
基于深度神经网络的电子商务智能客服系统设计与实现
2021-05-29 15:33张瀚月丁妍张毓冯时
软件工程 2021年5期
张瀚月 丁妍 张毓 冯时

摘 要:近年来,随着自然语言处理技术的飞速发展,传统的客服越来越不能满足当前的业务需求,基于自然语言技术的智能客服系统应运而生并被广泛应用在学习、生活、工作等各个领域中。本系统使用HTML和JavaScript进行前端页面的实现,采用Django进行后端的搭建,并使用MySQL进行数据的管理;使用ESIM模型进行语义匹配,该模型综合应用了BiLSTM和注意力机制,将不同句子的各单词特征相关性进行表示,再进行差积分析,凸显了局部推理信息,最终实现了具有回答用户问题、天气查询、推荐商品等功能的智能客服系统。
关键词:智能客服;电子商务;搜索引擎
中图分类号:TP311.1 文献标识码:A
Design and Implementation of E-commerce Intelligent Customer
Service System based on Deep Neural Network
ZHANG Hanyue, DING Yan, ZHANG Yu, FENG Shi
(School of Computer Science and Engineering, Northeastern University, Shenyang 110819, China)
zhanghanyuehyz@163.com; 20174530@stu.neu.edu.cn;
zhangyvneu@163.com; fengshi@cse.neu.edu.cn
Abstract: In recent years, with rapid development of natural language processing technology, traditional customer service is increasingly unable to meet current business needs. Intelligent customer service system based on natural language technology has emerged and is widely used in various fields, such as study, life, and work. This paper proposes to design an E-commerce intelligent customer service system using HTML (HyperText Markup Language) and JavaScript to implement the front-end page, Django to build the back-end, MySQL (Structured Query Language) to manage data, and the ESIM (Enhanced Sequential Inference Model) to perform semantic matching. This model uses BiLSTM (Bidirectional Long Short-term Memory) and attention mechanism to combine different sentences. Feature relevance of each word is expressed, and then difference product analysis is performed, which highlights the local reasoning information. Finally, the intelligent customer service system with functions such as answering user questions, weather inquiries, and recommending products is realized.
Keywords: intelligent customer service; e-commerce; search engine
1 引言(Introduction)
隨着人工智能的发展,聊天机器人逐渐走入人们的视野,它第一次出现在英国知名数学家图灵在Mind上发表的经典论文——《计算机器与智能》[1-2]中。聊天机器人在应用场景上主要可以划分为娱乐、在线客服、教育、个人助理和智能问答[3]。近几年来,信息的爆发式增长使得人们需要更快速、准确地在网络中获取自己需要的信息[4]。因此,智能客服机器人的需求日益增加,其发展趋势非常迅猛,它被广泛运用在电商平台的导购服务、公共平台的智能指导服务等方面。相对于人工客服,它有着巨大的优势:响应快速、全天候在线、成本低。顾客可以在任意时间咨询电子客服,并且得到迅速响应,这是人工客服无法做到的[5]。当一个企业的客户规模很大时,对客服的需求量也是不断增加的,这会给企业带来巨大的人力资源压力、服务成本压力、监管压力。而使用智能服务机器人只需对其进行开发、运营、维护,其成本要比人工客服小得多。因此,使用智能客服机器人代替人工客服是一种必然的趋势[6]。
本文实现了基于深度神经网络的电子商务智能客服系统,具有回答用户问题、查询天气、推荐商品等基本服务。用户可以询问与商品有关的信息并得到回答,同时该系统也会在页面上显示推荐用户购买的相关产品信息。
2 需求分析(Requirements analysis)
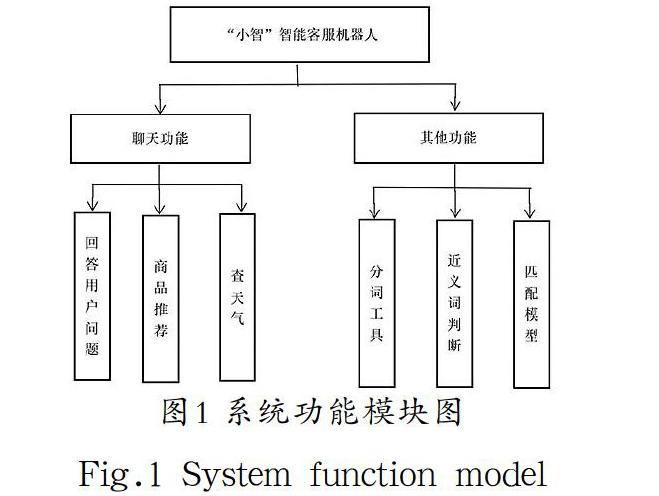
本系统所要实现的目标为一个多功能智能客服对话系统,拥有回答用户有关商品问题、进行商品推荐、查天气这三项基本功能。在用户与本系统交互时,系统会根据用户提出的问题进行关键词抽取,并在数据库中找到最为匹配的回答传送到前端并显示在界面上。同时它也具有商品推荐和天气预报的功能,用户可直接在聊天页面跳转到华为商城进行商品选择,也可查询所在地的天气情况,如图1所示。
3 实现技术(Implementation technology)
3.1 智能客服机器人简介
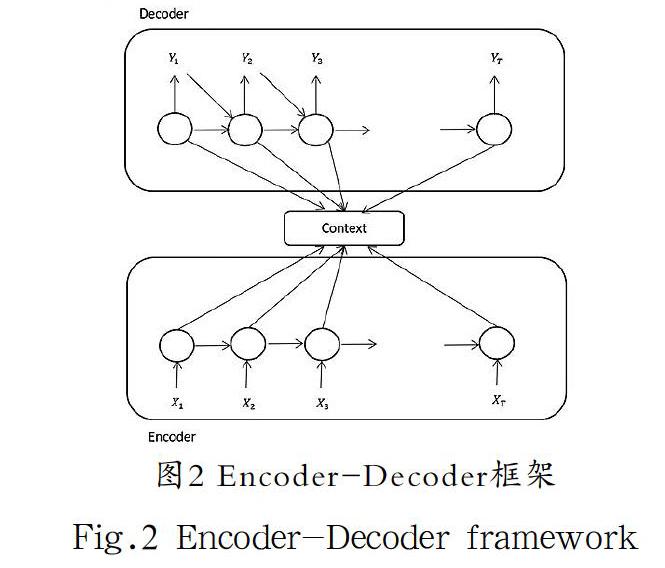
本智能客服对话系统采用了深度学习的框架,根据用户输入的句子,利用模型逐词或逐句生成答案,然后将答案回复给用户;采用了Encoder-Decoder模型,即编码—解码模型[7],其框架技术如图2所示。Encoder就是对输入序列进行编码,通过一系列非线性变换转化成一个带有语义固定长度的向量;Decoder就是根据之前生成的固定向量再转化成输出序列。本系统选择的模型是ESIM模型。
3.2 ESIM 模型算法流程
为了理解ESIM网络模型的工作原理,这里通过一系列算法方程进行说明。
进一步假设如下:给定两个句子和。其中a是前提(premise),b是假設(hypothesis)。ai和bj属于l维的词向量,可以由一些预训练的词向量和语义树组织来初始化,目标是要预测表示a和b之间的逻辑关系标签y[8]。
具体算法流程如下:
第一步(输入编码):BiLSTM作为推理模型的一个基础模块,用表示输入句子a在BiLSTM网络的时刻i的隐藏层输出(单词ai的隐状态)。同理,公式如下:
(1)
(2)
第二步(局部推理):采用注意力机制,注意力层通过计算隐状态对的注意力权重来作为前提和假设的相似度。具体计算公式为:
(3)
第三步:对于前提中一个单词的隐状态,由第二步得到的eij计算它与假设中的各单词的语义相似程度,公式如下。其中是对单词序列的加权求和。
(4)
(5)
第四步:计算了对的差异和点积锐化元组中元素之间的局部推理信息,将计算得到的差异和点积向量拼接在原始向量、之后。
(6)
(7)
第五步:计算了一个整合层来组合增强的局部推理信息。在树组合中,更新树节点以组合局部推理的总体公式如下:
(8)
(9)
第六步:计算平均池化和最大池化,并将这些向量进行拼接,形成最终的固定长度向量v。
(10)
(11)
(12)
4 系统设计和实现(System design and implementation)
4.1 总体设计
本系统以TensorFlow为开发平台,采用深度学习的框架构建了一个智能客服对话系统。前端采用了HMTL和JavaScript语言进行编写,并结合了CSS和jQuery;后端采用了Django的Web应用框架,以MTV模型为基础进行前后端的交互。前后端之间通过AJAX技术异步通信,是一种在无须重新加载整个页面的情况下,能够部分更新网页的技术,以创建快速动态网页[9]。传输的数据全部以JSON格式包装。用户在网页上产生请求后,后端通过协议将请求内容转发到相应的功能模块服务器上并返回响应,前端收到响应后通过JS对页面上显示的内容进行修改,并显示在界面上,如图3所示。
4.2 数据库设计
由于数据量较大并且要和Django相结合,因此使用MySQL数据库存储数据,使用继承Django的Models类的方式实现一个数据库模型类。类中共有四个数据成员,分别是int类型的id、varchar类型的name、varchar类型的question和varchar类型的answer。其中,id是表的主键,name用于记录商品名,question用于记录关于该商品的问题,answer记录对于问题的回答,如表1所示。
使用python manage.py makemigrations命令将数据模型生成迁移脚本文件,再使用python manage.py migrate命令将生成的迁移脚本文件映射到数据库中,生成数据表。其中数据库中的部分数据展示,如图4所示。
图4 数据库部分数据展示
Fig.4 Part of the database data display
4.3 搜索引擎
为了得到用户所提问题的候选答案,同时也为了保证运行时间,本文实现了一个轻量级的搜索引擎。首先使用搜索引擎来得到一些候选回答,然后再使用神经网络匹配模型筛选出更加精确的回答。本文使用了Python的第三方库Whoosh来制作搜索引擎。在使用搜索引擎之前,先要创建一个索引,而在创建索引之前,要先创建一个模式(Schema)。
算法1:创建索引。
if index文件夹存在:
打开索引
else:
os.mkdir("index") // 创建index文件夹
my_index = create_in("index", schema) // 创建索引
将数据库中的数据写入索引
创建索引结束
我们使用如上代码创建了一个模式,使用了jieba库中的ChineseAnalyzer作为语言分析器。在创建好模式之后,就可以创建索引了。首先,创建一个名为index的文件夹;然后,使用之前创建好的模式创建一个索引;最后,把数据库中的数据对应于模式中的各个字段保存到索引中。索引创建完成之后,就可以实现答案的搜索了。具体搜索流程如图5所示。
算法2:对问题进行搜索。
输入:用户询问的问题
question = request.POST.get('question_box') // 获得问题
parser=MultifieldParser(["name","question"],my_index.schema, group=qparser.OrGroup) //使用创建whoosh.query.Query对象
myquery = parser.parse(question) //对问题进行处理,生成query对象
with my_index.searcher() as searcher:
result = searcher.search(myquery) //对问题进行搜索
4.4 后端设计
(1)问答功能
本功能主要是对用户关于商品信息的提问进行回答。首先我们爬取了京东、淘宝上关于华为手机的问答对,构建了一个大型语料库。当用户输入问题后,使用搜索引擎搜索出最匹配的十个问题,然后使用语义匹配模型进行匹配,将得分最高的答案返回给用户,如图6所示。
(2)语义匹配模型
语义匹配模型主要分为数据预处理和匹配打分这两个部分,下面分别对其进行介绍。
首先是数据预处理。我们对用户输入的问题进行繁体转简体、使用jieba进行分词、去除停用词的操作,将句子转换为一个由词语组成的列表。
其次是匹配打分的过程。我们主要使用Keras搭建ESIM(Enhanced Sequential Inference Model)模型,该模型主要分為三个部分:输入编码、局部推理和推理合成[10]。
输入编码是使用BiLSTM模型表征输入句子中每一个单词和它的上下文信息。它能够很好地表征局部推理信息和它在上下文中的影响,其中我们假设句子的最大长度为20。
局部推理是采用注意力机制,通过计算状态对的注意力权重来作为前提和假设的相似度。最后利用点积等操作锐化局部推理信息,并将其拼接在一起。
推理合成部分依旧使用BiLSTM模型来整合局部推断信息。
最后将输出结果进行平均值池化和最大值池化,送入多层感知器(MLP)中,激活函数采用tanh函数,输出层采用softmax函数,得到前提和假设的匹配度。
该模型的输入为两个经过预处理后的单词列表,输出结果为这两个列表原本语句的匹配程度。我们采用了在京东上爬取的关于华为手机的问答对共十万条进行训练和测试,在测试集上的准确率达到88.5%,召回率达到88.8%。语义匹配流程图如图7所示。
(3)天气预报功能
在问答界面中,也提供了天气预报的功能,用户可以查看自己当前所在城市的天气情况。在HTML代码中,使用一个iframe标签,将该iframe标签的src属性设置为天气网站的链接,这样就将用户所在城市的天气信息返回到了前端。用户也可以通过点击天气信息的图形来了解关于天气更多的细节。
(4)商品推荐功能
问答机器人在顶部提供了通往华为商城的链接,用户点击后可以通往华为商城。
4.5 前端设计
我们采用HTML和JavaScript进行编写,设计了一个如图5所示的聊天界面。用户在聊天界面输入自己的问题并提交,使用post方法进行数据的传输,为了使得Django能够正确地找到HTML文件,需要在settings.py和views.py中指定文件的位置,因此进行了相应设置。
当对话数量较多时,聊天对话框被拉长,影响使用体验,因此为聊天对话框设置最大高度后添加overflow-y: scroll;样式,可在内容超出最大高度后自动显示滚动条。在用户输入内容或系统对用户进行回复后,通过对聊天框的scrollTop参数进行设置实现滚动条自动滚动显示最新内容。聊天对话框主体下方为输入框和发送按钮,当页面加载完成时,为发送按钮设置键盘监听事件,以实现按回车键直接发送消息。
4.6 数据集
本系统采用的数据集为京东商场有关华为手机的40 万条问题与回答数据,其中238,014 条用于训练,158,677 条用于测试。数据爬取的目标是京东上用户提出的问题和回答。由于京东上一部分的商品是动态加载的,因此采用selenium的方法进行数据爬取,为了使一个页面中的所有商品都可以加载出来,在爬取数据时,先让浏览器执行一段JS代码,将浏览器的滚动条拖到最下面,以完成一个页面中所有商品的加载。为了提高爬取的效率,将京东上一个页面的60 个商品分成12 组,采用多线程的方式分别对每一组进行数据的爬取。通过继承threading中的Thread类,实现一个Crawl类,通过构造函数,使类的实例具有商品编号和商品名称信息。定义Crawl类的run方法,在run方法中加入获取数据的函数,在线程启动时即开始爬取数据,使用PyQuery库的find方法结合CSS选择器找到想要的数据。在得到的数据中发现有很多回答会有“您好”或者“感谢您对京东的支持!祝您购物愉快”这样对我们的系统无用的语句,所以使用正则表达式对爬取到的答案进行清洗,将清洗的数据存入数据库中。
5 系统展示(System display)
系统运行结果如图8所示。
6 结论(Conclusion)
本文主要介绍了基于深度神经网络的电子商务智能客服系统的设计与实现过程。首先该系统构建了一个大型语料库,包含从京东等电商平台爬取的数万条问答对,作为模型训练和评估的数据。其次,该系统使用Django进行后端搭建,使用HTML和JavaScript进行前端实现,使用Keras进行模型的搭建和训练,代码简洁清晰。我们将各个功能进行封装,使其便于复用,降低了各模块之间的耦合度,使其易于扩展。同时该系统设置有问答功能、天气查询功能、商品推荐功能,能够在用户有需要的时候随时提供服务,降低了人工成本,提高了服务效率,商品推荐功能也会给用户提供更多购买选择,是一个极具实用性的系统。
参考文献(References)
[1] TURING A M. Parsing the Turing Test[M]. Dordercht: Springer, 2009:23-65.
[2] 冯晓波.中文问答系统中问题分类和关键词扩展的研究[D].北京:北京邮电大学,2011.
[3] 王浩畅,李斌.聊天机器人系统研究进展[J].计算机应用与软件,2018,35(12):1-6,89.
[4] LOW D B W. An improved immune genetic algorithm for the optimization of enterprise information system based on time property[J]. Journal of Software, 2011, 6(3):436-443.
[5] 王乾銘,李吟.基于深度学习的个性化聊天机器人研究[J].计算机技术与发展,2020,30(4):79-84.
[6] 张素荣.智能客服问答系统关键算法研究及应用[D].江苏:南京邮电大学,2018.
[7] LE Q, MIKOLOV T. Distributed representations of sentences and documents[C]//ROGOZHNIKOV A. International Conference on Machine Learning. Proceedings of the 31 st International Conference on Machine Learning. New York: JMLR, 2014: 1188-1196.
[8] ZHANG L, CHEN C. Sentiment classification with convolutional neural networks: An experimental study on a large-scale Chinese conversation corpus[C]// International Conference on Computational Intelligence and Security. 2016 12th International Conference on Computational Intelligence and Security. New York City: IEEE, 2016:165-169.
[9] 韩可彧.基于Django的XSS和CSRF防御系统的研究与实现[D].武汉:武汉邮电科学研究院,2018.
[10] 伍行素,陈锦回.基于LSTM深度神经网络的情感分析方法[J].上饶师范学院学报,2018,38(06):10-14.
作者简介:
张瀚月(1999-),女,本科生.研究领域:软件工程,机器学习.
丁 妍(1999-),女,本科生.研究领域:自然语言处理.
张 毓(1999-),男,本科生.研究领域:深度学习,软件工程.
冯 时(1981-),男,博士,副教授.研究领域:数据挖掘,自然语言处理.
猜你喜欢
今日农业(2021年21期)2022-01-12
知识经济·中国直销(2018年10期)2018-11-06
池州学院学报(2017年5期)2018-01-23
公民与法治(2016年12期)2016-05-17
中国卫生(2015年12期)2015-11-10
中国科技信息(2015年17期)2015-11-02
警察技术(2015年3期)2015-02-27
中国期刊年鉴(2015年0期)2015-01-19
新疆大学学报(自然科学版)(中英文)(2014年2期)2014-11-06
技术经济与管理研究(2014年11期)2014-03-11
