
多尺度融合超分辨率算法在无人机探测中的应用
2021-06-08 09:28李志朋赵长明张海洋张子龙
应用光学 2021年3期
李志朋,赵长明,张海洋,张子龙,吴 璇
(1.光电成像技术与系统教育部重点实验室,北京 100081;2.北京理工大学 光电学院,北京 100081)
引言
随着现代航空技术的发展与电子通信水平的提高,全球无人机数量飞速增长,在军事、民用领域都有着较为广泛的应用[1]。由于执行任务的飞行无人机具有低空、慢速、小型的特点,因此通常被称作“低慢小”目标[2],同时也在严重威胁着人身安全与设施安全。近年来对非合作低慢小目标的检测与识别取得了较多的关注,在该场景下,如何快速捕获视场中的疑似目标并做出准确的识别成为应用的关键。目前无人机的检测主要分为雷达探测[3-4]、光电探测[5-6]、射频探测[7]与声波探测[8]。由于无人机图像信息较为充分可靠,因此常被作为主要判定依据。对于远距离低慢小目标,其所呈数字图像中的像素数目极为有限,目标特征严重退化,轮廓特征不明显,且容易受到复杂环境的影响,因此做出准确的识别变得非常困难,常常与飞鸟、飞机或漂浮物等难以区分,造成误判或虚警[9]。针对以上问题,图像超分辨技术可以利用目标轮廓的先验知识,在低分辨率的区块中恢复出目标的高分辨率细节特征,比如李有为等在识别自然场景的交通标志等小目标时使用了SRGAN(super-resolution generative adversarial network)网络[10],提高了小目标检测的精度,mAP(mean average precision)提高了3.6%;黄露等在压缩视频超分辨率重建中使用CVSRnet(compressed video superresolution network)算法[11],提高了车牌识别的精度。图像超分辨率重建是指通过单幅或者多幅低分辨率图像重建得到相同场景的高分辨率图像。无人机探测超分辨重建属于单图超分辨,以视频中截取的单帧图片作为输入。基于CNN的图像超分辨率重建方法现今已成为超分辨任务的优选方案,它能充分利用先验知识,对图像细节进行高质量的恢复。随着SRCNN(super-resolution convolutional neural network)和FSRCNN分 别 在2014、2016年的提出[12-13],CNN在图像超分辨率领域的应用被大量研究,所涉及的算法主要有两大类型:首先是基于全卷积神经网络的直接超分辨率算法,该类算法训练较为简单,对样本量的需求不太大,但由于损失函数多为像素级的MSE(mean square error)函数,恢复出的高分辨率图像往往较为平滑,难以在细节纹理较多的图像中适用;除此之外,利用对抗生成网络成为另一种常用的实现路径,经典的代表有SRGAN[14]、ESRGAN(enhanced super-resolution generative adversarial networks)[15],该网络主要改变了网络的训练方式和损失函数类型,在训练方式上采用对抗形式生成的超分辨率图像更加清晰,具有较好的视觉效果,但GAN对噪声的处理较弱,对样本的需求量高,且生成器的参数量和密集程度往往较高,无法满足无人机识别实时性的要求。
为了解决图像超分辨率的精度与推理速度的矛盾,在FSRCNN基础上提出一种新的网络架构,即多尺度融合图像超分辨重建MFSRCNN(multiscale fusion super-resolution convolutional neural networks)。低分辨率图像同时进行上下采样得到多分辨率图像以保留更多的信息,并将多分辨率图像子网络并行连接,在整个过程中,通过在并行的相邻多分辨率子网络间多次交换信息进行多尺度的重复融合。与现有的广泛超分辨率重建的网络相比,MFSRCNN有两个好处:1)采用并行连接高分辨率和低分辨率子网的方式,重建过程中减少各分辨率图像信息的丢失,能够有效保留无人机的信息,有利于提高重建图像分辨率;2)采用重复的多尺度融合的方式,子网络信息不断交流融合,不同频率的图像特征通过整合,能够兼容低频成分和高频成分,对图像的细节和轮廓特征都具备较好的复原效果。经无人机真实数据验证,本文所提出的MFSRCNN算法在图像超分辨率重建效果上有了一定的提高,并利用YOLO验证了MFSRCNN算法在实际无人机探测中的可行性。
1 多尺度融合超分辨率重建算法
MFSRCNN算法通过卷积网络拟合图像特征提取、非线性映射、多尺度融合以及最终的重建,最后输出高分辨率图像结果,是在借鉴FSRCNN算法的特征提取与非线性映射思想基础上,结合反复的多尺度融合设计得到的模型。
1.1 FSRCNN算法
如图1所示,FSRCNN模型是一种基于SRCNN改进的单一图像的快速超分辨率重建卷积神经网络,而SRCNN网络结构十分简单,感受野比较小,提取的是非常局部的特征,细节无法恢复出来。
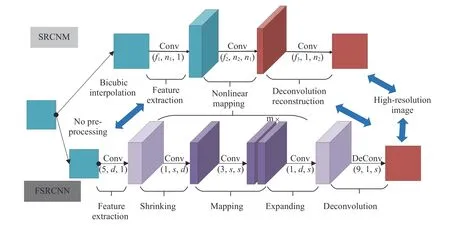
图1 FSRCNN模型以及与SRCNN的模型对比图Fig.1 Model comparison diagram of FSRCNN and SRCNN
FSRCNN在网络末尾采用反卷积层用于生成最终的超分辨率图像,减少了运算量。在网络结构上使用更多的卷积层与更小的卷积核来改变特征维数,在提升重建速度的同时保证图像重建质量[16]。FSRCNN重建速度快,但对于无人机这种较小目标的图像重建效果有限。FSRCNN中特征提取与非线性映射过程对于提高网络的运算速度是十分有启发性的,MFSRCNN算法同样采用更多的卷积层与更小的卷积核进行特征提取与非线性映射。
1.2 多尺度融合超分辨率重建网络结构
针对无人机图像目标较小、特征不明显的问题,基于FSRCNN设计了一个包含4个子网络并行的网络结构,见图2。

图2 多尺度融合超分辨率重建算法网络结构图Fig.2 Network structure diagram of multi-scale fusion super-resolution reconstruction algorithm
网络结构以4个不同分辨率的分支为主,低分辨率图像经过4×、2×、1×和0.5×变换后分别进行非线性变换,并将不同分辨率的feature map进行concatenate运算,用以融合不同分辨率特征。在特征融合阶段,不同频率的图像特征能够得到较好的整合,使其能够兼容低频成分和高频成分,对图像的细节和轮廓特征都具备较好的复原效果。
1.2.1 图像处理与特征提取
低分辨率图像到高分辨率图像,需要进行上采样。MFSRCNN上采样类似于FSRCNN,全部采用反卷积操作,增加感受野,改善图像质量,将重建过程转化为端到端的自主学习过程[17]。
通过卷积与反卷积对LR(low resolution)图像(100×100像素)进行upsampling与subsampled得到4种分辨率大小的特征图(400×400像素、200×200像素、100×100像素、50×50像素),作为4个并行的分支输入。并行网络从上到下依次命名为子网络1、子网络2、子网络3和子网络4。卷积在改变图像大小的同时进行4个尺度的特征提取。上采样过程中的反卷积在upsampling大于2时均采用多个串行反卷积(步长为2),具体过程见图3。

图3 图像处理与特征提取结构图Fig.3 Structure diagram of image processing and feature extraction
此网络结构中p取168,q取36,m取12。以子网络1为例,特征提取共168个卷积核,图4是前10个卷积核进行上采样与特征提取的结果。逆卷积后的图像放大到400×400像素,不同的卷积核提取不同的特征,某些卷积核对无人机轮廓较为敏感,例如卷积核1、7。某些卷积核对无人机内部特征比如4、5较为敏感。168个卷积核共同从轮廓、色彩、细节等方面提取无人机特征。
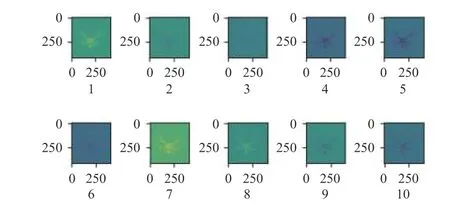
图4 子网络1中特征提取部分卷积核结果Fig.4 Partial convolution kernel results of feature extraction in subnetwork 1
1.2.2 非线性变换
以FSRCNN非线性变换为基础,通过1×1的卷积核进行降维,将维度由p降到q(p>>q),用于减少运算量;再经过N(N=2)个小的3×3的卷积层串联进行特征映射,卷积核的数目为q。以上操作在4个子网络上并行操作,如图5所示。
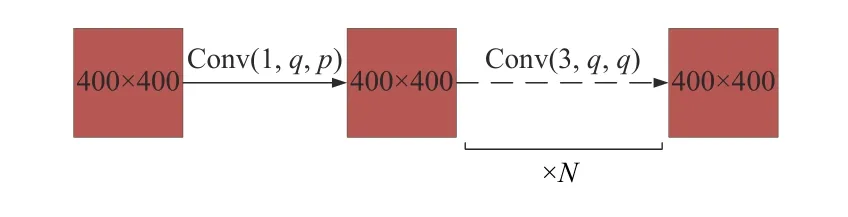
图5 非线性变换结构图Fig.5 Structure diagram of non-linear transformation
1.2.3 多尺度融合
多尺度融合是将不同尺度的特征图进行融合,增强图像细节,有利于提高超分辨率重建精度[18]。直接将不同分辨率的图像输入不同的子网络中,再进行特征融合,具体融合步骤见图6。
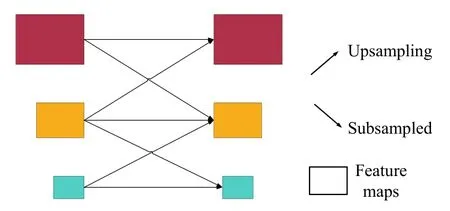
图6 多尺度融合示意图Fig.6 Schematic diagram of multi-scale fusion
如图6所示,不同子网络的特征图,分别做上采样与下采样调整到相邻子网络的特征图大小。每个子网络接收来自相邻并行子网络的信息进行融合。采用多次的特征融合,使子网络信息不断的交流融合,有利于超分辨率重建的目标细节特征提取。
图7为多尺度融合的过程,MFSRCNN相邻分辨率之间的feature map通过concatenate运算进行多尺度融合。以200×200像素 feature map为例,分别做卷积与逆卷积得到100×100像素与400×400像素的feature map,并与原100×100像素与400×400像素的feature map进行concatenate运算,得到对应尺度的融合结果。

图7 多尺度融合结构图Fig.7 Structure diagram of multi-scale fusion
1.2.4 图像重建
图像重建过程如图8所示,将4个并行子网络的特征融合结果分别进行特征提取,并通过1×1的卷积核进行扩充维度(扩充到p)解决低维度特征图的重建效果不好的问题。将4个并行子网络全部上采样到目标尺寸(400×400像素)进行特征融合并进行特征提取,最终得到3通道的超分辨率图像。

图8 图像重建结构图Fig.8 Structure diagram of image reconstruction
融合后的特征图中包含来自4个网络分支的3通道特征图,融合结果切片后得到特征图如图9。

图9 特征融合结果特征图Fig.9 Feature diagram of feature fusion results
融合结果中子网络1中的特征图图像轮廓更加清晰,细节比较丰富,含有较多的细节与轮廓信息,而网络的原始输入越小,其输出含有的轮廓与细节特征越少,低频信息越丰富。融合后的图像能够有效兼容高频信息与低频信息。图10是12个卷积核特征提取的灰度图。有些卷积核提取轮廓信息等高频信息,例如卷积核9,有些卷积核提取无人机内部(不包括纹理特征)的低频信息,例如卷积核1、2等。

图10 特征提取结果特征图Fig.10 Feature diagram of feature extraction results
在卷积层(反卷积除外)之后均接PRelu函数进行激活,加速训练过程,同时将FSRCNN中大的卷积核全部替换成多个3×3的小卷积核,保证重建质量。网络中全部采用零填充进行图像信息的恢复避免截断误差。卷积层中权值w采用Xavier初始化,反卷积层中采用正态分布初始化,参数b全部初始化为0。
1.3 模型训练
1.3.1 实验数据与硬件设置
常用的数据集没有包含低慢小无人机的数据集,本文采用的数据样本均为实验获取。样本原始图像大小为1 920×1 080像素,传感器为对角线8.467 mm(2/3英寸)的CMOS,焦距为8.1 mm~310 mm(光圈F1.8~F5.6)。样本数据如图11所示。

图11 实验数据示例Fig.11 Example of experimental data
实验采集样本数量有限,而现有数据集中很少有无人机的样本,故采用数据增强的方式扩充训练样本集。数据集增强可以减少网络的过拟合现象,通过对训练图片进行变换可以得到泛化能力更强的网络,更好的适应应用场景[19]。通过仿射变换、伽马变换以及一些裁剪工作,对无人机原始样本进行了数据集扩充,最后得到大约1 650个包含无人机的样本数据。
数据增强后,无人机数据样本依然有限。采用迁移学习的方式进行训练,先通过MFSRCNN网络对COCO数据集进行训练,得到预训练模型,提高模型的特征提取能力,并有效地防止过拟合现象[20]。通过fine-tune训练无人机数据实现无人机图像的超分辨率重建。
1.3.2 训练过程
目前超分辨重建领域常用的损失函数是Perceptual Loss与MSE。Perceptual Loss是将真实图片卷积得到的feature与生成图片卷积得到的feature作比较,使得高层信息(内容和全局结构)接近。网络训练速度快,在GAN中收敛效果好,具有高频细节信息[21]。MSE是目标变量与预测值之间距离平方之和,MSE loss虽难以避免细节上的模糊,但依然能得到不错的超分辨率结果。对于非GAN网络,MSE更为合适。故本算法采用MSE作为loss进行训练,并采用Adam优化算法。
无人机的输入数据为100×100像素,输出超分辨率大小为400×400像素,训练集与测试集中图片数量比例为4∶1。batch设置为8,初始学习率设置为0.000 1,并且在训练过程中设置一定的衰减。经过预训练与无人机数据训练后得到的loss曲线如图12所示。
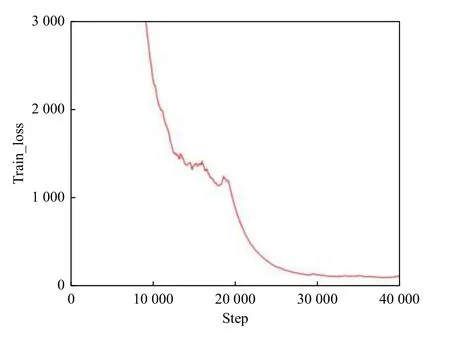
图12 训练过程中loss与step关系曲线Fig.12 Relationship curve between loss and step during training
图12中,前13 000个steps是对COCO数据集进行预训练,增强其特征提取能力。在曲线接近于平滑之后,开始迁移学习无人机数据,并设置学习率为0.000 1继续训练,step在30 000左右loss开始趋于平稳。如图13所示,无预训练重建结果PSNR=34.45,SSIM=0.814 4,经过预训练后PSNR=34.74,SSIM=0.824 2,预训练在一定程度上能够有效地增强重建细节,提升重建效果。

图13 有无预训练的超分辨率结果对比图Fig.13 Comparison of super-resolution results with and without pre-training
2 实验与结果分析
2.1 实验结果
2.1.1 实验结果分析
经过训练,得到无人机超分辨率4×重建结果,并与双三次插值(Bicubic)和FSRCNN重建结果对比,得到图14。

图14 MFSRCNN、FSRCNN与Bicubic重建效果对比图Fig.14 Comparison of reconstruction effects of MFSRCNN,FSRCNN and Bicubic
如图14所示,双三次插值、FSRCNN与MFSRCNN都对无人机模糊图像有一定的重建效果,其中双三次插值重建的图像比较模糊,失去了无人机的轮廓特征与细节特征,只是单纯地放大图像,而且会出现一定程度的黑边(可以通过算法改进去除),不利于后期的无人机识别。FSRCNN重建效果较好,比较清晰地展现无人机的轮廓特征,但重建结果中背景噪声较大。通过对比发现一方面MFSRCNN在明显地提高无人机图像重建效果的同时能够有效抑制背景噪声,提高图像的信噪比;另一方面,采用多次的多尺度融合加COCO数据集预训练,在超分辨率重建中不仅能更好地提取出无人机的特征,而且能在反复的多尺度融合中始终保留细节特征,有效重建出无人机的细节信息。为了更直观表示重建质量,将MFSRCNN算法与ESRGAN算法重建结果经beyond compare对比,得到图15。在细节方面,MFSRCNN结果更接近于ground truth,特别是对于重建目标比较大的情况。对比ESRGAN边缘信息更加丰富,重建效果更好。但是目标的高频细节还有部分缺失,有待于进一步的改进。

图15 MFSRCNN算法与ESRGAN算法重建结果对比Fig.15 Comparison of reconstruction results of MFSRCNN algorithm and ESRGAN algorithm
对4个子网络输出结果与超分辨率重建最终结果图进行傅里叶变换,得到图16。由频谱图可以看出,子网络1输出的高频信息丰富,轮廓与细节都较为明显,子网络2、3、4输出结果图高频信息偏少,低频信息比较丰富。超分辨率重建结果中高频信息与低频信息都比单独的子网络结果更加丰富,证明了特征融合对能够有效兼容高低频信息,对超分辨重建结果有一定的提升。

图16 4个子网络输出与超分辨率输出结果图和对应频谱图Fig.16 Results diagram of four subnetworks output and super-resolution output,and corresponding spectrogram
2.1.2 对比结果
重建图像的质量评价可检验超分辨率重建算法好坏,优化重建算法中的参数常用客观评价方法:峰值信噪比法(peak-signal-to-noise,PSNR)、结构相似性度量法(structural similarity index measurement,SSIM)等。
PSNR基于对应像素点间的误差,失真图像与原始图像的相似性通过计算对应像素点之间的差距来衡量。两个m×n单色图像I和K,如果一个为另外一个的噪声近似,那么它们的均方差定义为
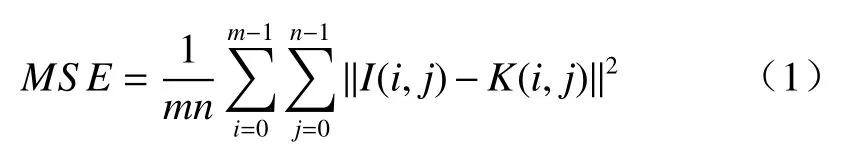
峰值信噪比定义为

式中MAXI2为图像点颜色可能的最大像素数值。
结构相似度度量方法是运用结构相似度指标,量化失真图像和原始图像之间的差异,评价失真图像的质量好坏,描述图像的质量,用亮度、对比度、结构3项信息相结合,与MSE和PSNR相比较,结构相似度度量方法与人类视觉特性更符合。
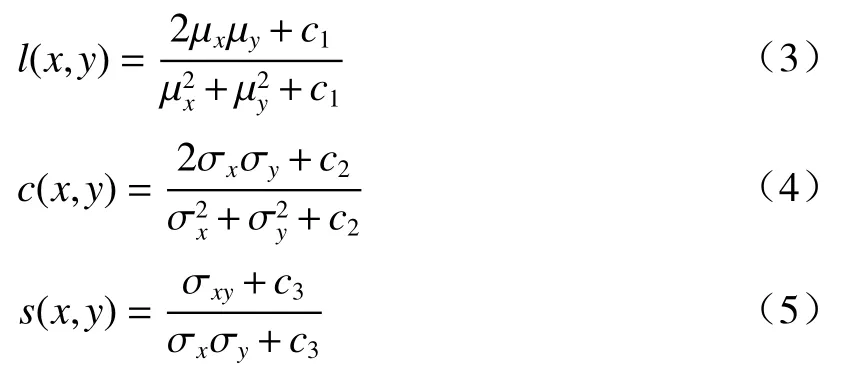
式中:µx为x的均值;µy为y的均值;σ2x为x的方差;σ2y为y的方差;σxσy为x和y的协方差;c1=(k1L)2;c2=(k2L)2;c3=(k3L)2为常数,避免除零,L为像素值的范围。取c3=c2/2,可以得到:

对MFSRCNN算法与其他经典的超分辨率重建算法对无人机测试集图像进行测试,并统计出在4×情况下不同算法下的PSNR与SSIM,得到表1。因为ESRGAN的损失函数采用Perceptual Loss,虽然重建视觉效果好,但是不适合采用PSNR进行衡量,故表1不列入ESRGAN对比。
根据表1得到MFSRCNN与其他算法性能与参数比较结果图,如图17所示。

表1 4×情况下不同算法对无人机测试集重建的PSNR与SSIM与参数对比Table 1 Comparison of PSNR,SSIM and parameters of UAV test set reconstruction by different algorithms in 4× case
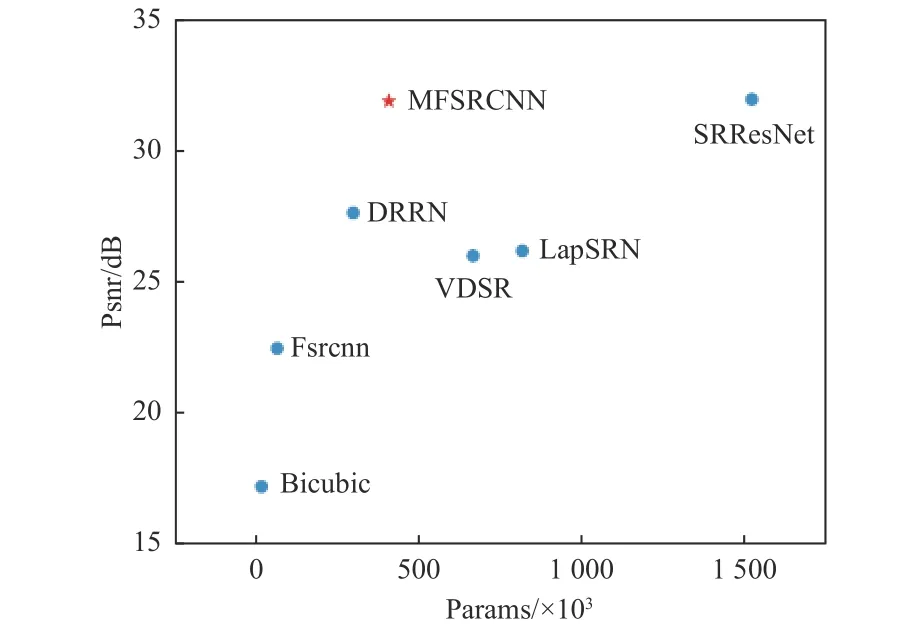
图17 MFSRCNN与其他先进的轻量级网络在Urban100数据集上4×的性能和参数比较Fig.17 4× performance and parameter comparison of MFSRCNN and other advanced lightweight networks on Urban100 dataset
MFSRCNN的总体框架与体系结构非常简单,但是比以往的很多模型更加有效,尤其是针对小目标的无人机超分辨率重建问题。MFSRCNN在模型尺寸与重建性能方面取得了很好的权衡。MFSRCNN虽然比FSRCNN、DRRN等轻量级网络模型参数多,但是其在无人机测试集上的效果远超出了其他网络模型。SRResNet虽然重建效果好,但是其网络过于复杂,网络参数是MFSRCNN模型的3~4倍,需要更多的网络训练与无人机超分辨率重建时间。
经实验验证:对于100×100像素的图像,在GPU运行条件下,MFSRCNN重建平均时间为0.033 s。在输入图像较小的情况下满足无人机实时探测的要求。
2.1.3 多尺度融合的作用分析
在保持原有网络参数和训练方法的基础上,将MFSRCNN中多尺度融合(即相邻分辨率之间的feature map进行concatenate运算)部分去掉,得到新的网络模型,训练得到结果与MFSRCNN对比结果如图18所示。

图18 有无经过多尺度融合对比图Fig.18 Comparison diagram with and without multi-scale fusion
经过对比,多尺度融合能够在一定程度上增强超分辨率重建的效果,轮廓与细节等信息更加清晰,对背景的复原程度更好,能够有效抑制噪声。多尺度融合的图像brenner函数大于无多尺度融合的图像,证明其能够有效提升重建清晰度。
2.2 YOLO检测结果
为了衡量无人机图像超分辨率重建效果,把无人机数据集中的部分数据重建前后的图像(200幅)依次输入YOLOV3网络进行无人机识别[22],得到部分结果如图19所示。

图19 无人机超分辨率重建前后通过YOLO网络检测结果图Fig.19 Diagram of detection results by YOLO network before and after UAV super-resolution reconstruction
图19中,LR表示重建前的图像,SR表示重建后的图像,数字代表检测的confidence score。从200幅重建前后的图像结果中选出部分典型数据如表2。
结合表2和图19可以看出,超分辨率重建对无人机的检测精度有了一定程度的提升,重建前的平均confidence score为80.73%,重建后为86.59%,平均提升6.72%。对于重建前LR无人机图像比较明显、score比较大的情况,检测提升效果不明显,置信度提升2%左右;对于重建前LR无人机图像不明显、score比较小的情况,重建后能够有效提升无人机分类预测概率与边界框定位精度;在某些无人机图像轮廓特征不明显、特征退化严重情况下,LR图像检测不出无人机,SR图像无人机可以检测到,提升了无人机的检测准确度;在较少情况下会出现无人机检测无提升甚至退化的现象,超分辨率模型还有待进一步的提升改进。结果证实MFSRCNN算法重建的有效性,具备较高的实际应用价值。
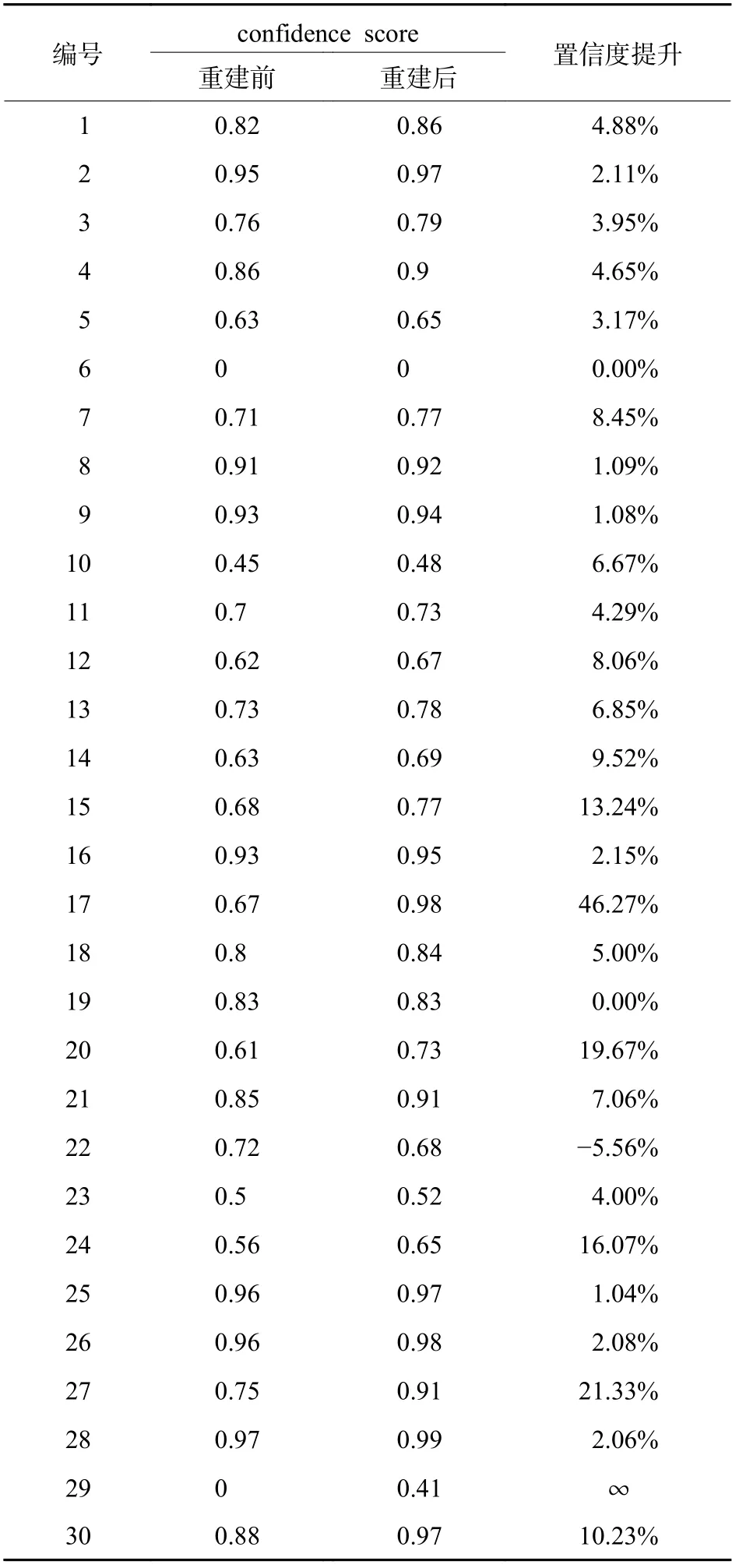
表2 部分无人机超分辨率重建前后通过YOLO网络检测结果Table 2 Detection results by YOLO network before and after partial UAV super-resolution reconstruction
3 结论
根据无人机图像目标小、特征不明显的特点,在FSRCNN基础上采用并行网络反复多尺度融合构建出一种新的超分辨率模型——MFSRCNN,对无人机图像进行超分辨率重建。在现有数据集上进行fine-tune对无人机数据集进行模型训练,最终得到超分辨率图像。该模型能够有效去除噪声,在增加分辨率的同时尽可能重建出无人机的细节与轮廓,提升了重建性能。通过与经典轻量级超分辨率重建算法进行对比,证明了MFSRCNN模型在模型尺寸与重建性能之间实现了较好的平衡,并通过YOLO网络证实了其后续在无人机检测识别领域的有效性。虽然MFSRCNN属于轻量级网络,能够基本满足无人机探测实时性的要求,但因为存在4个并行子网络,模型参数较多,还需在模型尺寸上做进一步改进,以提高重建速度,提升重建效果。
猜你喜欢
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06
数学物理学报(2019年3期)2019-07-23
电子制作(2018年19期)2018-11-14
家庭影院技术(2018年9期)2018-11-02
自动化学报(2017年5期)2017-05-14
自动化学报(2017年11期)2017-04-04
成都信息工程大学学报(2017年6期)2017-03-16
太空探索(2016年5期)2016-07-12
噪声与振动控制(2015年4期)2015-01-01
时代英语·高三(2014年5期)2014-08-26
