
基于YOLOv3的电力杆塔检测算法研究
2021-06-03 02:45潘俊杰
浙江电力 2021年5期
应 斌,唐 斌,潘俊杰,郭 震
(1.国网浙江省电力有限公司台州供电公司,浙江 台州 318000;2.台州宏达电力建设有限公司,浙江 台州 317000)
0 引言
电力杆塔作为支撑输电线的塔架结构,是输电线路中必不可少的关键设备,同时也是输电线路巡检的重要监测对象。电力设备长期暴露在野外,容易出现各种安全隐患,定期巡检输电线路是确保电力安全的重要保障。其中,杆塔检测是输电线路巡检的重要环节。目前无人机技术的高速发展为输电线路巡检带来了新的前景。相比较人工巡检,使用无人机进行巡检具有很多优势。无人机体积小,成本低,操控方便,可以在人工徒步到达不了的艰苦恶劣环境下飞行,适用于在不同位置和不同角度拍摄图像和视频,具有优良的机动性和灵活性。在出现自然灾难时,无人机仍然可以工作,受环境和天气限制少,其飞行速度较快,具有较高的输电线路巡检效率[1]。
近年来,随着深度学习在计算机视觉方面的迅速发展,使得无人机航拍巡检输电线路的杆塔成为现实[2-4]。卷积神经网络在计算机视觉领域上表现得尤为出众,已经广泛应用于计算机视觉的各个领域,包括图像分类、目标检测和语义分割等[5-8]。卷积神经网络利用组合低层特征得到更加抽象的高层特征或属性,具有优良的检测精度和速度[9]。特别是YOLO 算法凭借优良的识别效果和检测速度,在端到端的目标检测领域取得了重要的成果[10]。
电力杆塔由宽度、长度、方向各异的金属钢条构成,每个金属钢条相互交错,交叉点多,形成网状结构。可以采用计算机视觉的方法来提取电力杆塔的有效特征信息,实现对电力杆塔的检测。文献[11]采用基于Faster R-CNN 目标检测模型构建特征融合算法处理特征信息,对杆塔关键位置进行检测,该算法检测精度较高,但是检测的速度较慢,不利于对杆塔的实时监测。文献[12]分析了电力杆塔的特征后,对杆塔提取的线段进行膨胀处理,寻找线与线之间的交叉点并统计其角度,角度值个数超过阈值的区域可判断为电力杆塔,但该方法不适用于很多复杂背景下的检测,精确度不高。文献[13]采用LSD 算法直线段检测和Harris 角点检测,实现杆塔的初定位,最后通过HOG(方向梯度直方图)特征进行SVM(支持向量机)分类器的训练,用训练好的分类器去除伪目标,实现电力杆塔的最终定位,具有较好的识别效果。
本文针对电力杆塔实时检测的现状,提出了一种基于YOLOv3 检测模型的电力杆塔检测算法。该算法可以实现无人机在航拍巡检数据中实时检测出电力杆塔,检测速度快、精度高,对无人机输电线路巡检具有重要意义。
1 YOLOv3 目标检测模型
YOLO 是一种单阶段检测器,直接给出最终的检测结果,没有显示生成候选区域的步骤,检测速度较快,检测精度高,在检测过程中使用整个图像的特征,减少了因为背景产生的错误。
YOLOv3 在结构上,采用了特征提取网络Darknet-53,Darknet-53主要由53个卷积层组成,使用了大量的3×3 和1×1 卷积核[14]。它主要借鉴残差网络的设计思想,在层与层之间加入了一种快捷链路,加强了对小目标的检测能力。Darknet-53 中的残差卷积就是进行一次3×3、步长为2 的卷积,然后保存该卷积layer,再进行一次1×1 的卷积和一次3×3 的卷积,并把这个结果加上layer 作为最后的结果。残差网络的特点是容易优化,并且能够通过增加相当的深度来提高准确率,其内部的残差块使用了跳跃连接,缓解了在深度神经网络中增加深度带来的梯度消失问题。Darknet-53 的每一个卷积部分使用了特有的DarknetConv2D 结构,每一次卷积的时候进行L2正则化,完成卷积后进行BatchNormalization 标准化与Leaky Relu。BN 标准化就是通过将该层特征值分布重新拉回标准正态分布,特征值将落在激活函数对于输入较为敏感的区间,输入的小变化可导致损失函数较大的变化,使得梯度变大,避免梯度消失,同时也可加快收敛。普通的Relu 是将所有的负值都设为零,当Relu 的输入值为负的时候,输出始终为0,其一阶导数也始终为0,这样会导致神经元不能更新参数,从而不再学习。Leaky Relu 则是给所有负值赋予一个非零斜率,输出对负值输入有很小的坡度,解决了Relu函数进入负区间后,导致神经元不学习的问题,以数学的方式可以表示为:

式中:ai是1 至正无穷区间内的固定参数。
YOLOv3 采用3 个不同尺度进行目标检测,其基础尺度特征图大小为输入分辨率的1/32,另外2 个尺度为1/16 和1/8。例如,输入图像像素为416×416,其基础尺度特征图大小为13×13,它在输入图像中的感受野较大,因此适合检测图像中尺寸较大的目标。通过上采样并与前面卷积层输出的特征图融合,再经过多个卷积后得到了第2 个尺度的特征图26×26。在第2 个尺度特征图的基础上,采用同样的方法得到第3 个尺度的特征图52×52,它的感受野较小,因此适合检测图像中尺寸较小的目标。随着输出特征图尺度和数量的变化,YOLOv3 中锚框也需要进行相应的调整。YOLOv3 为每个尺度输出特征图设定了3种锚框,一共包括9 种不同尺寸。在感受野比较大的特征图13×13 上,采用较大的锚框(116×90)(156×198)(373×326),适合检测大型目标;在感受野中等的特征图26×26 上,采用中等的锚框(30×61)(62×45)(59×119),适合检测中型目标;在感受野比较小的特征图52×52 上,采用较小的锚框(10×13)(16×30)(33×23)来检测小型目标,YOLOv3 结构如图1 所示。
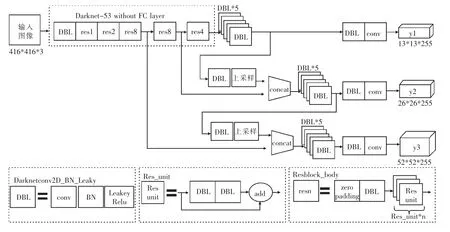
图1 YOLOv3 网络结构
2 杆塔数据集的搭建
2.1 数据集收集和标注
通过无人机拍摄和互联网收集整理,收集了1 200 张电力杆塔数据样本,采用如图2 所示的labelImg 工具对数据样本进行标注。在图中用矩形框框出电力杆塔,并标记对应的类别标签,本文将电力塔杆件从各图片中找出来,标记为tower(杆塔),软件自动保存标记数据(矩形框的坐标位置和对应的类别),保存的数据选择不同的存储格式,可以保存成标准VOC 数据集格式的xml文件和YOLO 模型的指定格式txt 文件。

图2 数据集标注
2.2 数据扩增
数据集的大小影响着深度学习目标检测的效果,由于收集整理得到的样本有限,为了提高模型的鲁棒性,增强泛化能力,本文采用水平镜像、旋转变换、颜色变换和图像错切等方法完成数据集扩增,如图3 所示。最终搭建的杆塔数据库训练集共有6 000 张图像样本,另外拍摄整理了600 张不同于训练集的杆塔图像作为测试集。

图3 数据扩增
3 YOLOv3 模型改进
3.1 杆塔先验锚框的选择
在Faster R-CNN 算法中的先验锚框机制启发下,YOLOv3 算法引入同样的机制。早期的先验锚框大小是在经验的影响下确定的,而在YOLO系列算法中使用了K-means 聚类算法获取先验锚框。在目标检测中,先验锚框取值是否合适关系着检测精度与速度。YOLOv3 使用的先验锚框是根据VOC 数据集[15]和COCO 数据集聚类所得[16],如表1 所示。

表1 原始先验锚框
电力杆塔形状特征大多比较细长,不适合用YOLOv3 的原始先验锚框尺寸进行检测,因此针对电力杆塔的检测需要重新进行维度聚类,选取合适的先验锚框参数,进而得到更好的检测精度和速度[17]。针对本文搭建的杆塔数据集,采用Kmeans 重新聚类数据集的真实标注框,最终得到适合电力杆塔的先验锚框,如表2 所示。

表2 改进后的杆塔先验锚框尺寸
将这些改进后的先验锚框均分到不同尺度的特征金字塔上。小尺寸的先验锚框针对高分辨率特征图,用于检测小目标;大尺寸的先验锚框针对低分辨率特征图,用于检测大目标。将原始先验锚框尺寸和改进后的先验锚框尺寸进行归一化,如图4 所示,可以看出改进后的先验锚框尺寸更符合电力杆塔的形状和比例。

图4 不同锚框尺寸比较
3.2 Loss 函数改进
YOLOv3 中的损失函数由三部分组成,包括边界框回归损失、置信度损失和类别的分类损失[18]。其中,边界框回归损失函数采用的是均方误差损失函数,而评估性能采用的是IoU(交并比)。
如图5 所示,细线框表示预测框,右上角处于圆心的粗线框表示真实框,从图中可知,损失相同的时候,可能会发生IoU 值相差较大的情况。所以采用均方误差计算损失函数还存在一定的缺陷,而IoU 更能体现预测框回归的质量,且具有尺度不变性。但是如果直接采用IoU 作为损失函数,当预测框和真实框没有交集时,不管两者之间的距离有多远,对应的IoU 都为零,这就导致了模型无法度量这种情况下的预测框和真实框的距离,并且损失函数此时不存在梯度,无法通过梯度下降进行训练。因此,本文采用一种新的度量预测框和真实框拟合程度的方法,即GIoU。
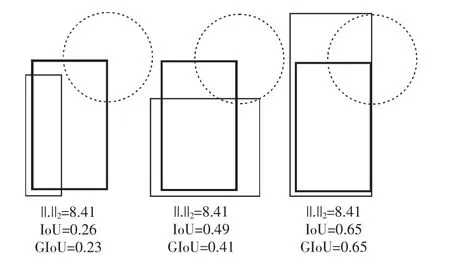
图5 损失相同时比较
如图6 所示,通过预测框A 和真实框B,可以算出两者的最小包围框C。最小包围框C 包括预测框和真实框的并集和d1,d2 区域[19]。通过最小包围框C,可以计算GIoU。IoU 和GIoU 的计算公式如下:


图6 预测框A 和真实框B 的最小包围框

式中:减数部分分子为最小包围框C 中不包含A或者B 的部分。
GIoU 是IoU 的下界,小于等于IoU,IoU 的取值范围是[0,1],GIoU 的取值范围是(-1,1]。当2个边界框不重合时,IoU 始终为0,而对GIoU 来说,A 和B 的距离越远,GIoU 越趋近于-1。IoU关注了A 和B 及其交集区域,而GIoU 在此基础上还关注了d1 和d2 区域,更好地反映出了预测框和真实框关系[20]。因此,可以使用GIoU 计算边界框回归损失,公式如下:
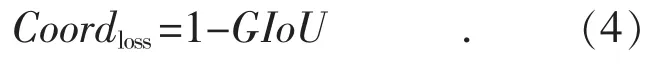
预测框和真实框的重合度越大,损失值越小,GIoU 的取值范围是(-1,1],所以Coordloss的取值范围为[0,2)。相较于采用均方误差作为边界框回归的损失函数,基于GIoU 的边界框回归损失具有尺度不变性,更能反映出预测框和真实框的距离,提升目标定位的准确性。
置信度损失和类别的分类损失如下所示:
最后总体的损失函数Loss 值如下所示:
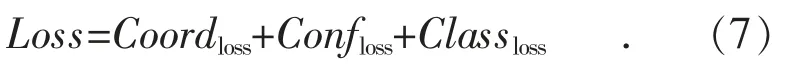
4 实验结果与分析
4.1 实验环境与参数
本文实验的环境为Intel Pentium G4560 的处理器,内存为16GB,GPU 为NVIDIA GeForce GTX 1050Ti,内存为4GB,cuda9.0,cuDNN7.0,OpenCV3.1.0。训练数据集为自行搭建的杆塔数据集,包括6 000 张图片。测试数据集为另外整理的600 张杆塔图片,都不存在于训练集中。
在YOLOv3 提供的Darknet53.conv.74 权重的基础上进行实验,采用GPU 训练模型,使用CUDA 和cuDNN 对训练过程进行加速[21]。训练采取mini-batch SGD(小批量随机梯度下降法)将网络的权重不断优化,表3 给出了实验过程中训练所使用的参数,迭代训练每个batch 样本更新一次参数,到达max_batches 后停止学习,初始的学习率设置为0.001,学习率调整策略选择“step”,将“stepsize”设置为1 500,即迭代次数达到1 500时,学习率调整为之前的0.1 倍。

表3 训练参数设置
4.2 实验评估指标
为了客观评估本文提出的杆塔检测算法的性能,采用以下参数作为相关评估指标[22]:
(1)True Positive(TP)表示实际为电力杆塔的区域被判断为电力杆塔区域的预测边界框个数。
(2)True Negative(TN)表示实际为背景的区域被判断为背景区域的预测边界框个数。
(3)False Positive(FP)表示实际为背景的区域被判断为电力杆塔区域的预测边界框个数。
(4)False Negative(FN)表示实际为电力杆塔的区域被判断为背景区域的预测边界框个数。
(5)Precision 为精确率,又称为查准率,其计算公式为:

(6)Recall 为召回率,又称为查全率,其计算公式为:
通过Precision 和Recall 可以计算平均精度AP[23]。每个类别的目标都有一个对应的AP,AP越高,目标检测算法效果越好。AP 表示以Recall为横轴、以Precision 为纵轴的P-R 曲线所围成的区域面积:

式中:p 表示Precision;r 表示Recall。
mAP 表示的是多类别平均精度[24],用来衡量杆塔检测模型性能:

4.3 模型对比分析
将训练后的模型在杆塔测试数据集上进行测试,mAP 达到了90.8%,模型测试的P-R 曲线如图7 所示,本改进YOLOv3 模型具有较好的杆塔检测效果。
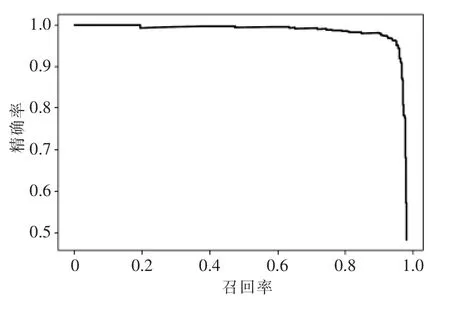
图7 P-R 曲线
将Faster R-CNN[25]、传统的YOLOv3、采用IoU 损失函数+改进的先验锚框组合的YOLOv3、采用GIoU 损失函数+原始先验锚框组合的YOLOv3 和改进的YOLOv3 模型进行对比实验,每组实验所用的数据集相同。对比不同网络模型检测杆塔的能力,验证改进YOLOv3 的优越性。其中Faster R-CNN 采用的特征提取网络为VGG16,实验结果均是在网络参数最优状态得到的,表4所示为实验结果。
从表4 可看出,two-stage 的Faster R-CNN由于其检测过程复杂,检测花费时间比one-stage的YOLOv3 系列算法要长,无法满足电力杆塔实时检测的要求,而相比传统的YOLOv3 算法、只改进先验锚框的YOLOv3 以及只改进GIOU 损失函数的YOLOv3 算法,改进后的YOLOv3 在相等的检测速度下具有更高的平均准确率,mAP 达到了90.8%。
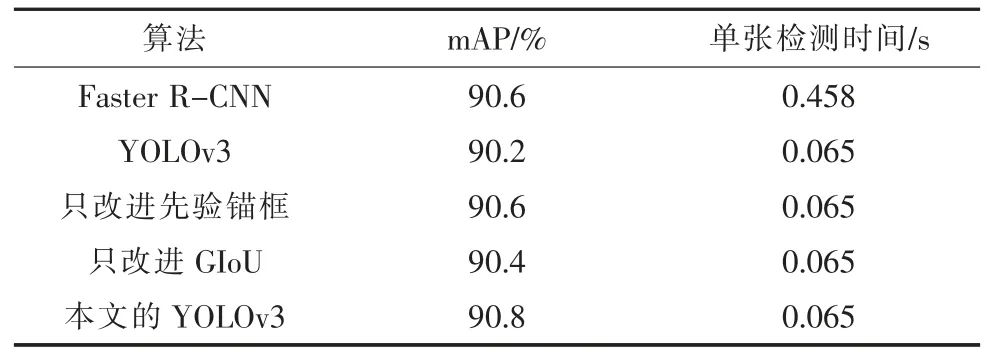
表4 不同模型性能对比
从测试集中抽取了不同样本的电力杆塔检测效果如图8 所示,图8(a)为传统YOLOv3 的检测效果,图8(b)为改进YOLOv3 算法的检测效果。改进YOLOv3 算法针对不同距离、不同背景的杆塔目标具备良好的检测能力,同时具有相对更高的定位精度,对于单张杆塔图片的检测耗时仅65 ms,mAP 达到了90.8%,相比于原算法,mAP 提升了0.6%,从而提高了杆塔检测精度。

图8 不同算法检测效果对比
4 结语
本文提出一种基于YOLOv3 改进的目标检测模型,并将其应用于电力杆塔检测中。首先通过自行拍摄和网络整理收集杆塔的图像样本,再利用水平镜像、旋转变换、颜色变换和图像错切等图像处理方法扩大样本数量,采用labelImg 工具对各图像样本进行标注,完成杆塔数据集的搭建。然后通过K-means 重新聚类计算得到最优的先验锚框,更符合杆塔的形状和比例,针对边界框回归不够准确的问题,采用GIoU 计算边界框回归损失,使边界框的定位更加准确。最后对比分析其他模型,认为改进后的YOLOv3 模型准确率较高,适用于多尺度的杆塔检测,检测速度达到了每帧65 ms,mAP 达到90.8%。
猜你喜欢
信号处理(2022年11期)2022-12-26
计算机与生活(2022年11期)2022-11-15
计算机工程与科学(2022年8期)2022-08-20
中南民族大学学报(自然科学版)(2022年3期)2022-05-08
卫星应用(2022年1期)2022-03-09
电子制作(2019年11期)2019-07-04
自动化学报(2017年5期)2017-05-14
光学精密工程(2016年4期)2016-11-07
电测与仪表(2016年23期)2016-04-12
探测与控制学报(2015年4期)2015-12-15
