
隐私保护的基于图卷积神经网络的攻击溯源方法
2021-06-04 00:21:42张嘉伟高怿旸王申奥沈玉龙马建峰
计算机研究与发展 2021年5期
李 腾 乔 伟 张嘉伟 高怿旸 王申奥 沈玉龙 马建峰
1(西安电子科技大学网络与信息安全学院 西安 710071) 2(西安电子科技大学计算机科学与技术学院 西安 710071) 3(西安电子科技大学人工智能学院 西安 710071)
在各类网络安全问题中,高级持续性威胁(advanced persistent threat, APT)现在是各大企业、政府所要面对的最大问题.智能系统通常“外部安全堡垒”建设完善,但是,APT攻击多以商业信息和政治安全为攻击目的,具有高度的隐蔽性,往往经过了长期的经营与策划.APT攻击已在世界范围产生了巨大的危害,2019年4月俄罗斯背景组织APT28(Fancy Bear)攻击乌克兰2019年大选活动(1)https://www.fifthdomain.com/international/2019/02/13/ukrainian-official-hacking-intensifies-as-election-nears/,6月14日美国E-ISAC发现Triton针对美国境内智能电网的探测活动(2)https://www.wired.com/story/triton-hackers-scan-us-power-grid/.检测并对APT攻击进行溯源,已成为了国家、企业所要解决的重要问题.如果安全攻防信息持续不对等,系统方将很难发现APT攻击的蛛丝马迹.由于APT攻击表现行为复杂多变,使用传统人工规则分析方式将存在很多局限,人工智能技术是解决此类问题的重要手段.
APT攻击持续时间长,空间跨度大,前期采用社会工程学等手段对目标进行反复侦察并获取有用信息,其行为往往难以探测并具有伪装性.当攻击者获取目标的信任并能够以不被发现的身份潜藏在目标网络中时,便会盗取信息并不断扩大其感染范围,严重的会使整个目标网络瘫痪.一次完整的攻击事件由多个阶段构成,主要包括信息搜集、漏洞利用、建立据点、权限提升、权限维持、横向移动、痕迹清除7步,期间涉及了多个攻击程序和步骤,这为实现对攻击的快速溯源、构建攻击溯源图、及准确判断APT攻击的类型带来了很大的挑战.传统的攻击溯源会将日志字段进行关键字相似度关联匹配,由于攻击者的隐秘性以及在系统中攻击事件所产生日志的关联性,使得溯源事件关联分析时会产生状态爆炸问题.除此之外,传统的访问控制,流量监控等技术手段针对APT攻击的检测和溯源早已不能适用,针对越来越智能的攻击者和丰富的攻击手段来说,检测和溯源技术必须引入人工智能的手段来帮助攻击事件之间的关系查找及具体攻击类型的鉴别[1].此外,由于日志及流量数据中往往包含大量的重要数据和敏感信息,因此,在检测攻击时必须对日志数据的访问进行限制从而保护数据隐私.
为解决这一问题,现有的工作[2-5]对日志记录展开了分析,然而现有的溯源方案仍存在着大量问题.当下很多的攻击检测都基于单个日志,他们对DNS,HTTP等单一日志进行流量分析[1-2],然而APT攻击多是多步攻击,其攻击踪迹隐藏在多个日志之中,单一日志分析很难完整地提取攻击社区.一次完整的APT攻击过程中不只有异常事件,而传统单点检测的方法只能发现某阶段的局部异常,没有关注日志间联系,无法从局部异常还原出整体攻击过程.同时,异常检测技术存在着严重的误报情况.并且,因为日志间关系错综复杂,连接日志关系时会产生严重的状态爆炸[6-7],为解决因此产生的状态爆炸问题,现有的工作[8-11]很多集中在了数据的筛选与精简,然而其实际表现并不一定可以很好地优化数据关系,而且可能会影响数据的有效性.MARD[12]和Holmes[13]可以实时构造APT的攻击图谱,但是没有对攻击进行特定类型的识别,这不利于后续APT攻击的防范和分析.
针对APT攻击的溯源和分类问题,需要进行多日志的关系连接、解决状态爆炸和隐私保护问题,本文提出了具有隐私保护的图卷积神经网络攻击溯源方法.本文首先通过正则匹配处理多日志信息,将日志解析为格式化条目.然后通过设定的特征关系,构建多维特征向量,从而构造条目关系网.对构建好的关系网进行权重优化,输入社区检测模块,提取出需要的攻击社区.同时,在外包日志数据时,采用一种日志隐私保护方法来实现多用户安全数据共享.在数据共享方案中,我们不仅实现了半隐藏访问策略来保护隐私信息,还实现了基于时间的细粒度访问控制,任何用户只有持有有效的属性密钥才可以访问共享的日志数据.最后本文将构造好的溯源图利用图卷积神经网络进行特定类型的分类,告诉管理方具体的攻击类型.
本文模拟了目前流行的4种APT攻击,在Linux,Windows系统平台都有实验,过程中收集了可能会留有痕迹的多种日志,依据方案给出的特征维度,构建了事件之间的关系,并通过基于TensorFlow构造的GCN框架对攻击进行了有效的分类.实验结果表明了多日志分析可以更完善的展示攻击社区,并且通过对Louvain的优化,运算时间最多可有90%的缩减,准确率可达92%.所使用的日志隐私保护方法,不仅支持大规模属性集,而且通过引入高性能的质数群,计算开销减少了83%以上,密文的存储开销也缩减了50%以上.
本研究主要有4个创新点:
1) 提出基于监督学习的攻击关系图优化方法,解决了状态爆炸问题,首次利用剪枝判断、连接优化的方法,提升社区检测的速度与准确性.
2) 通过隐私保护的大规模属性基加密方法,实现了日志文件在服务器存储的多用户安全共享和细粒度访问控制.
3) 利用图卷积神经网络对构造的溯源图进行基于人工智能的有效分类,准确告诉安全管理员攻击的类型,方便后续的攻击防御.
4) 实验过程复现了流行的多种APT攻击,收集产生的多种日志数据.展示了本方法通过日志分析构造出完整的攻击社区,并对分析结果做出了评估,很好地证明了系统的有效性.
1 相关工作
人工智能攻击检测技术:现有方法[14-16]使用具有代表性的训练数据和序列处理技术,从过去的事件学习并预测接下来的事件.其中文献[14]识别日志条目之间的关系,但忽视了事件之间的关系.然而,日志级别的粒度不能反映攻击者的真实意图,使得安全人员不能有效地识别和防范相应的攻击.Deeplog[14]和Tiresias[15]使用LSTM算法学习攻击日志并且对攻击进行预测,APT自动分类器[16]研究真实APT的已有行为,NoDoze[17]学习异常的攻击事件的特征从而对攻击进行检测,PrioTracker[18]学习异常流量数据特征并对流量数据进行检测.但这些方法忽略了41%的APT攻击技术和使用的软件都是未知,它们不能简单地从历史数据中学习并且进行预测.当攻击者使用新型的恶意软件或者未知方法时,攻击就能避开检测.大多数方法只考虑多个日志之间的空间相关性或单个日志的事件相关性,没有融入人工智能手段,不能进行有效的分类.
通常攻击者在发动一个APT攻击破坏前,就已经开始在进入系统之前为其做准备,他们通常扫描并收集情报,以更好地了解一个目标如何工作及其潜在的弱点.对于APT的溯源,Log2vec[19]使用系统审计日志来检测内部威胁,UIScope[20]利用Windows事件追踪(ETW)日志也只能追踪到进入系统内部的攻击事件.这2个方法关注系统内部威胁而忽略了破坏系统之前的准备工作.在后续的因果分析工作中,会确立事件之间的关联关系,由于是通过字段匹配来进行关联分析,当前事件依赖于前面所有事件,即会产生状态爆炸问题[21-22],这会导致溯源图构造的分析结果不准确.为解决这一问题,SLEUTH[23]和MORSE[24]利用了编码可信度和数据敏感性的评估标签,但在APT场景中,我们不能从原始审计日志中找出标签.OmegaLog[25]构造了一个带有应用程序日志的通用起源图(UPG),但跨应用程序的事件因果关联增加了解决问题的难度.UIScope[22]将系统事件属性归为高级UI元素,这种方法不能普遍适用于系统.
最近,策略隐藏的密文策略属性基加密(Hidden Policy Ciphertext-Policy Attribute Based Encryption, HP-CP-ABE)方案[26]得到了广泛的关注和扩展.然而,这类方案中的访问策略本身可能会包含用户隐私,这给用户隐私带来很大威胁.因此,Nishide等人[27]在2008年提出了第1个部分隐藏访问策略的属性基加密方案,但是仅支持与逻辑访问策略;2018年文献[28]中提出了完全隐藏访问策略的方案以支持访问策略中的属性完全隐藏,多属性机构和多种访问策略,为了降低该方案的开销,文献[28]扩展了该方案并引入外包解密和可验证机制;由于完全隐藏策略存在高计算复杂度等缺点,文献[29]基于合数阶群提出了一种具备解密测试的部分隐藏访问策略方案;之后,文献[30]提出了基于质数阶的部分隐藏访问策略方案以提高效率;2020年Han等人[31]提出了一种支持可撤销可追踪功能的部分隐藏策略的属性基加密方案.然而,该方案无法提供基于时间的用户密钥有效期的功能.
本文提出基于时间的细粒度访问控制.只有具有足够权限的用户在有效访问时间范围内才可以访问存储在服务器的共享日志数据.同时,共享日志数据的机密性需要得到保护.由于访问策略是随着密文一起在服务器存储和共享,因此,访问策略的值能够隐藏,保证用户隐私不被泄露.
2 攻击示例
一次完整的APT攻击涉及了多个程序、多个文件,其攻击痕迹分布在了多个日志之中,如图1所示.阶段1用户点击了钓鱼邮件中的链接,通过链接下载了含有恶意命令的文档;阶段2用户运行文档后,通过执行恶意命令,打开了PowerShell后门;阶段3便可访问用户数据、植入病毒.攻击针对性强,隐蔽能力高,完整的APT攻击过程不仅仅有异常行为,还有很多正常的程序过程,而且各阶段攻击采用的手段极为丰富,现有的异常检测系统并不能很好地对此进行分析.对此,本文给出了基于多日志的攻击社区提取方法.
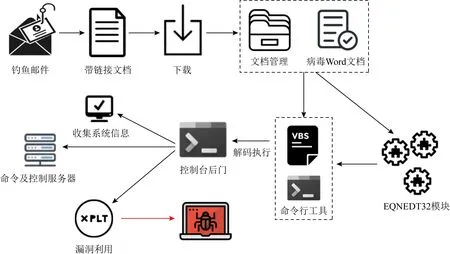
Fig. 1 Microsoft Office memory corruption vulnerability图1 Microsoft Office内存损坏漏洞
3 系统概览
完整的系统概览,如图2所示.整个系统包含了4个实体:密钥产生中心、日志生产者、日志分析者和服务器.其中①密钥产生中心,该实体负责初始化整个系统,生成系统公共参数和主密钥,并为系统中的用户分发密钥;②日志生产者在运行过程中生产大量的日志数据,为了减轻系统的本地负担,需要将日志数据加密后上传至服务器进行共享;③日志分析者负责各种日志数据的分析,并检测其中的攻击.在日志分析之前,该实体需要从服务器下载具体的加密日志文件并进行解密;④服务器提供海量日志存储和共享服务,并根据用户的请求返还对应的日志文件.
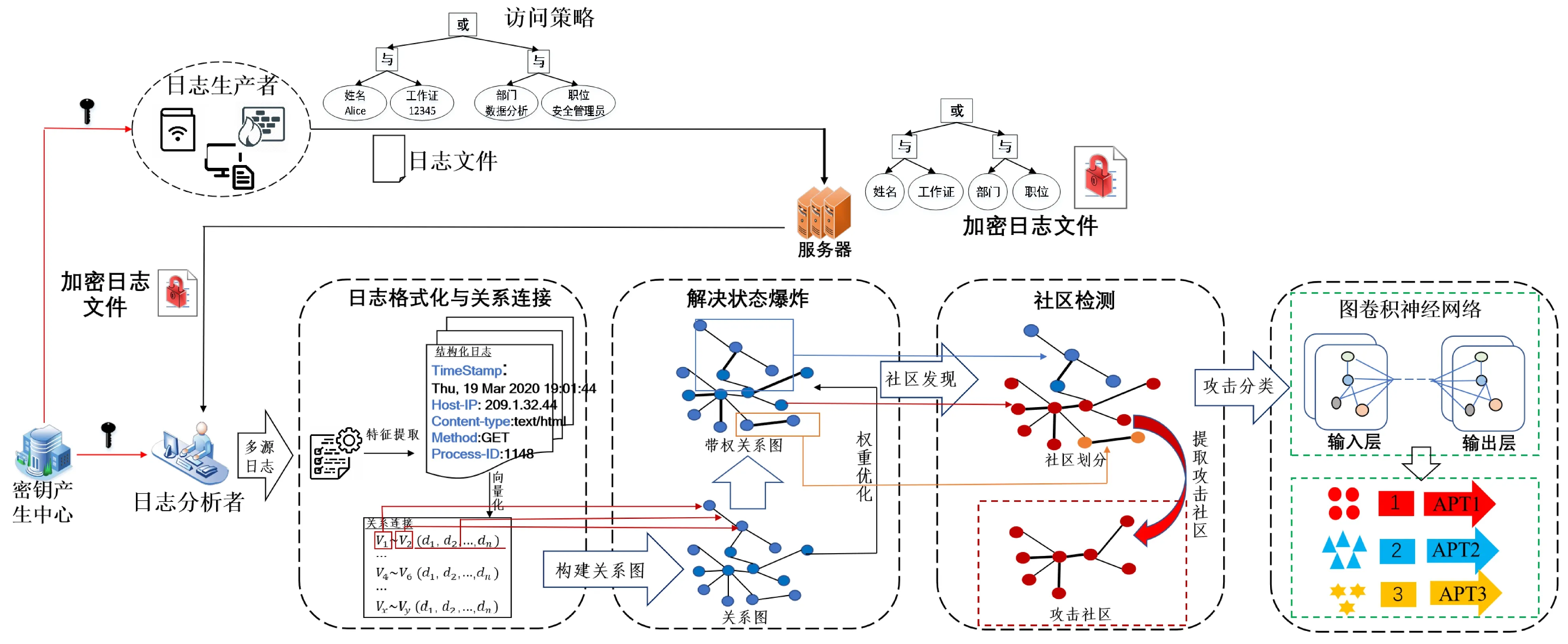
Fig. 2 Atlack provenance system framework图2 攻击溯源系统框架
本文系统运行过程分为4个部分,通过多个处理模块,提取所需要的攻击社区,从而更好的分析与解决APT攻击,并对攻击进行分类.阶段1,本文方法中的日志生产者收集的多种日志信息(如firewall日志、网络日志、系统日志)加密存储到服务器中.在需要日志分析时,合法的日志分析者从服务器中获取日志密文并解密.然后,日志分析者依据预设的提取字段,解析为信息完整且易于系统操作的结构化日志条目.将条目节点依据特征关系连接,构成关系图.因日志关系连接紧密,关系图的构建会产生的严重的状态爆炸,所以,阶段2本文方法采用了监督学习的方式,重构关系图,生成带权关系图.在阶段3进行社区检测,划分社区.通过社区发现提取所需的攻击社区.最后,本文利用图卷积神经网络对划分的社区进行攻击分类.
4 系统设计
4.1 日志格式化与关系链接方法
我们通过爬虫、抓包等方式收集系统、网络(HTTP,DNS,UDP/TCP)、应用(Chrome,Email,Office)等产生的日志,输入解析程序.解析程序中,将所需的特征量表达为正则式通过正则匹配方式,解析日志,如将系统的DNS日志“26-June-2020 09:18:46.056 queries:client 192.168.1.106#39164(www.baidu.com):query:www.baidu.com IN AAAA+(45.116.155.55)”解析为表1所示的结构化实体:
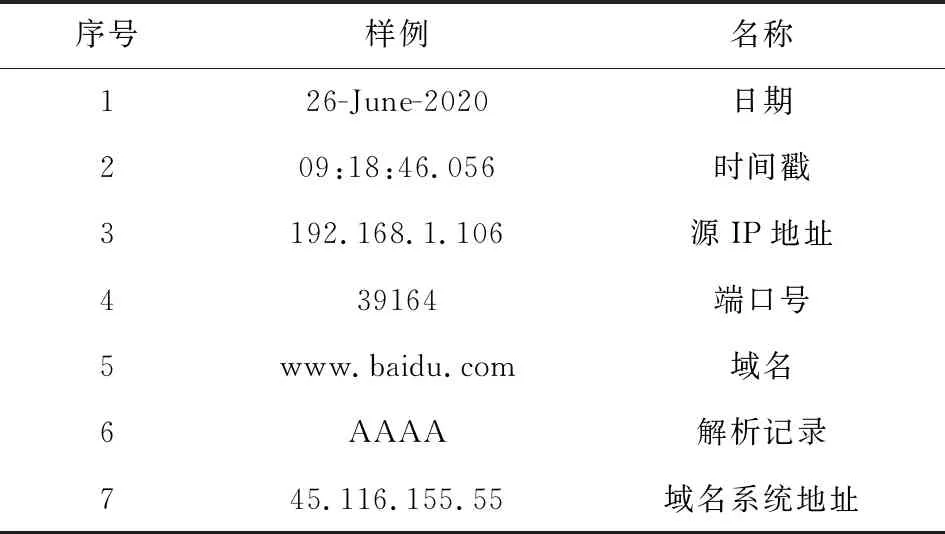
Table 1 Structured Entity表1 结构化实体
表2给出了解析中预设提取的条目特征,如进程号、端口号等,我们在表3中给出了这些特征的关系连接.
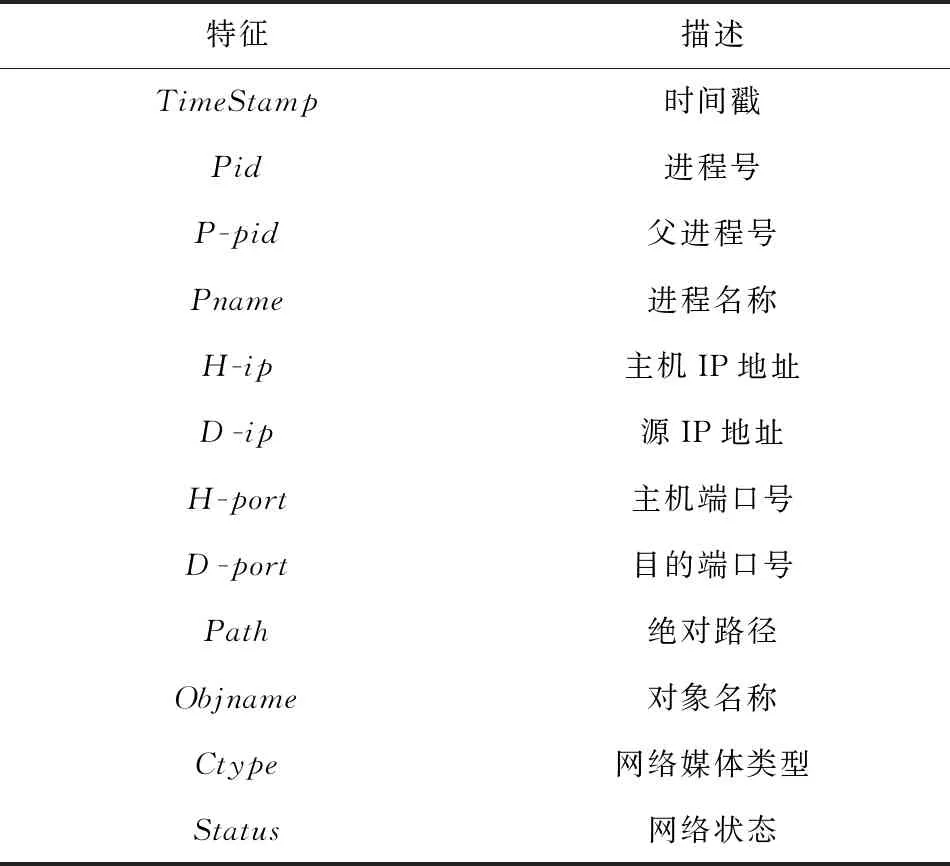
Table 2 Feature Description表2 特征描述

Table 3 Feature Relation Connection表3 特征关系连接

续表3
d1:在一个阈值时间内的事件往往有一定的相关,所以我们在该维度通过时间设定了关系的连接.如我们接受钓鱼邮件、下载病毒文档、执行文档会发生在同一时间段下.
d2~d4:APT攻击在靶机中多是由多个进程多次攻击完成,所以d2~d4维度表示了进程的相关性.如一个进程的溢出,从而产生新的进程,发起真正的攻击,所以进程号、名称、进程的父子关系都可以很好地联系2个日志事件.
d6~d10:网络攻击中检测IP地址、端口号、传输类型、传输状态是否相同,可以很重要地反映攻击来源的相关性、攻击方式的相关性,所以为其建立了特征联系.
d11~d13反映了进程与网络路径对文件的访问,如某一网络事件u下载恶意程序,另一进程v执行了该程序,则u和v应属于同一攻击路径.或者是进程A创建了恶意对象obj,而进程B访问了obj,进程A,B间也应存在攻击联系.
将解析后的格式化数据输入,通过日志条目的特征关系连接节点构成未加权无向图.形成一个n维网络图G(V,E,D).其中V是一节点事件集合,表示日志条目,E是日志条目间关系构成的边,D是n维的特征关系.最终形成了V×V×D的3维矩阵M,i和j表示2个节点条目,则Mi,j,k=1表示节点i和节点j间存在第k维的关系,Mi,j,k=0则表示节点i和节点j间没有关系.E中的边e可以表示为{(i,j,d1,d2,…,dn)|i,j∈V,dk∈D}.
4.2 解决状态爆炸问题
关系构图后,因日志条目间的关系错综复杂,不对特征量进行权重分配,会出现很明显的状态爆炸现象,而现有的很多攻击分析没有解决状态爆炸问题,直接对构成的关系网络图检测,所得结果会因攻击社区与非攻击社区间的关系连接产生很大的影响.为了解决这一问题,我们给出了使用监督学习优化权重的方法.我们将日志条目分为A,B社区,其中A社区包含攻击相关的日志条目,B社区包含攻击无关的日志条目.则eA,eB分别表示A,B社区内部的边,eAB为2个社区间的边,为了更好地区分攻击社区与非攻击社区,我们需要使eA≫eAB且eB≫eAB,所以我们使用了Logistic Regression,通过学习找到一个权重向量α,可以使权重关系满足不等式条件:
(1)
为了防止α对边加权后出现负权,我们通过函数设置将权重范围映射到[0,1],
(2)
对m条训练边,定义E=(xi,yi),i∈[1,m],xi表示第i条训练边e,若e∈eAB,则yi=1,否则yi=0,构造函数g:
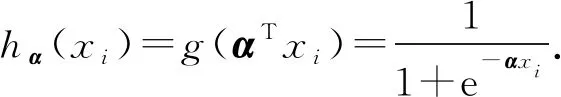
(3)
我们用hα(xi)表示e∈eAB,yi=1的概率,反之,概率为1-hα(xi),我们用对数似然法最小化成本函数:
(4)
4.3 社区检测方法
关系图加权后,我们给出了增强型Louvain算法对节点进行分类,找出攻击社区.
社区发现中通过模块度评估一个社区网络划分好坏的程度.其定义为
(5)
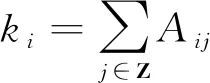
4.3.1 社区划分
将图中的每个节点初始化为独立的社区,然后对每个节点i,依次尝试分配到其邻居节点所在的社区,计算移动前后的模块度变化ΔQ,并记录ΔQ最大的邻居节点,若max ΔQ>0,则把节点i分配给ΔQ最大的居节点所在的社区,否则不移动社区.实验发现,节点i从A移动到另一社区B后,我们只需将不在社区B中节点i的邻居节点加入节点判读队列即可,无需判断全部节点.这样可以大幅提升算法速度,且对分区准确率影响很小.
算法1中,先将每个节点初始化为单节点社区,设置一个空队列,节点以随机顺序添加到队列中,然后我们从队首取出节点,通过质量函数,判断该节点是否应该移动至其他社区,若该节点被移动,则会将不属于新社区且尚未加入队列的所有邻居节点加入队列,然后我们不断从队列中取出节点进行移动操作,一直持续到队列为空.
算法1.快速移动节点算法.
输入:图G;
输出:节点所在社区C.
①FastMoveNodes(G);
②C←Initial(G);
③Q←Queue(V(G));
④ whileQ≠∅ do
⑤v←Q.pop();
⑥best_commnuity←SelectBeatCommunity();
⑦N←{u|(u,v)∈E(G),u∉
(best_community∪Q)};
⑧Q.push(N);
⑨ end while
⑩ ReturnC.
4.3.2 连接优化与节点聚合
社区划分过程中,每次仅考虑单个节点的移动,因此可能会出现当1个节点离开社区后,社区内节点断开的情况,为了解决在社区划分过程产生的连接不良,我们对划分的后社区进行了进一步的连接优化.
在划分社区后,对每个社区进行精炼,然后基于精炼社区聚合网络,避免聚合网络时会将断开的社区聚合为新的节点.并且在精炼划分过程中,使用贪婪移动限制太大,以至于不能达到最优划分,而通过随机性的选择社区允许更广泛地探索分区空间.所以我们让节点可以与使模块度增加的任意社区随机合并,模块度增加越大,移动可能性便越大.其中社区的随机选择程度通过参数θ>0影响.
分区精炼算法中,首先将G中的每个节点初始化为一个单节点社区,对于本地移动后划分好的社区,我们通过判断其节点的连接度是否良好,选择连接良好的节点进一步分析,对于良好连接的节点集合中未被合并的点,我们挑选连接良好的社区,将节点依模块度的提升随机移入,未被并入社区节点单独成为社区.
基于精炼分区,我们对整个网络图进行压缩,将一个社区的节点压缩为一个新的节点,社区内节点间的边权转换为新节点的自环权重,社区间连接的边权转换为新节点间的边权.然后重新执行社区划分.
4.3.3 基于GCN的网络威胁分类
图是一种常用的数据结构类型,它由若干个顶点以及边组成,通过边可以将顶点之间的连接关系进行直观的表示.CNN卷积神经网络能对目标的特征信息进行提取,从而学习到输入与输出之间的映射关系.但由于拓扑图中每个顶点的度都不同,因此CNN在非欧几里得数据上无法保持平移不变性.而GCN可以较好地解决这一问题,提取拓扑图的空间特征.
GCN是一种基于图的深度神经卷积网络,它能利用拉普拉斯矩阵对图的特征进行分析,从而完成分类等工作.GCN结构通常可分为输入层、若干隐藏层和输出层,其中隐藏层用于完成图上的卷积操作.
假设无向图G=(V,E),其中V,E分别代表顶点和边的集合.矩阵X,A分别为节点的特征矩阵和邻接矩阵.则GCN的层间传播规则为
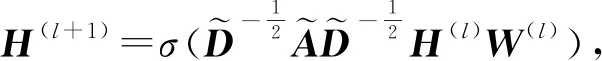
(6)
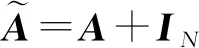
对于一个2层的GCN模型,其前向传播公式为
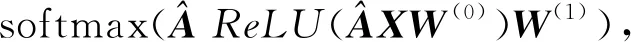
(7)
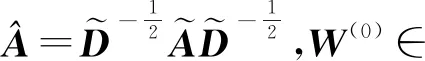
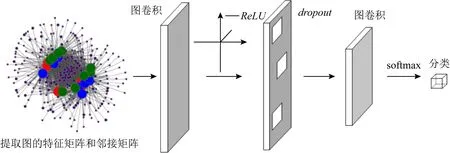
Fig. 3 Two layer GCN model图3 2层GCN模型
对于图3所示的2层GCN网络,分别使用ReLU和softmax作为激活函数.其中s为输入,ReLU将输入s与0取最大值后输出,对输入具有单侧抑制的作用,使神经元具有稀疏激活性.
使用ReLU激活函数可以解决非线性问题,有助于神经网络的快速收敛,ReLU表达式为
ReLU(s)=max(0,s).
(8)
在输出层我们使用softmax作为激活函数,归一化后每个元素的输出为
(9)
softmax函数可以将输出映射到(0,1)区间内的某个值,且各输出的加和为1.若将映射后的输出视为概率,则可以选取概率最大的节点作为预测目标,也就是预测标签.
对于本文所需要解决的分类问题,我们使用交叉熵误差作为损失函数:
(10)
其中,M为类别的数量;yic为指示变量(取值为0或1),若类别与样本i类别相同则取1,否则取0;pic为观测样本i属于类别c的预测概率.
在训练过程中,我们使用梯度下降法对权重矩阵W(0)和W(1)进行训练,每次训练迭代对整个数据集进行批量梯度降.并通过dropout向训练过程中引入随机性,防止模型过拟合,提高泛化能力.
在验证模型的有效性时,只需把样本送入训练完成的网络中即可得到预测标签.例如输入样本图的邻接矩阵A和特征矩阵X,根据GCN网络的前向传播公式式(7)以及训练好的权重矩阵,可以得到网络输出,并用softmax激活函数对输出进行归一化处理,选择最大概率的输出所对应的标签作为预测标签,并与真实标签进行对比,验证模型预测的准确性.
4.4 日志隐私保护方法
任何一种日志分析方法,都需要大量的日志数据作为支撑,这需要各种系统,包括资源受限的系统,不停产生大量的日志数据.因此,需要将日志数据外包存储到服务器中进行共享,以减轻系统的本地负担.
在图2所示的系统框架中,根据文献[30],整个系统运行时,共享服务器被认为“半可信”的,该实体按照指定协议提供服务,但是可能会通过分析用户日志数据获取隐私和机密信息.日志生产者被认为是可信的且不与服务器进行串谋.密钥产生中心被认为是可信的并且不与任何一方串谋.日志分析者被认为是不可信任的,存在一些恶意的日志分析者非法访问共享日志并且泄露其中的敏感和隐私信息,甚至篡改日志文件以影响其他日志分析者的分析结果.而日志文件包含大量的用户隐私和敏感信息,如果共享的日志文件被恶意日志分析者攻击或者被服务器分析和窃听,将会对用户隐私造成重大危害.因此,我们设计了一种新颖且高效的日志隐私保护方法.本文方法主要用于保护日志文件中敏感和隐私数据的安全共享.
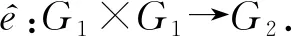
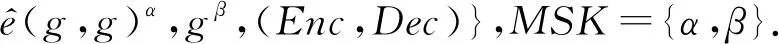
(11)
其次,密钥产生中心注册并校验用户的合法性,同时根据用户的属性集合生成对应的私钥,并指定该用户私钥的有效时间.对于一个用户u,系统选取一个随机数r∈Zp对其进行标识.而该用户的属性集合Su中的每个属性ai∈Su,计算对应的私钥元素Di=gairμ-β r.然后,系统对该用户设定一个密钥有效时间Tv,并且根据该有效时间Tv的形式化表示:
T=(δ1,…,δm,…,δk),
对于第m个时间元素δm,选择一个随机数σm∈Zp计算对应的私钥元素:
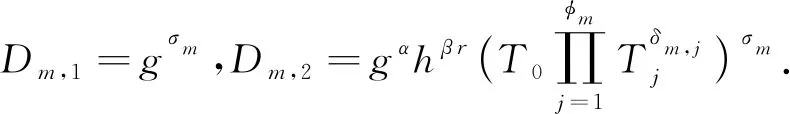
(12)
最后,密钥产生中心生成用户u的私钥为
SKu={D0=gβ r,D1=gr,{Di}ai∈Su, {Dm,1,Dm,2}m∈[k]}.
(13)
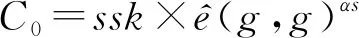
Cx,1=hλxμtx,Cx,2=g-txvx,Cx,3=gtx,
(14)
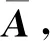
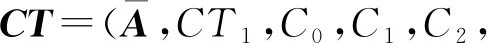
(15)
日志密文生成之后,日志生产者将该密文上传到服务器中,以节省本地的存储空间.
当日志分析者需要分析日志检测攻击时,从服务器请求得到加密日志数据CT,用自己的密钥SKu按照步骤进行计算:
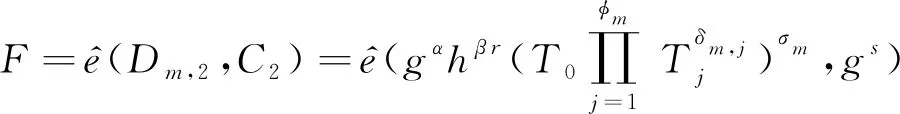
(16)
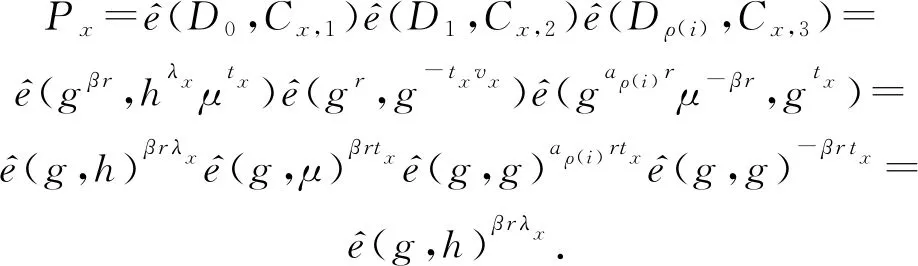
(17)
当且仅当日志分析者拥有足够权限时,即用户私钥中嵌入的属性值aρ(i)和密文中嵌入的访问策略值vx一致(aρ(i)=x),我们可以得到结果:
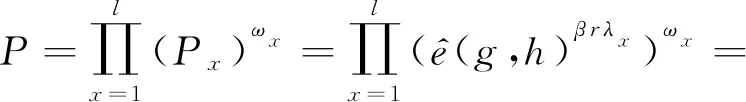
(18)
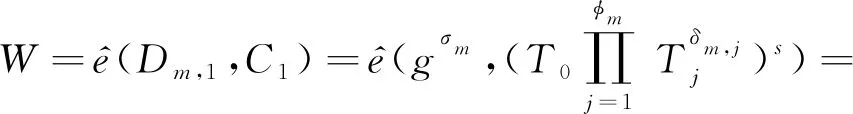
(19)
当且仅当日志分析者所持有的密钥在有效范围内.
最后,对称会话密钥ssk可以通过计算获得
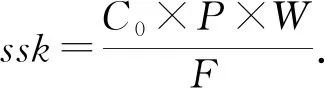
(20)
同时,明文数据可以通过m=Dec(ssk,CT1)进行恢复.日志分析者即可对日志明文进行相关攻击检测分析.
5 实验与结果
我们使用恶意软件数据集CCCS-CIC-AndMal-2020对增强型Louvain算法的计算速度提升进行了验证,并且对目前4种常见的APT攻击进行了仿真复现实验,以此来评价本文方法在图卷积神经网络攻击溯源中的检测效果.
5.1 数据集
在时间复杂度优化效果的验证部分,我们选用了恶意软件数据集CCCS-CIC-AndMal-2020.该数据集包括20万个良性和20万个恶意软件样本,总计40万个android应用程序,其中包含14个突出的恶意软件类别和191个恶意软件家族.
5.2 攻击溯源性能分析
在检测效果的对比部分,我们选取了表4所示的4种常见APT攻击漏洞来进行仿真复现实验,分别用本文方法与HERCULE方法进行攻击溯源,并将2种方法的检测准确性进行对比.

Table 4 Four Common APT Attack Vulnerabilities表4 4种常见APT攻击漏洞
增强型Louvain算法通过对社区划分的移动过程进行优化,大幅提升了算法的执行速度.为了更直观地展示该算法对于整个社区检测过程时间复杂度的优化效果,我们对比了本文方法和HERCLUE在同一数据集下进行社区检测所消耗的时间成本.
图4是2种算法的运行时间对比图,可以明显看出,HERCULE方法在该数据集上的平均执行时间为80.6 s,而本文方法的执行时间平均为8.2 s.图4中的实验结果证明:相比于HERCULE方法,本文方法时间优化率大约在90%左右.这种优化效果在算法检测大量节点或者进行多次迭代的过程中体现的尤为明显.
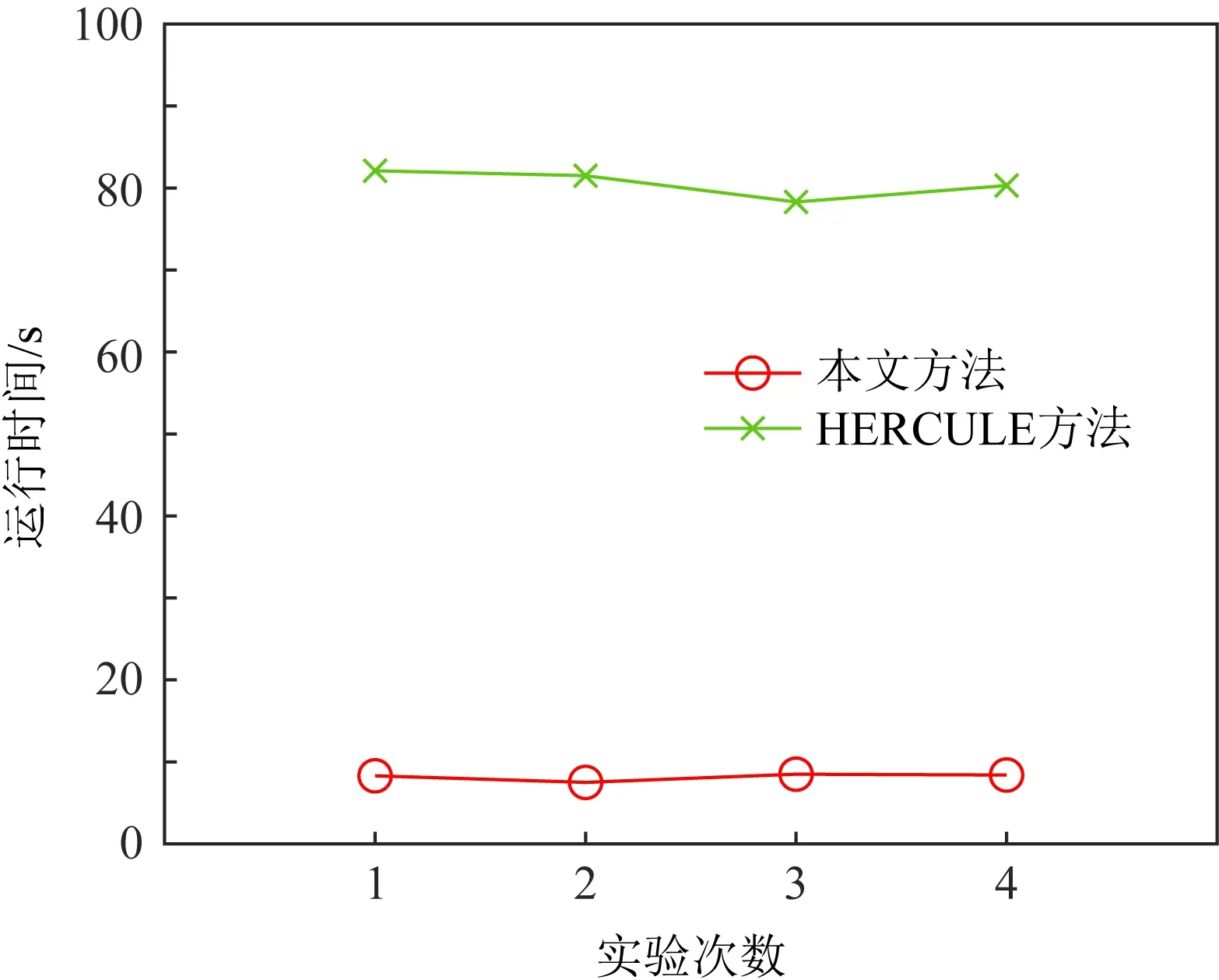
Fig. 4 Running time comparison between our method and HERCULE method图4 本文方法和HERCULE方法运算时间对比
另外,本文方法对社区划分过程中产生的连接不良的社区进行了优化,因此大大减少了无关日志节点在社区检测中的错误连接,提高了社区发现算法的精准度.为了对比方法在社区检测中的执行效果,我们用F1分数对其识别质量进行衡量.把正确分类为攻击日志的节点数量,错误分类为攻击日志的节点数量,正确分类为无关日志的节点数量和错误分类为无关日志的节点数量分别记为tp,fp,tn,fn.
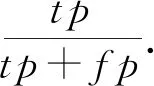
我们对比了该方法、HERCULE方法和PROBLEMCHILD方法.如图5所示,对于4种APT攻击的检测效果.在最坏情况下,如APT1检测中,本文方法的F1分数也可达到0.87,而HERCULE方法仅为0.74,PROBLEMCHILD方法更是低至0.68;而最优情况下,如APT3检测中,本文方法的F1分数可达0.94,HERCULE方法和PROBLEMCHILD方法分别为0.83和0.73.因为本文方法在检测中优化了连接不良的社区,所以可以大幅减少攻击相关的事件和与攻击无关的事件之间的错误连接.更好的事件划分有效地提高了检测系统的性能,对比HERCULE方法和本文方法的平均F1分数,分别为0.77和0.89.本文方法的检测效率平均提升了16%.对比PROBLEMCHILD方法,检测效率平均提升了20%.在图6中,我们展示了图卷积神经网络攻击溯源的可视化输出.方形节点所在的社区是与攻击相关的社区,圆形节点所在的社区则是与攻击无关的社区.通过对攻击社区进行分析,我们能够完成对攻击者恶意行为的重构和复现.
以图6中CVE-2019-1367所构建出的攻击社区为例,这是一个IE浏览器脚本引擎内存损坏漏洞,攻击者可以利用此漏洞破坏内存,获得用户的当前权限,并执行任意代码.如果当前用户拥有管理权限,攻击者可以在系统上执行各种操作,从创建具有完全权限的新账户到安装程序甚至修改数据.
在仿真实验中,我们利用本文方法对攻击行为进行了日志溯源,成功重构了3种攻击行为:1)攻击者发送电子邮件,并诱导目标打开Gmail中的链接,查看攻击者提前利用该漏洞构造的恶意网页.2)攻击者成功获取了目标客户机的管理员用户权限并与C&C服务器的IP地址192.168.2.15建立了反向TCP连接.3)攻击者浏览了不同的文件夹和文件.找到目标文件后,在命令行中启动FTP客户端,将文件上传到IP地址192.168.2.15.
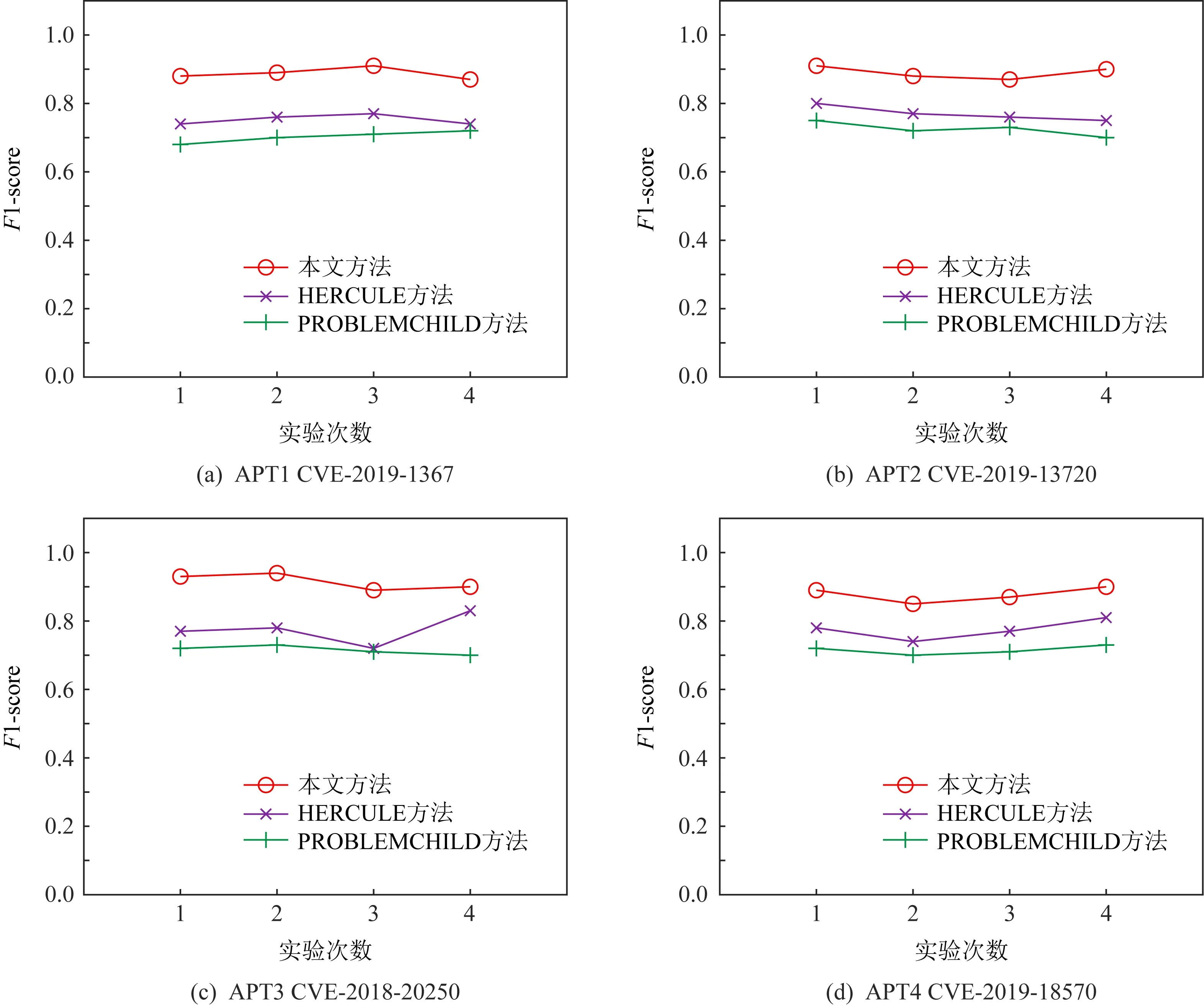
Fig. 5 Comparison of the detection effect of this method with HERCULE method and PROBLEMCHILD method图5 本文方法与HERCULE方法、PROBLEMCHILD方法的检测效果对比

Fig. 6 Visual community graph of APT attack图6 APT攻击的可视化社区图
5.3 GCN分类准确率对比
为验证本文使用GCN作分类的有效性,我们将其与4种其他的方法进行比较验证:
1) 深度游走(DeepWalk)[32]使用随机游走(random walk)的方法在图中对节点进行采样,产生相应的节点序列.然后用skip-gram模型对序列进行向量学习.
2) 半监督节点嵌入(semi-supervised embedding, SemiEmb)[33]可以将图数据映射为低维稠密向量,从而获取图的拓扑结构等相关信息.
3) 独立成分分析(ICA)[34]利用源信号的独立性和非高斯性,从多维统计数据中分离出独立分量.ICA可以在源信号和线性变换未知的情况下,从观测的混合信号中估计出源信号.
4) BiLSTM-GCN[35]将网络流量数据分解为基于IP的网络流,并基于网络流对IP信息进行重构,最后利用GCN模型从所有IP中检测出APT攻击的异常IP.
模型的测试结果如表5所示,我们使用本文方法对不同的威胁类型进行了分类测试,并用DeepWalk,SemiEmb,ICA,BiLSTM-GCN 4种方法作为对照.结果表明:对于4种不同类型的攻击,本文所采用的GCN模型的分类准确率均显著优于其他4个模型.
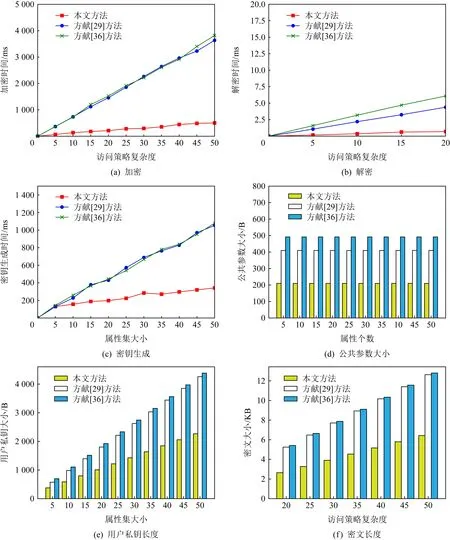
Fig. 7 Scheme performance evaluation图7 方案性能评估
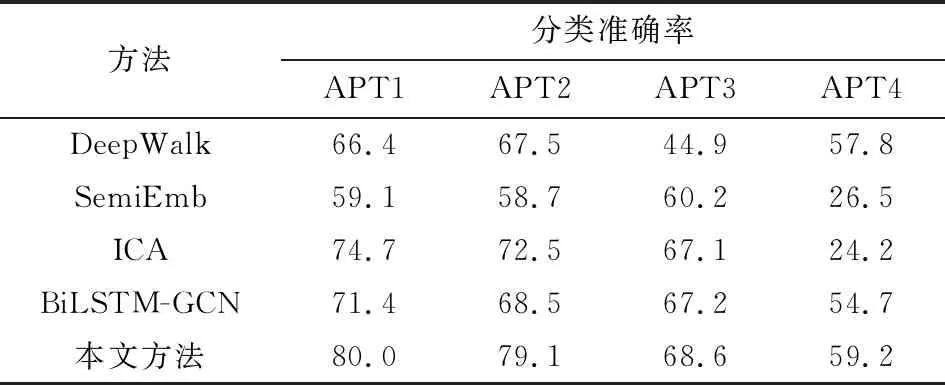
Table 5 Comparison of Classification Accuracy表5 分类准确率对比 %
相对于传统方法,本文结合GCN能有效对图的特征进行提取并充分利用节点的特征关系,从而提高分类精度,得出较好的分类结果.
5.4 隐私保护性能分析
图7(a)描绘了3个方案的文件加密时间消耗.可以很明显看出,本文的方案在加密过程中所需要的时间损耗远小于文献[29,36]所述方案,而且随着访问策略复杂度的增长,本文中方案所需的加密时间增长较为缓慢.图7(b)展示了3个方案中文件解密时间随着密文个数的变化情况.在同样的访问策略设置下对同样个数的密文进行解密的时间长度,本文中的方案所需要的时间消耗要远低于另外2个文献[29,36]方案.图7(c)显示了3个方案的密钥生成时间.可以看出,在同样的时间元素个数条件下,密钥生成时间也在随着用户属性集合大小缓慢增大.而文献[29,36]方案的密钥生成时间远高于本文方法中的时耗.
图7(d)描绘了系统公共参数的大小随系统属性集合的变化情况.很明显,3个方案中,系统公共参数的大小均不受系统属性全集大小的变化,也就是说,这3个方案均事实上支持大规模属性集合.在本文方案中,由于要支持时间有效性而引入了时间相关的公共参数,因此,会增大公共参数的存储开销.图7(e)显示了用户私钥大小在3个方案中随着用户属性集合大小的变化情况.本文方案的用户私钥大小会随着时间元素个数的增加而缓慢增长.而在同样的时间元素个数设置下,本文方案和文献[29,36]方案中的用户私钥大小都随着用户属性集合大小的增大而增长,可以很明显看到,本文方案的变化较为缓慢,同时,在同样的用户属性集合大小情况下,文献[29,36]方案中的用户私钥存储占用要远高于本文方案.图7(f)展示了密文大小在3个方案中的变化情况.如图7所示,3个方案中的密文大小均受访问策略的复杂度影响.而且,随着访问策略的复杂度的增大,密文大小也在增加,所占用的存储空间也会加大.然而,由于未采用双系统方案,本文方案的密文占用存储开销远低于文献[29,36]方案.因此,本文的密文所需要的存储空间更小.
本文方案由于在系统公共参数中,引入时间相关的一些固定参数,因此在公共参数的存储开销中有所增加.然而,在方案的计算性能和其他存储空间开销方面,本文方法都远超文献[29,36]方案.因此,本文方法更具有实用性和可操作性.
6 总 结
本文介绍了一种具有隐私保护的基于图卷积神经网络的攻击溯源方法.本文方法将收集的多种日志解析为计算机可以操作的格式化条目,通过权重优化解决了多日志关系连接导致的状态爆炸,并且通过对Louvain算法的调整,很好地优化了社区检测过程,最后基于GCN对多重APT攻击进行精确分类.相较于现有的单日志分析方法,本文方法可以更加完整地提取攻击社区.同时,本文方法结合属性基加密实现了日志数据的隐私保护.实验通过在不同操作系统上复现的多种APT攻击,显示了我们重构后的攻击社区信息更加完整且有效.实验同时表明:优化后的社区检测很好地提升了算法的检测速度和社区划分的准确度.而且,所提出的隐私保护方法在实验中也表现出了高效性和可用性.
猜你喜欢
机械工业标准化与质量(2022年6期)2022-08-12 02:07:42
好日子(2022年3期)2022-06-01 06:22:30
华人时刊(2021年13期)2021-11-27 09:19:02
国际眼科杂志(2021年9期)2021-09-15 03:24:42
装备制造技术(2020年2期)2020-12-14 03:09:16
心声歌刊(2020年4期)2020-09-07 06:37:14
陕西画报(2018年6期)2018-02-25 01:37:20
小学生(看图说画)(2017年6期)2017-11-06 06:48:08
中国卫生(2015年12期)2015-11-10 05:13:34
电子设计工程(2014年19期)2014-02-27 12:00:42
