
基于用户历史序列的点击率预估
2021-05-25 05:26包晓安张瑞林
软件导刊 2021年5期
包晓安,陈 昀,张瑞林,张 娜,徐 曼
(浙江理工大学信息学院,浙江杭州 310000)
0 引言
近年网络广告成为广告商推广产品和营销的流行方式,为电商网站提供了大量收益。在按点击付费的广告系统中,广告通过千次有效点击(effective Cost Per Mille,eCPM)排序,而eCPM 是由广告点击率乘以点击的期望收益计算的。点击的期望收益与广告产品本身性质有关,点击率在广告系统的收益中起关键性作用,所以点击率预估模型性能直接影响到广告系统收益。与有目标的搜索不同,用户点击广告没有明确意图,在建立点击率预估模型时,需要从丰富的历史行为中提取用户的兴趣和需求。描述用户和广告特征是广告系统点击率建模的基本要素,合理利用这些特征并从中挖掘信息至关重要,Rendle[1]提出因式分解机(Factorization Machines,FM)[1],通过计算二阶特征组合预估点击率;GBDT+LR[2]通过决策树模型对输入特征进行训练,然后把决策树模型的输出输入到LR 模型中进行点击率预估。
近年由于深度学习在图像处理和自然语言处理中的成功应用,基于深度学习的点击率预估模型成为研究热点。这些模型有相同的模式,都是由嵌入层和多层感知机组成。先通过嵌入层把高维稀疏的原始数据变成低维稠密数据,再把低维稠密数据输入多层感知机进行计算。多层感知机可以计算特征的高阶非线性特征组合,减去了人工特征组合过程。Hengtze 等[3]提出Wide&Deep 结合LR深度神经网络计算低阶和高阶特征组合;Guo 等[4]提出DeepFM 用FM 代替Wide&Deep 的Wide 部分,自动计算二阶特征组合。然而这些模型只考虑了物品自身的特征组合运算,没有考虑历史行为隐藏的信息和用户行为在一段时间内的联系性。
在点击率预估模型中特征的提取和组合十分重要,用户的兴趣和需求是多变的,但在一段时间内用户的兴趣和需求是相似的。协同过滤算法通过计算物品之间或用户之间的相似度来预估点击率。自注意力机制可使历史数据根据目标物品的不同有不同的权重,卷积神经网络可以有效提取数据特征。因此,本文提出结合协同过滤和自注意力机制并用卷积神经网络提取特征的CANN(Collabora⁃tive Attention Neural Network,CANN)模型。CANN 通过自注意力机制计算历史点击物品与目标物品的相似度对历史数据加权,并采用卷积神经网络对加权后的历史数据进行特征提取。本文主要工作如下:①结合用户历史行为进行点击率预测;②提出CANN 模型,结合协同过滤和自注意力机制对目标物品和历史行为进行计算,使得历史行为面对不同的目标物品时有不同的侧重点;③通过卷积神经网络对加权后的历史行为进行特征提取;④在两个公共数据集上进行比较实验,验证CANN 的有效性。
1 相关工作
深度神经网络在CTR 模型中应用十分广泛,输入特征越来越多,模型层数越来越深,为得到更好的特征组合结果进行了很多模型结构改进工作。
FM 可以当作只有一个隐藏层的网络,首先在稀疏的输入数据上使用嵌入层,然后施加专门设计的变换函数进行目标拟合,以获取特征之间的组合关系。
Wide&Deep 用神经网络代替了变换函数,通过一个y=WT x+b线性模型和一个深度神经网络计算点击率。PNN[5]在神经网络结构中加入了一层乘积层,试图去获取更高阶的特征组合。PNN 在嵌入层之后对特征进行两两相乘,再把相乘的项与原来的项一同输入神经网络。Deep⁃FM 用因式分解机代替Wide&Deep 的Wide 部分,省去了专家特征选取。xDeepFM[6]改进了DeepFM,使不同特征相乘有不同的向量。这些模型通过嵌入层和多层感知机减少了人工特征组合工作。
自注意力机制来自自然语言处理,它根据人的注意力在某时刻只会集中于某些部分的生物性特征进行设计,对词向量进行加权求和使不同问题的关注点不同。2017 年Ashish[7]的Attention is all you need 受到关注,自注意力机制被广泛应用到各个领域。Jun 等[8]将自注意力机制和FM 结合提出了AFM 模型。
卷积神经网络在点击率预估模型中的应用越来越多,如Tang[9]就使用了卷积神经网络,FGCNN[10]通过结合卷积神经网络和PNN 进行点击率预估。
2 CANN
本文提出的CANN 由自注意力机制、卷积神经网络组成,可以学习用户历史序列特征。下面详细介绍嵌入层、协同过滤算法、自注意力机制、CANN。
2.1 嵌入层
由于多用户与物品交互少,因此点击率预估模型输入是十分稀疏的高维输入,如用户U={u1,u2,…,um},物品I={i1,i2,…,in},用独热码表示u1=[0,1,0,0,0,…,0],i1=[0,1,0,0,0,…,0],u1点击过的物品S1=[1,0,0,0,0,1,…]。如果物品有1 000 个,则一个物品的独热码表中就会有999 个0,1 个1,输入量大且数据稀疏,十分不易于计算,因此引入嵌入层。
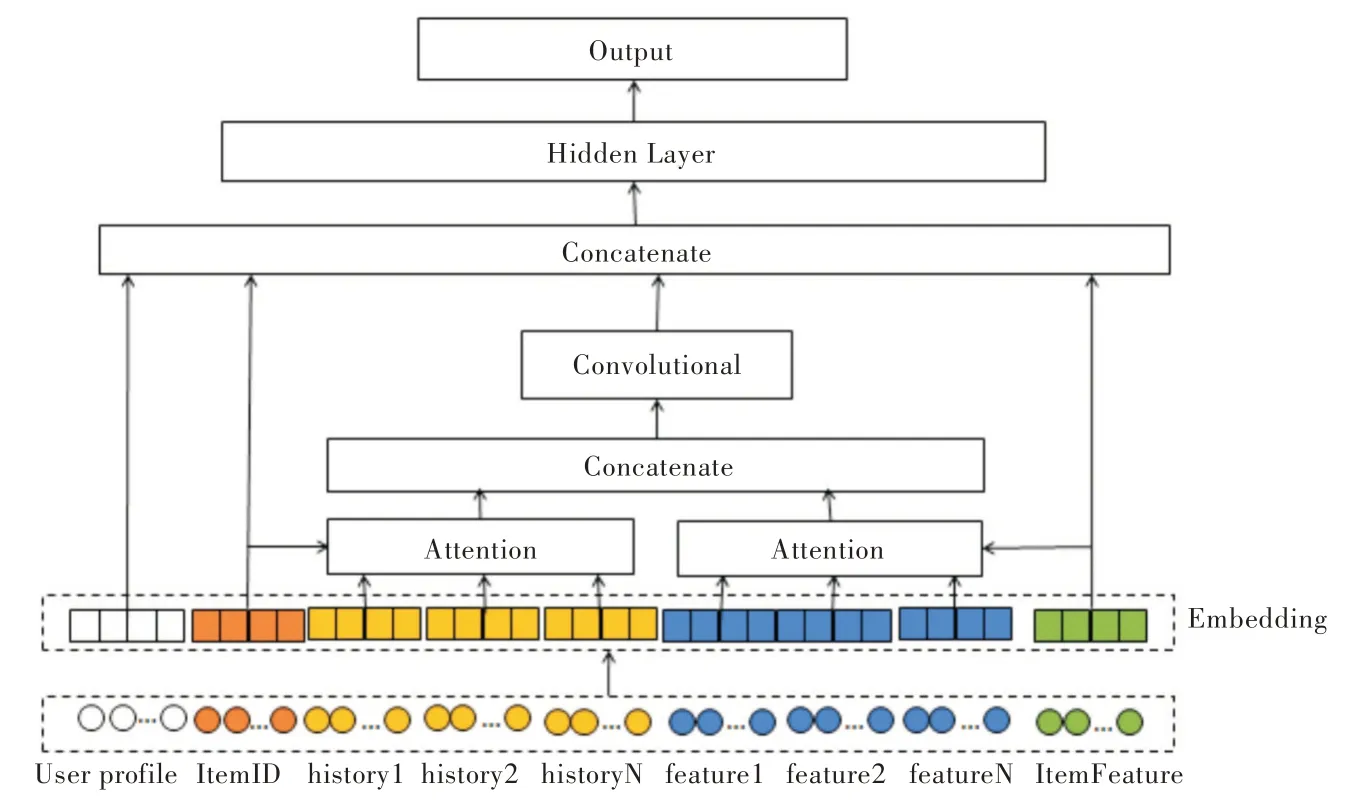
嵌入层的思想来源于自然语言处理中把单词转换成向量,意思相近的单词距离相近,可通过skip-gram 计算单词向量。在点击率预估模型中,输入特征稀疏且维度高数据量大,不利于计算。引入嵌入层思想,用一个向量代表一个特征值,使输入数据变得稠密。用一个低维向量表示一个物品I∈Rm×k,k 协同过滤推荐算法是根据用户的历史数据去推测用户对物品的点击率。根据对象不同,协同过滤推荐算法又分为基于物品的协同过滤、基于用户的协同过滤和混合推荐。本节介绍基于物品的协同过滤。在基于物品的协同过滤中,用户对某物品的点击率预估余弦相似度公式为: 其中,i为目标物品,j为用户u 已点击过的物品,m 为用户点击过的物品总数,|N(i)∩N(j)|为同时点击物品i和物品j的用户数,|N(i)|,|N(j)|分别为点击物品i的用户数,点击物品j的用户数。在点击物品i的用户数和点击物品j的用户数不变时,同时点击物品i和物品j的用户数越多,物品i,j的相似度越大,用户u 点击物品i的可能性也越大。如尿不湿和啤酒问题,通过基于物品的协同过滤可以发现尿不湿和啤酒经常一起出现,因此它们会有较高的相似度。 在加密—解密框架中,自注意力机制使翻译不同的单词时其余单词有不同的权重。自注意力机制通过Q,K,V计算,其中,X 为输入数据,计算公式为: 其中,dk是Q 和K 的维度,用于防止Q,K 点乘结果过大。在CANN 中,结合协同过滤算法用余弦相似度代替计算: 在计算点击率的同时计算物品相似度,使相似物品的距离相近。不同于加密—解密框架,在CANN 中可只计算目标物品与用户历史行为的Attention,分别计算物品ID 和物品特征ID 的Attention。 CANN 结构如图1 所示,总体分为两部分:①对历史数据进行信息提取;②全连接层。输入由用户ID、物品ID、物品特征ID、历史物品ID 和历史物品特征ID 组成,输入数据先经过Embedding 层得到稠密数据。在自注意力机制中将物品ID 和历史物品ID 计算,将物品特征ID 和历史物品特征ID 计算,将计算后的数据输入卷积神经网络进行特征提取,最后把所有数据都输入全连接层进行计算。卷积神经网络计算过程如图2 所示,每一层都用m×1的卷积核进行卷积计算,直到m=1,提取出历史序列相应维度特征。 Fig.1 CANN structure图1 CANN 结构 Fig.2 Convolution neural network calculation process图2 卷积神经网络计算过程 全连接层用ReLU 作为激活函数,计算公式为hi=,hi表示第i 个隐藏层,Wi表示第i 层权重,bi表示偏差。在输出层用Sigmoid 作为激活函数y′=本文用交叉熵损失函数计算损失,公式如下: 其中,yϵ{0,1}表示标签,y′为模型输出值,表示用户点击概率。 MovieLens-1M:在推荐系统中常用此数据集,包含1 000 209 条用户对电影的评分,3 900 部电影和6 040 个用户,其中电影共有18 个类别。为了使数据符合点击率预测,本文将用户看过的电影都标注为1,并随机从用户未看过的电影中选取负样本标注为0,使正负样本比例为1∶1。本文按用户评论时间排序,把用户每5 个评论作为历史数据,第6 个评论作为目标物品,预测第6 个物品的点击率,并把每个用户的最后一组序列作为测试集数据。嵌入层维度设置为48,优化器为Adam,学习率为0.001。 UserBehavior:UserBehavior 是阿里巴巴提供的一个淘宝用户行为数据集,用于隐式反馈推荐问题的研究,其中包含987 994 个用户,4 162 024 个商品,9 439 个商品类别,100 150 807 条用户行为数据。文件中包含用户ID、商品ID、商品类目ID、行为类型和时间戳。用户行为数据包括4 种行为,分别为点击商品、将商品加入购物车、购买商品和收藏商品。由于本文只预测点击率,所以本文只使用其中的点击商品行为。选取近5 万个用户,每个用户15条点击数据,将其按用户和时间排序,其它处理同电影数据集一样,最终获得900 144 条训练数据,99 976 条测试数据,如表1 所示。 Table 1 Data set statistics表1 数据集统计 DNN:普通的深度神经网络,只包含嵌入层和全连接层。 PNN:在嵌入层之后插入了一层乘积层。 DeepFM:结合因子分解机和深度神经网络的模型。 点击率预估中AUC(Area Under Curve)经常被用来作为评估标准,本文使用AUC 和LogLoss(交叉熵损失)作为评估标准。 表2 显示对比模型和CANN 的实验结果。从表2 可以看出,所有模型都优于DNN,说明在DNN 上添加特征处理是有效的。在MovieLens-1M 数据集和UserBehavior 数据集上,CANN 的AUC 和LogLoss 都要明显好于其它3 个模型,这说明对历史序列进行特征提取的重要性。在其它3 个模型中历史序列被当作普通的特征数据,在CANN 中历史序列通过协同过滤自注意力机制进行处理并通过卷积神经网络提取特征,因此CANN 的效果要好于其它3 个模型。 Table 2 Experimental results表2 实验结果 本文通过用户历史序列预测广告点击率,结合协同过滤和自注意力机制对历史序列进行计算,使数据有不同的侧重点,使用卷积神经网络提取特征。在两个公共数据集上进行实验,通过对比验证了本文提出的CANN 模型的有效性。无论是AUC 还是LogLoss,CANN 都要明显好于其它3 个模型。用户历史序列数据是刻画用户特征的重点,在未来工作中可以继续对利用历史序列提取用户特征进行研究,进行用户画像,进一步提高点击率预估准确性。2.2 协同过滤推荐算法
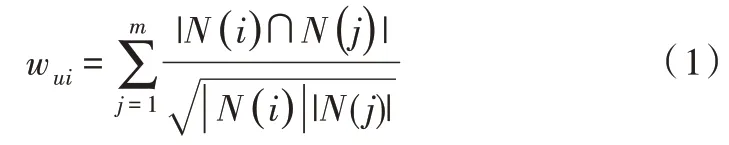
2.3 自注意力机制
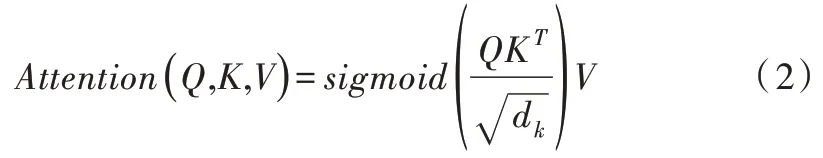

2.4 CANN


3 实验
3.1 实验数据

3.2 对比模型
3.3 评估标准
3.4 分析与结论

4 结语
猜你喜欢
矿山安全信息(2022年22期)2022-11-24
小学生学习指导(低年级)(2022年5期)2022-05-31
疯狂英语·初中天地(2021年11期)2021-02-16
少年漫画(艺术创想)(2019年2期)2019-06-06
华东师范大学学报(自然科学版)(2018年3期)2018-05-14
当代化工研究(2016年2期)2016-03-20
小天使·一年级语数英综合(2015年8期)2015-07-06
海峡姐妹(2015年8期)2015-02-27
海外英语(2013年3期)2013-08-27
