
基于用户评论大数据挖掘的导向应用系统设计
2021-05-25 01:59:36谢卓亨邱金波
卷宗 2021年11期
谢卓亨 邱金波
(广东石油化工学院 电子信息工程学院,广东 茂名 525000)
1 前言
根据最新的数据显示,我国网民规模为8.02亿,互联网普及率达57.7%,截止2018年6月,我国网络购物用户规模达5.69亿。手机网络购物用户规模达到5.57亿,使得网络店铺数量如雨后春笋一般。随之而来的是不断的呈现在网民面前的各大网络商城,如淘宝网、聚美优品、京东商城、易购等,用户选购的时候,面对网络上大量的参齐不齐的评价数据,用户消费者无法直观简洁地获取到该商品的有效 信息。
2 系统的设计方案
本文首先分析电商信誉评价体系特点,了解其评价指标以及每个指标具有的实时性和评分标准,以及产品综合评分的评判指标和评分计算方法。运用python语言的Scrapy框架获取大量的用户评价信息,并存入mysql数据库,再利用自然语言SonwNLP文本情感分析系统,对mysql数据库中的用户评价进行逐句分词处理。随即,运用关联规则挖掘算法找出客户评价中描述产品特性的词汇,并提取出与该产品特性词汇相关联的观点词以及观点词的极性。最后,利用建好的数学模型和算法并用django和pyecharts数据的可视化为消费者提供真实可靠的宝贵信息。
3 各功能模块设计
3.1 数据准备—网络爬虫
首先,根据选定的研究对象,利用Scrapy(Scrapy是一种用于抓取网站和提取结构化数据的应用程序框架,可用于广泛的有用应用程序,如数据挖掘,信息处理或历史存档。)和requests对特定数据进行爬取,然后,对分散的数据按照一定的规则或格式合并,并存入数据库。
3.2 数据处理—基于评论内容的评价指标赋值
对选取的数据进行在处理,检查数据的完整性和一致性,消除噪音,滤除与数据无关的冗余数据。通过已经建立的评价指标体系, 需要将用户在线 评论内容中的各个观点与上述指标一一对应并将用户 的观点以及情感强度量化为具体数值。
SonwNLP数据的分析,词表构建,利用Python的Snownlp进行中文分词(Character-Based Generative Model),词性标注(TnT 3-gram 隐马),情感分析,文本分类(Naive Bayes),提取评论关键字(TextRank算法),在利用大量的买家在线评价内容、二次评价、买家信用等级、采集时间等数据,建立数学模型。
3.3 温数据的可视化—展示大数据
采集为了买家能够直接地获取到有用的大数据,将采用django(一个高级的Python Web框架,采用MVC的架构模式)+pyecharts(pyecharts是一个用于生成Echarts图表的类库)将数据可视化展示。
3.4 核心技术要点
3.4.1 Scrapy爬虫技术
通过抓包抓取各大电商的评论url,并且分析参数。并且对不符合条件的数据进行清洗,消除错误、冗余和数据噪音,以此保证数据质量。
例如某件商品的质量无法划分为5个等级,而是通过用户对商品质量好坏的观点描述及情感倾向来判定其商品质量是否满足用户的需求,进而反映网商的信用。因此用户评论所涉及的评价指标的量化实际上是根据情感词的褒贬词性以及情感倾向度按照一定的标准进行量化后为其所描述的属性词进行赋值的过程。
3.4.2 Snownlp建模
通过对大量电子商务平台的观察与分析,构建能够对应网商信用度评价指标的属性词表利用Snownlp对筛选出了的评论依次进行分词处理。根据构建的属性词表筛选出来的评论进行查找匹配,保留匹配成功的属性词,并检查匹配成功的属性词是否满足要求的覆盖范围, 符合要求则保留该条评论。
情感分类的基本模型是贝叶斯模型Bayes,对于有两个类别c1和c2的分类问题来说,其特征为w1,…,wn,特征之间是相互独立的,属于类别c1的贝叶斯模型的基本过程为:
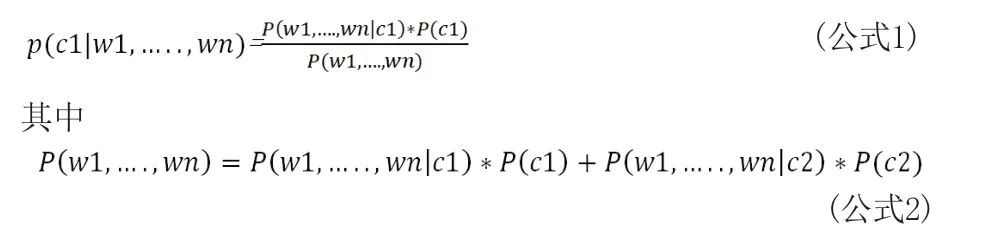
3.4.3 用户评论量化的基础
光敏确定指标的量化公式,在用户的评论中,既包含属性词,同时还包含对属性词进行描述的动词和形容词以及描述情感强度的副词,为了达到统一的评分标准,在进行量化前笔者根据上述属性词表对评价指标的得分按照一定的得分规则进行赋值。通过语义分析可以看出,电子商务环境下用户大多数评论内容中的词语组合较为浅显易懂,搭配比较简单,例如:“形容词+副词”的形式最为普遍,因此可以定义指标得分公式为:

其中,s为指标最终得分,i为属性词的初始值,默认为3分,j为副词的极性得分,如果句子中没出现副词则默认为1分,k为动词或形容词极性得分。
4 结论
本设计通过交互控制界面可以实现用户评论大数据挖掘的导向应用等功能,还可以提供对大量数据进行情感分析的数据基础。对实际应用的大型电子商务网站的建立,优化有一定的工程设计应用参考意义。
猜你喜欢
阅读(快乐英语中年级)(2023年6期)2023-05-24 22:53:36
三门峡职业技术学院学报(2021年4期)2021-04-19 09:00:38
大众投资指南(2021年35期)2021-02-16 01:06:26
英语世界(2021年13期)2021-01-12 05:47:51
电力与能源(2017年6期)2017-05-14 06:19:37
国家图书馆学刊(2016年2期)2016-10-09 06:19:31
信息通信技术(2015年6期)2015-12-26 01:16:46
高中生学习·高三版(2014年3期)2014-04-29 06:09:37
电子设计工程(2014年18期)2014-02-27 12:00:13
图书馆建设(2012年3期)2012-10-23 05:16:30
