
有色噪声分布式多通道语音增强算法研究
2021-06-07 06:19范忠奇王善斌
科技创新与应用 2021年14期
范忠奇,王善斌
(山东理工大学 计算机学院,山东 淄博255049)
多通道语音增强技术是近年来发展起来的一种多功能麦克风系统。多通道语音增强算法主要包括经典波束形成算法、多通道维纳算法、多通道子空间算法、多通道最小失真算法以及多通道统计估计算法。这些多通道语音增强算法可以在增加麦克风数量的同时减少语音失真的背景噪声,但不同情况其性能不同。多通道维纳算法在平稳噪声情况下获得了良好的性能,但在非平稳噪声情况下性能较差。多通道子空间算法比维纳算法在非平稳噪声情况具有更好的性能,多通道统计估计算法通过假设清洁语音信号和噪声信号的傅里叶系数服从一定的概率分布,从而降低了背景噪声。卡尔曼滤波被称为一种有效的语音增强技术,不需要假设信号的平稳性,现有的用于语音增强的卡尔曼滤波算法都是通过提高卡尔曼滤波的AR参数的精度来实现的。本文提出了一种在有色噪声环境下的时域分布式多通道语音增强滤波算法。该算法是基于卡尔曼滤波的时域多通道语音增强算法。仿真结果表明,该算法优于几种传统的多通道语音增强算法,实现了更高的降噪和低信号失真。
1 分布式多通道模型及其滤波算法
1.1 分布式多通道语音模型
分布式麦克风系统,它可以准确地及时去除M嘈杂的发言。分布式多通道麦克风模型可描述为:

其中M是通道的数量,yi(n)和vi(n)是噪声并且是第n个样本和通道i中的噪声语音和背景噪声,si(n)是真正的源信号,ci∈[0、1]是时间不变衰减因子。在特殊情况下,M=1和c1=1,分布式多通道模型成为一个众所周知的单通道模型。我们的目标是从M嘈杂的信号观测{yi(n)}Mi-1中估计语音信号s(n)。
1.2 分布式多通道语音卡尔曼滤波算法
本文提出了一种基于卡尔曼滤波算法的分布式多通道语音增强的时间域在有色噪声的情况下,让语音信号s(n)被建模为AR过程:

ai是AR语音模型参数,u(n)是方差的高斯白噪声。用向量形式可表示为:

其中s(n)=[s(n-p+1),..s(n)]T,u=[0,..,0,u(n)]T,F是pxp矩阵定义为:

考虑到每个通道的语音信号都被有色噪声所破坏。让第i信道噪声vi(n)被建模为AR过程:

bij是AR噪声模型参数和wi(n)均为零均值和方差为(n)的白高斯噪声。式(4)可以写成向量形式:

其中vi(n)=[vi(n-q+1),..,vi(n)]T,wi(n)=[0,.,0,wi(n)]T,Gi是qxq矩阵

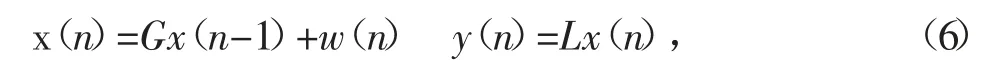
其中:
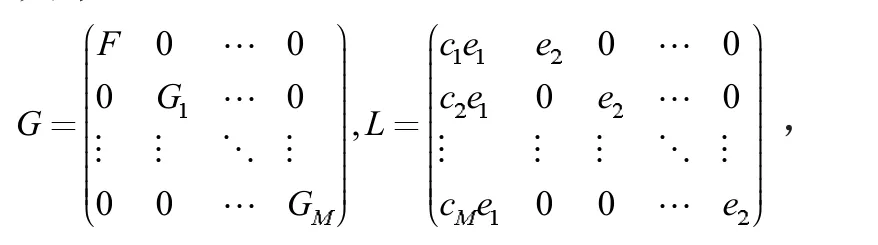
e1=[0,...,0,1]是1×p向量,e2=[0,0,…1]是1×q向量。
使用以下递归方程可以获得标准卡尔曼滤波估计:

在上述卡尔曼滤波估计的基础上,提出了一种分布式多通道语音增强的卡尔曼滤波算法,由L和N分别表示帧长度和帧数的算法,I(p+qM)×(p+qM)是(p+qM)×(p+qM)统一矩阵和e2=[0,0,1,0,.,0]是一个1×(p+qM)向量与qth元素是1和其他元素是0。通过该算法获取增强后的语音信号s^(n)。
2 实验仿真结果比较
2.1 实验方法
在实验环境中,房间是长10m,宽8m,高6m,声源位于(2、4、1.6)处。10个全方位麦克风的均匀线性分布麦克风阵列,相邻麦克风之间的间距约为30cm。第i麦克风位于(2.2,4+0.3x(i-1),1.6)。测试话语和噪声信号来自NOIZEUS语料库,所有信号的采样都是8kHz。随机从NOIZEUS数据库中选择20个不同的语音句子。这些句子连接在一起是一个清晰的信号。然后,将这些干净的语音加到噪声中,输入信噪比分别为5dB。在这里使用杂噪音。在MATLAB环境下进行了仿真。
2.2 实验结果与比较
实验中采用分段信噪比(SSNR)的改善评估降噪效果。SSNR定义为:

其中s(n)是原始语音信号,s^(n)是增强信号,N是原始语音信号的长度,Nl是l段语音长度。更大的SSNR值意味着更好的性能。

图1 在信噪比为5dB的杂音噪声中,6种算法与麦克风数量对SSNR的改善效果
在实验中,本文将所提出的算法与其他5种算法进行了比较。当麦克风数M=1,2,…,10时,输入信噪比为5dB。设p=6,q=6。图1描述了在输入信噪比是5db,以及在杂噪声的情况下当MMSE-LSA、MMSE-MSS、Wiener、子空间和KEMD-LP作为麦克风的数目M从1到10时,该算法的SSNR变化。首先看到,该算法在SSNR改善优于其他5种算法,特别是在增加麦克风数量方面。这表明,在麦克风数量大的情况下,该算法具有最大的降噪能力。通过增加麦克风的数量,可以大大提高算法的性能。图2显示了当输入信噪比值为5dB和M=4时,纯净信号、受有色噪声污染的噪声信号和6种增强信号的波形。结果表明,该算法产生的增强信号的波形比其他5种算法更接近于原语音信号。
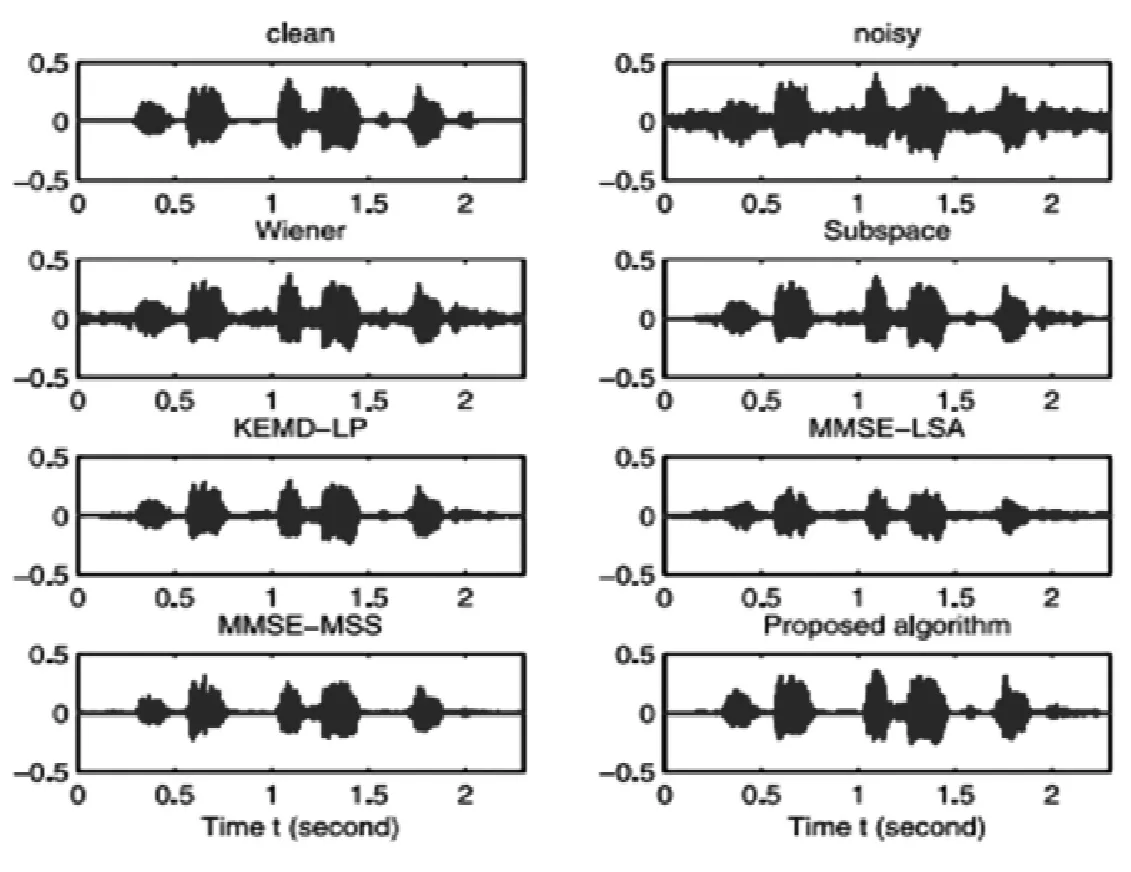
图2 在M=4、输入信噪比为5dB的杂音噪声情况下,6种算法处理后的纯净信号、噪声信号和6种算法处理后的增强信号的波形
3 结论
本文提出了一种基于卡尔曼滤波的有色噪声分布式多通道语音增强算法。仿真结果表明,与传统的分布式多信道语音增强算法相比,该算法具有更高的降噪效果。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
现代仪器与医疗(2022年1期)2022-04-19
北京航空航天大学学报(2021年7期)2021-08-13
科技与创新(2020年8期)2020-05-08
舰船电子对抗(2020年1期)2020-04-27
北京航空航天大学学报(2019年9期)2019-10-26
电子制作(2019年23期)2019-02-23
雷达学报(2017年3期)2018-01-19
北京航空航天大学学报(2017年9期)2017-12-18
小学科学(2016年12期)2017-01-06
