
命名实体识别研究综述
2021-05-28 06:03:48袁清波杨帆
现代计算机 2021年11期
袁清波,杨帆
(陆军工程大学指挥控制工程学院,南京210007)
0 引言
随着计算机和网络通信技术的迅猛发展,互联网上数据量呈爆炸性增长。这些数据产生渠道众多,而大部分都是非结构化数据,给人们快速获取有效信息带来了较多困难。如何将这些非结构化数据转换为结构化数据,以进行高效利用,是当前亟需解决的问题,也是信息抽取(Information Extraction,IE)研究的重要内容之一。命名实体识别(Named Entity Recognition,NER)作为知识图谱构建过程中的关键技术,主要完成从非结构化数据中识别出预定义好的语义类型命名实体,目前广泛应用于搜索引擎、智能推荐、机器翻译和问答服务等领域。先前已有部分人员对命名实体识别的方法进行了相关综述[1-2],但到目前为止已有一段时间,本文针对近几年出现一些最新方法进行介绍。
1 产生与发展
近年来,一些重要国际竞赛会议对命名实体识别技术的产生与发展起到了重要推动作用。这些会议主要有消息理解MUC 会议、自动内容抽取ACE 会议、文本分析TAC 会议以及语义评测SemEval 会议等。
MUC 会议由美国海军海洋系统中心NOSC 发起,在美国国防部高级研究计划局DARPA 的资助下,旨在对军事文本信息进行自动分析评估,对命名实体识别技术的评测起到了重要作用。MUC 会议自1987 年开始到1998 年结束,共举办了七届。MUC 会议定义的召回率(Recall)和精确率(Precision)两个评价指标现已成为命名实体识别领域的评价标准。MUC 会议的举办对于命名实体识别的发展起到了极大的推动作用。
ACE 会议是由美国国家标准技术研究院NIST 组织的评测会议,其中的一项重要任务就是命名实体识别。ACE 会议自1999 年开始到2008 年结束,共举办了八届。ACE 对MUC 定义的任务进行了细化,在语料的语种数量和数据规模都有所增加。ACE 会议主要涉及英语、阿拉伯语和汉语三种语言,主要包括实体检测和跟踪、关系检测和表征、事件检测与表征等三任任务。
TAC 会议是由NIST 组织的一系列评估研讨会,旨在通过提供大量测试集,通用评估程序以及可共享其结果的论坛来鼓励自然语言处理和相关应用的研究。TAC 由一组称为“tracks”的任务集组成,每个任务集中于NLP 的特定子问题。命名实体识别的有关评估被归为TAC 中的知识库填充(Knowledge Base Population,KBP)评估任务中。KBP 评估从2009 年开始,每年举办一次,截至2019 年,已经举办了十一届。
SemEval 会议是由国际计算语言学协会ACL 下的特殊兴趣小组SIGLEX 组织的评估会议。该会议是由SensEval 词义消歧评估系列会议发展而来的,后来又加入了语义角色标注、情感分析和命名实体识别等多项任务。SemEval 会议从1998 年开始举办第一届,截至2019 年,已经成功举办了十三届。
2 相关方法
命名实体识别方法发展至今,总体可以分为基于规则的方法和基于机器学习的方法[3],具体如图1 所示。基于机器学习的方法按照对语料依赖程度分为两类:有监督的命名实体识别和无监督的命名实体识别。基于深度学习的方法在命名实体识别任务中已成为当前研究的主要方向,取得的性能也在逐年提高。
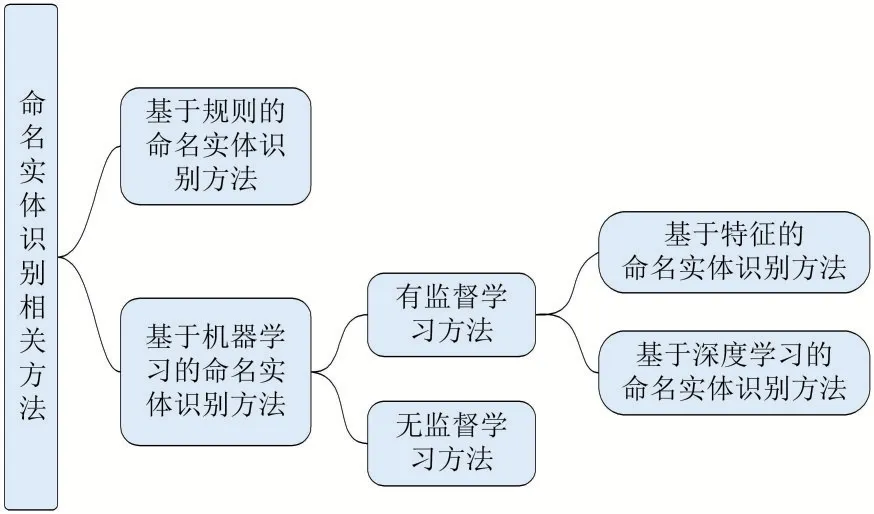
图1 命名实体识别相关方法
2.1 基于规则的命名实体识别方法
在早期的命名实体识别研究过程中,主要以基于规则的方法为主。基于规则的方法,主要由领域专家编写制定规则,要求相对比较高。该方法首先由领域专家编写一些简单的规则,然后在语料库中进行试验,通过对错误的结果进行分析后而不断改进规则,直到命名实体识别的效果达到满意为止。在基于规则的方法中,比较常用的是基于词典匹配的方法,通过字符串完全或部分匹配来完成命名实体识别,实现相对简单且效率较高。基于词典匹配的方法实现过程中,通常可以通过正向、逆向、双向最长匹配,字典树和AC 自动机等各种算法来进行实现。基于规则的命名实体识别方法的优点是无需提前对语料库进行标注,在小规模语料库上效果较好,且系统运行速度快;缺点就是编写规则对人员个人水平要求较高,且系统移植性较差。一些著名的基于规则的NER 系统有LaSIE-Ⅱ、NetOwl、Facile、SAR、Fastus 和LTG 系统。
2.2 基于特征的命名实体识别方法
基于特征的命名实体识别方法属于传统机器学习中的有监督方法。该方法将命名实体识别当作是序列标注任务,具体算法模型需要利用标注好的语料进行训练。基于特征的方法在识别命名实体过程中,通常包括以下几个步骤:①标注语料,一般采用IOB(In⁃side-Outside-Beginning)或IO(Inside-Outside)标注体系对语料库文本进行人工标注;②特征定义,通常选取当前词、前一个词、后一个词、词性等特征,其对命名实体识别的结果影响较大;③训练模型,经常采用的模型主要有隐马尔可夫模型(Hidden Markov Model,HMM)[4]和条件随机场(Conditional Random Field,CRF)[5]。
2.3 基于深度学习的命名实体识别方法
基于深度学习的命名实体识别方法已成为当下研究的主流,而且取得了不错的效果。与基于特征的NER方法相比,基于深度学习的NER 方法无需人工制定规则或者复杂的特征,易于从输入语料中提取出隐藏的特征。在NER 任务中,常用的神经网络主要有卷积神经网络(Convolutional Neural Network,CNN)、循环神经网络(Recurrent Neural Network,RNN)以及基于注意力机制(Attention Mechanism)的神经网络。其中RNN 中的长短时记忆神经网络(Long Shot-Term Memory Neural Net⁃work,LSTM)目前已经广泛应用于NER 任务中。
Li 等人[6]在2020 年提出了一种典型的深度学习NER 总体架构,如图2 所示。该架构主要分为三个部分:①输入分布式表示(Distributed Representations),考虑了单词和字符级别的嵌入,以及结合了在基于特征的方法中已经很有效的附加特征,如词性标签和地名词典;②上下文编码器(Context Encoder),使用CNN、RNN 或其他网络捕获上下文依赖关系;③标签解码器(Tag Decoder),主要用于预测输入序列的标签,也可以训练用来检测实体边界。
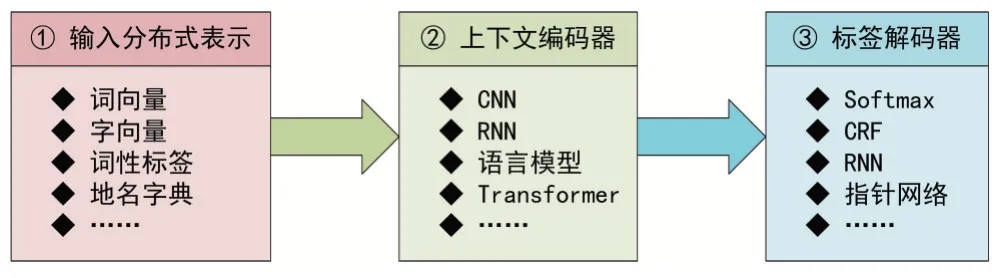
图2 深度学习NER总体架构
按照处理语言领域的不同,基于深度学习NER 方法可分为英文NER 方法、中文NER 方法及其他语种方法。英文及中文NER 常用方法如图3 所示。
(1)英文NER 方法
Huang 等人[7]在2015 年提出了一系列基于LSTM的序列标注模型,包括LSTM、双向LSTM(BI-LSTM)、带有条件随机场(CRF)的LSTM(LSTM-CRF)以及带有CRF 层的双向LSTM(BI-LSTM-CRF),并比较了上述模型在NLP 标记数据集上的性能。首次将BI-LSTMCRF 模型应用到了NLP 基准序列标记数据集中,并证明该模型可以有效地利用过去和未来的输入特征和句子级别的标记信息。Ma 等人[8]在2016 年提出了一种结合双向LSTM、CNN 和CRF 的端到端序列标记模型,是一个真正的端到端模型,不依赖于特定任务的资源、特征工程或数据预处理。Rei 等人[9]在2016 年提出了基于注意力机制的词向量和字符级向量组合方法用于序列标注任务中。该方法认为命名实体识别除了需要词向量,还需要词中的字符级特征向量。在RNN-CRF模型基础上,采用注意力机制对词向量和字符级特征向量进行拼接。Lample 等人[10]在2016 年提出了LSTM-CRF 命名实体识别模型,该模型依赖于两个关于单词的信息源:基于字符的单词表示主要从有监督的语料库中学习得到;无监督单词表示主要从无注释的语料库中学习得到。Li 等人[11]在2019 年提出了一种基于机器阅读理解(Machine Reading Comprehension,MRC)的框架代替序列标注模型统一处理嵌套与非嵌套命名实体识别问题。该方法适用于非嵌套和嵌套两种类型的NER。相比序列标注方法,该方法简单直观,可迁移性强。通过实验表明,基于MRC 的方法能够让问题编码一些先验语义知识,从而能够在小数据集下、迁移学习下表现更好。Yan 等人[12]在2019 年提出了TENER 模型。该模型是在原始Transformer 基础上针对NER 任务进行的改进,采用经过改进的Transformer编码器来对字符级特征和单词级特征建模。
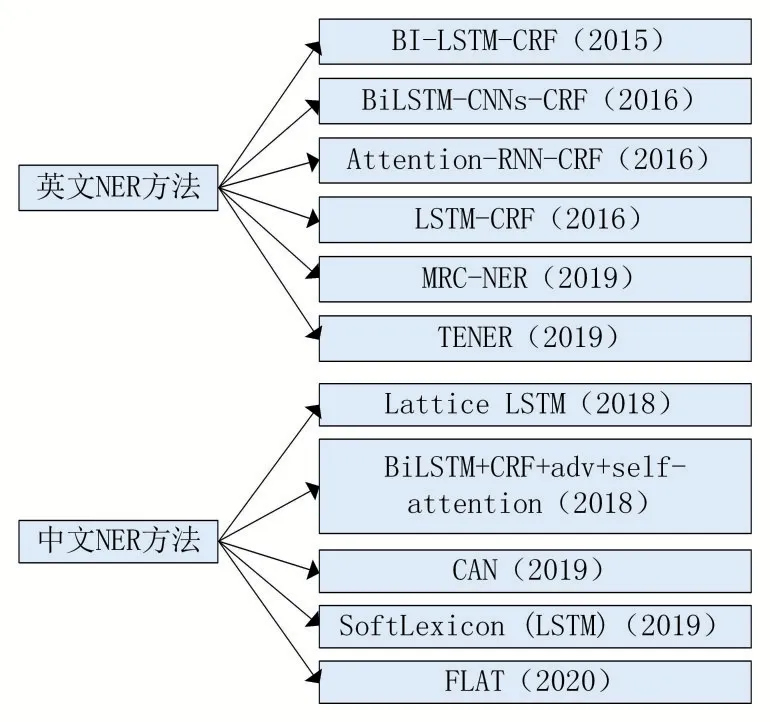
图3 基于深度学习英文及中文NER常用方法
(2)中文NER 方法
Zhang 等人[13]在2018 年针对中文NER 提出了一种网格结构的LSTM 模型(Lattice LSTM)。该模型相对基于字符(character-based)的方法,能够充分利用单词和词序信息;相比基于词(word-based)的方法,不会因为分词错误影响识别结果。该模型的核心思想是通过网格LSTM 表示句子中的单词,将潜在的词汇信息融合到基于字符的LSTM-CRF 中。Cao 等人[14]在2018 年针对中文NER 提出了一种新颖的对抗性转移学习模型(BiLSTM+CRF+adv+self-attention)。作者认为中文分词(Chinese Word Segmentation,CWS)和中文NER 任务有很多地方很相像,也有很多不同。于是提出了对抗迁移学习模型,以充分利用两者共同的边界信息,同时也防止中文分词特有的特征对中文NER 任务造成影响;同时还将自注意力机制引入到模型中,以来捕捉句子中长距离的依赖性和语法信息。Zhu 等人[15]在2019 年针对中文NER 提出了一种基于注意力机制的卷积神经网络模型(CAN)。该模型由一个具有局部注意力层的基于字符的卷积神经网络(CNN)和一个具有全局自我注意力层的门控递归单元(GRU)组成,用于从相邻的字符和句子上下文中获取信息。Ma 等人[16]在2020 年提出了一个简单而有效的中文NER 方法Soft⁃Lexicon(LSTM),可以将词汇信息整合到字符表示中。该方法避免了设计复杂的序列建模结构,对于任何神经网络模型,只需对字符表示层进行细微调整,就可以引入词典信息。同时,该方法还可以很容易地与BERT等预训练模型相结合。Li 等人[17]在2020 年提出了一种适用于中文NER 的FLAT 模型(Flat-Lattice Trans⁃former),是在Zhang 等人[13]Lattice 模型基础上进行的改进。为解决传统Lattice 模型计算效率低下、引入词汇信息有损的这两个问题,FLAT 基于Transformer 结构进行了两大改进:一是对每一个字符和词汇都构建两个头部位置编码和尾部位置编码,将Lattice 结构转化为平面结构;二是引入相对位置编码,以提升Transformer 的位置感知和方向感知。FLAT 模型不去设计或改变原生编码结构,设计巧妙的位置向量就融合了词汇信息,既做到了信息无损,又大大加快了推断速度。
2.4 基于无监督的命名实体识别方法
无监督学习的一个典型方法是聚类。基于聚类的NER 系统基于上下文相似性从聚类组中提取命名实体。无监督NER 的关键思想是:词法资源、词汇模式和在大型语料库上计算的统计信息可以用来推断命名实体的提及。Michael 等人[18]在1999 年提出使用未标记示例来解决命名实体分类问题,提出了两种无监督的命名实体分类算法。该方法表明使用未标记的数据可以将对监管的要求减少到仅7 个简单的“种子”规则。同时,利用数据的自然冗余性,名称的拼写和出现的上下文都足以确定命名实体类型。Nadeau 等人[19]在2006 年提出了一个无监督的地名索引建立和命名实体歧义解决系统。该系统解决了该领域中经常讨论的两个主要限制:一是系统不需要人工干预,例如手动标记训练数据或创建地名索引;二是系统可以处理三种以上的经典命名实体类型(人、位置和组织)。此外,Zhang 等人[20]在2013 年提出了一种无监督的从生物医学文本中提取命名实体的方法。他们的模型采用术语、语料库统计(如反向文档频率和上下文向量)和浅层句法知识(如名词短语组块),而不是监督。在两个主流生物医学数据集上的实验证明了它们的无监督方法的有效性和可推广性。
3 评价指标
在命名实体识别任务评测过程中,国际上的评价指标主要有准确率(Precision)、召回率(Recall)、F 值(F Measure)。
(1)准确率
准确率又称为查准率,是针对识别结果而言的,它表示的是识别结果样本中有多少是对的。把正确的识别结果记为TP(True Positive),错误的识别结果记为FP(False Positive)。其计算公示为:

(2)召回率
召回率又称为查全率,是针对原来的样本而言的,它表示的是原来的样本中有多少被正确识别了。把正确的识别结果记为TP,错误的识别结果记为FN(False Negative)。其计算公示为:

(3)F 值
对于命名实体识别来说,准确率和召回率两个指标有时候会出现相互矛盾的情况,二者实际上为互补关系。这样就需要综合考虑它们,最常见的方法就是F 值,又称为F Score。其计算公示为:
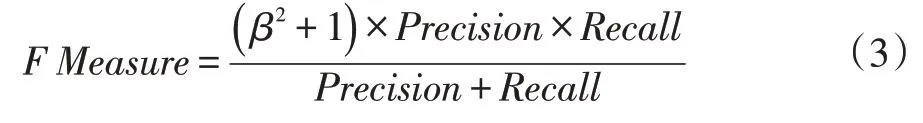
其中β是用来平衡准确率和召回率在F 值计算中的权重。在关系抽取任务中,一般β取1,认为两个指标一样重要。此时F 值计算公式为:
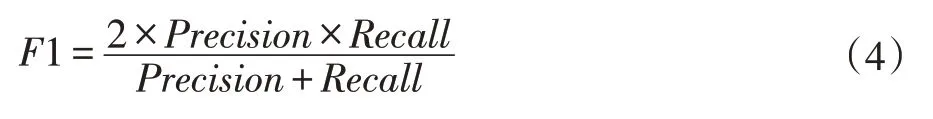
4 结语
本文首先对命名实体识别的产生与发展进行了简要介绍;其次对命名实体识别的相关方法进行了总结和梳理,重点是目前研究较热的深度学习方法;最后对命名实体识别的评价指标进行说明。从深度学习方法中可以看出,BiLSTM-CRF 模型是当前基于深度学习的NER 方法中最常见的模型。NER 系统的成功很大程度上取决于其输入表示,集成或微调预训练的语言模型嵌入向量正成为深度学习NER 的新的发展方向。利用这些语言模型嵌入向量时,可以显着提高性能。另外,当在大型语料库上对Transformer 进行预训练时,显示出Transformer 编码器会比LSTM 更有效。命名实体识别作为一个开放性的热门话题,有待于更多研究者们进一步深入的研究。
猜你喜欢
电脑爱好者(2022年15期)2022-05-30 01:29:23
中学生数理化(高中版.高考理化)(2021年2期)2021-03-19 08:52:46
天津外国语大学学报(2020年1期)2020-03-25 13:29:26
小学生学习指导(低年级)(2019年12期)2019-12-04 03:39:42
电子制作(2019年19期)2019-11-23 08:41:50
少儿美术(快乐历史地理)(2018年7期)2018-11-16 05:31:14
东方女性(2018年3期)2018-04-16 15:30:02
散文诗(2017年17期)2018-01-31 02:34:08
作文评点报·低幼版(2017年13期)2017-04-18 18:15:11
语言与翻译(2015年4期)2015-07-18 11:07:45
