
学习绩效预测模型构建:源于?学习行为大数据分析
2021-05-19 06:15胡航杜爽梁佳柔康忠琳
中国远程教育 2021年4期
胡航 杜爽 梁佳柔 康忠琳
【摘要】
随着教育大数据分析技术的发展,学习预测研究已成为学习分析技术的一个重要研究方向,但通过不同场景学习行为日志数据进行学习预测研究较少。研究采集了823名大學生学习场景中在线学习日志数据和生活场景中一卡通消费和借阅图书日志数据,构建在线学习行为、早起行为、借阅行为和学习绩效预测指标,通过五种机器学习模型对学习绩效进行预测分析,结合提升(Boosting)和装袋(Bagging)两种方法提升预测模型的准确率,并与人工神经网络和深度神经网络模型进行预测性能对比。研究表明,多场景行为表现指标有较强的预测能力,深度神经网络模型预测准确率最高(82%)但耗时最多。同时,结合决策树与规则模型建立了分类规则集,构建了一种结合决策树和深度神经网络的学习行为诊断模型,该模型兼具高预测准确率、易读性高和易操作等特点,可实现多场景学习行为诊断,实现精准教学干预与学习资源推荐。
【关键词】 大学生;学习行为;多场景;学习绩效;预测模型;机器学习;决策树;神经网络
【中图分类号】 G40-057 【文献标识码】 A 【文章编号】 1009-458x(2021)4-0008-13
一、引言
随着教育大数据的广泛应用,学习预测研究已成为学习分析技术的一个重要研究方向。学习分析技术已从原理探究、应用价值等理论研究转向基于教育大数据的学习行为分析、数据可视化、学习预测等实际应用研究(胡航, 等, 2020)。学习预测研究主要依据之前和当前的学习活动特征对学习者未来的结果表现进行预估,如学习成绩、学习目标和学习能力等,通过不同形式的学习预测来改善学习成效和学习体验(AlShammari, Aldhafiri, & Al-Shammari, 2013; Nkhoma, Sriratanaviriyakul, Cong, & Lam, 2014)。学习结果预测集中在成绩预测理论模型构建、成绩预测模型实证研究、算法准确性对比、算法开发、预警因素研究和综述研究等方面,主要采用决策树、回归分析、神经网络、朴素贝叶斯、支持向量机等方法来预测学习绩效和学习效果(王改花, 等, 2019)。随着机器学习、情感分析、模式识别等智能技术的不断发展和成熟,特别是深度神经网络识别技术与教育领域的结合,为学习预测研究提供了有力的技术支撑,逐步应用于学生学习追踪、表现预测、教学辅助工具和行为分析等场景(陈德鑫, 等, 2019)。尽管学习预测研究有了一些初步成果,但以优化学习过程和改善学习成效为目标的学习预测研究还未在教育领域得到深入实践和应用,距离准确和大规模应用还较远(牟智佳, 等, 2017)。如何建立具有较高预测性能、兼具易读性和易操作性的学习预测方法,并依据预测结果进行差异化的干预与推荐应用,成为亟待解决的问题。本研究采用深度神经网络结合机器学习分析技术,运用多场景学习行为数据,构建学习行为诊断模型,以期为学习绩效预测分析和学习干预提供参考和指导。
二、研究基础与研究问题
(一)基于机器学习的预测研究
机器学习是一组使计算机能够在没有人为编程干预的情况下进行自我学习的新技术,在社会的各个行业得到广泛应用(Kannammal, 2015)。随着技术的不断成熟,机器学习中的监督学习在教育领域的应用也越来越广泛和深入。监督学习主要寻找能够从外部提供的实例中进行推理的算法,从而产生一般的假设,其目标是根据预测器的特征建立一个清晰的类标签分类模型(Kotsiantis, 2007)。监督学习在教育领域中的研究内容主要集中在成绩预测理论模型构建、成绩预测模型实证研究、算法准确性对比、算法开发、预警因素研究、综述研究等方面。黄等(Huang & Fang, 2013)基于多元线性回归(Multiple Linear Regressions,MLR)、多层感知网络(Multi-Layer Perceptron,MLP)、径向基函数网络(Radial Basis Function,RBF)和支持向量机(Support Vector Machine,SVM)四种类型的数学建模技术,结合六种预测变量组合开发了一个预测数学模型,发现支持向量机模型的平均准确率最高。塞勒姆等(Slim, Heileman, Kozlick, & Abdallah, 2014)以第一学期学生的基本信息(初始成绩、性别等)作为基线,分析了预测指标与平均绩点(GPA)的相关关系,利用贝叶斯信念网络(Bayesian Belief Network,BBN)预测了学生在学术生涯早期的表现,在第二学期加入其他行为表现指标后提高了模型的预测准确率。马布蒂等(Marbouti, Diefes-Dux, & Strobel, 2015)通过采集大一新生前九周的出勤率、测验和作业数据,利用逻辑回归(Logistic Regression,LR)模型对中期考试进行预测,并在后期的研究中通过SVM、朴素贝叶斯分类器(Naive Bayes,NB)、决策树(Decision Tree,DT)、多层感知机等各种监督学习中常用的分类预测器,以逻辑回归为基线模型进行准确率的比较(Marbouti, Diefes-Dux, & Madhavan, 2016)。胡塞等(Hussain, Zhu, Zhang, & Abidi, 2018)为了预测学生学习活动的参与程度,利用在虚拟网络环境中采集的学生行为数据,对五种监督学习算法进行了预测比较,发现基于J48决策树、JRIP和梯度增强分类器在准确率、Kappa值和召回率(Recall)方面表现出更好的性能。近年来,一些学者开始将多种机器学习分类器混合使用,结合朴素贝叶斯分类器的高准确率和J48分类器的效率,利用学生学习的基本信息和行为表现数据进行学习成绩的预测和学生表现的评估(Karthikeyan, Thangaraj, & Karthik, 2020)。这些研究不仅表现了不同学习行为数据对学习绩效和学习效果之间存在显著的相关性,还反映出行为表现指标良好的预测效果。
在预测准确率提升方法上,除了采用基于不同机器学习对预测效果进行筛选外,还可以采用集成算法AdaBoost模型对学生进行分类预测,提升分类器的预测准确率(Han, Tong, Chen, Liu, & Liu, 2017)。尚蒂尼等(Shanthini, Vinodhini, & Chandrasekaran, 2018)将REPTree作为元学习的决策树方法,基于Adaboost、Bagging、Dagging和Grading四种代表性分类器技术构建不同的决策树,发现Adaboost是基于学生测试成绩预测学生学习绩效的最佳元决策分类器,在测试集上的准确率从89.4%提升到97.6%。陈子健等(2017)采用Bagging和Boosting集成学习方法构建集成式学习成绩分类预测模型,能不同程度地提升贝叶斯网络(BN)、决策树(DT)和人工神经网络(ANN)三种算法的分类性能,真正率、精度和召回率的准确率从73%~75%提高到79.3%。因此,本研究在机器学习模型的选择和优化上,使用提升(Boosting)和装袋(Bagging)两种方法提升模型的准确率,改进模型的預测性能。
(二)基于神经网络的学习绩效预测研究
1. 神经网络的预测研究
人工神经网络(Artificial Neural Network,ANN)是模仿生物神经元对等物,由被称为神经元的处理单元相互连接而组成的一套机器学习方法(Adewale, Bamidele, & Lateef, 2018),神经网络的结构是分层的,神经元在连续的层中进行组装,每一层的输出被输入到连续的层中,在输入层、隐藏层和输出层上部署了非线性函数的组合。神经网络应用于社会的各个领域,在教育领域主要通过不同的神经网络算法组合实现学生学习效果预测和学习预警等。里库伦佐等(Lykourentzou, Giannoukos, Mpardis, Nikolopoulos, & Loumos, 2009)提出一种多前馈神经网络,将早期学生在电子学习课程中的测试成绩作为网络的输入数据集,动态预测学生十周后的最终成绩。牟智佳等(2017)选择决策树、朴素贝叶斯网络和BP神经网络三种预测分类算法,比较学习时长和学习次数预测学生在MOOC中辍学的准确率,发现BP神经网络预测准确率最优,达到99%以上。法友米等(Fayoumi & Hajjar, 2020)以学生的学术指标源作为输入数据集,开发了一套基于神经网络模型的决策支持系统,用于评估和预测学生学业表现,并将该模型与大数据和分析研究相结合,以实现高级可视化。
2. 深度神经网络的预测研究
深度神经网络方法被称为“表示学习方法”,由若干层非线性模块组成。该方法能够使系统足够熟练地学习复杂问题,从而使系统足够健壮,能够对复杂和微小的特殊情况产生敏感(Waheed, et al., 2020)。与统计学方法相比,深度神经网络促进了泛化,使其能够从数据中正确推断出隐藏的模式(Montavon, Samek, & Müller, 2018)。近年来,越来越多的学者将机器学习与神经网络进行结合。柯里根等(Corrigan & Smeaton, 2017)通过分析学生与虚拟学习环境的互动次数预测学生学习成绩,运用递归神经网络(RNN)的变异长短期记忆(LSTM),以随机森林为基准对结果进行评估,LSTM方差高达13.3%;依安达等(Iyanda, Ninan, Ajayi, & Anyabolu, 2018)利用前期单一学习成绩(表现因子)预测学生的后期学习成绩,发现广义回归神经网络(径向基函数神经网络的一种特殊形式)整体性能优于多层感知机模型(MLP)。
深度神经网络的搭建对研究者的技术要求较高,需要具备一定的程序开发经验。怀卡托智能分析环境Weka,不仅集合了大量能承担数据挖掘任务的机器学习算法,还能基于神经网络对图形、文本等非结构化数据进行分析,对学生的学习成绩进行分类预测(Meruelo, Jacobus, Idy, Nguyen-Louie, & Tapert, 2018)。Weka提供了深度神经网络组件WekaDeeplearning4j。它是一个基于Java语言的开源深度学习库,广泛支持各种深度学习算法的模型框架,为研究者通过图形用户界面应用深度学习技术提供了新的手段(Lang, Bravo-Marquez, Beckham, Hall, & Frank, 2019)。
通过文献分析发现,国内外学者采用机器学习在学习成绩、学习评价等方面做了大量研究,但现有研究基础还存在以下不足:一是学习分析场景较为单一,通常是基于某一具体学习情境的学习效果预测,较少将多样化的学习环境纳入研究范畴,其应用推广受到限制;二是预测数据来源的局限性,较少形成较为完整的学习活动数据链路,影响学习结果的准确率;三是预测方法受限于有限的数据类型和数据量,传统的统计学和机器学习方法较多,采用深度神经网络等深度学习技术进行学习绩效预测研究,特别是基于多场景、多模态数据源进行教育大数据挖掘的研究较少。
(三)研究问题
此前,研究团队通过行为指标的聚类和关联建立了早起和借阅行为与学习绩效的关系,并从元认知角度进行了分析和探讨(杜爽, 等, 2020)。在此基础上,本研究基于大学生网络课程学习过程、早起行为和图书借阅行为,将课内学习表现与课外学习行为数据联系在一起,建立多个学习场景的数据链路,通过对不同机器学习分类模型的预测分析和性能提升,结合深度神经网络技术对大学生学习绩效进行分类预测,主要聚焦以下问题:
①哪些预测指标对学习绩效有较好的预测能力?
②基于研究样本,哪些机器学习模型具有更好的预测性能和效能?
③结合不同预测模型的优势,如何建立用于教学干预与学习推荐系统的学习行为诊断模型?
三、研究设计
(一)数据来源及变量构建
1. 数据来源
以C市S高校2018级所有3,243名大学生作为数据采集对象,共采集到2018年9月至2019年8月23,948条日志数据和18,342条成绩数据。学习场景数据来源于在线课程学习数据,包括学校超星学习平台中的学习日志数据;生活场景数据包括图书借阅数据和早起数据,来源于图书馆业务日志和一卡通消费日志数据;学习绩效数据来自超星学习平台的在线测试成绩和学校教务系统中对应课程的期末笔试成绩两个方面。
日志数据记录了所有学生的活动,但这些数据存在不同程度的缺失和数据不平衡情况。对于数据缺失问题,如在一卡通借阅数据中有32.5%的学生在图书馆没有借阅记录,而剩下的学生中又有25.2%的学生仅借阅过1次,一卡通消费数据也有类似问题。数据缺失的原因主要是大学目前没有对借阅图书进行硬性要求,借阅图书是学生进行主动学习的一种行为表现;在一卡通消费数据中也并非所有学生都会在早上有消费行为。因此在数据预处理阶段,除了将重复、无效等记錄进行删除之外,还将缺少4个或更多变量值的学生记录进行删除,保证样本数据的完整性和有效性。
对于数据不平衡问题,如在学习绩效分布中有82.4%的学生学习绩效大于或等于80,仅有17.6%的学生小于80。对于这种偏态分布的数据采用分层抽样方法,对学习绩效大于或等于80的学生进行随机抽样(样本量减少),对学习绩效小于80的学生利用SMOTE方法进行重复抽样(样本量增加),抽样后样本中学习绩效的两种类别比例接近1∶1,确保样本数据的代表性和无偏性。通过对数据的多次校验和处理,最终抽取出823名学生的有效数据作为本研究的样本。
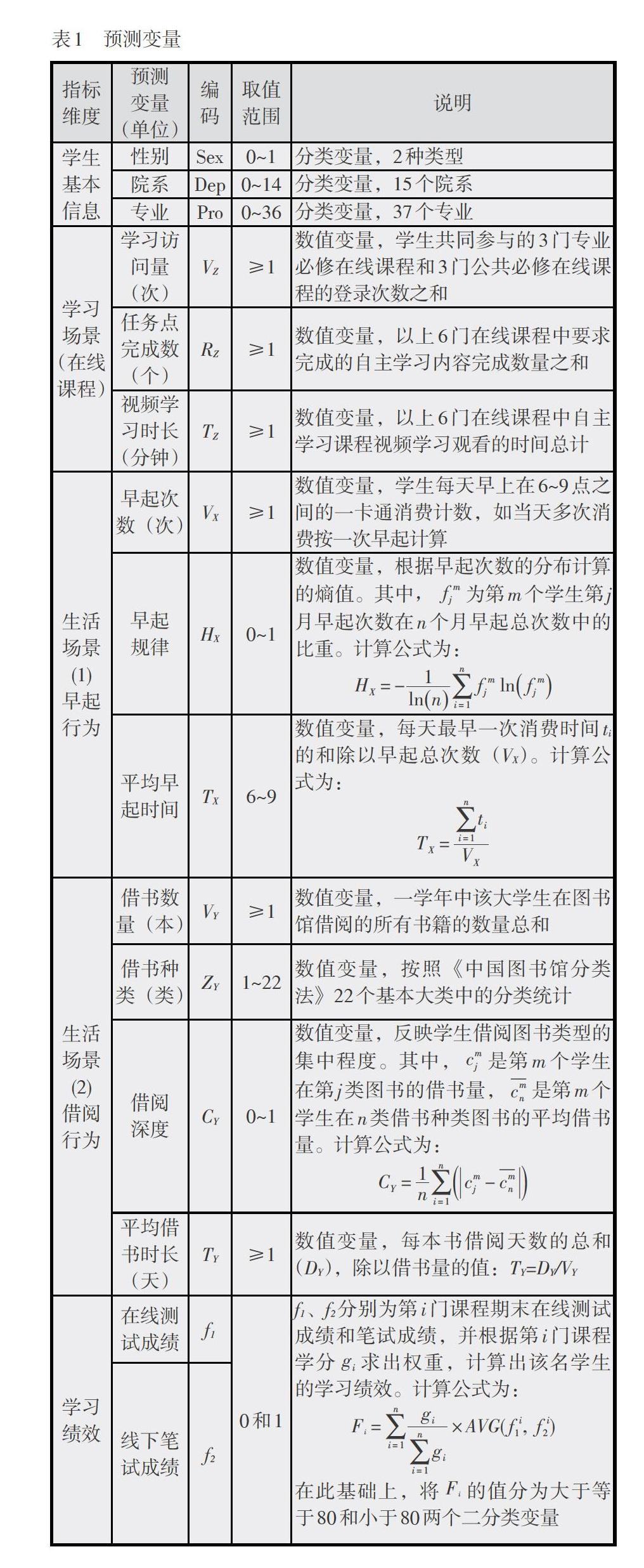
2. 预测变量的构建
在预测指标的选择和处理上,不同学者针对不同研究目的有不同的选取方式和处理方式,本研究采用倾向性指标和行为表现指标相结合的方式(范逸洲, 等, 2018)。倾向性指标也称“静态指标”,即在学习进行中不会改变的变量,如性别、民族等。具有某些倾向性指标(如良好初试成绩)的学习者能够在后期呈现出较好的学习状态(Mckay, Miller, & Tritz, 2012),初始自我调节的学习能力、学习驱动力也能很好地估计学习者能否获得较高的测试分数(Shum & Crick, 2012)。行为表现指标也称“动态指标”,即随着学习的进行会发生改变的变量,如行为次数、行为规律、行为的发生时长等。多数研究者在建立学习绩效和学习效果预测模型中均加入了行为表现指标(Huang, et al., 2013; Slim, et al., 2014; Hussain, et al., 2018; Karthikeyan, et al., 2020)。倾向性指标与行为表现指标相互影响,如果对学习早期或中期的学习效果进行预测,倾向性指标的预测能力较强(Whitener, 1989),而对学习中后期的学习绩效进行预测,倾向性指标的预测能力逐渐减弱而行为表现指标的预测能力随之增强,后期将成为核心预测指标 (Park & Tennyson, 1986)。
本研究将两类指标结合,倾向性指标包括学生的性别、院系、专业等基本信息,行为表现指标包括学习场景(在线课程)和生活场景(早起行为和借阅行为),预测结果为学习绩效变量。在研究早期采集两类指标所对应的预测变量值,而在后期数据处理阶段对其进行筛选。具体指标如表1所示。
(二)模型选择与评估指标
1. 预测模型选择
在预测模型选择上,主要聚焦在多场景学习过程中通过倾向性指标和行为表现指标预测大学生学习绩效是否大于、等于或小于80分,是一个典型的二分类问题。因此,采用机器学习中常用的二分类模型——决策树(J48)、RIPPER规则模型(JRip)、支持向量机(SVM)、贝叶斯网络(BayesNet)和逻辑回归(Logistic)分别比较不同模型对本研究样本的预测性能。预测模型分为两个阶段:一是进行监督学习,将已知的学习绩效等级作为类别标签用于模型对预测变量的训练,建立模型参数;二是使用测试数据将模型用于未知类别的判定,以评估模型的预测性能。
2. 预测模型的评估指标
对二分类模型的性能评估指标,一般统计预测正确与否的数量后计算评估指标。常用的统计参数包括:True Positive(真正,TP)被模型预测为正的正样本;True Negative(真负,TN)被模型预测为负的负样本;False Positive(假正,FP)被模型预测为正的负样本;False Negative(假负,FN)被模型预测为负的正样本。对模型预测效果最为直观的评估指标是准确率(Accuracy),反映了分类算法对整个样本的判定能力,但仅用准确率来判断模型的预测效果并不能客观反映出整个模型的预测能力,还需要通过查看模型Kappa值、召回率(Recall)、灵敏度、特异度等指标进行综合分析。本研究主要分析以下评估指标:
准确率 = (TP+FP)/(TP+FP+TN+FN);
灵敏度 = 真正率(TPR)= TP/(TP+FN);
特异度 = 1 - 假正率(FPR)= FP/(FP+TN);
召回率 = TP/(FP+FN)。
准确率反映整个模型判定正确的样本比例,体现模型对整个样本的判别能力;灵敏度也称“真正率”(TP Rate),反映正确判定的正例占总的正样本的比值;特异度也称“假正率”(FP Rate),反映错误判定为正例占总的负样本的比例;召回率反映了被分类算法正确判定的正例占总的正例的比例。
在此基础上,基于混淆矩阵构建灵敏度与特异度的关系图,即ROC(Receiver Operating Characteristic)曲线,分别在实际正样本和负样本中观察相关概率分布,通过计算曲线下面积AUC(Area Under Curve)评估模型的预测能力。
(三)研究方法与研究工具
1. 研究方法
预测方法为分析数据和生成模型参数提供有力的技术保障,本研究的分析过程如图1所示:①在数据清洗的基础上对预测变量进行相关性和信息增益率计算,筛选出与学习绩效关系最佳的预测变量;②使用十折交叉验证的方法对五个模型进行训练和测试;③在单一预测模型的基础上采用Bagging和Boosting方法集成分类器提升各模型预测效果,同时进行预测效果评估;④以人工神经网络(ANN)为基线模型,与使用DeepLearning4j深度神经网络的预测方法进行比较,计算AUC值来评估预测性能;⑤为了提供用于后期进行学习行为判断依据,对决策树进行可视化分析,结合JRip规则算法共同生成用于诊断学习行为的规则集;⑥结合前期各预测模型的优势,构建基于规则集的学习行为诊断模型,为建立教学干预与学习资源推荐系统提供可行依据。
2. 研究工具
常见的学习预测工具有Weka、SPSS、SQL Sever 2008 Data Mining、SSAS等,或者几种工具交替使用共同完成数据分析和预测评估。本研究基于PC平台Intel Corei5-9300H和Windows版本1909,为了让WekaDeeplearning4j更好地发挥性能,安装了支持GPU CUDA 10.2的安装包。分析工具使用Weka3.8和Clementine12,利用两者的优势达到最佳研究效果。在数据预处理、分类预测、集成分类器和深度学习分析阶段,采用Weka分析工具;在决策树可视化和规则集生成阶段,采用Clementine分析工具。
四、数据分析结果
(一)预测变量的筛选
1. 相关性分析与排序
对所有预测变量进行相关性分析,计算各变量与学习绩效F之间的皮尔逊相关系数,可衡量变量之间的线性相关关系。同时,计算变量之间的方差膨胀因子(VIF),检测他们之间是否存在高度共线性。若相关系数小于0.1或VIF大于10,则表明该变量对学习绩效的预测效果不佳,应考虑删除。从表2可以发现,在13个预测变量中ZY和Pro的相关系数小于0.1,并且ZY和VY的VIF数值远高于其他变量,因此将ZY变量删除,其他变量保持不变。删除ZY后重新进行计算发现,VY的VIF降至1.917,符合共线性要求。
2. 信息增益率分析与排序
计算所有预测变量与学习绩效F之间的信息增益率。信息增益率能有效反映预测信息量的大小,它是通过计算变量的熵度量(属性熵和类别条件熵的比值)来评估最佳预测变量对学习绩效的信息携带量,是一种有效地从样本中选择属性的方法(Karthikeyan, et al., 2020)。研究采用Weka中InfoGain属性评估器,同时采用Ranker进行降序排序(如表3所示)。从表3可以看出,Dep、Sex、Pro和ZY四个变量的信息增益率最低,小于或接近0.1。因此,结合相关性分析结果,删除ZY、Dep、Sex和Pro四个变量。从中可以发现,虽然相关性和信息增益率排序顺序有所不同,但最终保留的9个变量数是一致的。
(二)分类预测模型效果分析
采用十折交叉验证法对各个分类模型进行训练和测试。交叉验证法先将数据集分成十份,然后轮流将其中的九份作为训练数据,剩下的一份作为测试数据,最后通过将每次正确率的平均值作为算法精度的评估值,这样可以最大化利用样本进行模型训练(Wong & Yeh, 2020)。经过各模型的参数调优,得到各模型的预测结果(如表4所示),各模型的Kappa值在0.357~0.573之间,Kappa值在0.21~0.40属于一般一致性(fair),在0.41~0.60属于中等一致性(moderate)(Viera & Garrett, 2005),说明各模型分类结果一致性和信度基本达到要求。
从预测结果分析看,真正率最高且假正率最低的是J48,准确率达到0.724,其次是JRip和SVM,最低的是BayesNet和Logistic模型,准确率仅有0.685。召回率、ROC面积与模型真正率基本成正比,模型的耗时在0.01~0.03秒之间,构建速度很快。其中,与BayesNet准确率一致的Logistic(0.685),假正率却低于前者(0.333<0.345),假正率越低说明模型的错误越少,表明Logistic模型的预测能力优于BayesNet。
(三)采用Boosting和Bagging集成方法提升分类器预测效果
两种集成方法都使用特殊算法将分类器的分类结果进行组合来判断预测类别,但使用不同的分类策略。提升(Boosting)为每一个训练样本赋一个权重,在每一轮提升过程结束时自动调整权重。装袋(Bagging)是将原数据集进行有放回的抽样,构建出大小和原数据集一样的新数据集,再对所有基分类器的预测值進行多数表决(陈子健, 等, 2017)。因此,两种方法对不同分类器的预测效果和预测性能的提高是不一样的(如图2所示)。
从图2可以发现,各预测模型通过两种集成分类器在真正率、准确率和召回率上均有不同程度的提高,假正率都有所降低。比较两种集成方法,除了JRip模型之外,其余预测模型使用装袋(Bagging)比使用提升(Boosting)无论是在真正率、准确率和召回率上都有所提高,其中增幅最大的是逻辑回归模型,准确率从0.685提高到了0.719,增幅最小的是贝叶斯网络,增幅不到0.01。JRip模型在使用提升集成方法而并非在装袋集成方法取得最好的预测性能,这可能与JRip算法本身的运行机制有关,但准确率已从0.717提高到0.741,与准确率最高的J48(0.744)效果相当;J48在采用装袋集成方法后的假正率下降到所有模型中最低的0.259,预测性能进一步得到优化。
(四)人工神经网络与深度神经网络预测效果分析
Weka中的人工神经网络分类器是MultilayerPerceptron,运行之前需要构建网络结构,设置激活函数、损失函数、隐藏层数和学习率。深度学习分类器在Weka中采用Dl4jMlpClassifier,除了与神经网络相似的基本设置之外,还需要设置网络类型、监听器类型、Epoch个数等参数,然后将之前的9个预测变量作为模型输入加载到两个神经网络中运行,同样采用十折交叉验证法对分类模型进行训练和测试,关键参数设置和预测结果如表5所示。
从表5可以看到,相较之前五个机器学习模型,两个神经网络模型的真正率、准确率、召回率、ROC面积等预测指标均有较大幅度的提升,Kappa值分别为0.674和0.715,模型分类结果的一致性达到了高度一致(substantial,0.61~0.80)等级,模型准确率分别达到了0.796和0.820,同时假正率也降低到0.206和0.179。之后还进行了不同方案的模型参数调试,如设置不同的隐藏层数和修改学习率、Epoch数等,最终经过多次尝试和运行,基于本研究的数据集深度神经网络的预测效果整体上高于人工神经网络。但两种神经网络模型运行十折交叉验证的时间较长,模型耗时比其他机器学习模型多出较多。
为了比较各个模型的预测性能,计算出五个机器学习模型和两个神经网络模型的ROC面积AUC, AUC的值在0.5到1之间,越接近1预测性能越好。图3是五种机器学习预测模型在采用提升或装袋集成分类器后的最优AUC值。一般认为AUC值为0.6~0.75时区分能力一般,大于0.75时区分能力较好。可以看到基于本研究数据预测性能最优的是J48决策树模型,AUC=0.818表示模型的预测能力较好,其余模型的AUC值分布在0.736至0.791之间,模型性能尚可接受。对比两个神经网络预测模型(如图4所示)可以发现,两者均高于前五种机器学习预测模型0.039~0.168,且深度神经网络的AUC值已达到了0.904,说明该模型的预测性能很好。
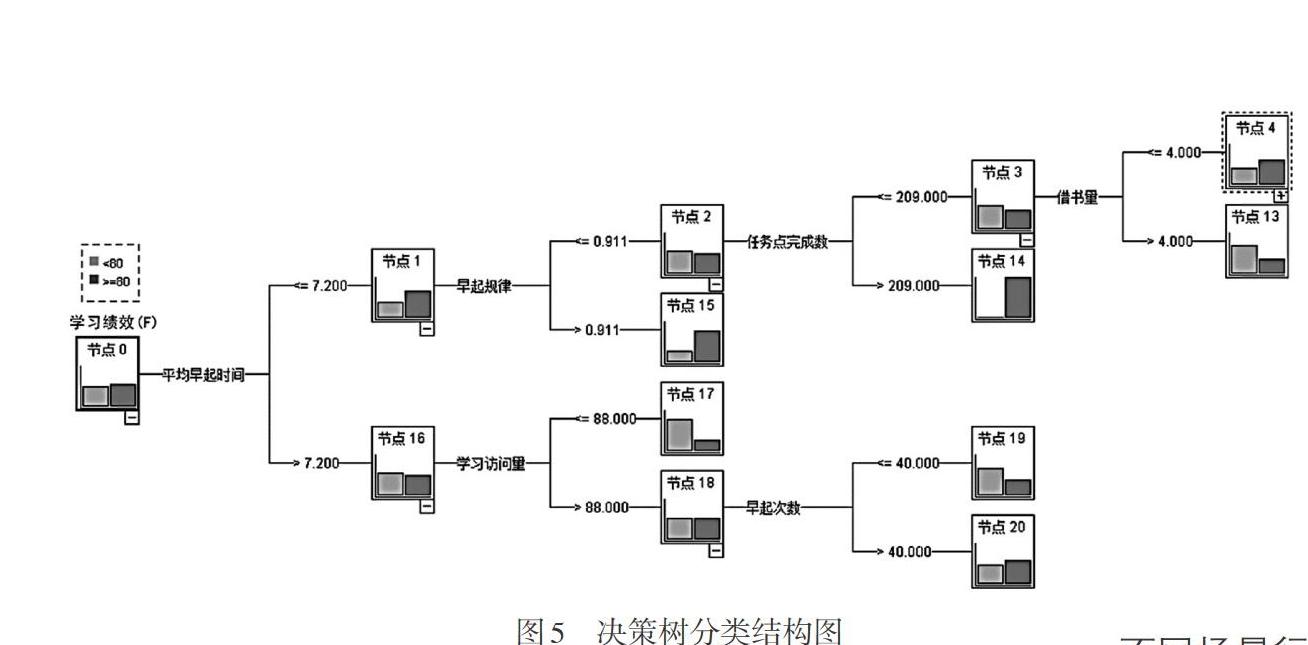
(五)决策树可视化分析
深度神经网络预测模型虽然可以得到较高的准确率,但无法直观解释各预测指标与学习绩效之间的关系,特别是变量的预测重要性等特征,需要进一步深入分析,因此采用较为直观、利于理解并基于本研究数据预测准确率较高的决策树模型进行可视化构图。采用Clementine中决策树生成器生成树状结构图,共生成21个节点,因节点5至节点13的分裂条件与父节点重复,且这8个节点只覆盖50名学生,所以将这8个节点进行折叠,折叠后的13个节点可以解释823名学生中773名学生的变量分布(如图5所示)。
根据决策分类图中的路径分析,可以较为直观地分析学生的学习绩效等级关系,例如通过节点0、1、15这条路径可以得出:如果平均早起时间早于7.200(7:12AM)并且早起规律大于0.911(好于91.1%的学生),那么模型可以预测他的学习绩效达到“≥80”这个等级。
从决策树分类结构图中可以发现,对学习绩效预测影响最大的是平均早起时间,其次是早起规律、学习访问量、任务点完成数、早起次数及借书量,而视频学习时长、借阅深度和平均借书时长三个变量没有出现在决策树结构图中。在Clementine中决策树生成器算法为C5.0,它选择具有最高信息增益的变量作为节点的分裂条件,因此可以看到分裂顺序与表2中预测变量的排序顺序基本一致。三个没有出现的变量主要原因是在决策树生产完后进行了剪枝(Pruning),剪枝方法可以处理模型对数据的过拟合问题,通常剪枝方法使用统计度量,剪去最不可靠的分枝,起到精简模型的作用。
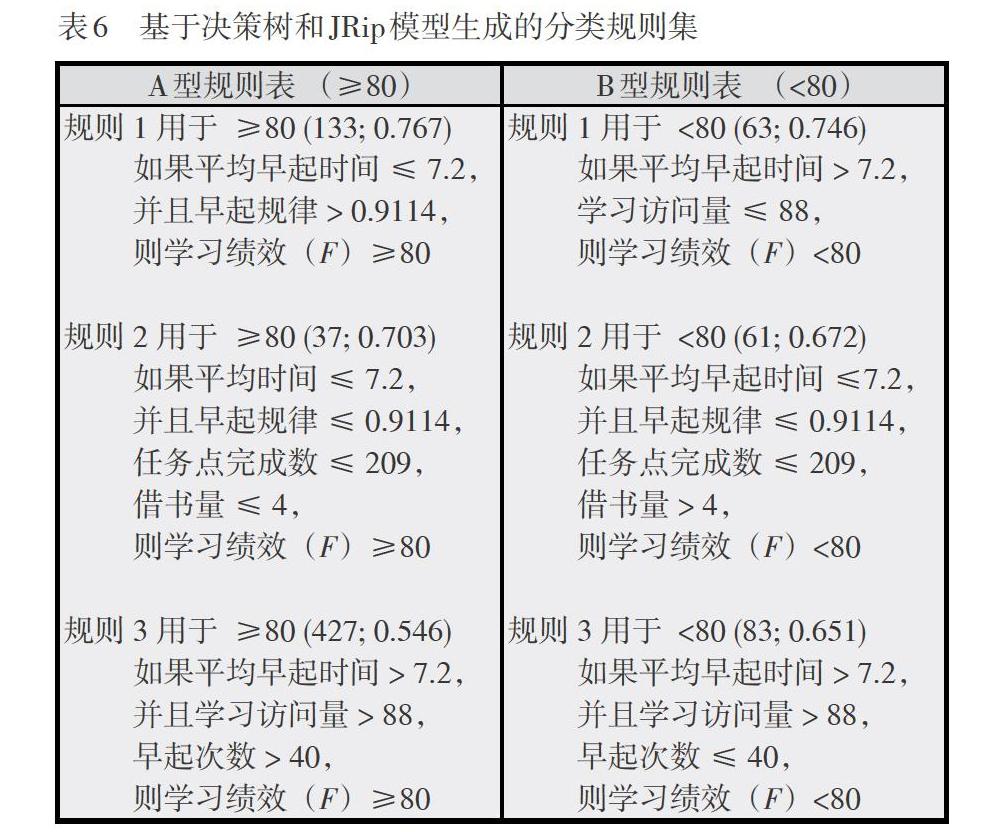
(六)基于决策树和JRip算法生成分类规则
为了增强决策树分类结构的易读性,利用JRip模型产生的规则与决策树结果共同生成规则集。JRip是RIPPER规则算法的简称,采用贪婪算法构造规则集,采用错误率降低剪枝REP(Reduced Error Pruning)技术,相较于决策树有更好的剪枝和停止准则,可以进一步简化和优化规则集。生成的规则集按照学习绩效“≥80”A型和“<80”B型进行分类,并根据该规则所能分类的比例进行排序(如B类规则1中“63;0.746”表示该规则可对63人中的74.6%也就是47人进行分类),比例越高说明规则的信度越高。选取每一类型比例最高的前三条规则,最终生成用于学习行为诊断模型的规则集(如表6所示)。
从表6规则集中可以发现,在生活场景中早起行为的平均早起时间是所有规则中的第一条,而且早起规律也是较为重要的规则,其次是学习场景中的网络学习中学习访问量和任务点完成数,而同样是生活场景的借阅行为中的借书数量却只出现了两次。基于本研究样本数据,可以将三个场景的学习行为对学习绩效的预测重要性排序:早起行为 > 网络学习 > 借阅行为。
五、研究讨论与总结
(一)行为表现指标有较强的预测能力
从预测指标的分析中,倾向性指标在相关分析和信息增益率比较排序后被全部删除掉,排名靠前的均为行为表现指标,说明倾向性指标和行为表现指标对于学习绩效的预测能力存在较大差异。这与早期的一些预测研究结果是相符的(斯伯克特, 等, 2012; Park, et al., 1986),学习活动开展初期倾向性指标的预测能力较强,而随着学习活动的开展行为表现指标逐渐替代倾向性指标,成为预测学习绩效的主要參数。学生的基本属性随着时间的推移,对学生自身的发展而言,在校园学习场景和生活场景中发生的学习行为对学习绩效的影响也随之增加。
不同场景行为表现指标的预测能力在模型预测中是不一样的,而不同的生活场景对学习绩效的预测能力也存在差别。主要原因在于:一是学习场景中的在线学习数据仅能反映学生真实学习活动中的部分表现,通过在线学习日志分析对基于MOOC等远程在线教学活动的预测能力较强,而对于混合式学习、翻转课堂等需要结合线下课程共同实施的活动,对学生最终学习绩效的预测能力可能是有限的(Hellas, et al.,2018);二是在生活场景中由于早起与借阅数据量的差异影响了预测能力,该预测数据中早起行为几乎包括所有学生每天早上的一卡通消费日志,数据采集量较大,而图书馆借阅日志的生成需要学生主动进行借阅图书行为后才能产生,有些学生一学期或一学年的借阅量都较少,也就是这两种行为数据的密度分布存在差异,对学生行为表现的度量显然是不一样的,从而影响了学习绩效的预测效果。
(二)机器学习模型预测性能分析
将多种机器学习分类器混合使用,可以兼具各分类器的性能和效率优势,综合和集成多类预测模型能显著提升预测能力。本研究采用的五种机器学习模型通过两种集成方法后预测准确率平均提升1.01~3.4个百分点,提升后的预测准确率在69.3%~74.4%,与其他学者82%~89%(Huang, et al., 2013)、60%~63%(Hamoud, Hashim, & Awadh, 2018)、82%~88%(Hussain, et al., 2018)和60%~73%(武法提, 等, 2019)采用不同工具进行学习绩效预测的准确率基本一致。这些模型在预测指标和预测方法的选择上都与具体应用场景和数据样本有关。这说明数据样本的差异性使得同一预测方法在不同样本中的预测效果存在差异,而同一数据样本采用不同的预测方法也会得到不同的预测结果。因此,在选择预测方法时需要根据具体的数据样本类型和分布等情况,基于预测目标的要求采用有针对性的预测算法,才能实现较为可靠和可信的预测结果。
(三)深度神经预测性能和效能分析
从人工神经网络与深度神经网络的预测效果来看,仅采用Weka中基本分类器构建预测模型,在没有采用提升与装袋集成分类器的情况下就达到了较高的预测准确度(0.796,0.82)。其他学者采用神经网络进行预测的准确率在65%以上(孙发勤, 等, 2019; Corrigan, et al., 2017)。深度神经网络的预测准确率均高于人工神经网络,且在Kappa值、召回率等指标上均较好。因此,深度神经网络预测模型可用于对学生学习行为的精准预测,相较于其他机器学习预测模型,其优异的预测性能可用于学习行为诊断和学习干预方式的界定。
但深度神经网络预测模型也存在耗时较多的问题。从图6可以看到,在机器学习模型中各初始预测模型的耗时一般只需0.01~0.03秒,采用了提升和装袋集成分类器后模型的耗时开始大幅度增加,但耗时区间基本在0.08~0.44秒之间,小于0.5秒。而采用神经网络分类器的两个模型耗时在5.66~7.78秒之间,与基本的机器学习模型耗时相比多了10~15倍。从人工神经网络与深度神经网络模型的效能上比较(如图7所示),预测准确率仅提高了2.4个百分点,耗时就增加了2.12秒,这从预测的代价来说是较大的。不过随着计算机性能的不断提升,特别是基于并行计算的GPU价格下放,无论是机器学习还是神经网络算法在GPU上的计算速度将得到很大改善,计算效能也有极大提升,这为基于深度神经网络的智能化预测应用提供了极大的技术保障。
(四)构建学习行为诊断模型
虽然基于神经网络算法的预测结果好于其他分类器,但对于希望挖掘学习动机和学习发生的内在机理,目前深度神经网絡算法对于学习技术研究来说还是一个黑盒算法,尚不能提供一个具体的用于学习效果诊断的评判依据。深度神经网络模型能得到一个比较理想的预测结果,但预测的可操作性还不够具体。因此,本研究提出一种结合决策树规则集和深度神经网络的学习行为诊断模型,相比单一诊断模型,该模型不仅具有深度神经网络模型的预测精度,而且兼具决策树和规则算法的易读性和可操作性,提升整体模型的泛化能力(如图8所示)。
从图8可以看到,该模型分为知识推理引擎、知识解释引擎和知识应用引擎三个部分。在知识推理阶段,主要是从学生基础信息库和学习事件数据库中采集模型需要的训练集,用于不同预测模型的参数建立,通过深度神经网络建立准确率较高的预测模型,用于判断行为数据的预测结果。同时,采用基于决策树和规则算法的机器学习预测模型生成用于预测诊断的规则集,通过测试集验证其预测效果。在知识解释引擎中,根据预测结果和预测规则建立学习行为诊断模型,通过关键词AND(并且)、OR(或者)或者不同规则表达式的混合使用,当新的验证集数据进行诊断并形成预测结果时,解释引擎具有的IF(条件)THEN(应用)结构将触发诊断规则,继而根据诊断分类(A型或B型)执行特定的应用。知识应用引擎根据特定类型提供相应的推荐和干预模型,对于学习绩效较好的A型依据资源推荐策略,提供更具个性化的学习资源推荐;对于学习绩效一般的B型依据诊断模型中规则集分析学习行为的欠缺之处,提供有针对性的学习行为干预策略,并对干预后的学习行为进行检测和评估,通过对学习绩效的测试和评价检测推荐和干预模型的实施效果,同时将后期活动的数据经过预处理后存入学习事件数据库中,为进一步更新和优化预测模型提供数据保障。
(五)学习绩效预测机制与教育价值
学习绩效预测的目的不仅是计算出较高准确率的分类结果,更重要的是利用预测结果为学习者提供服务,促使学习者优化学习路径,改善学习成效(Thomas, 2016),从预测机制和教育价值上分析:
一是在不同场景数据的模型预测上,局限在一个具体场景中的学习绩效预测难以将预测结果泛化到整个学习环境中去,而基于多场景数据的预测模型能比较全面地反映学习绩效与场景中不同学习行为之间的重要性,不仅对预测的准确率和预测效果都有较大的提升,而且预测诊断后可以基于规则为学生提供在不同学习场景的改善意见。如一名学生经过深度神经网络模型诊断为A类型后,发现符合A类规则2,说明该学生有较好的学习能动性,但生活规律一般,因此可以在生活场景中鼓励学生定制学习规划表、推荐与学科专业相关的图书,在学习场景中推荐相关网络课程、提供数字化学习资源等手段,为学生提升学习效率、改进学习方法、提升学习效果提供帮助和指导(胡航, 等, 2020)。随着智能影像分析和情感识别等技术的日益完善,未来可以获取学习者更多场景的数据,如在课程学习过程中内在心理状态变化数据等,将学习表情、学习情感、学习注意力,从心理学视角分析学习行为和状态,探测影响学习结果的影响因素(牟智佳, 等, 2017),从而提高学习预测准确率。
二是在学习行为的干预上,根据被预测的等级进行对应级别的干预措施。如预测为学习较差类的学生进行级别较大的干预(Perelmutter, McGregor, & Gordon, 2017),然而由于预测等级的具体原因不清晰,常以一类学生为单位进行集体干预。通过本研究提供的学习行为诊断模型,可以反过来从判断规则中找到每个学生学习行为中的问题和薄弱点,避免以群体为单位的粗粒度干预方式,从而为每个学生提供有针对性的干预措施,使个性化的“精准干预”成为可能(胡航, 等, 2019)。如一名学生经过模型诊断为B类型后,发现平均早起时间晚于7.2,并且网络课程学习访问量低于88次,符合B类型的规则1,因此教师可以针对该学生的具体情况采取鼓励早起学习、增加网络课程学习时间等干预措施,从而激发和调动学生的学习意识和学习积极性,同时也为教育政策制定、教学资源规划和教学方法实施提供决策支撑。
三是在教育决策上,大数据分析与预测技术的发展为教育决策的制定提供了新的契机,同时也带来了新的挑战。本研究采集的数据由于部分属性值的缺失(稀疏性)和不平衡(异质性),需要高维度的数据特征度量和抽样方法,增加了数据处理的难度,降低了数据的使用率(从3,243名学生中抽取出823名),也影响了研究样本对总体的解释程度。因此,基于大数据分析的教育决策发展也面临一系列亟待解决的问题。但随着基于大数据智能技术的发展,特别是面向异构大数据的新一代统计推断体系以及适用于噪声数据挖掘方法和预测方法的不断完善,将为学校教育管理者和教师分析教育现象和结果之间的联系提供更加可靠的数据基础,从而增加教育决策的成功率,降低教育决策风险和成本。
六、结语
本文采用学生学习场景和生活场景中的学习行为日志数据,通过五种机器学习模型和两种神经网络模型对学习绩效进行预测,分析和比较预测结果和预测效能,结合深度神经网络模型的高预测准确率和决策树与规则模型的易读性和易操作性,构建了基于规则集的学习行为诊断模型。在研究还存在一些局限性,限于数据的缺失和不平衡,研究样本还未能全覆盖;三个场景中的学习行为数据预测学习绩效还未能涵盖大学学习场景中对学习绩效影响的其他因素。在后期研究中,将在更多学习场景中整合不同学习类型和学习行为数据,针对每个学习场景自身的特点和性质采取不同的智能化学习分析技术,为学习者和教育工作者提供更加精准的预测与干预服务,形成教学实验、教学研究、教学实践的教育大数据研究与实践的教科研发展闭环。
[参考文献]
陈德鑫,占袁圆,杨兵. 2019. 深度学习技术在教育大数据挖掘领域的应用分析[J]. 电化教育研究(2):68-76.
陈子健,朱晓亮. 2017. 基于教育数据挖掘的在线学习者学业成绩预测建模研究[J]. 中国电化教育(12):75-81,89.
杜爽,飞云倩,何牧,胡航. 2020. 大学生“早起”和“借阅”行为与学习绩效的关系研究[J]. 中國远程教育(11):47-58,77.
范逸洲,汪琼. 2018. 学业成就与学业风险的预测——基于学习分析领域中预测指标的文献综述[J]. 中国远程教育(1):5-15,44,79.
胡航,李雅馨,曹一凡,赵秋华,郎启娥. 2019. 脑机交互促进学习有效发生的路径及实验研究——基于在线学习系统中的注意力干预分析[J]. 远程教育杂志(4):54-63.
胡航,李雅馨,郎启娥,杨海茹,赵秋华,曹一凡. 2020. 深度学习的发生过程、设计模型与机理阐释[J]. 中国远程教育(1):54-61,77.
牟智佳,武法提. 2017. MOOC学习结果预测指标探索与学习群体特征分析[J]. 现代远程教育研究(3):58-66,93.
牟智佳,武法提. 2017. 教育大数据背景下学习结果预测研究的内容解析与设计取向[J]. 中国电化教育(7):26-32.
斯伯克特,任友群. 2012. 教育传播与技术研究手册[M]. 上海:华东师范大学出版社.
孙发勤,冯锐. 2019. 基于学习分析的在线学业成就影响因素研究[J]. 中国电化教育(3):48-54.
王改花,傅钢善. 2019. 网络学习行为与成绩的预测及学习干预模型的设计[J]. 中国远程教育(2):39-48.
武法提,田浩. 2019. 挖掘有意义学习行为特征:学习结果预测框架[J]. 开放教育研究(6):75-82.
AlShammari, I. A., Aldhafiri, M. D., & Al-Shammari, Z. (2013). A Meta-Analysis of Educational Data Mining on Improvements in Learning Outcomes. College Student Journal, 47(2), 326-333.
Adewale, A. M., Bamidele, A. O., & Lateef, U. O. (2018). Predictive modelling and analysis of academic performance of secondary school students: Artificial Neural Network approach. International Journal of Science and Technology Education Research, 9(1), 1-8.
Corrigan, O., & Smeaton, A. F. (2017). A course agnostic approach to predicting student success from VLE log data using recurrent neural networks. In European Conference on Technology Enhanced Learning (pp. 545-548).
Fayoumi, A. G. , & Hajjar, A. F. (2020). Advanced learning analytics in academic education: academic performance forecasting based on an artificial neural network. International Journal on Semantic Web and Information Systems (IJSWIS), 16.
Hamoud, A. K., Hashim, A. S., & Awadh, W. A. (2018). Predicting Student Performance in Higher Education Institutions Using Decision Tree Analysis. International Journal of Interactive Multimedia and Artificial Intelligence, 5(2), 26-31.
Han, M., Tong, M., Chen, M., Liu, J., & Liu, C. (2017). Application of Ensemble Algorithm in Students Performance Prediction. In 2017 6th IIAI International Congress on Advanced Applied Informatics (IIAI-AAI), 735-740.
Hellas, A., Ihantola, P., Petersen, A., Ajanovski, V. V., Gutica, M., Hynninen, T., … & Liao, S. N. (2018). Predicting academic performance: a systematic literature review. 23rd Annual Conference on Innovation and Technology in Computer Science Education (ITiCSE 2018), 175-199.
Huang, S, & Fang, N. (2013). Predicting student academic performance in an engineering dynamics course: A comparison of four types of predictive mathematical models. Computers in Education, 61(1), 133-145.
Hussain, M., Zhu, W., Zhang, W., & Abidi, S. M. R. (2018). Student Engagement Predictions in an e-Learning System and Their Impact on Student Course Assessment Scores. Computational Intelligence and Neuroscience, 2018, 6347186.
Iyanda, A. R., Ninan, O. D., Ajayi, A. O., & Anyabolu, O. G. (2018). Predicting Student Academic Performance in Computer Science Courses: A Comparison of Neural Network Models. International Journal of Modern Education and Computer Science, 10(6), 1-9.
Navamani, J. M. A., & Kannammal, A. (2015). Predicting Performance of Schools by Applying Data Mining Techniques on Public Examination Results. Research Journal of Applied Sciences, Engineering and Technology, 9(4), 262-271.
Karthikeyan, V. G., Thangaraj, P., & Karthik, S. (2020). Towards developing hybrid educational data mining model (HEDM) for efficient and accurate student performance evaluation. Soft Computing, 1-11.
Kotsiantis, S. B. (2007). Supervised Machine Learning: A Review of Classification Techniques. Informatica (Lithuanian Academy of Sciences), 31(3), 249-268.
Lang, S., Bravo-Marquez, F., Beckham, C. J., Hall, M. A., & Frank, E. (2019). WekaDeeplearning4j: A deep learning package for weka based on Deeplearning4j. Knowledge Based Systems, 178, 48-50.
Lykourentzou, I., Giannoukos, I., Mpardis, G., Nikolopoulos, V., & Loumos, V. (2009). Early and dynamic student achievement prediction in e-learning courses using neural networks. Journal of the Association for Information Science and Technology, 60(2), 372-380.
Marbouti, F., Diefes-Dux, H. A., & Strobel, J. (2015). Building Course-Specific Regression-based Models to Identify At-risk Students. 2015 ASEE Annual Conference & Exposition.
Marbouti, F., Diefes-Dux, H. A., & Madhavan, K. (2016). Models for early prediction of at-risk students in a course using standards-based grading. Computers in Education, 103, 1-15.
McKay, T., Miller, K., & Tritz, J. (2012). What to do with actionable intelligence: E 2 Coach as an intervention engine. In Proceedings of the 2nd International Conference on Learning Analytics and Knowledge (pp. 88-91).
Meruelo, A. D. , Jacobus, J. , Idy, E. , Nguyen-Louie, T. , & Tapert, S. F. (2018). Early adolescent brain markers of late adolescent academic functioning. Brain Imaging and Behavior, 13(1), 1-8.
Montavon, G., Samek, W., & Müller, K. R. (2018). Methods for interpreting and understanding deep neural networks. Digital Signal Processing, 73, 1-15.
Nkhoma, M., Sriratanaviriyakul, N., Cong, H. P., & Lam, T. K. (2014). Examining the mediating role of learning engagement, learning process and learning experience on the learning outcomes through localized real case studies. Journal of Education and Training, 56(4), 287-302.
Park, O. C., & Tennyson, R. D. (1986). Computer-Based Response-Sensitive Design Strategies for Selecting Presentation Form and Sequence of Examples in Learning of Coordinate Concepts. Journal of Educational Psychology, 78(2), 153-158.
Perelmutter, B., McGregor, K. K., & Gordon, K. R. (2017). Assistive technology interventions for adolescents and adults with learning disabilities. Computers in Education, 114, 139-163.
Shanthini, A., Vinodhini, G., & Chandrasekaran, R. M. (2018). Predicting Students Academic Performance in the University Using Meta Decision Tree Classifiers. Journal of Computer Science, 14(5), 654-662.
Shum, S. B., & Crick, R. D. (2012). Learning dispositions and transferable competencies: pedagogy, modelling and learning analytics. In Proceedings of the 2nd International Conference on Learning Analytics and Knowledge (pp. 92-101).
Slim, A., Heileman, G. L., Kozlick, J., & Abdallah, C. T. (2014). Predicting student success based on prior performance. In 2014 IEEE Symposium on Computational Intelligence and Data Mining (CIDM) (pp. 410-415).
Thomas, S. (2016). Future Ready Learning: Reimagining the Role of Technology in Education. 2016 National Education Technology Plan. Office of Educational Technology, US Department of Education.
Viera, A. J., & Garrett, J. M. (2005). Understanding interobserver agreement: the kappa statistic. Family Medicine, 37(5), 360-363.
Waheed, H., Hassan, S.-U., Aljohani, N. R., Hardman, J., Alelyani, S., & Nawaz, R. (2020). Predicting academic performance of students from VLE big data using deep learning models. Computers in Human Behavior, 104, 106189.
Whitener, E. M. (1989). A Meta-Analytic Review of the Effect on Learning of the Interaction between Prior Achievement and Instructional Support. Review of Educational Research, 59 (1), 65-86.
Wong, T.-T., & Yeh, P.-Y. (2020). Reliable Accuracy Estimates from k -Fold Cross Validation. IEEE Transactions on Knowledge and Data Engineering, 32(8), 1586-1594.
收稿日期:2020-09-11
定稿日期:2020-11-29
作者简介:胡航,博士,副教授,硕士生导师,西南大学教师教育学院卓越教学中心副主任,深度学习研究中心主任(400715)。
杜爽,硕士,讲师,四川外国語大学教育技术中心(400031)。
梁佳柔,硕士研究生;康忠琳,硕士研究生。西南大学教育学部(400715)。
责任编辑 韩世梅
猜你喜欢
医学食疗与健康(2021年27期)2021-05-13
成都信息工程大学学报(2019年3期)2019-09-25
电子制作(2018年16期)2018-09-26
中国交通信息化(2018年5期)2018-08-21
电子测试(2018年1期)2018-04-18
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
郑州大学学报(医学版)(2015年1期)2015-02-27
电测与仪表(2014年15期)2014-04-04
