
基于双倍比特量化分类索引技术的图像检索研究
2021-05-17 03:51鲁明宋馥莉刘平胜兰勇
河南科技 2021年3期
鲁明 宋馥莉 刘平胜 兰勇
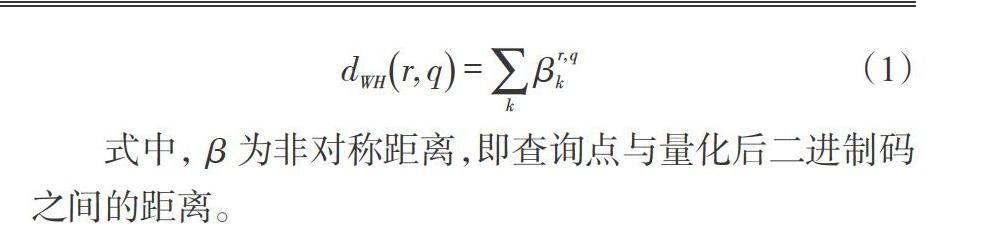

摘 要:本文对图像数据进行双倍比特量化分类,增强了每个维度数据的差异程度。为了最大限度地提升量化后的查询精度,其间采用量化后比对结果和量化前的查询数据进行非等距计算,提高索引的查询精度。试验证明,最近邻查询的准确率较传统二进制映射中的双倍比特量化大大提高了性能。
关键词:二进制量化;双倍比特量化;加权距离度量
中图分类号:TP301.6文献标识码:A文章编号:1003-5168(2021)03-0015-04
Research on Image Retrieval Based on Double Bit
Quantitative Classification Index Technology
LU Ming1 SONG Fuli1 LIU Pingsheng2 LAN Yong3
(1. The Open University of Henan,Zhengzhou Henan 450008;2. Zhongshan Torch Polytechnic,Zhongshan Guangdong 528436;3. Tianjin University of Finance and Economics Pearl River College , Tianjin 301800)
Abstract: In this paper, the double-bit quantization classification of image data had enhanced the degree of difference in data in each dimension. In the meantime, in order to maximize the query accuracy after quantification, the comparison result after quantization and the query data before quantification were used to perform non-equal distance calculations to improve the query accuracy of the index. Experiments showed that the accuracy of nearest neighbor query greatly improved the performance compared to the double-bit quantization in traditional binary mapping.
Keywords: binary quantization;double bit quantization;weighted distance metric
視觉图像检测[1]和图像检索[2-3]的核心工作存在相似性,二者都需要在高维数据库中检索和匹配相似的特征数据。它的目的是在大型高维数据库中搜索相似的数据来查询数据。最近邻算法作为大型多维度数据库的常用算法,其性能和效率问题愈发显现[4]。
1 概述
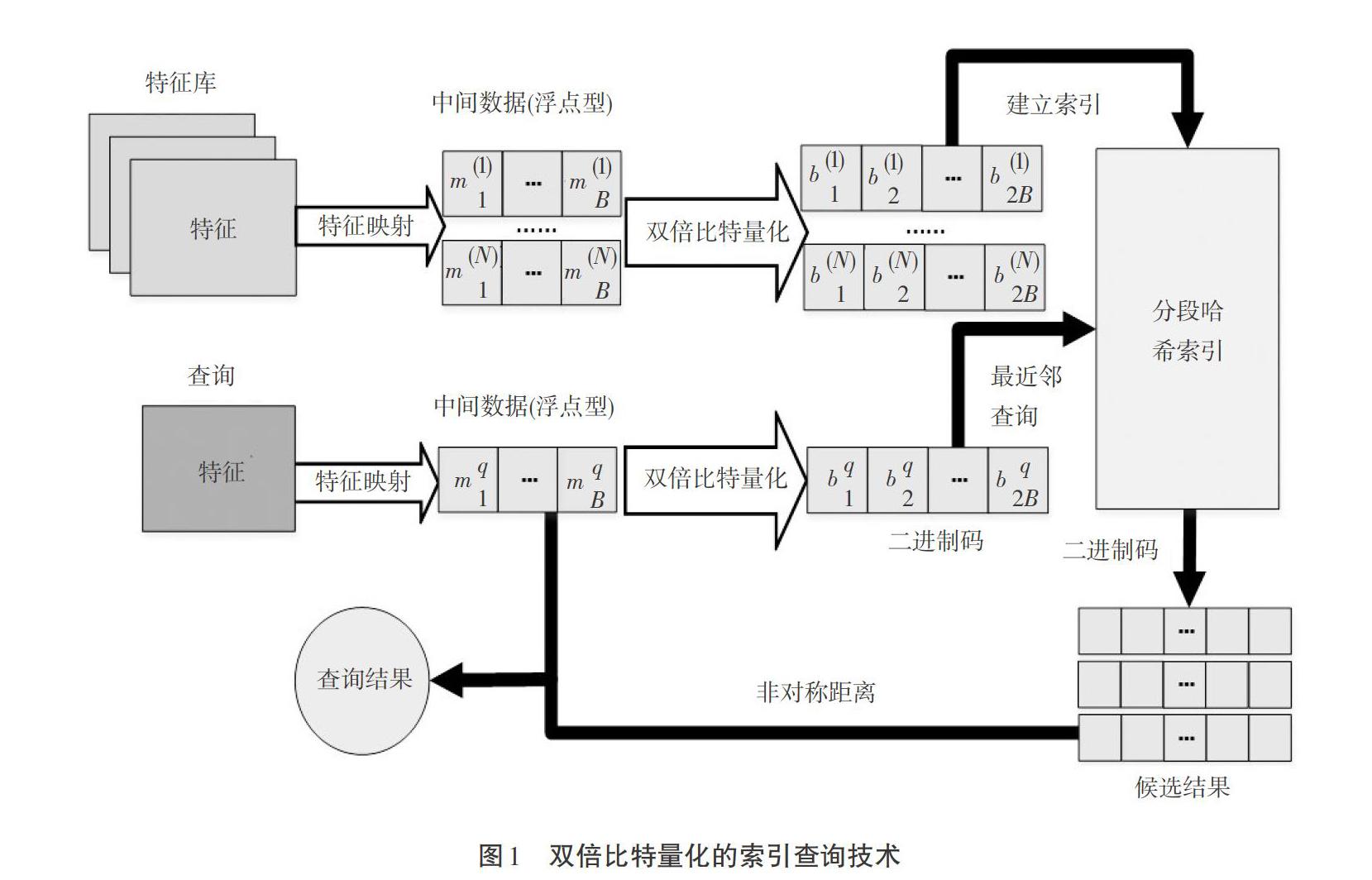
针对最近邻算法图像检索效率低的问题,本文在高维图像检索过程中引入了二进制编码形式。二进制代码是执行效率最高的一种编码形式,可以应用于图像数据的二进制量化和索引技术[5]中。二进制量化是将图像数据存储格式中原始浮点相似的特征数据转化映射为近似的二进制码,然后针对生成的二进制代码设计出高效快捷的图像检索算法,以适应大规模数据环境[6]下的图像检索需求。如图1所示,本文提出了一种双倍比特量化的索引查询技术,具体创新主要有两点。
1.1 双倍比特量化的方法
将浮点高维特征空间投影到高维向量二元映射,属性间的区别在于添加了中间高维向量空间,每一维的数据有两位的二进制代码。双倍比特量化可以应用于不同的二进制量化技术、不同的类型和不同的尺寸特征。
1.2 非对称距离查询算法
对于每次查询,可以在汉明最近邻的空间选择双倍比特量化举措,继而在汉明最近邻候选集空间通过浮点计算非对称距离,对查询函数(中间数据)和二进制码特征库进行重新排序,从而提高查询精度指标。
本文使用的要领具有三个显著优势。一是双倍比特量化方法能够高效降低量化耗损,提高查询精度;二是双倍比特量化和非对称距离算法可以应用于现有的二进制量化和索引方法;三是双倍比特量化易于实现。基准数据集试验表明,双倍比特量化方法可以使最近邻查询精度提升15%~25%。
2 研究现状
2.1 二进制量化
目前,研究者提出了很多著名的二进制映射方法,其主要分为两类,即基于随机的映射和基于学习的映射。基于随机的映射主要有局部敏感哈希(LSH)和位置敏感聚类(Locality Sensitive Clustering, LSC)。LSH使用内积来比较两个向量的相似程度,通过多元正态分布取得多个哈希函数,并将其稀疏之特质映射到超平面。随机映射与处理数据无关,处理速度快,但只有在维度足够高时才有好的检索效果。基于学习的二进制映射技术在维度低的情况下能满足查询精度的要求,但试验效率较低,而且中间向量的每一维数据在传统的量化方法下只能被简要地映射为两类(为0或者1),这样的量化方法不能很好地保持原始特征之间的相似关系。位置敏感聚类方法主要包括三部分:第一,生成位置敏感哈希函数;第二,桶标记的产生,即利用位置敏感哈希函数对每个点进行映射得出桶标记;第三,桶标记的合并。由于桶标记的个数多于实际的类数目,需要选择合适的合并区间对桶标记进行合并,合并后的桶标记对可用来对数据点进行分组,得出最终的类标签。
4.1 试验设置
试验在BIGANN SIFT 1M和Caltech101两个数据集上开展,如表2所示。试验的硬件环境是Intel Xeon E5-2620*2(7.2 GT/s,2.00 GHz,15M cache,6cores),内存为64 GB。
4.2 双倍比特量化分类索引
下面使用多种二进制映射方法来验证本文所提二进制映射的优化方法,包括局部敏感哈希(LSH)、主成分分析(PCA)和迭代量化(PCA-ITQ)。
每个试验包括1 000个查询,以查询的平均准确率和平均召回率当作性能指标来明确双位量化。试验在两个数据集(BIGANN SIFT 1M和Caltech101)比照使用差异二进制映射方式。为了获得双倍二进制码,训练集中的高维特征被映射为中间数据,并根據每个维度的正负符号获得中值。继而,以与训练集相同的方式将特征库中的特征和查询特征变换为中间数据,通过双倍比特量化将数据转化为二进制码。最后,计算并查询二进制码与每个二进制码的加权海明距离。在两个数据集上,使用原始二进制映射算法和双倍比特量化方法比较结果如表3和表4显示。
试验结果表明,传统二进制映射的性能有了很大的提高。在使用原始二进制映射算法时,数据集BIGANN 1M SIFT的结果(百分比)如表3所示。二进制代码分别是32位、64位、128位和256位。二值投影算法分别为ITQ、RR、SH、LSH和PCA。T@1表示top-1的准确率,B@10表示top-10的召回率。SB代表单位量化,DB代表双倍比特量化。
在使用双倍比特量化方法时,数据集Caltech GIST datasets的结果(百分比)如表4所示。二进制代码分别为64位、128位、256位和320位。二进制投影算法分别是ITQ、RR、SH、LSH和PCA。T@1表示top-1的准确率,B@10表示top-10的召回率。SB代表单位量化,DB代表双位量化。
每个试验有1 000个查询。本研究只对结果进行了重新排序,召回率仍旧保持固定不变,所以本试验以准确率作为检测指标。在两个有差别的数据集(BIGANN SIFT 1M和Caltech101)中,本文使用不同的二值映射方式,结果发现,使用不对称距离进行重新排序的结果优于直接获取的成果。
5 结论
在大规模数据环境下进行快速最近邻查询时,需要量化普通二进制数据,但是查询信息的原始特征信息弱化会导致查询精度降低。研究者充分利用二进制运算规则简单、适于逻辑运算的特点,提出了一种双倍比特量化分类索引方法,解决了该问题。本文对量化分类后的二进制数据和查询信息未量化前的数据进行距离计算,大大提高了查询的精度和准确性。大数据集试验证明,该方法可以提升15%~25%的最近邻查询精度。
参考文献:
[1]贾佳,唐胜,谢洪涛,等.移动视觉搜索综述[J].计算机辅助设计与图形学学报,2017(6):1007-1021.
[2]RUBLEE E,RABAUD V,KONOLIGE K,et al.ORB:an efficient alternative to SIFT or SURF[C]//International Conference on Computer Vision.2012.
[3]ZITNICK C L.Binary Coherent Edge Descriptors[C]//European Conference on Computer Vision,2010.
[4]马艳萍,姬光荣,邹海林,等.数据依赖的多索引哈希算法[J].西安电子科技大学学报,2015(4):159-164.
[5]李雯,邓涵,许玉珍.基于双倍比特量化与分段哈希索引的军事图像过滤[J].航天控制,2019(4):59-65.
[6]宋馥莉,闫培玲.双倍比特量化近似查询索引算法研究[J].河南科技,2019(25):28-31.
