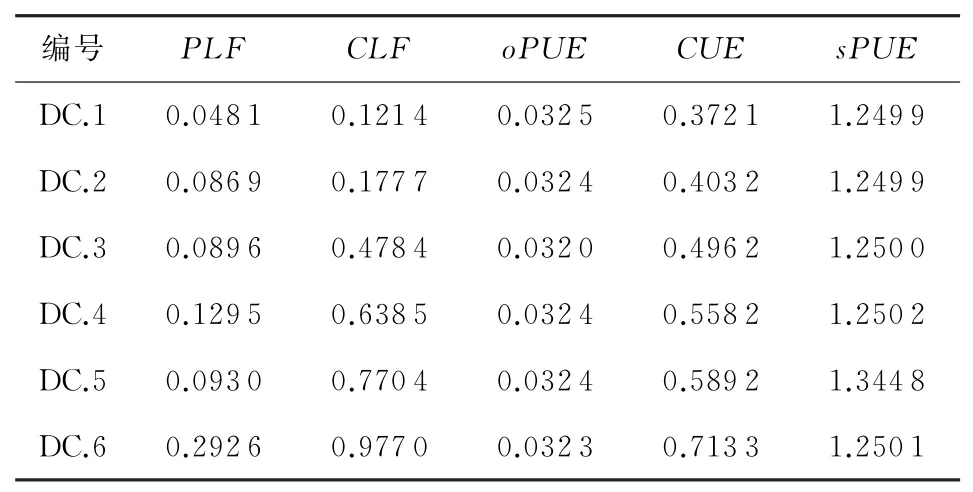
Table 4 Sample Data表4 样本数据
3.2 权重计算
根据综合权重法对数据中心的能源效率指标进行加权,由于客观加权是根据信息熵和样本数据的变异系数计算的,因此熵值较大时,由于其不稳定性,对结果的影响更大.熵值小的指标值由于不稳定性较低而对结果的影响较小.因此,可能存在重要指标权重较小的情况.因此,本文使用主观加权方法进行调整.使用1~9标度法对数据中心建立评判矩阵,结果如矩阵A所示:

根据评分矩阵A得到CI=0.0716,且一致性比率CR=0.063 9<0.10,因此一致性检验通过.计算得到数据中心能效评价指标体系各指标的综合权重,权重计算结果如表5所示:
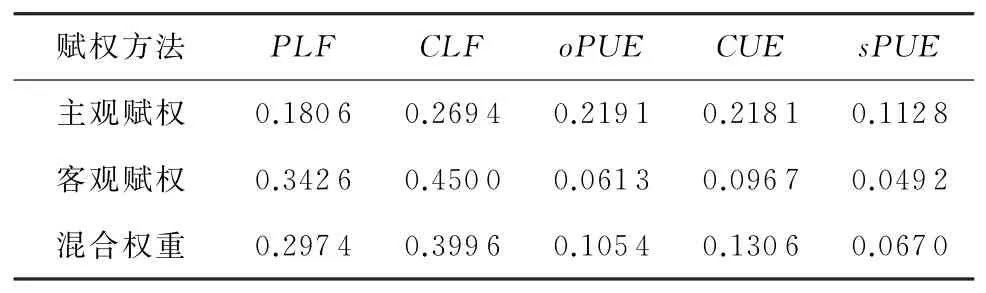
Table 5 Weighting of Energy Efficiency Metrics表5 能效指标权重
3.3 多指标能效评估
通过Matlab将样本数据引入评估模型进行统计计算,得到不同数据中心的能源效率评估结果.从表6中可以看到评估结果的置信因子θ<0.1,证明评估结果是可信的.评估结果如图9所示.
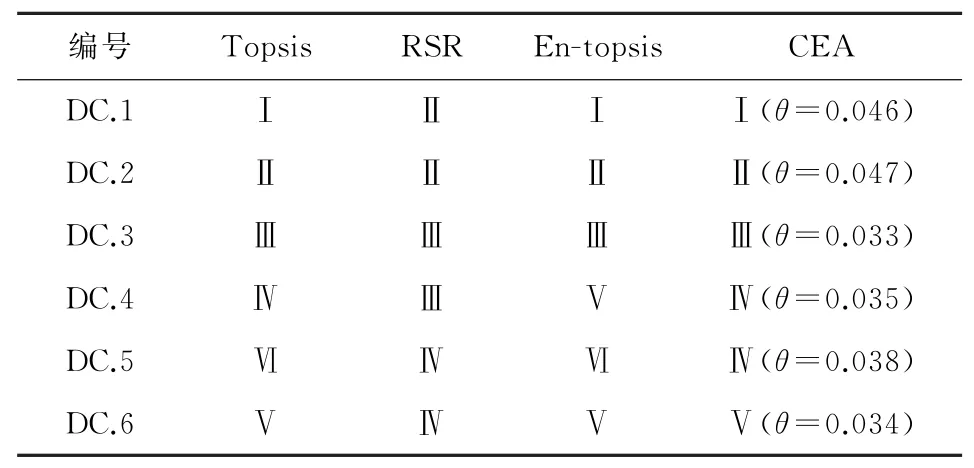
Table 6 Comparison of Different Evaluation Methods表6 不同评估方法的评估结果比较
为了进一步证明云能效评估方法的有效性,利用Topsis[43],rank-sum-ratio(RSR)[44-45]和entropy weighttopsis methods(En-topsis)[46-47]对数据中心能效进行了评估,比较结果如表6所示.其中Topsis和En-topsis得到的都是样本数据中心的排名,与本文的云能效评估方法(CEA)的等级结果趋势一致.RSR也将能效分为5个等级,它的评级结果与云能效评估结果相差不超过一个等级,即结果是相似的.这些方法的结果表明,云评估能效方法是可信的.
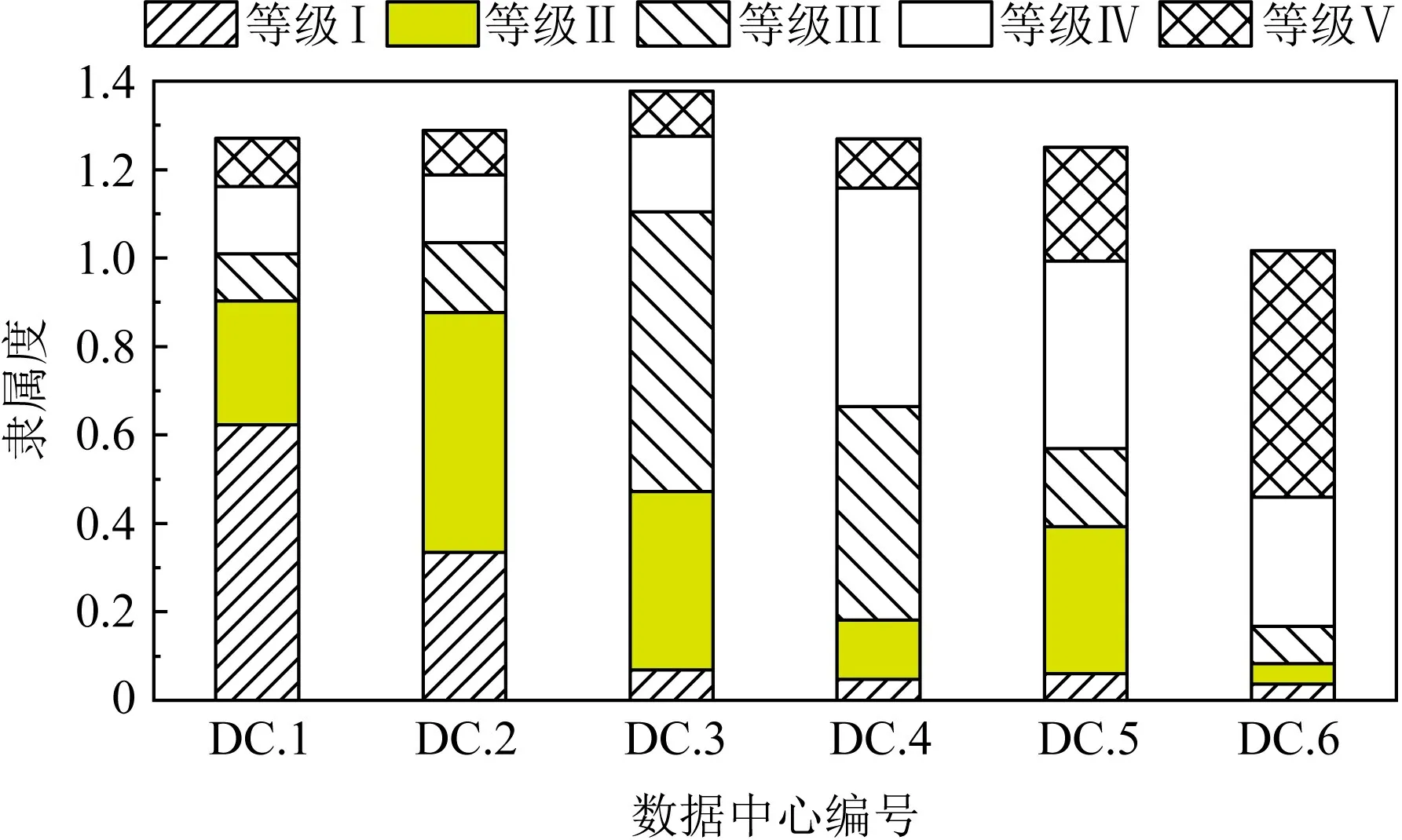
Fig.9 Comprehensive membership calculation results图9 综合隶属度的计算结果
Topsis和En-topsis在实际的评估过程中规范决策矩阵的处理比较复杂,不容易求出理想解,而RSR方法在使用的过程中有可能会损失一些数据信息,导致对数据信息的利用不完全.由于这些方法不如云模型在定性与定量转换上的有效性,且无法克服数据中心能效评估不确定性的特点,因此云模型的方法在数据中心的能效评估问题上是更具优势的.
3.4 能效指标影响因子分析
将隶属度作为母序列,指标作为特征值序列,利用灰色关联分析得到各指标和隶属度之间的关联度.各能效指标对能效评估结果的关联度如图10所示:
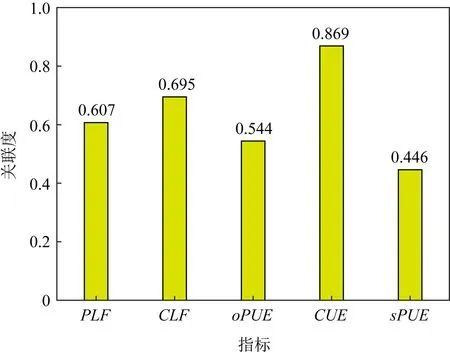
Fig.10 The relevance of each metric to the evaluation result图10 能效指标关联度
由图10可以发现CUE是一个高度相关的因素,其次是CLF.研究数据中心能效的根本目的是节约能源,实现可持续发展.碳排放控制是提高数据中心能效的重要环节,这意味着清洁能源在数据中心的使用将是未来发展的必然要求.该能效研究结果督促数据中心运营商使用更清洁的能源以减少数据中心的碳排放,提高能源效率.此外,CLF对能效评估的结果也有很大影响,这与行业内对数据中心能效的一般理解是一致的.
控制冷却能耗是提高数据中心能效的重要手段.数据中心必须配备足够的冷却设备以提供良好的环境条件来保证数据中心的正常运行,而冷却设备不仅消耗大量的能量,还产生大量的热量,如果数据中心冷却设备出现故障,IT设备过热,那么数据安全将受到威胁,也可能会给数据中心带来巨大的损失,选择一个安全且有效的制冷策略对数据中心运营商而言是一个巨大的挑战.相关性最小的指标是sPUE.但是当碳排放、冷却、供电和配电等能效影响因素都相对较好时,这一点不应被忽视.
影响数据中心能效的因素分析如图11所示.对于前4个数据中心样本,CLF是除CUE之外影响评估结果最大的因素.对于后2个数据中心样本,PLF因素对结果的影响甚至超过了冷却的影响,这意味着需要对数据中心的供配电设施进行优化,以提高数据中心的整体能效.根据评估结果,不同的指标对数据中心能效评估结果的影响程度不同.因此,不同数据中心在节能方面的优化重点也有所不同,数据中心运营商可以根据分析结果更有针对性地提高数据中心能源效率.

Fig.11 The correlation coefficient of each metric of each sample图11 样本各指标关联系数
4 结 论
数字时代已经到来,云网融合将使得数据中心行业迎来新的繁荣,而控制数据中心能耗的增长已经成为亟待解决的问题,为了更好地提升数据中心的能源效率,有必要使用多个指标从多个方面对数据中心的能效进行评估.本文从数据中心的能耗来源出发,分析了IT设备、冷却设备、供配电系统等.然后从各种数据中心能效指标中选取了5个重要的且有代表性的指标,这5个指标的组合可以综合评估数据中心的能源效率.
利用主客观加权相结合的方法对数据中心不同的能效指标进行权重分配,然后采用云模型方法融合不同的数据中心能效指标,得到综合的能效评估结果.最后,应用灰色关联分析方法对影响数据中心能源效率的重要因素进行了分析.实验结果表明:该评估方法能够有效地评估数据中心的能效.完成了能效指标从定量到定性的转换,并能够找到影响数据中心能效评估水平的因素,为数据中心能效提升提供了有利的途径和有价值的帮助.
猜你喜欢
社会科学战线(2022年5期)2022-07-23
锦绣·上旬刊(2022年2期)2022-05-16
心理学报(2022年5期)2022-05-16
民族文汇(2022年9期)2022-04-13
现代临床医学(2022年1期)2022-02-12
当代陕西(2020年17期)2020-10-28
家用电器(2020年7期)2020-10-26
家用电器(2019年6期)2019-09-10
人大建设(2018年5期)2018-08-16
证券市场红周刊(2018年3期)2018-05-14
