
基于K-means算法的互联网有害信息挖掘模型构建
2021-06-16 16:43:04尚秋明
电子技术与软件工程 2021年4期
尚秋明
(中国互联网络信息中心 北京市 100190)
当今时代人们多数通过互联网进行聊天、交易等活动,信息技术的高速发展大大提高了信息传递效率,虚拟网络中越来越多的有害信息不仅严重危害了网络环境,扰乱了社会治安,还给网民带来经济损失。因此,对互联网有害信息监管是当前亟需解决的问题。
随着互联网每时每刻产生的海量数据,传统的监管方式在互联网有害监管方面存在效能低下、管理松散、数据难以共享等难题。随着大数据技术不断出现,这一问题逐渐得到一定程度的解决。目前应用比较广泛的数据挖掘算法主要有K-means、决策树、Apriori等,其中K-means 算法运行效率高、实现容易被广泛应用到数据挖掘中。本文就K-means 算法在互联网违法信息监管中应用进行研究。
1 K-means算法
K-means 算法核心思想是将某些相似的数据进行分类后聚集在一起方法。该算法首先选取K 个中心点,然后计算每个中心点到各种聚类群体之间的聚类,重新分配中心点。采用迭代方法进行聚类中心划分,直到中心点达到设置范围,算法终止[1-2]。可用如下公式进行表达:

式中:xi表示第j 个簇类中第i 个数据;cj表示第j 个簇类中心点。
2 K-means算法在舆情监测管理中应用
舆情监管是互联网有害信息管理重要内容。梁晓贺[3]研究了网络微博舆情问题,提出了一种微博舆情主题发现超网络模型及超边相似算法,图1 为该算法流程图。
所设计的超边相似度算法微博舆情监控模型中假设舆情主题中网络模型共计N 条超边,用符号相似度计算方法为:


所设计的算法与K-means 算法融合后,通过仿真,结果表明所设计的算法在微博舆情监控中能够很快识别。
王林[4]针对复杂的微博热点问题,当前所使用的K-means 算法在初始中心选点存在难点问题,提出了一种基于MapReduce 的并行K-means 算法。该算法核心思想为使用MapReduce 中的map函数进行对象到聚类中心距离计算,该过程中需要重新标记聚类类别。Reduce 函数主要进行Map 函数的中间结果计算,并形成一个簇类中心。仿真结果表明所改进算法提高了K-means 算法精度,在舆情监测管理中有重要作用。
田世海[5]为提高舆情监管准确率,将K-means 算法与NRL 结合融合在一起形成新的算法。该算法核心思想是通过概率事件进行舆情监管。假设每个舆情监管事件中都包含两个d 维向量,分别为表示节点作为其它相邻节点的d 维向量。可用计算公式表示。使用概率计算方法得到舆情关注概率为:将K-means 算法应用到概率计算中得到,舆情事件分类为m 类,符号中心点用符号表示簇类划分点数,每个簇类代表每个舆情事件,事件之间相似度可用符号表示。中心点平均值计算方法为:。仿真结果表明所设计的算法能够较快明确分组数量,聚类效果好。

图1:基于超边相似度算法微博舆情监控算法
闫俊伢[6]对K-means 算法应用到舆情监管应用进行详细分析,发现现有的K-means 算法在舆情挖掘中存在挖掘准确率和稳定性有待提升问题。为解决这一问题,提出了将遗传算法与K-means 算法相结合。基于遗传算法、K-means 算法相结合的聚类算法中使用浮点编码规则进行编码;使用均匀变异算子进行基因变异;适应度计算方法为,E 表示误差平方和,b 为常数。
徐建国[7]将改进的K-means 算法应用到高校舆情监管中。当前K-means 算法容易存在局部最优问题,在传统的聚类算法中增加了相似度计算方法重新选取新的簇类中心。仿真结果表明所设计的算法相比传统的K-means 聚类算法性能提升了8%。陈艳红[8]研究了K-means 算法在高校舆情监控中应用,提出了将剩余的样本与中心点进行中心点选择,仿真结果表明改进算法能够提高算法性能。
谢修娟[9]针对当前K-means 算法初始聚类中心选取容易导致算法陷入局部最优问题,对K-means 算法进行改进。所设计的算法借用DBSCAN 密度算法进行改进。假定微博文档集合符号初始聚类中心集合符号初始化聚类簇符号改进K-means 算法伪代码为:

Input:微博数据Output:违法信息监督结果Step1:从数据库中获取微博文档数据集b,根据初始类中心c,进行聚类划分Step2:更新聚类中心,清空聚类中心,进行下一类操作Step3:重复Step1 和Step2,如果达到设置误差函数,跳转到Step4;否则跳转到Step1 Step4:输出监督结果。
研究结果表明所改进的K-means 算法具运行效率、准确性、稳定性指标等到提高。
张寿华[10]针对网络舆情热点话题监督提出了使用K-means 算法进行挖掘。所构建的舆情监测模型中,关键词提取计算方法为:

文档聚类计算方法为:
(1)热点新闻分析模型为:
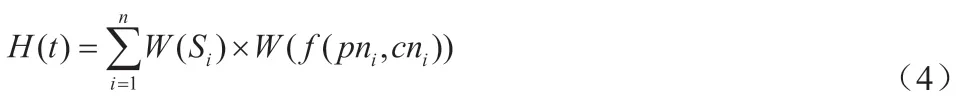
式中:H(t)表示新闻热度值;n 表示新闻数量;W(Si)表示新闻网站权重;表示新闻参与评论权重;pni表示新闻参与人数;cni表示新闻评价人数。
(2)信息转载模型为:
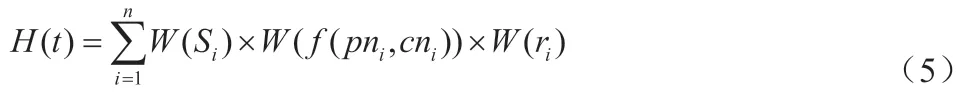
式中:H(t)表示话题论坛热度值;n 表示话题数量;W(Si)表示话题的权重值;表示话题浏览次数和回复权重;pni表示话题参与人数;cni表示话题评价人数;W(ri)表示话题转载次数权重。
应用结果表明所设计的基于K-means 算法的话题聚类方法能够很好进行话题监管。
3 K-means算法在互联网有害行为监管中应用
互联网违法信息监管是当前重点研究课题。汪黎嘉[11]详细研究了K-means 算法在网络有害信息监管中应用,所设计的算法包括:
(1)网络信息初步筛选,计算方法为:

式中:S 表示互联网信息可行度评价指标;Cc 表示信息变更次数;Cl 表示信息变更阀值;Ft 表示互联网信息访问次数;Tt 表示违法信息访问时间。
吕飞[12]将改进K-means 算法应用到互联网涉烟违法犯罪区域划分研究。针对传统的K-means 算法局部容易出现最优情况,提出了使用概率方法寻找质点。应用结果表明所设计的算法能够准确识别烟草互联网有害信息。
张玉峰[13]研究了有害信息的类型,包括色情信息、虚假信息、垃圾信息、网络安全信息、文化侵略信息等。提出使用数据挖掘技术对有害信息挖掘。结果表明K-means 算法在有害信息分类中具有重要应用前景。
4 结语
本文详细分析了K-means 算法在互联网有害信息挖掘中应用。当前K-means 算法应用到舆情监管中发挥了重要作用,未来发展方向是结合大数据技术、神经网络算法,能够提高算法准确率。K-means算法应用到有害监管中具有重要作用,未来可发展到诈骗行为识别中。
猜你喜欢
东方法学(2024年1期)2024-04-01 21:00:20
电脑报(2020年12期)2020-06-30 19:56:42
电脑报(2019年4期)2019-09-10 07:22:44
中国计算机报(2019年27期)2019-09-04 08:28:25
法制博览(2018年24期)2018-01-22 22:27:15
新闻前哨(2016年7期)2016-09-27 21:28:28
少儿美术·书法版(2016年1期)2016-02-06 00:59:39
大众摄影(2015年9期)2015-09-06 17:05:41
中学生数理化·八年级数学华师大版(2008年3期)2008-08-26 11:26:16
现代农业科技(2006年23期)2007-01-05 03:23:54
