
基于强化学习的多燃烧模式混合动力能量管理策略*
2021-06-09 15:18:34范钦灏
汽车工程 2021年5期
张 昊,范钦灏,王 巍,黄 晋,王 志
(清华大学,汽车安全与节能国家重点实验室,北京100084)
前言
高效清洁燃烧技术与混合动力技术的结合是乘用车满足未来法规的有效途径[1]。融合了均质混合气压燃着火(homogeneous charge compression ignition,HCCI)与火花点火(spark ignition,SI)的HCCI∕SI多燃烧模式混合动力系统,具有显著的节能减排前景。即在中小负荷下利用HCCI燃烧模式的低燃油消耗率和超低排放优势,而在大负荷下切换至传统火花点火(SI)燃烧模式,避免发生失火和爆震等异常燃烧现象[2],得到了国内外学者的广泛研究。Ahn等利用HCCI∕SI多模燃烧发动机的稳态MAP建立了车辆模型,在多种循环工况下验证了这种先进燃烧模式对整车燃油经济性的提升[3]。Benajes等对一款搭载多燃烧模式发动机的并联式混合动力汽车进行了仿真分析,得出随着动力总成混合程度的提升,整车燃油消耗显著降低的结论[4]。Gao等利用数值模拟方法研究了采用多模燃烧的混合动力系统,结果表明配备多燃烧模式发动机的混合动力总成,较配备传统发动机的混合动力总成具有更大的节能潜力[5]。
在多模燃烧混合动力系统中,发动机在相同的功率需求下可以选择不同的燃烧模式,其能量管理是一个多变量、强耦合的非线性时变系统。最优的能量管理策略能够高效地控制动力系统的功率流动和发动机的燃烧模式,充分发挥HCCI∕SI多燃烧模式的优势并提高其运行稳定性,获得最佳的整车性能。针对搭载HCCI∕SI多燃烧模式发动机的混合动力汽车,设计与之相匹配的能量管理策略,从而优化动力总成的工作特性,是当下多燃烧模式混合动力系统亟待研究的核心技术之一。Musardo等针对多模燃烧混动系统,仿真验证了自适应等效燃油消耗最小策略(adaptive⁃equivalent fuel consumption minimiation strategy,A⁃ECMS),证明了与燃烧模式相匹配的能量管理策略能更充分地发挥发动机节能减排潜力[6]。在此基础上,García等将分别以油耗和排放为目标的两种A⁃ECMS算法应用于多模燃烧并联式混合动力系统中,验证了A⁃ECMS在油耗和排放方面优于基于规则的控制策略,并指出需要研发适用于多模燃烧混合动力系统的专用能量管理策略[7]。需要注意的是,以上研究都假设了燃烧模式切换过程是瞬间完成的,即混动模型中忽略了切换过程产生的额外燃油和排放损失。然而,能量管理的实际效果与车辆模型准确度紧密相关,Nüesch等的研究表明HCCI∕SI燃烧模式的切换会造成瞬态燃烧和排放恶化,因此提出了一种考虑HCCI∕SI切换过程中瞬态燃油和排放损失的发动机模型[8]。同时,针对一款搭载HCCI∕SI多模燃烧的48 V轻度混合动力汽车,提出了基于燃烧模式切换惩罚的ECMS算法,通过数值模拟证明了该算法能够有效避免燃烧模式的频繁切换[9]。
基于规则和基于最优控制的多燃烧模式混合动力能量管理策略,通常需要建立精确的控制模型并进行标定,比如A⁃ECMS算法中对油电等效因子的估计模型等[10]。这加大了能量管理策略的制定难度,并且难以保证对多模燃烧发动机工况点的优化效果,而基于深度强化学习的方法可以较好地解决这一问题[11]。本文中以搭载多燃烧模式发动机的功率分流型混合动力汽车为研究对象,依据HCCI∕SI发动机台架试验数据和电机有限元仿真结果,建立了基于MAP的多燃烧模式混合动力汽车模型,并利用有限状态机引入HCCI∕SI切换的瞬态油耗惩罚。定义了以燃烧模式切换频率、油耗和SOC波动为指标的奖励函数,提出了基于深度强化学习(deep reinforcement learning,DRL)的能量管理策略。将整车作为环境,训练基于深度Q网络(deep Q⁃network,DQN)的能量管理智能体。利用深度神经网络对能量管理策略集进行储存,解决了强化学习因数据存储维数过多导致训练困难的问题。同时,基于优先经验回放机制,优先回放对于能量管理策略训练更有价值的经验,使智能体更快适应环境,提升了DRL算法的收敛速度。最后,在WLTC和NEDC工况下与基于规则的控制策略、A⁃ECMS策略和动态规划结果进行仿真对比,验证所提出策略在减少燃烧模式切换频率和提升燃油经济性方面的有效性。
1 多燃烧模式混合动力系统建模
本文所研究的多燃烧模式混合动力汽车的动力系统为功率分流构型,如图1所示。主要由驱动电机、发电机、多模燃烧发动机、动力传动机构、动力电池组、功率变换单元和相应的控制器组成,主要参数见表1。

图1 整车动力传动系统结构图

表1 整车参数
1.1 发动机台架试验与模型
本文采用一台4缸直喷汽油机进行了HCCI∕SI多燃烧模式的切换试验,台架系统如图2所示,发动机主要参数见表2。其中,空燃比测量装置采用ABM⁃10型空燃比仪,通过ECU进行闭环控制。

图2 HCCI∕SI发动机试验台架示意图
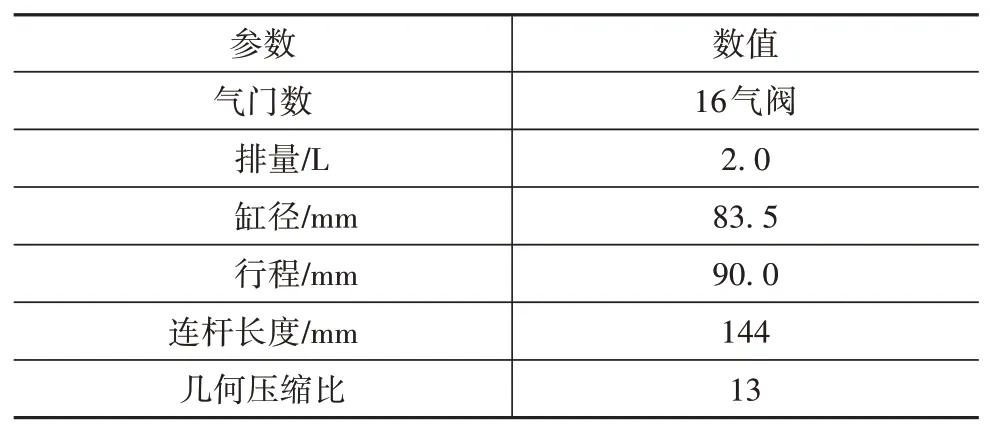
表2 试验发动机参数
HCCI∕SI多燃烧模式发动机的台架试验结果如图3所示,该万有特性图显示了两种燃烧模式的性能和运行区域。其中,HCCI采用稀薄燃烧,实现了较好的节油效果,其转矩范围为13~67 N·m,转速范围为1 300~2 700 r∕min。同时,由于其燃烧温度低,因此NOx排放极低,而HC和CO排放则通过在富氧条件下采用三效催化器处理。SI燃烧的转矩运行范围为20~175 N·m,适合工作在理论空燃比附近,从而保证三效催化器高效运行。为防止频繁切换,采用了滞回控制,图3中的白色圆圈表示台架试验中两种燃烧模式的切换点。

图3 HCCI∕SI发动机万有特性图
HCCI∕SI的切换采用分步方法实现,即单独控制节气门和配气相位的动作,通过损失一定程度的燃油经济性和排放性能,换取HCCI∕SI的平稳切换。由HCCI燃烧向SI燃烧切换时,首先减小节气门开度,然后将配气相位由HCCI燃烧的负阀重叠(negative valve overlap,NVO)切 换 为 正 阀 重 叠(positive valve overlap,PVO)。当向HCCI模式切换时,则先将配气相位切换至NVO相位,接着保持节气门全开,避免节气门和配气相位对气流影响的耦合,大幅降低控制难度。基于台架试验获得的HCCI∕SI发动机万有特性图,建立了基于MAP的多燃烧模式发动机模型,并令发动机沿最佳燃油消耗曲线运行。同时,利用有限状态机引入切换过程的瞬态油耗惩罚,如图4所示,其中kp是对当前BSFC的惩罚系数,如kp=1.1表示增加10%的油耗,nc表示惩罚系数作用的发动机工作循环数。

图4 基于有限状态机的瞬时油耗惩罚
1.2 电机有限元分析与模型
根据电机参数在Ansys Maxwell软件中建立了驱动电机和发电机的有限元模型,见图5,其结构与Prius的永磁同步电机(permanent magnet synchro⁃nous machine,PMSM)保持一致。利用Toolkits插件导出如图6和图7所示电机效率特性图,建立基于MAP数据的驱动电机和发电机模型用于整车仿真。
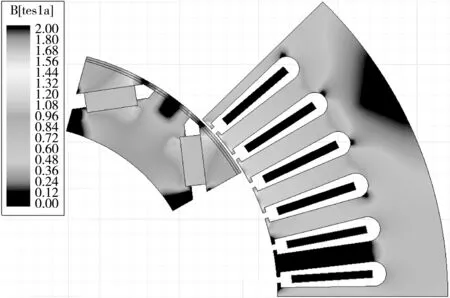
图5 永磁同步电机的有限元模型
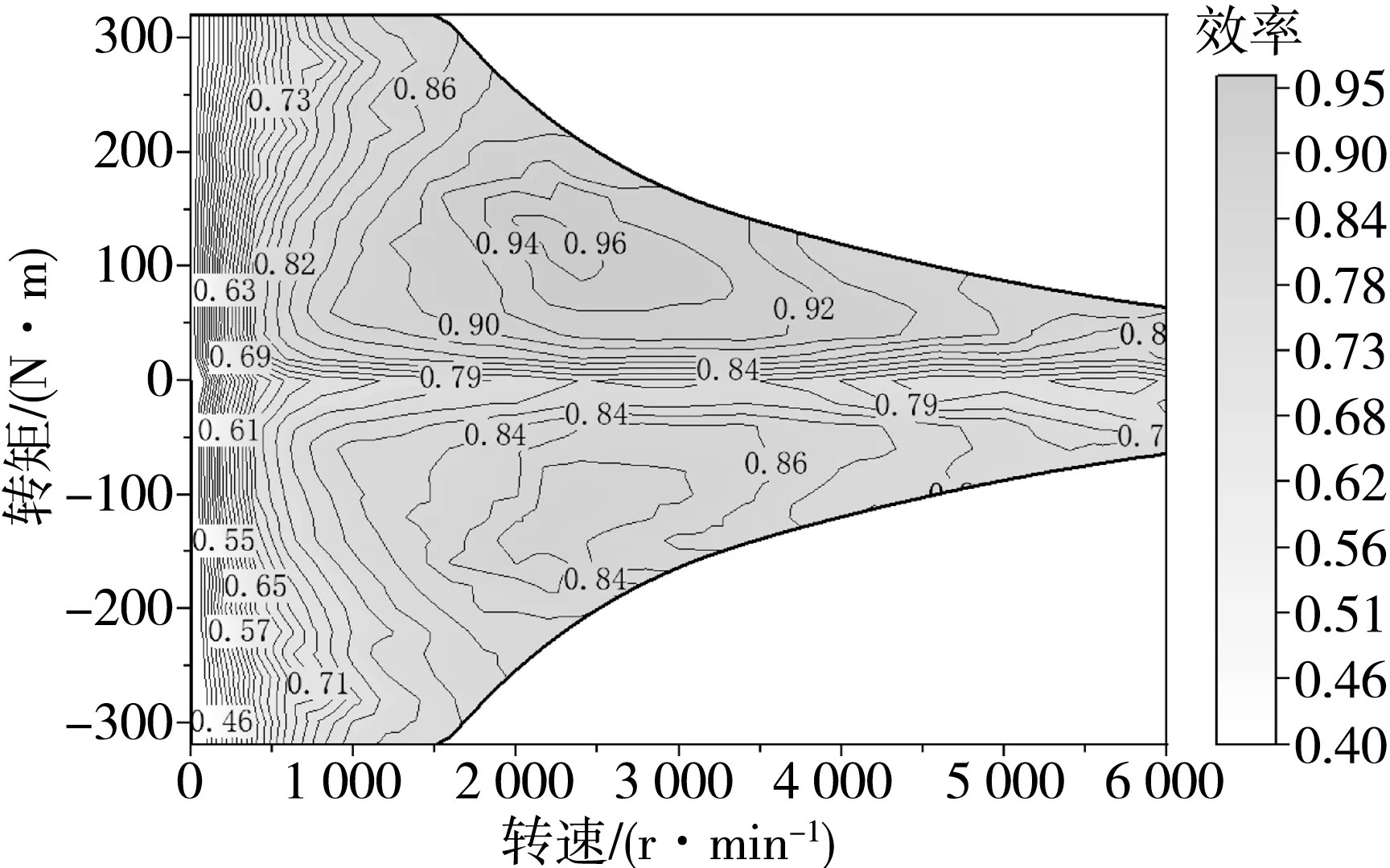
图6 驱动电机效率特性图
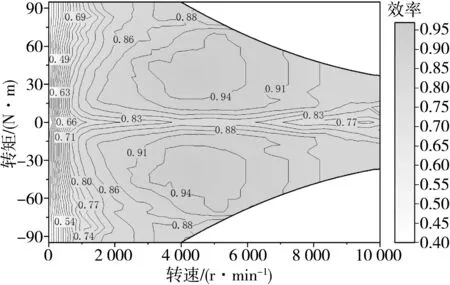
图7 发电机效率特性图
1.3 动力电池组模型
动力电池采用内阻-开路模型,本文忽略电池组温升及其对电池内阻的影响,其数学模型如式(1)~式(3)所示。

式中:SOC为电池荷电状态;S O C0为电池初始荷电状态;C为电池组容量;t为时间;Ibat为电池组放电电流;Uoc为电池组开路电压;Rbat为电池组内阻;Pbat为电池组功率。
1.4 整车纵向动力学模型
如图3所示,驱动电机、发电机和发动机分别与行星齿轮的齿圈、太阳轮和行星架相连。行星齿轮将发动机的部分转矩传递给发电机,其余部分转矩用于直接驱动车辆。根据车辆行驶过程中的动力学平衡关系,以及行星齿轮的转速、转矩关系,建立功率分流型混合动力汽车的纵向动力学模型,如式(4)~式(7)所示。
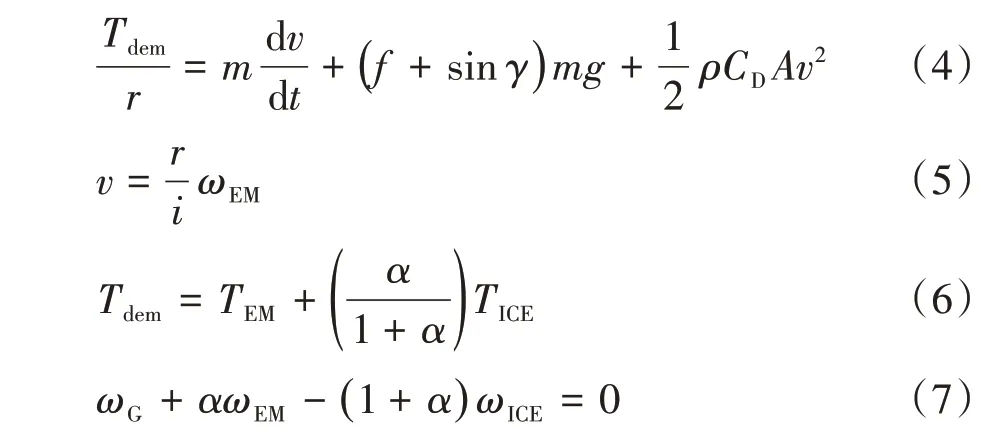
式中:Tdem为车辆行驶的需求转矩;TEM、TG和TICE分别为驱动电机、发电机和发动机的输出转矩;ωEM、ωG和ωICE分别为驱动电机、发电机和发动机的角速度;α为行星齿轮齿比;i为主减速器速比;r为车轮半径;m为整车质量;A为车辆迎风面积;v为车辆行驶速率;t为时间;f为滚动阻力系数;γ为路面倾角;g为当地重力加速度;ρ为空气密度;CD为空气质量系数。
2 基于DRL的能量管理策略
Q学习是强化学习的一个分支,是一种基于价值的学习方法,包括环境与智能体两个实体。通过使智能体在与环境交互的过程中,所做出一系列动作的回报最大,从而建立最优的动作策略集。深度Q网络算法是深度学习和Q学习相结合的产物,它将深度神经网络作为Q函数的近似方法,即用深度神经网络替代传统的Q函数。同时,DQN算法通常与经验回放算法相结合,以降低样本间的相关性。
2.1 DQN框架
DQN算法采用了两个神经网络,分别是当前值Q网络和目标值Q̂网络。它们是两个结构完全一致但参数不同的全连接网络,其参数分别用θ和θ-表示,通过训练可以建立其输出Q值与状态及动作之间的映射关系。定义损失函数为两者的均方误差并进行反向传播,在训练过程中对当前Q值与目标Q̂值依次更新。最优策略即在状态下选用使总体奖励最高的一系列动作,算法基本形式如下:

式中:Q为智能体动作a t的期望价值函数,即在状态s t下执行a t动作预计获得的价值;r t为实际价值;t为时间步;α为学习率;γ为对未来潜在奖励的衰减率。
DQN的损失函数定义为当前值Q网络和目标值Q̂网络输出的Q值之差:
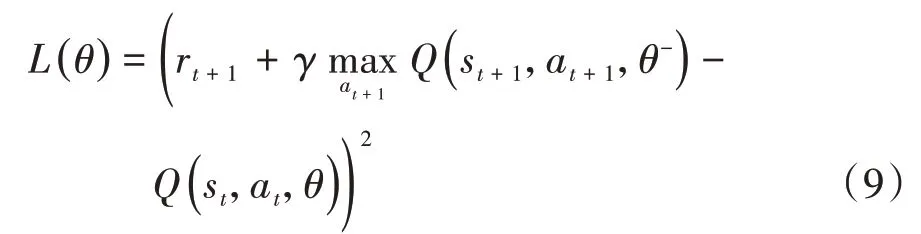
在不损失经验多样性的前提下优先使用具有较大回报的经验,进一步提高经验数据的利用率,引入了排序优先经验回放算法。定义时序误差δ(t)、经验优先级p t和采样概率p(t)如下:

式中:rank(t)为时序误差按绝对值由大到小排序后的序号;n为记忆存储空间的大小;β为控制优先采样的程度,取值为[0,1],当β=0时表示均匀采样。
2.2 状态空间
HCCI∕SI多燃烧式混合动力系统作为环境,与能量管理智能体进行交互,反馈给智能体的状态信息包括电池组S O C、车辆加速度acc、车速v和发动机工况点与高效区的偏离程度σ。由此定义多燃烧式混合动力系统模型的状态空间,如式(13)所示。

式中:BSF C t为t时刻的燃油消耗率;B SFCmin为发动机最小燃油消耗率。
2.3 动作空间
针对HCCI∕SI多模燃烧的专用能量管理策略,其核心是对发动机输出功率和燃烧模式切换的优化。当智能体收到环境的状态反馈时,需在动作空间A中选择一个动作,即对发动机的功率PICE和燃烧模式Mode进行调整。其中,对输出功率调整被定义为每秒功率的变化量,并进行了离散化。输出功率增量的上、下限分别设为5和-10 kW∕s,以减小对系统的冲击。同时,由于本试验发动机在HCCI燃烧模式运行的功率边界为12 kW,因此燃烧模式的切换采用混合控制方式,输出功率大于12 kW时直接切换为SI燃烧模式,小于该功率时则基于DRL策略进行切换控制。多燃烧模式能量管理策略的动作空间如下:

式中:ΔPICE为对发动机输出功率的调整,kW;Mod e为燃烧模式,其定义分别如式(16)和式(17)所示。
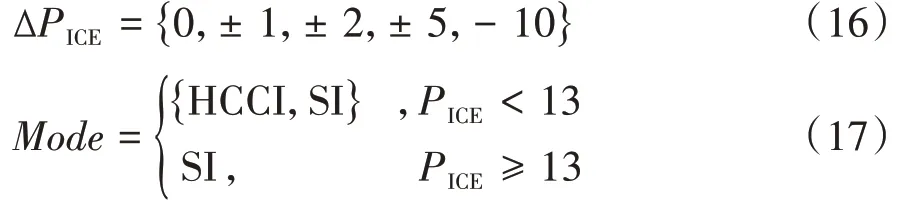
2.4 奖励函数
采用HCCI∕SI多燃烧模式的初衷是提高燃油经济性,因此油耗被纳入奖励函数中。同时,由于燃烧模式的切换会造成瞬态燃烧和排放恶化,甚至导致发动机失火和爆震现象,在奖励函数中引入燃烧模式切换指令以避免HCCI∕SI的频繁切换。此外,为维持电池SOC在一定水平,在奖励函数中加入了电池SOC实际值与其参考值偏差的平方项。由于以上三者均为对系统产生不利影响的指标,因此在定义奖励函数时,将以上3个变量的系数均设置为惩罚系数,即设为负值,惩罚权重分别用a、b和c表示,如式(18)所示。

式中:r为奖励;Fuel_con t为动作a t持续时间内的燃油消耗量;S O C_ref t为SO C参考值;Mode_swt t表示燃烧模式是否切换,如式(19)所示。

2.5 算法实现流程
基于以上定义,提出了基于DQN算法的多燃烧模式混合动力能量管理策略,如图8所示,完整的算法实现流程如表3所示。

图8 基于DQN的能量管理策略

表3 DQN算法伪代码
3 验证与讨论
3.1 仿真模型设置
为验证基于深度强化学习的能量管理策略的可行性和有效性,在Matlab∕Simulink环境中建立了搭载多燃烧模式发动机的混合动力整车仿真模型,其中电池的充放电区间为40%~80%。图9展示了用于验证策略的两种典型循环工况,分别由3组WLTC工况和4组NEDC工况组成,在两种工况下分别验证传统控制策略与本文算法的控制效果。驱动电机和发电机均采用矢量控制方式,考虑到当发动机输出功率过小时,即使工作在HCCI状态依然无法实现良好的燃油经济性,且存在失火或爆震可能,因此两种策略中发动机的起动功率均设置为2 kW,且沿最佳燃油消耗线运行。同时,为研究专用能量管理策略对发动机的节能效果,需保证总驱动能量仅由发动机提供,即保持两种策略的始末SOC值均一致,本文将SOC初始值和SOC终值均控制在60%左右。

图9 循环工况
3.2 算法参数设计与收敛分析
DQN中当前值网络和目标值网络的结构完全一致,其输入层和输出层分别与状态变量和动作变量对应,两个神经网络均包含3层全连接层,各层神经元个数分别为300、150和50。参数的选择决定了训练的收敛效果和能量管理策略的性能,本文经对比后确定学习率α为0.001,未来奖励衰减率γ为0.9,贪婪值ε设为0.01,训练回合数设为500,奖励函数的系数a、b、c在WLTC工况下分别为5,35和2 000,在NEDC工况下设为2,25和650。每回合的平均回报反映了智能体训练进程的效果,如图10所示,其中每回合指在3.1节的循环工况下完整训练一次。WLTC和NEDC工况的起始平均奖励值分别在-250和-100左右,随训练回合数增多,平均回报均呈上升趋势,分别在约150和250回合时收敛,说明深度强化学习算法对多燃烧模式混动能量管理具有较好的适用性。
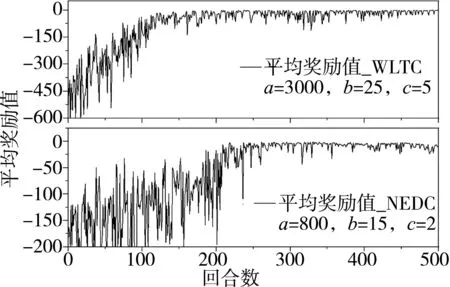
图10 平均回报
3.3 电池充放电情况
在WLTC和NEDC工况下电池SOC的变化情况分别如图11和图12所示。其中基于规则的控制策略能够在驱动功率较小的情况下,较好地维持SOC。而在功率需求较大时表现为将电池电量消耗至SOC下限,之后进入充电模式至SOC达到上限,在WLTC和NEDC工况下的SOC终值分别为61%和60%。A⁃ECMS策略基于车辆需求功率和电池SOC,利用极小值原理选择最优的功率分配,同时,燃油等效因子的自适应调节保证了SOC的动态维持,在WLTC和NEDC工况下的SOC终值分别为63%和62%。而对于基于DRL的能量管理策略,经过训练的智能体能够基于状态反馈,选择使奖励函数最大的功率分配。从其SOC的变化过程可以看出,该控制策略更加趋向于电驱动,在过程中选择一定程度的SOC下降作为代价,避免发动机小功率频繁起动,从而获得更佳的燃油经济性。同时,SOC值仍保持在40%以上,未造成对电池寿命的损害,在WLTC和NEDC工况下的SOC终值分别为63%和59%。
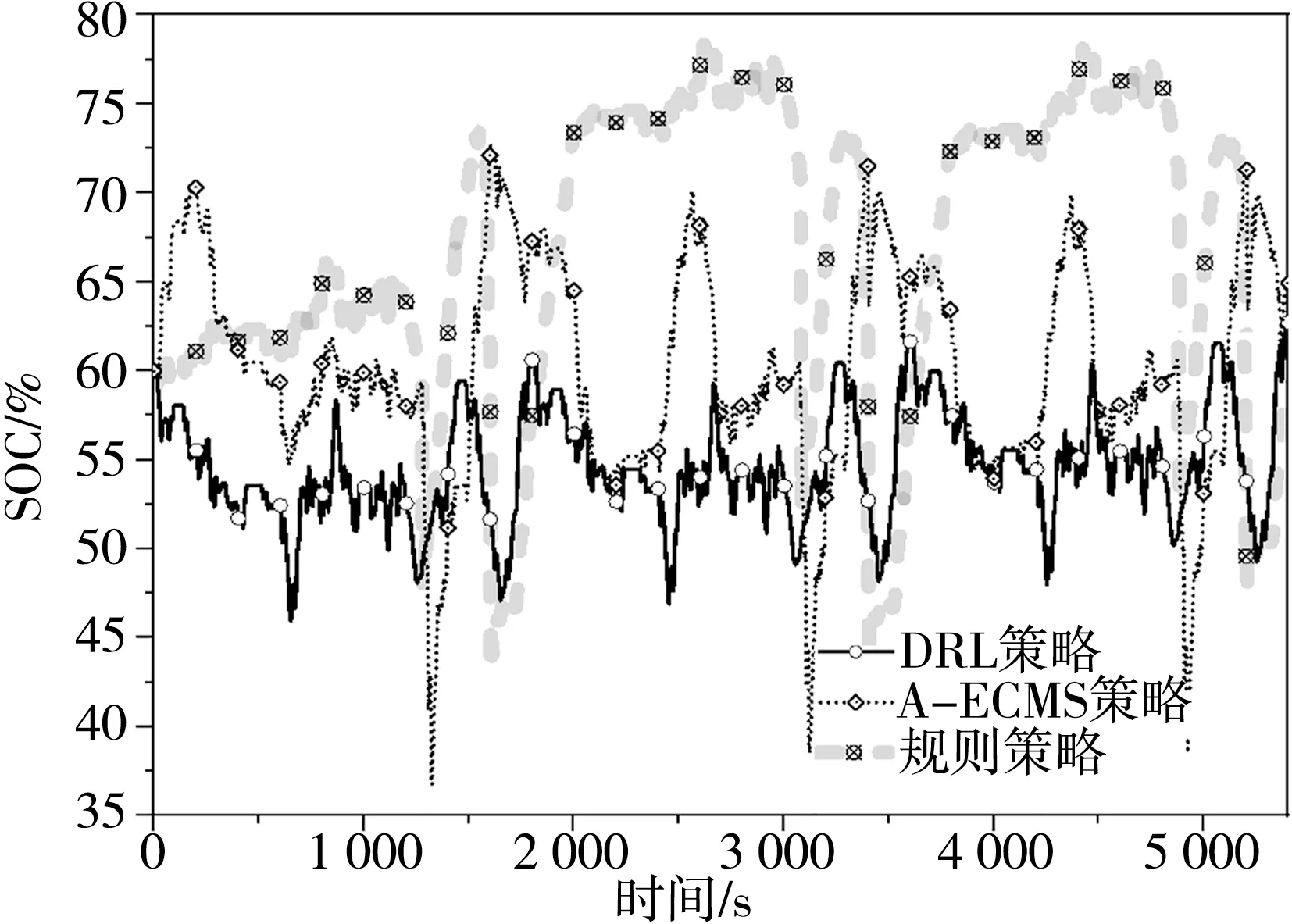
图11 WLTC工况的SOC对比

图12 NEDC工况的SOC对比
3.4 能量管理策略效果分析
在WLTC和NEDC工况下,规则策略、A⁃ECMS策略和DRL策略的发动机运行工况点分别如图13和图14所示。在基于规则的控制策略下,发动机输出功率跟随行驶功率需求,因此不可避免地工作于低效区,在WLTC和NEDC工况下的百公里油耗分别为6.0和4.7 L,两种工况下的燃烧模式切换次数分别达到了291和136次。基于最优控制理论的A⁃ECMS策略明显改善了发动机工作的效率区域,在WLTC和NEDC工况下的百公里油耗分别为5.1和4.4 L,燃烧模式切换次数分别为191和67次。与以上两种策略相比,DRL策略能够更好地规划功率分配,并将发动机工作点分配到SI和HCCI燃烧模式的高效区,在两种工况下的百公里油耗分别为4.9和4.1 L。燃烧模式切换方面,在WLTC工况下切换176次,在NEDC工况下仅切换52次。
上述3种策略的燃油消耗率分布情况如图15所示,可以看出DRL策略能够在不影响整车动力性能以及不引起电池过充、过放电的前提下,明显抑制发动机在过渡区域的停留时间。表4给出了两种工况下规则策略、A⁃ECMS策略、DRL策略和动态规划的能量管理效果对比,可以看出在SOC终值基本一致的情况下,DRL能量管理策略下的油耗和燃烧模式切换次数均优于规则策略和A⁃ECMS策略,与动态规划的结果相近。针对WLTC和NEDC工况,DRL策略的燃油经济性相比规则策略分别提升18%和13%,相比A⁃ECMS策略分别提升8%和6%。此外,经过训练的智能体能够权衡燃烧模式切换的收益和代价,从而避免频繁切换,两种工况下相比规则策略分别减少40%和62%,相比A⁃ECMS分别减少了13%和15%。

图13 WLTC工况下不同策略的发动机工作点

图14 NEDC工况下不同策略的发动机工作点

图15 燃油消耗率分布对比
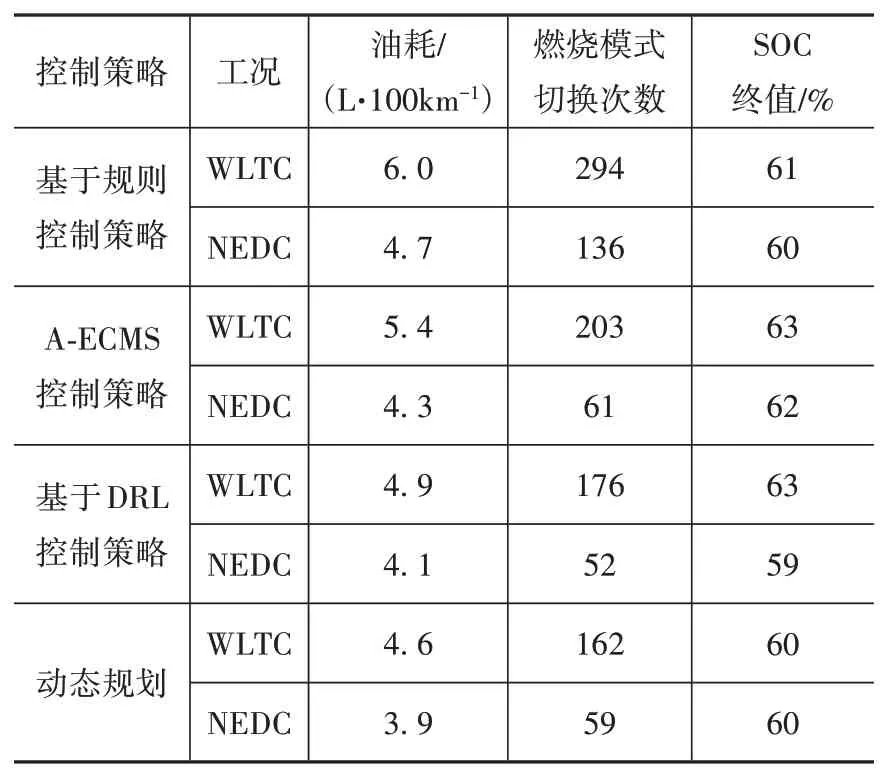
表4 能量管理结果对比
此外,验证了DRL策略对驱动电机的影响,在WLTC和NEDC工况下,电机的运行工况分别如图16和图17所示。在中、小功率情况下,电机作为主要驱动源,其输出功率与车辆需求功率呈正相关,而在发动机高功率输出状态和车辆制动状态下则进行能量回收。与电动机的匹配较好,均未出现负荷过小导致低效运行的情况或过载情况。
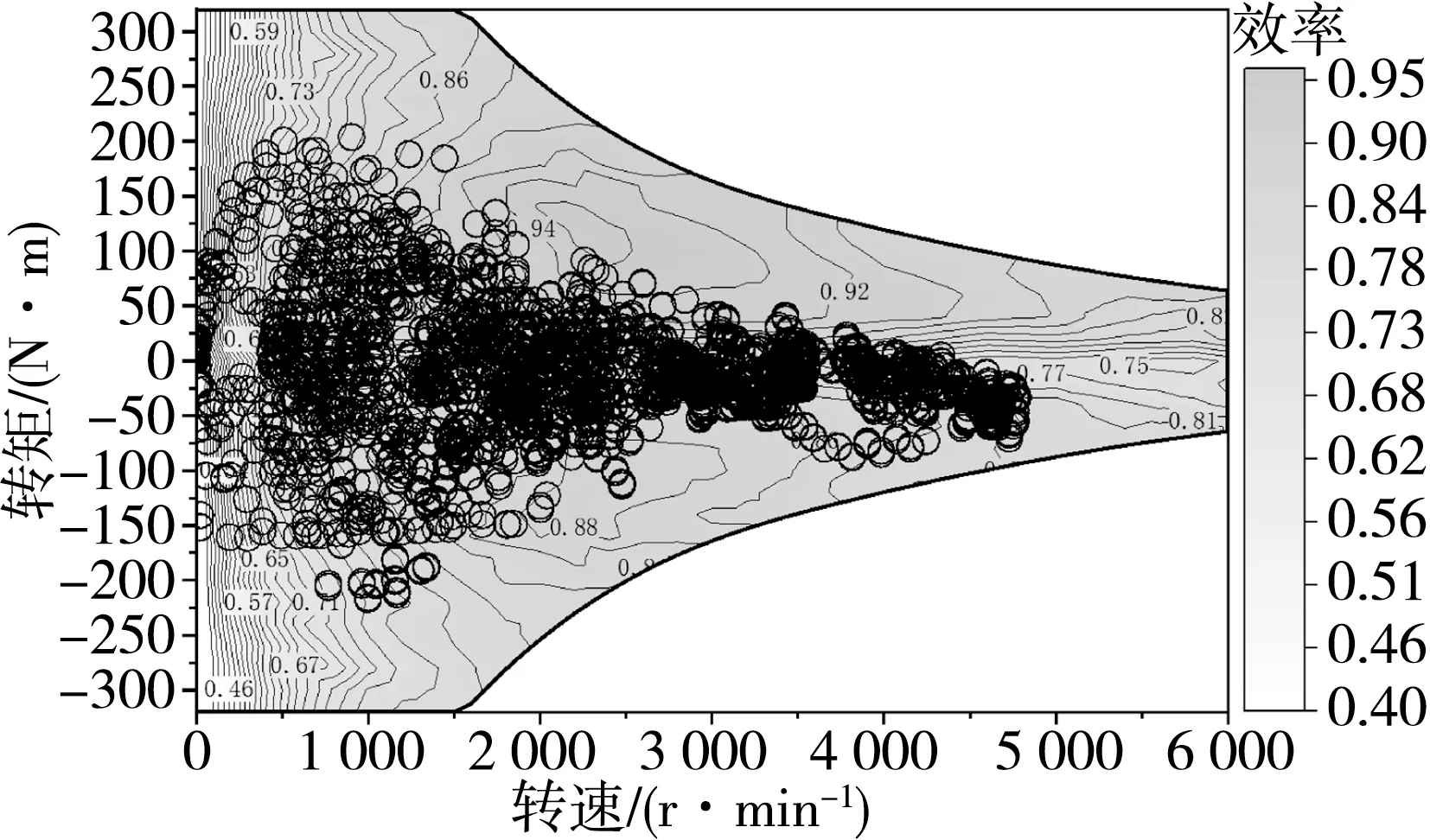
图16 DRL策略的电动机工作点(WLTC)

图17 DRL策略的电动机工作点(NEDC)
4 结论
将多燃烧模式发动机应用于油∕电混合动力汽车,是交通领域具有前景的节能减排技术路线。针对多模燃烧混合动力系统设计专用能量管理策略,是发挥高效清洁燃烧技术优势的前提。本文中针对多模式燃烧的特性,以燃油经济性和抑制燃烧模式频繁切换为目标,基于深度强化学习理论优化设计了能量管理策略。
基于发动机台架试验和电机有限元分析,在Matlab∕Simulink环境下建立了基于MAP的混合动力汽车模型并进行了标定。将整车作为环境,训练基于DQN的能量管理策略,并利用排序经验优先回放策略提升了DQN算法的收敛速度。
在WLTC和NEDC工况下验证了本文策略的效果,结果表明基于DRL的能量管理策略能在维持SOC的情况下,避免燃烧模式频繁切换,并且充分利用中小负荷HCCI燃烧,控制效果优于规则策略和A⁃ECMS策略,与动态规划的全局最优解接近。燃烧模式切换频率降低13%以上,燃油经济性提升6%以上。
本文提出的专用能量管理策略适用于多燃烧模式的混动系统。控制策略框架具备迁移能力,可进一步应用于其它多燃料、多燃烧模式混合动力系统的能量管理。
猜你喜欢
建材发展导向(2022年10期)2022-07-28 03:03:58
大众投资指南(2021年23期)2021-12-06 05:46:40
建材发展导向(2021年12期)2021-07-22 08:06:32
小哥白尼(野生动物)(2021年3期)2021-07-21 02:28:38
建材发展导向(2021年9期)2021-07-16 07:11:10
小学科学(学生版)(2020年1期)2020-01-19 06:02:06
中华诗词(2017年4期)2017-11-10 02:18:29
都市丽人(2015年2期)2015-03-20 13:32:31
汽车维护与修理(2015年6期)2015-02-28 12:17:16
汽车维护与修理(2015年2期)2015-02-28 12:15:44
