
一种多特征多模型的反欺骗语音系统
2021-06-16 02:40:34林龙晋
无线电工程 2021年6期
林龙晋,高 勇
(四川大学 电子信息学院,四川 成都 610065)
0 引言
声纹识别又称自动说话人识别(Automatic Speaker Verification,ASV),是生物识别中的关键技术。但随着ASV系统的普及,针对ASV系统的欺骗语音攻击也日益增多,如果欺骗语音成功通过ASV系统,会对系统的安全性能造成巨大破坏,ASV系统的安全性亟待加强。
国际上,每两年举办一次的ASVspoof大赛是目前检测欺骗语音规模最大、覆盖最全面的挑战赛,参赛者提交的反欺骗算法为欺骗语音检测系统提供了大量创新工作。目前,对于欺骗语音的检测,大部分的工作都集中于前端特征提取以及后端分类器设计两个方面。在前端特征提取上,Todisco M等人受音乐处理中的常数Q变换(Constant Q Transform,CQT)启发,提出了常数Q倒谱系数(Constant Q Cepstral Coefficients,CQCC)[6],该特征在低频段的频率分辨率高,在高频段的时间分辨率高,可以有效检测ASVspoof2015中的单元选择算法[7]产生的欺骗语音。Lantian Li等人使用逆梅尔倒谱系数(Inverse Mel Frequency Cepstral Coefficients,IMFCC)特征强调频谱高频区域的分析[8],在ASVspoof2017上获得了不错的效果。在后端分类器设计上,近几年的工作大多集中于神经网络分类器改进。Cheng-I Lai等人搭建了注意力机制扩张残差网络(Dilated ResNet)[9],在ASVspoof2017和ASVspoof2019上都取得了很好的效果。Moustafa Alzantot等人[10]使用了带dropout层的残差块构建的残差网络,将梅尔频率倒谱系数(Mel Frequency Cepstral Coefficients,MFCC)[11]、常数Q倒谱系数与短时傅里叶变换对数谱在残差网络上的结果进行融合,有效降低了欺骗检测系统的错误率。
本文使用了三角滤波器组的3种不同形式,每种形式的三角滤波器组对频域的侧重点不同,并使用了更大的分帧帧长以及帧移,增加快速傅里叶变换点数,增大了频率分辨能力,更容易发现真实语音与欺骗语音的不同点。后端分类器采用高斯混合模型(Gaussian Mixture Models,GMM)与残差网络模型(Residual Network,ResNet),通过组合不同前端特征与后端分类器构建不同的欺骗语音检测模型并将结果融合。相对单一特征、单一分类器设计的反欺骗语音系统,本文提出的方法更有效,错误率也更低。
1 三角滤波器组特征提取
1.1 语音信号预处理
在提取语音信号的特征前,需要对语音信号进行预处理,包括预加重、分帧与加窗3个步骤。
由于人的发声器官的特殊性,在发声过程中语音会受到声门激励与口唇辐射的影响,频率越高,语音信号的功率谱衰减越严重。预加重的目的是消除这些影响,补偿语音信号中被抑制的高频成分。语音信号可以通过一个高通滤波器完成预加重处理:
H(Z)=1-0.97Z-1。
(1)
语音信号具有短时平稳性,因此,需要通过分帧处理将语音信号分成较短的语音帧。在分帧前,通过截断、复制填充的方式将语音信号归一化到4 s的长度,然后采用2 048点的帧长,512点的帧移进行分帧处理,并加上汉明窗使语音信号获得周期性。帧长越大意味着频域分辨能力越强[12],这使得检测系统更容易发现欺骗语音与真实语音的不同。
1.2 滤波器组设计
基于三角滤波器组的特征提取是语音识别领域中的常用方法,比如MFCC就广泛应用于说话人识别中。提取MFCC的过程中使用的梅尔滤波器组是一组低频分布密集、高频稀疏的三角滤波器,可以将线性频率映射到符合人耳听觉感知的梅尔频率上,对语音信号的低频信息更加敏感。梅尔频率与线性频率的关系为:
fmel=2595×lg(1+f/700),
(2)
式中,f为真实频率;fmel为梅尔频率。考虑到欺骗语音与真实语音的差异可能不仅仅只存在于低频段,频域的其他区域也有可能发现这些差异信息。因此,对相同的一条语音信号,同时提取它的线性倒谱系数(Linear-Frequency Cepstral Coefficients,LFCC)以及逆梅尔倒谱系数(Inverse Mel-Frequency Cepstral Coefficients,IMFCC)特征以进行对比试验,相比MFCC,LFCC与IMFCC的差异在于分别使用了线性滤波器组与逆梅尔滤波器组,进行了不同的频率尺度变换:
flinear=f,
(3)
(4)
式中,flinear为线性滤波器组变换后的频率;fi-mel为逆梅尔频率;fmax为语音信号处理中的最高采样频率,根据奈奎斯特定理,一般设为8 000 Hz。线性滤波器组只是对原始线性频率的均匀细分,变换后的频率与原来的相等;逆梅尔滤波器组则是梅尔滤波器组的反转,低频分布稀疏、高频分布密集。3种滤波器组的结构如图1所示。

(a) 线性滤波器组
文献[13-14]表明,采用更多的滤波器个数可以显著增加检测性能,因此,对于梅尔滤波器组与逆梅尔滤波器组,本文使用120个滤波器进行实验,线性滤波器组则采用40个滤波器。
1.3 特征提取
语音信号提取特征的过程如图2所示。

图2 特征提取过程Fig.2 Feature extraction process
语音信号在预处理后,通过快速傅里叶变换得到频谱:
(5)
式中,xi为语音帧,i指语音帧的序号;N为傅里叶变换的点数,为2 048点,和语音帧长度相同;k为频谱上的频率序号。得到的频谱取绝对值后,送入不同的三角滤波器组中进行滤波,结果取对数:
(6)
式中,1≤m≤M,M为滤波器的个数,梅尔滤波器组与逆梅尔滤波器组的滤波器个数为120,线性滤波器组的滤波器个数为40。得到的滤波对数信号pi(k)通过离散余弦变换(Discrete Cosine Transform,DCT)完成特征提取:
(7)
式中,1≤n≤L,L表示倒谱系数个数,在本文提取的MFCC与IMFCC中L设置为23,在LFCC中设置成与滤波器个数相同的值,为40。
提取倒谱系数的一阶差分与二阶差分系数,并加入语音帧的对数能量参数,与原系数进行拼接得到最终的语音特征。
2 多分类模型与打分结果融合
在语音识别领域,常用的分类模型可以分成浅层模型与深层模型,浅层模型包括高斯混合模型(Gaussian Mixture Models,GMM)、支持向量机(Support Vector Machine,SVM)等,深层模型则是基于各种不同神经网络的分类器。本文在浅层模型中选择比较常用的GMM,在深层模型中选择残差网络(Residual Network,ResNet)作为分类器,对前端提取的MFCC、LFCC、IMFCC特征进行判别分类,并做对比实验。
2.1 高斯混合模型
在训练阶段,所有的真实语音全部用来训练真实语音的GMM模型,记为GMMB,相对地,伪造语音全部用来训练伪造语音的GMM模型,记为GMMS。随即在测试阶段,计算提取的语音帧特征Xi在2个GMM模型上的对数似然比(Log-likelihood ratio,LLR),如下所示:
LLR(Xi)=ln(p(Xi|GMMB))-ln(p(Xi|GMMS))。
(8)
每条语音在GMM上得到的打分结果通过计算所有语音帧的对数似然比并进行等权值加权平均得到。整个过程如图3所示。

图3 GMM模型的训练与测试Fig.3 Training and testing of GMM model
2.2 残差网络模型
由于预处理步骤中进行了语音分帧,一条语音提取到的特征是一个二维矩阵的形式,类似于一幅图像,可以用卷积神经网络(Convolutional Neural Networks,CNN)进行处理。一般而言,网络越深,学习的参数越多,对目标的判决也越精准,但过深的网络会造成梯度消失,使网络性能下降。残差网络能通过跳跃连接的方式解决这个问题,因此,本文参考了文献[10]中的网络设置,采用ResNet设计网络模型,结构如图4所示。

图4 ResNet结构Fig.4 The structure of ResNet
输入的语音特征在经过初始卷积层处理后通过4个ResNet基础块,每个基础块包括主支路与分支路。在主支路,对特征矩阵进行2次卷积处理,在分支路,只加深特征矩阵深度以使2条支路的矩阵大小匹配,2条支路求和后通过池化层输出,在这一过程中特征矩阵不断加深并降维。特征矩阵最后通过2个全连接层并使用Logsoftmax函数分别输出语音的真实概率与欺骗概率的对数值,两值相减就是ResNet模型的打分结果,这一过程类似GMM模型中的对数似然比的计算,如下:
Score(X)=ln(p(X|bonafide))-ln(p(X|spoof))。
(9)
以处理MFCC为例,ResNet模型参数如表1所示。
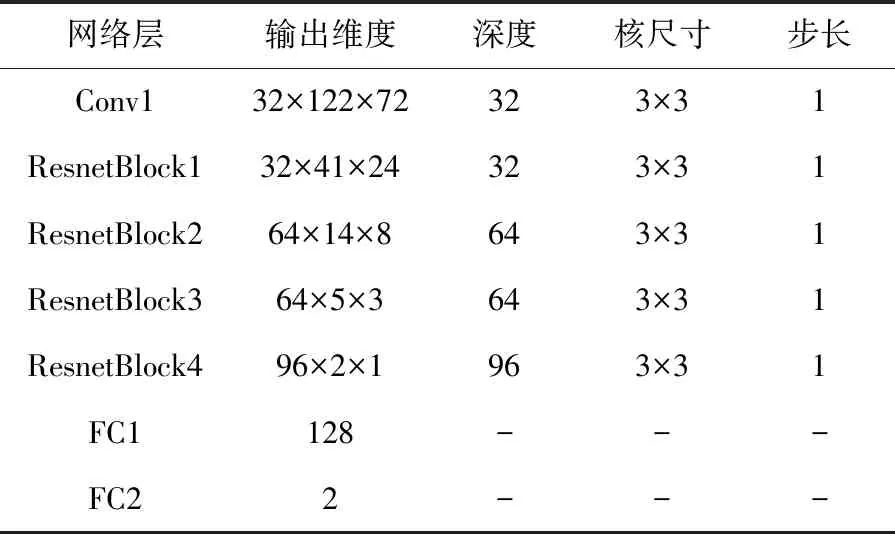
表1 ResNet模型详细参数Tab.1 The parameters of ResNet model
网络使用LeakyRelu函数替代传统的Relu函数,前者比起后者有更好的学习能力;在2个全连接层中使用了dropout层,比率设置为0.5,随机丢弃隐藏神经元来防止网络过拟合。
2.3 打分结果融合
浅层、深层模型的学习参数不同,对特征学习的着重也不同,由于2种模型最后给出的打分都是针对测试语音的对数似然比,可以将深浅层模型的打分结果通过等权重融合[15]的方式融合在一起;提取的MFCC、IMFCC与LFCC特征对语音频谱的侧重不同,在分类器模型中的表现也不同,通过打分融合的方式结合3种不同特征能达到特征互补的效果。多特征多模型的打分结果融合流程如图5所示。

图5 多特征多模型打分结果融合Fig.5 Fusion of multi-feature and multi-model score results
3 实验与结果分析
3.1 数据集
实验采用Asvspoof2019大赛的逻辑访问(Logical Access,LA)数据集[5]验证不同模型以及多特征多模型融合后的效果。Asvspoof2019的LA数据集基于VCTK[16]语料库,采用了108个说话人的语音样本产生欺骗语音,欺骗语音由文语转换(Text to Speech,TTS)以及语音转换(Voice Conversion,VC)中最先进的算法产生得到。所有说话人的真实语音与欺骗语音样本被互不相交地分配到训练集、开发集与评估集,其中,训练集与开发集使用了相同的6种欺骗语音产生算法(A01~A06),评估集中使用了13种欺骗语音产生算法(A07~A19)。评估集中的A16与A04、A19与A06是两对相同的算法,其余11种算法相对训练集而言是未知的算法。数据集中的语音样本采样率均为16 kHz,采样位数均为16 bit,详细设置如表2所示。
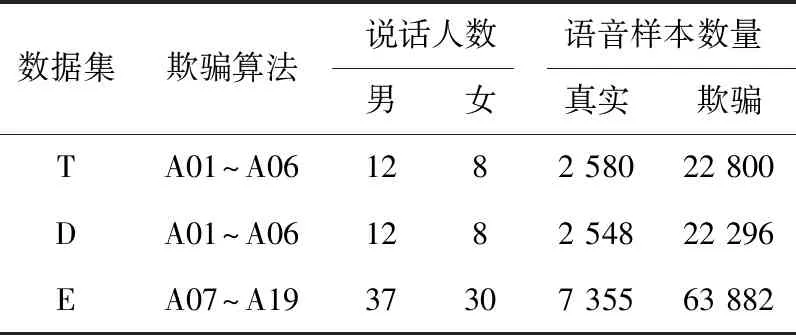
表2 Asvspoof2019LA数据集详情Tab.2 The detail of ASvspoof2019LA data set
T、D、E分别表示训练集、开发集与评估集。
3.2 模型评价指标
错误拒绝率(False Rejected Ratio,FRR)与错误接受率(False Accepted Ratio,FAR)是衡量检测系统的2个关键指标,前者指错误拒绝真实语音样本的概率,后者指错误接受欺骗语音样本的概率。一般使用等错误率(Equal Error Rate,EER)来代表检测系统的性能:
EER=Pmiss(θEER)-Pfa(θEER),
(10)
式中,θEER表示错误拒绝率Pmiss与错误接受率Pfa相等时的检测系统阈值。
Asvspoof2019大赛设置了参数固定的自动说话人识别(ASV)系统,与反欺骗语音系统(Counter Measures,CM)结合使用。为了表征整个系统的性能,Asvspoof2019使用了最小串联代价成本检测函数(tandem Detection Cost Function,t-DCF)[17]指标,t-DCF为:
(11)
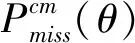
(12)

3.3 深浅层模型实验结果分析
以第2节的方法提取训练数据集的MFCC、IMFCC与LFCC特征,并分别训练GMM模型与ResNet模型。其中,GMM模型的混合度为512,ResNet的初始学习率为0.000 05,batch大小为32,一共训练100个epoch。模型训练完成后,分别在开发集与评估集上测试并获得打分结果。使用比赛官方的工具包计算模型的EER与t-DCF,如表3所示。
其中,CQCC-GMM-B与LFCC-GMM-B是比赛提供的2个基线系统,本文使用的LFCC-GMM模型相比LFCC-GMM-B使用了更大的帧长、帧移以及滤波器个数,增加了频率分辨能力,相比基线系统有一定的提升。从实验结果可以看出,6个模型融合的结果Fusion-6models表现良好,EER是所有模型中最低的,但在t-DCF指标上不如MFCC-ResNet模型,原因可能是其他表现较差的模型影响了最终融合的结果。
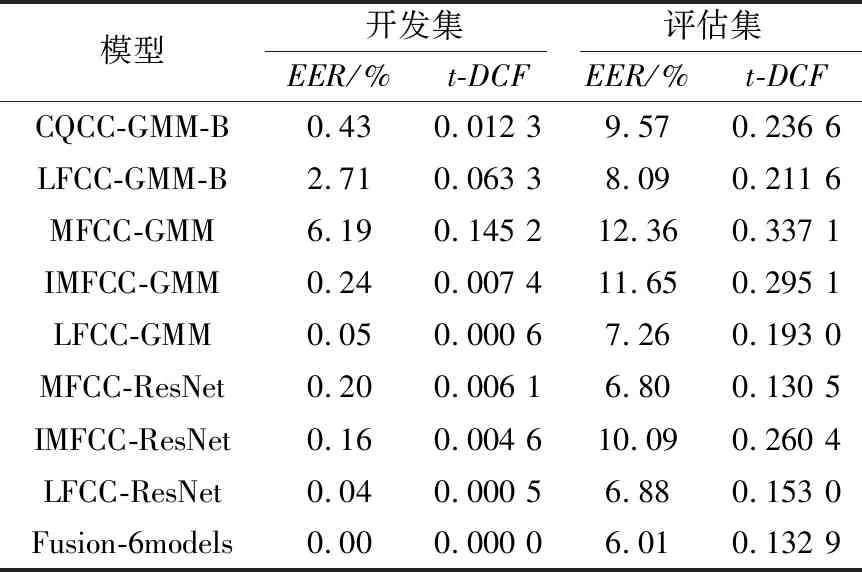
表3 不同模型在开发集与评估集上的EER与t-DCFTab.3 EER and t-DCF of different models on development set and evaluation set
3.4 不同欺骗算法效果分析
为了观察模型在面对已知与未知欺骗算法时的效果,单独提取评估集中的A07~A19产生的欺骗语音与真实语音混合,并计算t-DCF,结果如表4和图6所示。
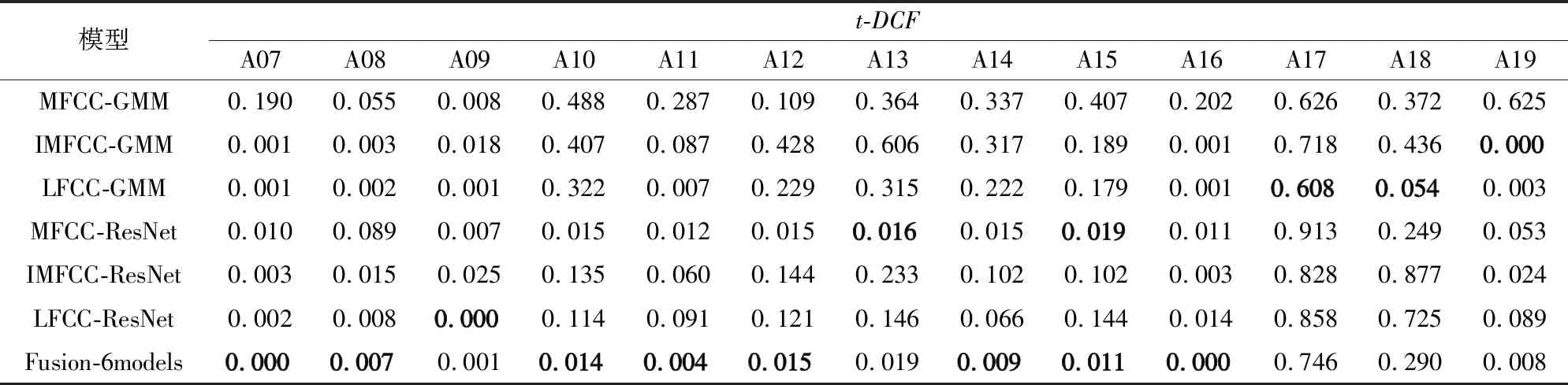
表4 不同模型在不同算法上的t-DCFTab.4 t-DCF of different models on different algorithms

图6 不同模型在不同算法上的t-DCFFig.6 t-DCF of different models on different algorithms
可以看出,对于大部分未知欺骗算法,深层模型ResNet比浅层模型GMM表现更好,但在欺骗算法A17与A18上,浅层模型反而表现更佳。除了MFCC-GMM,其余5个模型都能很好地识别已知欺骗算法A16与A19,说明欺骗语音可以很容易地骗过传统说话人识别系统中常用的MFCC-GMM模型。所有模型在基于波形滤波与变分自编码器(Variational AutoEncoder,VAE)[18]的A17欺骗算法上表现都比较差,虽然文献[5]中的结果说明A17算法对于ASV系统的威胁并不大,但这种算法仍需重点关注。实验结果表明,融合后的模型在大部分欺骗算法中的效果都是最优的,这说明了打分结果融合是提升CM系统检测性能的有效方法之一。
3.5 不同模型融合实验效果分析
从表3的结果可以看出,融合所有模型可以有效降低EER,却会使t-DCF升高,可能是部分模型影响了最终结果。因此,使用穷举的方法测试所有模型融合组合的效果,其中,表现最好的是MFCC-ResNet、MFCC-GMM、IMFCC-GMM与LFCC-GMM的融合模型,记为Fusion-4models。为了验证深浅层模型融合可以起到互补作用,对比Fusion-4models与只融合3种GMM模型和3种ResNet模型的结果,并测试在不同欺骗算法上的表现,如表5所示。

表5 融合模型在不同算法上的t-DCFTab.5 t-DCF of fusion models on different algorithms
只融合GMM模型的Fusion-GMM在A17与A18欺骗算法上效果不错,但在其他大部分欺骗算法中表现较差。只融合ResNet模型的Fusion-ResNet恰好相反。Fusion-4models则均衡了2种模型的t-DCF值。最终的模型融合结果与其他人提出的M1[9]与M2[10]模型进行对比,结果如表6所示。
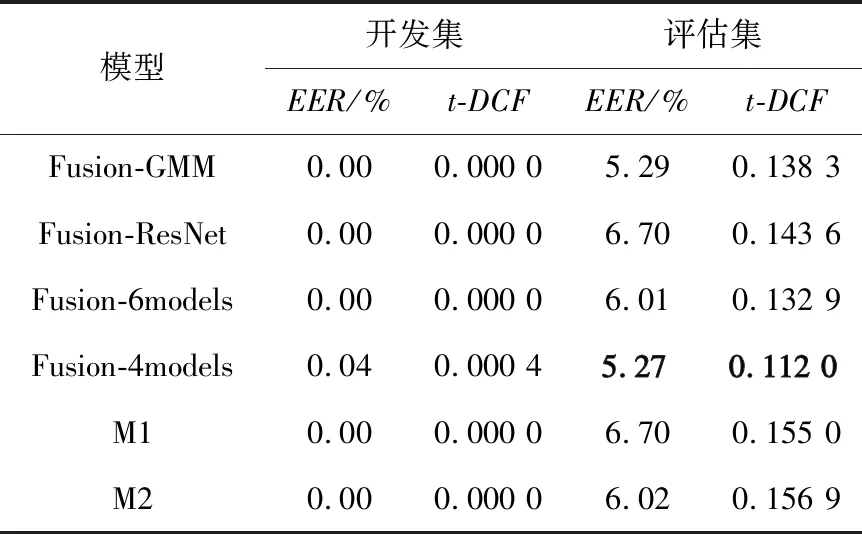
表6 融合模型在开发集与评估集上的EER与t-DCFTab.6 EER and t-DCF of fusion models on development set and evaluation set
其中,M1模型使用CQCC、MFCC与对数短时频谱特征,后端分类器采用ResNet;M2模型使用CQCC、MFCC与短时傅里叶变换对数谱特征,后端分类器则采用压缩奖惩网络(Squeeze-and-Excitation Networks,SENet)[9]与扩张残差网络,并引入注意力机制。2种模型都使用了融合打分结果的方法。相较而言,本文使用的融合浅层模型的方法效果更好。对比表6与表3,在t-DCF上,Fusion-4models相比基线系统LFCC-GMM-B降低了约47%;在次要指标EER上,相比LFCC-GMM-B降低约35%。
4 结束语
在前端特征提取上,采用了3种基于三角滤波器组的特征;在后端分类器设计上,本文采用传统的GMM模型作为浅层模型,ResNet模型作为深层模型,一共测试了6组模型的效果;结果表明,在总体上,深层模型比浅层模型效果更好,但在欺骗算法A17与A18上不如浅层模型。使用打分结果进行的模型融合可以权衡不同模型的优缺点,提升系统的性能,但仍然无法有效检测A17算法产生的欺骗语音。此外,本文对语音前端特征以及后端分类器的选取并不全面,后续工作将会进行其他特征与分类器的实验,同时,也会重点研究针对A17的反欺骗算法,提升反欺骗语音系统的泛用性。
猜你喜欢
哈尔滨工业大学学报(2022年5期)2022-04-19 13:26:36
电子制作(2019年11期)2019-07-04 00:34:38
语言与文化论坛(2019年3期)2019-04-13 02:25:30
电子制作(2018年16期)2018-09-26 03:26:50
电子测试(2018年1期)2018-04-18 11:52:35
光学精密工程(2016年4期)2016-11-07 09:05:00
光学精密工程(2016年3期)2016-11-07 09:03:33
系统工程与电子技术(2016年7期)2016-08-21 13:59:02
火控雷达技术(2016年2期)2016-02-06 02:29:00
党员文摘(2014年10期)2014-10-14 23:50:35
