
基于一种条件熵距离惩罚的生成式对抗网络*
2021-05-23 06:12:18谭宏卫王国栋周林勇张自力
软件学报 2021年4期
谭宏卫 ,王国栋 ,周林勇 ,张自力,3
1(西南大学 计算机与信息科学学院,重庆 400715)
2(贵州财经大学 数统学院,贵州 贵阳 550025)
3(School of Information Technology,Deakin University,Locked Bag 20000,Geelong,VIC 3220,Australia)
GANs 是由Goodfellow 等人[1]受博弈论中二人零和博弈思想的启发所提出的一种深度生成模型,其网络结构主要由判别器网络和生成器网络所构成.判别器的目的是尽量正确地判断:输入数据是来自真实数据分布还是来自生成分布;而生成器的目的是尽量去学习与真实数据分布一致的分布,并生成以假乱真的样本.虽然GANs 已广泛应用于图像生成[2,3]、超分辨率图像合成[4,5]、语义分割[6,7]等多个领域,但要生成高质量的样本仍是该领域的一个挑战.
为了提高GANs 生成样本的质量,出现了很多有针对性的算法[8],这些算法主要基于以下两个角度而提出.
一是基于网络结构的算法研究.由于GANs 网络结构的灵活性,其判别器网络和生成器网络可以是任何类型的网络结构.深度生成式对抗卷积网络(deep convolutional generative adversarial network,简称DCGAN)[2]就是其中一种典型的网络结构算法,其判别器和生成器均使用卷积神经网络(CNN),同时改变梯度优化算法(Adam)[9],以及加入批量标准化(batch normalization,简称BN)[10]层等策略,以提升GANs 网络的稳定性及整体性能.此后,研究者们将一些高性能网络模块嵌入到DCGAN 的网络结构中,极大地提升了GANs 网络的性能,如将残差模块[11]整合到WGAN-GP[12]中以生成文本,将自注意机制模块[13]整合到条件GANs 中以生成图像[14],将Laplacian 金字塔模块[5]融入到GANs 网络中以提高人脸图像生成的质量[4]等.除此之外,还有部分算法是针对特定的应用而提出不同结构的GANs 算法,如SGAN[15]、TripleGAN[16]、CycleGAN[17]、BigGAN[6]等.这些算法基本上都是从纯网络结构角度来设计的,并未考虑样本多样性问题.本文利用信息熵来衡量样本多样性,并将其融入到算法中以提高GANs 生成样本的质量.
二是基于目标函数的算法研究.这类算法主要从两个方面展开研究:(1) 改变目标函数的形式;(2) 惩罚目标函数.针对前者,Nowozin 等人[18]将原始GANs 中的JS 散度[19]推广到一般化的f 型散度,并提出f-GAN 算法;进一步地,Mao 等人[3]根据原始GANs 的对抗规则,用平方损失函数来代替GANs 中的熵损失函数,从而提出LSGAN 算法.除此之外,Arjovsky 等人[20]从微分流形的角度严格证明了JS 散度是导致GANs 生成器梯度消失及训练不稳定的主要原因,由此他们提出用Wasserstein I 型距离[21]代替JS 散度来衡量真实分布与生成分布之间的距离,并提出WGAN 算法[22].至于后者,Gulrajani 等人[12]利用1 中心梯度惩罚技术来解决WGAN 中Lipschitz 条件的限制,并提出WGAN-GP 算法以提高WGAN 生成样本的质量.由此研究路线,Hoang 等人[23]开发了零中心梯度惩罚的GANs 算法(GAN-0GP).Miyato 等人[24]提出谱标准化的生成式对抗网络(SNGAN),他们利用标准化的谱范数来限制判别器网络的Lipschitz 常数,使得网络的Lipschitz 常数逼近于1,这相当于对判别器网络实施正则化.截止目前,虽然有很多优秀的GANs 算法极大地提升了生成样本的质量,但仍不能满足现实任务的需求,亟需探索高性能的算法以提高GANs 生成样本的质量.
基于对上述GANs 算法研究的调查,本文提出一种条件熵距离惩罚的生成式对抗网络,旨在进一步提高GANs 生成样本的质量.我们所提出的这一对抗网络与其他惩罚技术最大的区别在于:惩罚函数直接惩罚生成器,而非判别器.首先,利用条件熵构造一种距离,可证此距离满足度量空间中的三大条件:正定性、对称性及三角不等式.为了既能保证生成数据多样性与真实数据多样性的一致性,又能迫使生成分布尽可能地逼近真实分布,本文直接用这个距离来惩罚GANs 生成器.除此之外,本文在DCGAN[2]网络结构的基础上,进一步优化GANs网络结构及初始化策略,主要的优化策略有:(1) 将批量标准化(BN)和谱标准化(SN)有机地融入到判别器网络中;(2) 删除生成器中的尺度不变层(311 层),即卷积核为3、步长为1 以及加边数为1 的卷积层;(3) 改变两个网络的初始化策略,判别器和生成器均使用正交初始化[25].这样的网络结构设计及初始化策略,不但能缩小网络的参数空间和降低显存消耗,而且还能提高网络的训练效率和性能.
本文第1 节简要介绍GANs 基础知识.第2 节构建一种距离,优化网络结构,并提出一种GANs 惩罚算法.第3 节是实验.第4 节为本文总结.
1 背景知识
GANs 是一种有效而直接的深度生成模型,其基本网络结构由判别器网络D和生成器网络G所构成.本质上,GANs 的优化问题是一个极小极大问题[1],其损失函数分为两部分,分别对应于判别器网络和生成器网络的损失函数,其损失函数分别如下:
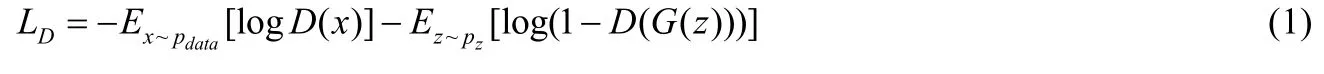

其中,pdata和pz分别表示真实数据分布和隐分布(先验分布).为便于表示,令表示生成分布,则有从理论上讲,GANs 经过多轮迭代,可使生成分布无限逼近真实分布[1].但在训练之初,方程(2)中的损失函数有可能达到饱和,无法传递有价值的信息,使得两个分布无法逼近.鉴于此,Goodfellow 等人[1]建议将饱和的损失函数(2)转化成非饱和损失函数,于是有

相比方程(2),方程(3)中的损失函数更能使GANs 训练稳定,也因此有研究者将原始GANs[1]称为非饱和型GANs(non-saturating GANs,简称NSGANs)[26].
GANs 的训练过程分为两个阶段:第1 阶段训练判别器D,第2 阶段训练生成器G.当训练完判别器D之后,传递真假信息给生成器G,而生成器G根据信息(实质上是梯度信息)的真伪,调整更新策略,尽量生成高质量的样本去“哄骗”判别器.于是,产生了这样的对抗策略:当训练判别器D时,尽量使D(G(z))=0;而当训练生成器G时,尽量使D(G(z))=1.通过这样的对抗策略,判别器和生成器都在不断地提升彼此的判别能力和生成能力,直到判别器无法判断生成器生成的样本是来源于真实数分布还是生成分布.图1 所示为GANs 的训练框架图.

Fig.1 The framework for training GANs:Training D in first stage (in the red dotted box)and training G in second stage (in the black solid line box)图1 GANs 的训练框架:第1 阶段训练判别器D(红虚线框内),第2 阶段训练生成器G(黑实线框内)
2 条件熵距离惩罚的生成式对抗网络
本节将详细阐述本文所提出的惩罚算法.首先,利用条件熵构建一种距离,并将其直接惩罚于生成器的非饱和损失函数上,即方程(3);其次,在DCGAN 网络结构[2]的基础上,优化GANs 的网络结构及超参设置,改变生成器网络和判别器网络的初始化策略,以此来提升模型的训练效率及性能.
2.1 条件熵距离
信息熵是随机变量不确定程度的度量;它也是从平均意义上描述随机变量所需信息量的度量.设X是离散型随机变量,其分布函数为则X的信息熵[19]为

其中,x 表示随机变量X的取值空间.同理,对于离散型随机变量Y,有其中,FY(y)是随机变量Y的分布函数,y 是Y的取值空间.对于在X给定的条件下,随机变量Y的条件熵[19]可定义为

其中,F(x,y) 和F(y|x) 分别表示X和Y的联合分布函数和条件分布函数.若要度量两个随机变量分布之间的距离,可用它们之间的KL 散度[19]来度量,其定义如下:

现考虑度量两个随机变量X和Y之间的关系或一个随机变量包含另一个随机变量的信息量,可用两个随机变量之间的互信息来度量[19],其定义为

由KL 散度(6)定义可知,I(X;Y)=D(F(x,y)||FX(x)FY(y)).由此可见,I(X;Y)也度量了两个随机变量之间的距离;同样,I(X;Y)非负,并且,当且仅当X=Y时,I(X;Y)=0.但是,I(X;Y)同样不是两个随机变量之间真正的距离,因为它不满足距离定义中的三角不等式.鉴于此,根据方程(5)可构造如下距离:

而又由I(X;Y)=H(X)-H(X|Y)=H(Y)-H(Y|X),可得ρ(X,Y)=H(X)+H(Y) -2I(X,Y).由方程(8)可知,ρ(X,Y)由条件熵所构成,故称其为条件熵距离(conditional entropy distance,简称CED).需要特别指出的是,若X和Y为连续性随机变量,只需将每个定义中的分布函数换成概率密度函数,求和符号换成相应的积分符号即可.
定理1.ρ(X,Y)是一种距离,即满足:
(1) 正定性:ρ(X,Y) ≥ 0,当其仅当X=Y时,ρ(X,Y)=0.
(2) 对称性:ρ(X,Y)=ρ(Y,X).
(3) 三角不等式:对于随机变量X、Y、Z,有ρ(X,Y)+ρ(Y,Z)≥ρ(X,Z).
证明:
(1) 正定性.由于熵是非负,得ρ(X,Y)=H(X|Y)+H(Y|X) ≥ 0,并且当X=Y时,H(X|Y)=H(Y|X)=0,可知ρ(X,Y)=0;反之,当ρ(X,Y)=0时,由ρ(X,Y)=H(X|Y)+H(Y|X)及熵的非负性,有H(X|Y)=H(Y|X)=0,此时X=Y.因此,ρ(X,Y) ≥ 0,当其仅当X=Y时,ρ(X,Y)=0.
(2) 对称性.由ρ(X,Y)=H(X|Y)+H(Y|X)=H(Y|X)+H(X|Y)=ρ(Y,X)易知,ρ(X,Y)=ρ(Y,X).
(3) 三角不等式.若要证ρ(X,Y)+ρ(Y,Z)≥ρ(X,Z),只需证H(X|Y)+H(Y|X)+H(Y|Z)+H(Z|Y)≥H(X|Z)+H(Z|X)成立.而对于随机变量X、Y、Z,有H(X|Y)+H(Y|Z)≥H(X|Y,Z)+H(Y|Z)=H(X,Y|Z)=H(X|Z)+H(Y|X,Z)≥H(X|Z).
同理可得,H(Y|X)+H(Z|Y)≥H(Z|X),合并两个不等式就有H(X|Y)+H(Y|X)+H(Y|Z)+H(Z|Y)≥H(X|Z)+H(Z|X)成立,即有ρ(X,Y)+ρ(Y,Z)≥ρ(X,Z)成立.因此,ρ(X,Y)是一种距离.证毕.□
2.2 生成器的条件熵距离惩罚
GANs 生成样本的质量与其样本的多样性和逼真度密切相关.鉴于此,需构建这样一种GANs 算法:在保持多样性的同时,尽量使得生成分布无限逼近真实分布.利用条件熵距离能实现这样的算法,信息熵可度量样本的多样性,而由此构造的距离可度量生成分布与真实分布之间的距离.为此,只需将条件熵距离直接惩罚于GANs生成器的目标函数上,使之生成的样本更具多样性和高逼真度,从而提高GANs 生成样本的质量.在判别器损失函数不变的条件下,将条件熵距离直接加入到生成器非饱和损失函数中,即方程(3)中,有:

其中,λ是惩罚因子.在实际中,并不容易估算方程(10)中的条件熵距离,其需要具体的分布函数或密度函数表达式,以图像生成为例,图像数据的真实分布和生成分布并不可知.在这种情况下,用经验分布函数代替真实分布函数不失为一个好的选择.设真实数据样本的经验分布函数为pEdata,生成数据样本的经验分布函数为pEG,则方程(10)中的由此看出,随机变量的取值空间分别是真实数据域和生成数据域.由损失函数方程(9)和方程(10)构成的GANs,我们称其为条件熵距离惩罚的GANs,简记为熵距离GANs(entropy distance GAN,简称EDGAN).EDGAN 的算法流程如算法1 所示.
算法1.条件熵距离惩罚GANs 算法(EDGAN).
EDGAN 算法利用小批量随机梯度下降法训练网络,同时使用OAdam 梯度优化算法(β1=0.5,β2=0.9),判别器和生成器均使用正交初始化,惩罚因子λ设为1.
输入:
· 样本批量数m=64;
· 两个网络学习率:判别器lr_D=0.0001,生成器lr_G=0.0004;
· 隐分布Z~N128(0,0.02);
· 网络迭代总次数k= 100000;
· 判别器迭代次数kD=2,生成器迭代次数kG=1.

根据条件熵距离的特性,EDGAN 算法在尽量保持样本多样性的同时,使得生成分布与真实分布之间的距离尽可能地接近,即在EDGAN 算法的更新过程中,同时考虑样本的多样性和逼真度两个因素,这有助于提高GANs 生成样本的质量.虽然GANs 的目标函数是影响其性能的关键因素,但绝不是唯一的影响因素,这其中还有网络结构、超参设置及初始化策略等因素都有可能影响其性能.因此,优化GANs 的网络结构及参数设置也是提升GANs 性能的重要技术手段之一.本文将在DCGAN 网络结构[2]的基础上,优化GANs 的网络结构及超参设置,改变GANs 的初始化策略,缩小GANs 的参数空间,加速GANs 的训练效率,并结合惩罚机制,提升GANs的整体性能.
2.3 优化网络结构
DCGAN 的网络结构是一种经典的GANs 网络结构,其判别器网络和生成器网络均使用卷积神经网络(CNN),它的基本参数设置是:在判别器和生成器中均使用批量标准化(BN),生成器的激活函数除输出层用Tanh函数外,其余层都使用ReLU 激活函数[27],判别器除最后一层用Sigmoid 激活函数外,其余层均使用LeaklyRelU激活函数[28](斜率为0.2),两个网络的参数初始化都取值于N(0,0.02)随机数,两个网络的学习率都是0.000 2,隐分布是均匀分布U[-1,1],批量数(batchsize)是128,梯度优化算法是Aadm 算法[9](β1=0.5,β2=0.999).图2 是图像尺寸为3 × 32 ×32 的DCGAN 网络结构,其中,在判别器中类似于conv 64 3 1 1 BN LReLU 的卷积层依次表示该卷积层网络的输出通道是64(即深度),卷积核(kernel)是3,步长(stride)是1,加边数(padding)是1,卷积操作之后执行批量标准化,最后使用激活函数LReLU(LeakyLReLU)输出该层网络结果.同理,在生成器中,首先将隐分布随机数(noise)压缩成尺寸为512 × 4 ×4 的样本,然后传入下一层;deconv 表示降卷积网络层,其他表示的含义与判别器一样.
本文所有的实验都在Pytorch 框架[29]下完成,为了便于表示和叙述,其网络结构的表示方法也是借助于Pytorch 中的表示方法.在Pytorch 中,如果卷积核为3,步长是1,加边数也是1,则无论是判别器中的卷积层还是生成器中的降卷积层的输出尺寸与上一层的尺寸一致,我们将这种卷积层称为311 尺度不变层.这种卷积层具有特殊的含义,它只提取特征不作尺度变换.因此,在DCGAN 的网络结构中,常在311 尺度不变层后面加上尺度变换层构成另一类输出通道下的样本尺度.这样的设计在每类输出通道下都要进行两次特征提取,使得所提取的特征更加精细化.如果在判别器中精细化的特征更有利于提升其判别能力,但在生成器中,就不一定能够提升生成能力.因为精细化的特征使得生成器更容易忽视样本的一般特征,从而导致生成的样本质量反而下降.后面的实验也证实了这样的判断.

Fig.2 The 3 × 32 × 32 network structure of DCGAN图2 图像尺寸3 × 32 × 32为的DCGAN 网络结构
优化网络结构是提升GANs 性能的技术之一.鉴于上述分析,剔除DCGAN 生成器中所有的311 尺度不变层将有助于提升GANs 生成样本的质量,同时也极大地缩小生成器网络的参数空间,加速网络的训练效率.特别需要强调的是,图2 所示生成器的倒数第2 层也是311 层,但其真正的目的是通道变换,而非特征提取,所以不能剔除.除此之外,本文还将SNGAN[24]中的谱标准化(SN)策略融入到GANs 的判别器中.与DCGAN 和SNGAN最大的不同是,改进的判别器网络并非单纯地使用批量标准化或谱标准化,而是将两者有机地融合到判别器网络中.具体地说,将SN 层加入到Sigmoid 层的前一层,其余层均使用BN 层.这样设计的目的在于,充分地利用两种标准化的优势.BN 的主要作用是使前后两层之间的分布尽量保持一致,减小每层网络内部之间的协方差偏移(covariate shift),改善梯度更新过程,加速网络收敛.而SN 的主要作用是使得每层网络的Lipshitz 常数尽量逼近1,进而使得判别器网络的训练更加稳定,其作用等价于网络正则化.由此看来,BN 与SN 之间并无冲突,其作用也不可相互替代.同时,无需顾虑SN 在网络中的位置,根据BN 和SN 的原理,加入Sigmoid 层的前一层是最合理的位置.一般情况下,DCGAN 中Sigmoid 层的前一层网络是压缩层,将上一层的结果压缩成N×1×1×1(N表示通道数),此时使用BN 并不能起到任何作用,但SN 不一样,仍然能够控制该层的Lipschitz 常数,并且此时的SN 仍能对模型产生正则化效果.从这个角度分析,SN 解决了BN 在Sigmoid 层的前一层网络中失效的问题.因此,将两者有机地融合到判别器中更有利于提升网络的判别能力.图3 所示为优化的DCGAN 网络结构.
初始化策略及超参数设置是GANs 网络结构的重要组成部分,这两项配置对网络结果有一定的影响.常用的GANs 网络权重初始化是高斯分布(N(0,0.02)或均匀分布(U(0,1))随机数.本文采用的初始化策略是判别器与生成器均使用正交初始化[25].这个初始化策略受到如下事实的启发:随机向量的正交变换的熵不变[19].需要特别强调的是,偏置项没有初始化,因为卷积层的后一层加入BN 层或SN 层之后,该卷积层的偏置项并没有发挥任何作用,所以一般将偏置项去除.除此之外,经过不断的实验,获得了如下最优超参:惩罚因子λ=1,批量数为64,梯度优化算法使用OAdam(optimistic Adam)算法[30],其参数设为β1=0.5,β2=0.9,判别器的学习率lr_D为0.000 1,生成器的学习率lr_G为0.000 4,隐空间分布是128 维的标准高斯分布,网络迭代率是2:1(即生成器每迭代1 次判别器需迭代2 次).接下来,通过实验来证实网络结构配置(包括超参数、初始化策略以及结构优化)的高效性以及惩罚模型的有效性.

Fig.3 The optimized network structure of DCGAN (the image size is 3 × 32 × 32)图3 优化的DCGAN 网络结构(图像尺寸为3 × 32 × 32)
3 实 验
为了验证EDGAN 算法的性能,本文在CIFAR10[31]、SVHN[32]、STL10[33]、CelebA[34]、LSUN[35]数据集上进行实验,其中,LSUN 数据集只用bedroom 子集,共3 033 042 张图片,同时与近年来的一些代表性算法作对比.所有实验都在Pytorch 框架下完成,且数据集STL10、CelebA 和LSUN(bedroom)的图像尺寸被统一剪裁为3 × 32 ×32.首先,在第3.1 节中简述模型的评价标准;之后,在第3.2 节中验证优化的网络结构性能;然后,在第3.3节中对惩罚模型的有效性进行验证;最后,第3.4 节是算法性能对比.
3.1 性能评价标准
目前在GANs 领域中,IS(inception score)得分[36]和FID(Frechet inception distance)值[37]是两个最经典的性能评价指标,几乎已成为该领域内通用的评价标准.IS 得分是利用在ImageNet 数据集上预训练的InceptionV3网络[38]对GANs 生成的样本构建一个得分统计量,其表达式如下:

FID 值实质上是两个假设的高斯分布之间的Wasserstein II 型距离[40].具体地,FID 值是利用inception V3 网络(其他CNN 网络也可行)分别将生成样本与真实样本嵌入到一个特征空间中,同时假设嵌入的样本服从高斯分布,并分别计算嵌入样本的均值μG、μd和协方差CG、Cd,则两个分布之间的FID 值为

由FID 值的定义(12)可知,只要满足高斯分布的假设,FID 值能够很好地度量GANs 模型的性能.根据中心极限定理[41],若样本容量趋于无穷大,则其极限分布服从高斯分布.于是,在实际中计算FID 时常常要求GANs 生成足够多的样本.由于FID 值是间接地度量生成分布与真实分布之间的距离,因此,FID 越小,模型的性能越好.相比IS 得分,FID 值更能全面地度量GANs 模型生成样本的质量(无论是多样性还是逼真度)[37],这个指标几乎已成为GANs 领域内统一的评价标准.本文所有的实验结果都仅以FID 值作为评价标准.在无特别说明的情况下,所有实验的FID 值都是分别从真实样本中抽取50 000 个样本,从生成样本中抽取50 000 个样本而计算得出.
3.2 优化的网络结构性能验证
为了验证两种优化策略的有效性,即:(1) 将判别器倒数第2 层的卷积层修改为谱标准化的卷积层(如图3(a)中倒数第2 层所示);(2) 删除生成器中的311 不变层,在DCGAN 网络结构上执行消融实验(ablation study).为便于表示,用SN_in_P(SN in Penultimate)和R311(Remove 311)分别表示第(1)种和第(2)种优化策略.为简化实验过程,这个消融实验仅在CIFAR 10 数据集上执行,生成器分别训练70k、100k、140k 和200k 次.然后,将这种优化策略拓展到其他4 个数据集上来验证其性能.CIFAR 10 数据集是由60 000 张32×32 的彩色图片构成,其中有50 000 张图片构成训练集,10 000 张图片构成验证集,本文用到的数据集是去标签后的训练集(50 000 张).
表1 是两种优化策略的消融实验结果.表1 的结果显示,SN_in_P 策略对DCGAN(表1 第2 行)的整体性能有所提升,但是提升幅度显著差于R311 策略,尤其是训练次数为140k 时,FID 值下降至26.27.可以看出,移除前(表1 中DCGAN)和移除后(表1 中R311)的结果形成了鲜明的对比.为了验证两种策略相结合的效果,我们分别实验当批量数为128(表1 中第5 行)和64(表1 中第6 行)时,网络的性能变化情况.可以看出,在4 种迭代次数下,两种优化策略相结合的网络性能均有不同程度的提升,FID 值均在下降.相比之下,当批量数为64 时,网络效果更好.表1 所示结果充分证实,本文所提出的两种优化策略是有效的,尤其是两种优化策略相结合的网络更是大幅度地提升了网络的性能.

Table 1 Testing the effectiveness of optimization strategy on network structure (FID)表1 网络结构优化策略的有效性验证(FID)
为了全面地验证两种优化策略的效果,我们分别在CIFAR10、SVHN、CelebA 等5 个数据集上训练两种策略相结合的网络.为便于表示,称这个优化的网络结构为OptimizedDCGAN.在这个实验中,将批量数设为64.表1的结果已经显示,批量数为64 比批量数为128 时的网络性能更好.为了验证这一事实,单独对批量数执行消融实验.图4 是DCGAN 分别在CIFAR 10 数据集上训练70k、100k、140k 和200k、批量数分别为64 和128 的结果.可以清晰地看出,批量数为64 的网络(蓝色)显著优于批量数为128 的网络(浅灰色).在无特别说明的情况下,后续所有实验的批量数均设为64.表2 是OptimizedDCGAN 在5 个数据集上分别训练70k、100k、140k 和200k次后的结果.

Fig.4 The effect of batchsize on network performance (CIFAR 10)图4 批量数对网络性能的影响(CIFAR 10)
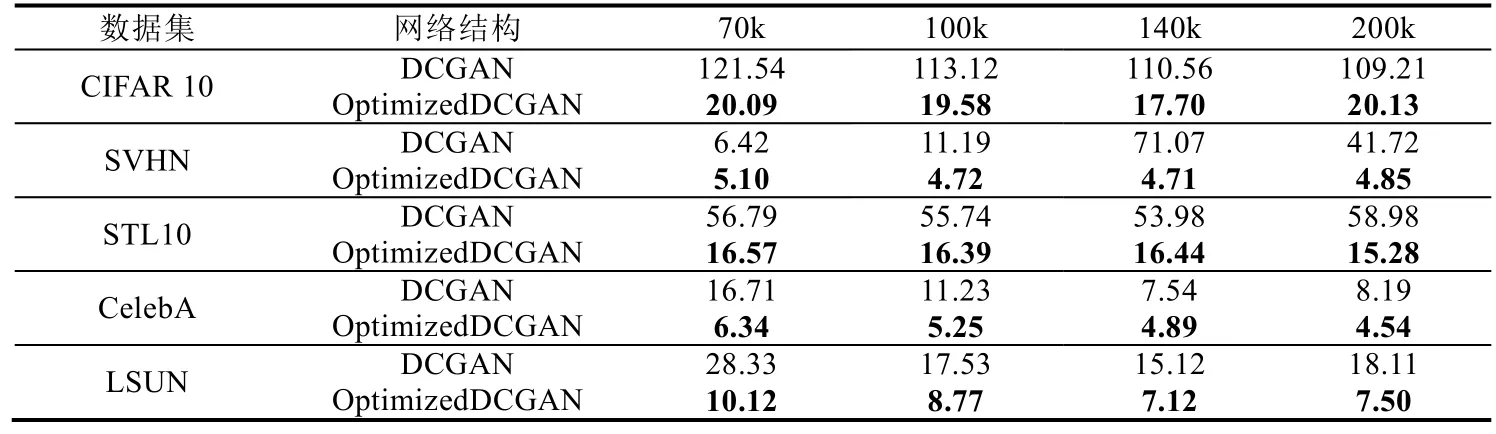
Table 2 The performance of the optimized DCGAN network structure (FID value)表2 优化的DCGAN 网络结构的性能(FID 值)
相比DCGAN 网络结构,优化的网络结构OptimizedDCGAN 的性能在5 个数据集上均有显著的提升.值得强调的是,在SVHN 数据集上,DCGAN 在4 种训练次数上的表现极不稳定,尤其是在训练次数为140k 时,FID 值忽然从11.19(100k)上升至71.07,200k 时又下降至41.72,而OptimizedDCGAN 网络结构表现较为稳定.表2 的结果再次验证了本文所提出的网络结构优化策略的有效性.
3.3 惩罚模型的有效性验证
本节验证由OptimizedDCGAN 网络结构与条件熵惩罚相结合的惩罚模型的有效性.首先,探究惩罚模型一些关键参数的最优配置,包括迭代率、学习率以及初始化策略等;其次,验证本文所提出的惩罚技术的有效性.
3.3.1 惩罚模型的参数配置及初始化策略
考虑到深度神经网络对网络参数配置的敏感性,我们通过一系列的消融实验来确定一些关键的超参数及其初始化策略.通过反复实验得到,惩罚模型的一些最优参数配置如下:惩罚因子λ=1,迭代率2:1(即生成器每更新一次判别器需更新两次),判别器学习率lr_D=0.0001,生成器学习率lr_G=0.0004,梯度优化算法使用OAdam(0.5,0.9),初始化策略:判别器和生成器均使用正交初始化.下面,我们利用消融策略逐一验证这些配置的有效性.为简化验证过程,所有消融实验仅在CIFAR 10 上执行,生成器均训练100k 次.
首先,确定最优的惩罚因子λ.在其他参数保持不变的前提下,观察λ=0.1,1,5,10,15,20时网络性能的变化情况,其结果显示在表3 中.可以看出,当λ=1 时,网络性能表现最佳,此时FID 值为14.02.其次,再观察网络学习率、迭代率、初始化策略、梯度优化算法对网络性能的影响,每个目标观察量均设置5 种变化,并统一表示为A、B、C、D、E.这些实验结果均总结在表4 中,其中每个目标观察量的5 种变化A~E的含义均置于FID 值的下方.由表4 的结果可知,当lr_D=0.0001、lr_G=0.0004 时,网络性能表现最佳.从学习率的实验结果还可以看出,这个参数对网络性能的影响较大;特别地,当lr_D>lr_G时(如表4 中B、D组合),网络性能较差,反之,则较好(如A、C、E组合).为此,我们单独执行实验9 种学习率组合以探究这个有趣的现象,结果如图5 所示.

Table 3 Different penalty factors and corresponding FID values on CIFAR 10表3 不同惩罚因子λ 所对应的FID 值(CIFRA 10)

Table 4 Implementing the ablation studies with respect to some hyper parameters and initialization (CIFAR 10)表4 一些超参数及初始化策略的消融实验(CIFRA 10)
在图5 中,蓝色的点(LR1-LR4)表示lr_D>lr_G的点,红色的点表示lr_D≤lr_G的点.可以清晰地看出,蓝色点的FID 值普遍高于红色的点,这说明上述现象是存在的.对于迭代率,选择2:1 较好.在初始化方法中,选用4 种初始化方法:正交初始化(Orth)[25]、Glorot 正态初始化(Glorot)[42]、高斯初始化N(0,0.02)以及Kaiming 正态初始化(KaiN)[43],5 种组合.
上面表4 的结果显示,当判别器和生成器均实施正交初始化时,网络性能最优.在梯度优化算法中,只选择两种优化算法(Adam,OAdam),不同参数下的5 种组合.已有研究表明,Adam 算法一般要优于其他优化算法[12,23,44],如SGD、RMSprop、Rprop 等算法.在惩罚模型中,选择OAdam(0.5,0.9)较优.

Fig.5 The effect on network performance with different learning rates图5 不同学习率对网络性能的影响
3.3.2 惩罚技术的有效性验证
为了充分体现本文所提出的惩罚技术的有效性,分别在CIFAR 10、SVHN、STL 10、CelebA 和LSUN 这5个数据集上执行如下实验:(1) 不带任何惩罚的网络(no-penalty);(2) 利用条件熵距离惩罚生成器的网络(EDGAN);(3) 利用Jensen-Shannon(JS)散度(对称版本的KL 散度)惩罚生成器的网络(with-JS-penalty);(4) 利用WGAN-GP[12]中的梯度惩罚技术惩罚判别器、条件熵距离惩罚生成器,即双惩罚网络(with-bi-penalty),其中,判别器惩罚因子沿用WGAN-GP 中的设置(惩罚因子为10,Lipschitz 常数为1).同样,所有生成器均训练100k 次,实验结果见表5.特别需要强调的是,表5 第2 列的结果(不带惩罚的网络)与表2 训练100k 次时的结果不一样,主要是由于两个网络使用的参数及初始化策略不一致,前者使用第3.3.1 节中的参数及初始化配置,而后者使用DCGAN 中的配置.首先,观察不带惩罚的网络(表5 第2 列)与带条件熵距离惩罚生成器的网络(表5 第3 列,本文提出的算法),5 个数据集所对应的FID 值均有不同程度的下降,网络性能获得提升.这充分说明,本文所提惩罚技术是有效的.其次,再观察带JS 惩罚的网络(表5 第4 列)以及双惩罚网络(表5 最后一列),5 个数据集上的FID值均大于第3 列的FID 值(EDGAN),这也充分证实,本文所提出的惩罚技术具有明显的优势.

Table 5 Verifying the penalty effect of EDGAN algorithm:The generator iterates 100k times (FID value)表5 验证EDGAN 算法的惩罚效果:生成器更新100k 次的FID 值
3.4 整体性能对比
上述一系列实验可验证得出,EDGAN 算法能够显著提高GANs 网络的性能.为了更进一步地验证EDGAN的优越性,现将该算法与近年来的一些代表性算法作比较.本文在5 个数据集上训练LSGAN(2017)、WGAN GP(2017)和SNGAN(2018)等5 种算法,其结果显示在表6 中.其中,表6 最后一列表示最优结果的生成器迭代次数,最后一行是真实数据的FID 值.从表6 所示结果可以看出,EDGAN 算法在多个数据集上都超越了目前的一些经典算法,只有在SVHN 和LSUN 数据集上稍逊于GAN-0GP和LSGAN 算法.与此同时,EDGAN 在CIFAR 10、STL 10 和CelebA 数据集上的FID 值更进一步地接近真实数据集的FID 值.表6 中加灰色的行是SAGAN 算法,这是一种经典的条件GANs 算法,而这里是将其标签信息从算法中删除,此时,SAGAN 算法就退化为无条件的GANs(即GANs).在此执行这个实验,意在说明是否可将条件GANs 的优良性能移植到无条件GANs 上?SAGAN在5 个数据集上的实验结果表明,答案是否定的.这也充分证实这样的一个事实:条件GANs 并不能当作无条件GANs 来使用.因此,开发高性能的无监督图像生成算法成为本文研究的出发点.
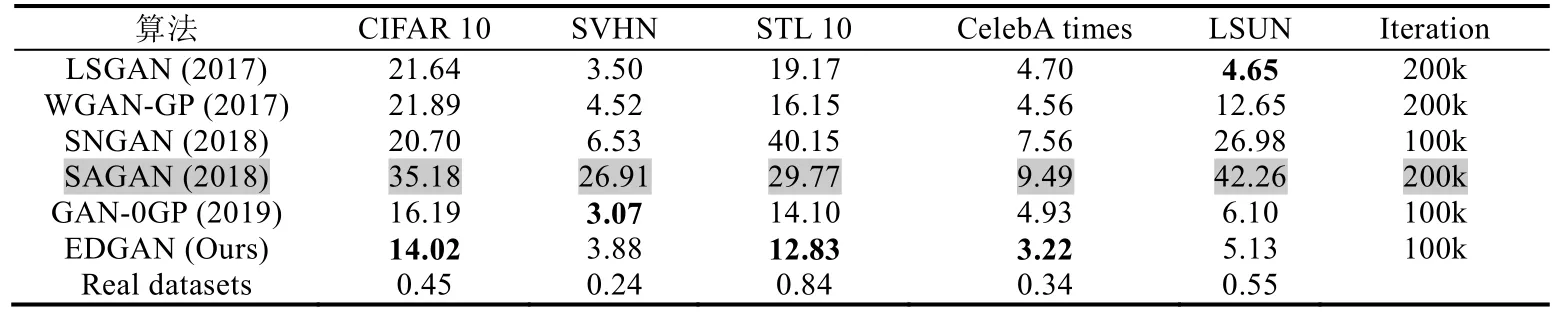
Table 6 Comparison of the algorithm performance表6 算法性能对比
4 结束语
本文利用条件熵距离对GANs 生成器的目标函数进行惩罚,其目的是在保持样本多样性的条件下迫使生成分布尽可能地接近真实分布,这使得GANs 生成的样本既有多样性又具有高逼真度,从而能够提高GANs 生成样本的整体质量.除此之外,本文在DCGAN 网络结构的基础上,对GANs 的网络结构进行优化,其中包括:(1) 根据批量标准化和谱标准化的互补特性,将两个标准化技术有机地融入到判别器网络中,以提高网络的判别能力;(2) 去除生成器网络中的311 尺度不变层,提升生成器的生成能力,同时也可缩小生成器网络的参数空间,以此提高网络的训练效率及性能;(3) 改变两个网络的初始化策略,判别器网络和生成器网络均使用正交初始化.最后,将惩罚的GANs 目标函数与优化的网络结构相结合,形成条件熵距离惩罚的GANs,即EDGAN.实验结果表明,EDGAN 算法已经超越了目前的一些经典GANs 算法.
虽然本文通过实验验证EDGAN 可以提高GANs 生成样本的质量,但其收敛性理论问题仍有待进一步加以研究.另外,如何利用EDGAN 生成的样本解决一些无监督问题,即EDGAN 的下游问题,仍有待深入研究.
猜你喜欢
小读者(2020年2期)2020-03-12 10:34:06
阅读(快乐英语高年级)(2019年11期)2019-09-10 07:22:44
小学生导刊(2018年34期)2018-12-18 01:53:14
趣味(语文)(2018年1期)2018-05-25 03:09:58
山东青年(2016年3期)2016-02-28 14:25:55
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27 06:31:53
管理现代化(2016年3期)2016-02-06 02:04:41
管理现代化(2016年3期)2016-02-06 02:04:13
智能系统学报(2015年4期)2015-12-27 09:37:52
学苑创造·A版(2015年6期)2015-07-01 09:00:12
