
基于深度学习的超声白内障检测算法
2021-05-28 06:03:54王勇
现代计算机 2021年11期
王勇
(四川大学计算机学院,成都610065)
0 引言
白内障是因为眼睛水晶体混浊而造成视力缺损的疾病,可能进犯单眼或双眼。症状包含彩度降低、视线模糊、光源产生光晕、无法适应亮光,以及黑暗环境下视觉障碍。该病为全球半数眼盲及33%视力受损病例的原因[1],及早发现和治疗可减少白内障患者的痛苦并防止视力障碍到眼盲的转变。然而,受过训练的眼科医生的专业知识对于白内障临床检查至关重要,由于潜在的成本问题,这可能会使大多数人都难以得到早期干预导致眼疾加重。在基层和偏远山区的医疗机构中,传统的超声诊断往往具有设备但没有人才的困境。由于超声诊断结果的主观性强,可重复性差,不同机构,不同人员的评价结果具有很大的同质性和客观性偏差,所以需要有经验且专业的超声专家提供诊断。但是,专家受时间和地域因素的影响,只能为极其有限的少数病患群体提供超声诊断服务。因此,计算机辅助诊断避免了许多此类问题,并且正在作为常规阅读的替代和补充方法而受到越来越多的研究者的重视[2]。因此本文着手于超声图像,利用深度神经网络对图像或图像中病变进行分类。
1 相关工作
现有的大量白内障检测系统所使用的特征提取与疾病检测算法,采用的分类方法都是基于传统的机器学习的方法。主要是采用支持向量机,使用支持向量机分类,适用于样本量少的训练[3]。因此适用于样本量小的医学图像范畴,但需要人工手动提取相关特征。
目前也有部分是只基于深度学习的方法,使用裂隙灯图像和视网膜图像等高质量图像进行分类。然而拍摄裂隙灯图像[4]和视网膜图像[5]等高质量图像的仪器造价高昂,通常偏远地区和基层医院没有此类装备。相较于裂隙灯图像和视网膜图像等高质量图像,超声向一定方向传播,而且可以穿透物体,如果碰到障碍,就会产生回声,不相同的障碍物就会产生不相同的回声,人们通过仪器将这种回声收集并显示在屏幕上,可以用来了解物体的内部结构。并且B 超检查的价格也比较便宜,又无不良反应,可反复检查,可以获得比较清晰的眼球不同方向的断面像,足以用来判别白内障的病状。采用的神经网络的分类的方法,不需要人工手动提取特征,只需要将大量的样本送进神经网络中,让神经网络自己学习,自动地提取特征,来进行分类,分类效果更加准确。
2 数据采集
我们建立一个交互式的共享白内障超声数据库。该数据库包含正常人,白内障和各种眼疾患者的高质量B 型超声图,并在专家的指导下建立多维细粒度的患者分析数据。我们在采集阶段通过医院采集了“0-7”类8 种眼病的图片,考虑到收集的数据集中许多眼睛样本都包含多种疾病,因此将收集到的数据集进行排列并将其分为三类。
如图1(a)所示,属于“0”类别(正常眼睛)的图像为1,895 张,属于“1”类别(轻度白内障)的图像为3,615张,属于“2”类别(为白内障)的图像为6,906 张。图1(b)显示了混合疾病类别的分布。“1+3”的值等于134,这意味着有134 例眼睛同时患有1 型白内障和3 型玻璃体混浊。为了平衡样本的正负,我们随机选择了1865 只正常眼,1866 例轻度白内障眼(包括166 种混合疾病)和1864 例严重白内障眼(包括161 种混合疾病)进行训练和测试。
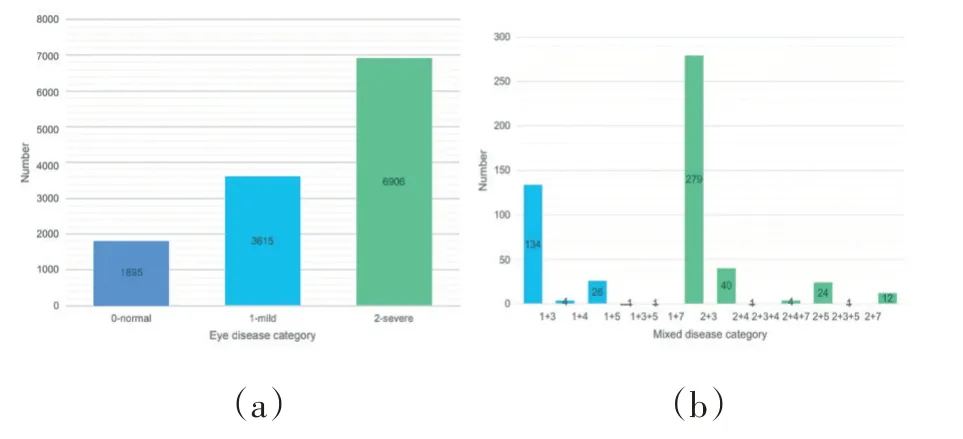
图1 数据集统计
3 白内障检测算法
我们提出了一种深度学习模型,框架概述图说明了我们的流程,其中分为两个模块(1)区域选择模块,使用YOLOv3[6];(2)分类模块包含深层网络DenseNet-161[7]提取的高层特征。我们的模型需要两步完成训练:①我们使用YOLOv3 如图2 所示,检测出B 超图片中我们需要的信息——眼球和晶状体,然后成对将眼球和晶状体图像输入深度学习模型。这样帮助我们同时从成对的白内障分类图片中,学习有判别的表示,其中包含相同类别的相似眼球和晶状体图像,以及不同类别的不相似图像;②我们将成对的晶状体和眼球图片放入分类模块中提取他们的深度特征,并训练成一个分类器。
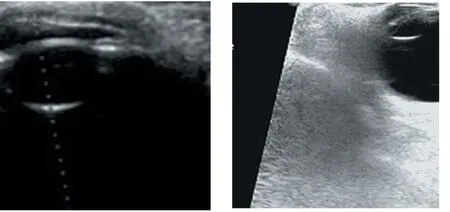
图2 OpenCV裁剪图
3.1 基于目标检测的区域选择模块
原始的超声检查图像包含了整个眼部及眼部周围的数据,眼部周围数据十分复杂,噪声干扰极大,对病状识别的准确率有巨大影响,所以识别系统需先对输入的图像进行眼球目标检测。最开始我们使用OpenCV 将图片转化为灰度图,然后将图像二值化提取轮廓。再通过最小内接矩形裁图,但是效果极差,无法准确框定眼球。后来改用目标检测网络,通过对大量的原始图像进行边框标注的眼球数据来学习位置信息。
我们采用YOLOv3 作为目标检测网络。如图3 所示,YOLOv3 对输入图片进行了粗、中、细网格划分,以便分别实现对大、中和小物体的预测。特征提取采用DarkNet-53[6],即在全卷积的基础上,引入Residual 残差结构[8],在减小深层网络训练难度的同时,明显提升精度。此外,训练前使用K-means 算法[9],对预处理图像进行聚类处理,并且获得较好的先验框。并且引入RCNN 系列[10]的anchor 锚点机制,YOLOv3 的anchor 帮助网格预测方法速度更快且稳定。然后通过NMS[11]处理,框定准确度最高的框。YOLOv3 凭借其出色的稳定性和高效性,可以在极短的时间内快速进行区域定位,并且容易实现轻量化。
最初我们使用原始YOLOv3 直接同时框定眼球和晶状体并且实现分类,但是眼球以及晶状体的框定结果很差,并且完全无法进行正确分类,所以我们对原始的YOLOv3 进行了小小的改动。我们使用了3773 带注释的眼球和晶状体图像作为训练输入,并将所有对象归为一类,分别训练两个YOLOv3。首先使用K-means 提取先验框,然后使用YOLOv3 本身进行学习。为了更好地定位学习框,在计算损失时省略了类损失,因为只有一类。损失函数如下所示:

图3 YOLOv3结构图
3.2 基于DenseNet-161的分类模块
DenseNet-161 借用residual 残差结构,将不同层的网络稠密连接,确保网络中最大的信息流通。DenseNet 这种稠密的连接方式比传统的卷积网络需要更少的参数,并同时改善整个网络的信息流和梯度,每个图层都与损失函数和原始信号连接,使网络更容易训练;此外,DenseNet 密集的连接具有正则化效应,减少小规模数据集的过拟合。向前:每一层都可以看到所有的之前的输入,对于网络已经学习到的“知识”(即已有feature map),以及原始输入,都可以直接连接到,然后再添加自己的“知识”到全局知识库。鼓励了特征的重用,特征重用就可以减少不必要的计算量。另外,多层之间可以很好地进行交互,每一层都接受前面所有层的输出,具有多层特征融合的特性。向后:跳跃结构,可以很近地连接到最后的loss,训练起来很容易,直接接受最终loss 的监督,深层监督,解决梯度消失的问题,并且,能起到正则化的作用缓解过拟合。DenseNet-161 准确度和效率在分类网络中都名列前茅,能够帮助实现高效精准判别。
4 实施细节及实验结果
4.1 实施细节
对YOLOv3 输出带有bbox 的图像进行裁剪,然后对短边进行上下均匀零填充,使图片正方形化。然后将所有图片规范化到128×128 的统一尺度,进行随机水平翻转、随机左右翻转0-10 度、亮度调节、规范化操作。将有限的图片进行10 倍的扩充,同时翻转旋转等操作大大提升了网络的鲁棒性。一组图像集的均值和标准差可以很好地概括这组图像的信息和特征。均值就是一组数据的平均水平,而标准差代表的是数据的离散程度。规范化使神经网络在训练的过程中,梯度对每一张图片的作用都是平均的,也就是不存在比例不匹配的情况,以保证所有的图像分布都相似,也就是在训练的时候更容易收敛。
本实验中使用的数据集包括5,595 张图像。其中5,045 个用于训练,550 个用于测试。为了开发和评估模型,将总共5,045 只B 超检查眼随机分为内部训练集和内部验证集。通过随机提取每个数据库中90%和10%的记录来生成内部训练和验证集。然后,在YOLOv3 之后,我们可以获得5,595 个眼球和5,595 个晶状体图像。
YOLO-v3 配置如下:img-size 416, batch-size 16,iou-thres 0.5, conf-thres 0.001, nms-thres 0.5, class 1,(SGD)lr 0.01,momentum 0.9,weight-decay 0.0005。由于COCO 和ImageNet 数据集类别与此数据集无关,因此我们不采用预训练模型。
来自COCO 和ImageNet 的权重。眼球的YOLO锚点:121,121,149,149,158,158,164,164,169,169,172,172,175,175,181,181,191,191。镜头的YOLO 锚点:47,47,55,75,57,56,65,63,73,70,78,77,83,60,95,65,97,57。
评分标准:FN代表正常眼睛、FM轻度白内障、FS重度白内障、FFinal代表平均准确率,计算过程如下:
4.2 实验结果
最开始我们直接使用原图放入5 层卷积中训练,发现准确率只有56%;后来不断尝试AlexNet[12]/VGG-16[13]/ ResNet-18[8]/ ResNet-152/ DenseNet-121/Dense Net-161/DenseNet-201,发现DenseNet-161 效果最好,准确率高达84%。

表1 不同分类器判别原始图像准确率
然后,我们使用通过YOLOv3 获得的晶状体和眼球图像,再次通过上述网络训练,发现仍是DenseNet-161 效果最好,准确率高达90%。
5 结语
在本文中,我们提出了一种基于B 超图像的白内障检测方法。该方法由区域选择模块,特征提取模块组成。区域选择模块检测B 超图像的眼球和晶状体。为了完全捕获图像特征,使用带有卷积神经网络的特征提取模块获取高级特征。将来,我们将使用更多的特征提取方式,获得更高的准确率。同时实现更多种类的眼部疾病检测,并尝试使用生成对抗网络来扩展我们的辅助训练数据集。
猜你喜欢
发明与创新·小学生(2022年6期)2022-05-22 08:20:02
发明与创新(2022年18期)2022-05-18 14:55:32
中国典型病例大全(2022年7期)2022-04-22 00:50:34
中国实用医药(2021年7期)2021-04-16 11:21:38
童话世界(2019年25期)2019-10-26 02:27:04
中医眼耳鼻喉杂志(2019年2期)2019-04-13 05:23:52
自我保健(2019年1期)2019-01-12 13:26:01
中国继续医学教育(2015年4期)2016-01-07 07:38:01
中外医疗(2015年5期)2015-08-29 01:54:42
人民中国(日文版)(2015年9期)2015-03-20 15:08:12
