
基于XGBoost算法的坐席话务量预测
2021-05-16 17:25赵龙周源李飞范文斌
现代信息科技 2021年22期
赵龙 周源 李飞 范文斌

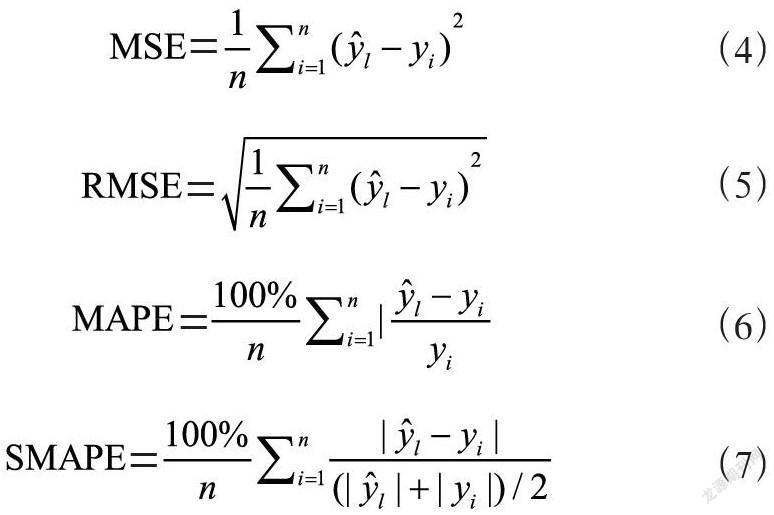


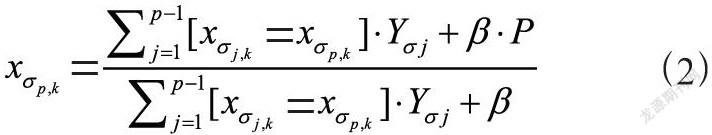
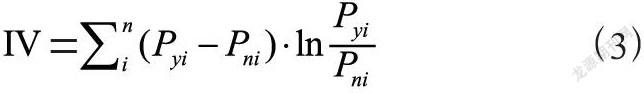

摘 要:“呼叫中心”一词来源于英文Call Center,自其诞生以来就作为企业和客户之间的沟通桥梁,是客户和企业沟通最直接的渠道,因此优化呼叫中心的接聽应答效率是管理者一直以来的追求。该文为了向管理者提供前瞻的话务量预测信息供管理者决策,提出了使用XGBoost、LightGBM、Catboost算法结合信息价值分析法选择的特征通过累加型滑动窗口法建立话务量预测模型,并在真实数据上比较了三个算法的预测表现。结果表明XGBoost算法对于运营商呼叫中心话务量的预测较为准确,为坐席排班提供数据支撑。
关键词:呼叫中心;XGBoost;话务量;坐席排班
中图分类号:TP18 文献标识码:A文章编号:2096-4706(2021)22-0086-04
Abstract: The word“call center”comes from English Call Center, since its birth, it has been used as a communication bridge between enterprises and customers, it is the most direct channel for customers and enterprises to communicate. Therefore, optimizing the answering efficiency of call center has always been the pursuit of managers. To provide managers with forward-looking forecast information of telephone-traffic volume for their decision-making, this paper proposes to use XGBoost, LightGBM and Catboost algorithms and combined with the characteristics selected by the information value analysis method to establish the telephone-traffic volume prediction model through the cumulative sliding window method, and compares the prediction performance of the three algorithms on the real data. The results show that the XGBoost algorithm is more accurate in predicting the call center’s telephone-traffic volume, and provide data support for seat scheduling.
Keywords: call center; XGBoost; telephone-traffic volume; seat scheduling
0 引 言
随着经济和互联网技术的快速发展,电信业务不断更新,客户对网络质量、感知体验及其相关服务要求越来越高,因此呼叫中心行业在客户关系中占有重要地位。
在过去几十年的管理,通过电话沟通呼叫中心为客户提供有效和响应性的服务,切实解决客户的各种问题,如处理客户的疑难点、需求和请求,是服务行业必不可少的系统,特别是对于大型组织[1]。
对于那些通过呼叫中心收集订单来组织业务的公司来说,呼叫中心的有效性和营销活动之间存在着至关重要的联系。为了达到目标服务水平,管理者必须在呼叫中心的适当时间内雇佣适当数量且技术熟练员工。基于详细的通话数据,短期预测来调度可用的坐席池是呼叫中心管理者面临的一项基本挑战。由于呼叫高峰时间可能持续时间较短,呼叫中心的人员配备并不总是足够灵活来适应这一需求。因此,对呼叫中心到达的稳定性建模和计算员工需求是呼叫中心管理的关键问题[2,3],即当前的热点和难点是科学预测以及有效提高呼叫中心行业的话务量预测精确度。
1 算法描述
1.1 XGBoost算法
XGBoost[4]是一个基于梯度提升的高度可扩展的决策树集成。与梯度提升一样,XGBoost 模型通过减少损失函数来构建目标函数的额外扩展。它仅使用决策树作为基本分类器,并使用损失函数变化来控制树的复杂性。
其中,式中,T为树叶数,ω为树叶输出分数。γ值表示内部节点分裂所需的最小损失减少。收缩是XGBoost中的另一个正则化参数,它最小化了附加的扩展步长大小。其他方法,如树的深度,可以用于控制树的复杂性。为了更快地训练模型和减少存储空间需求,对于降低树的复杂度是必要的。
此外,XGBoost随机化技术,如随机子样本和列的二次采样,能够减少过拟合,加快训练。为了最小化寻找最佳分割的计算复杂度,XGBoost使用了一个基于列的压缩存储,其中的数据是预先排序存储的。这种基于列的存储结构支持并行搜索每个考虑的属性的最佳划分。另外,XGBoost还使用基于数据百分位数的方法来测试候选分割的子集,并使用聚合统计信息计算它们的增益,而不是扫描所有可能的候选拆分。因此,节点级数据子抽样类似于这个概念。XGBoost还使用了一种稀疏性感知算法,有效地从分离候选的损失增益的计算中消除空值。
1.2 LightGBM算法
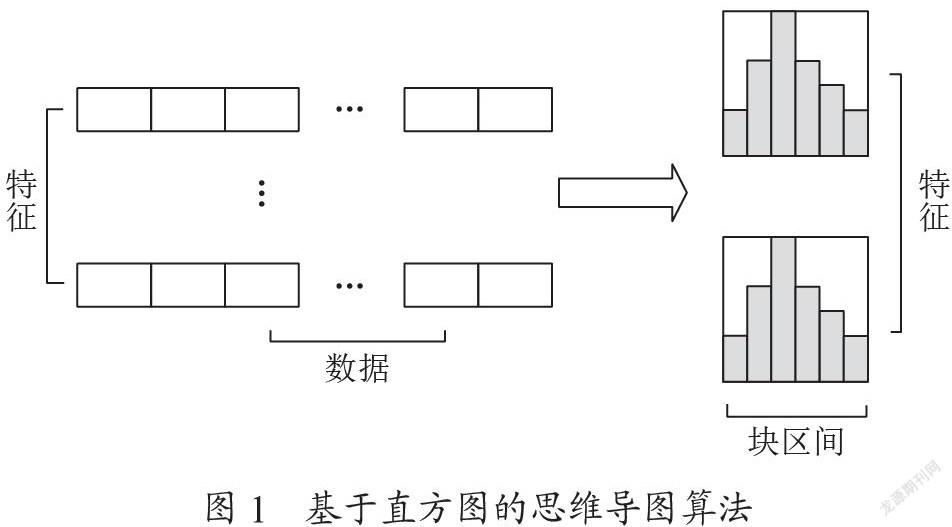
LightGBM算法是微软在梯度提升回归[5]的基础上提出的,是最新、最有效的机器学习算法之一。它采用基于直方图的算法,将连续的特征值存储到离散的容器中[6,7]。基于直方图的算法可以帮助加快训练并减少内存使用[8]。另外,采用直方图减法技术,利用目标叶的父叶减去其邻叶得到目标叶,也有助于加快收敛速度。基于直方图的算法的思维导图如图1所示。连续的特征被分散到离散的箱子中,使用许多直方图来积累统计量。
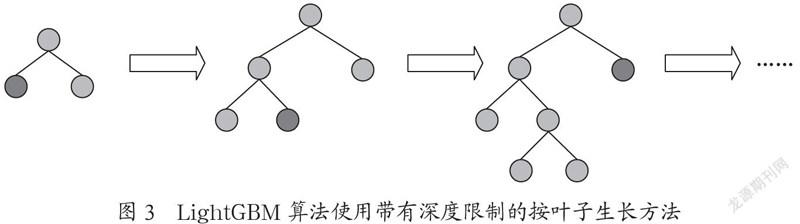
LightGBM实现了带有深度限制的按叶子生长(leaf-wise)算法[9],选择σ损失最大的叶子生长。下面介绍两种树木生长方法。许多正常的提升算法使用图2所示的按层生长 (level-wise)的决策树生长,并且在每个层中拥有相同数量的叶子。level-wise决策树生长法选择σ损失最大的叶子生长,这意味着每一层的叶片数量并不总是相同的,如图3所示。leaf-wise决策树生长可以帮助实现更低的损失[8]。此外,LightGBM在过拟合的情况下限制了樹的深度。
一般来说,LightGBM具有足够的复杂性,并具有处理多非线性关系问题的强大能力。它既能保持高效率,又能保持高精度。因此,它在处理中子计算方面具有广阔的应用前景。
1.3 Catboost算法
CatBoost是一种新的梯度增强决策树(GBDT)算法,能够很好地处理分类特征。该算法与传统GBDT算法的不同之处在于以下几点:
(1)在训练时处理分类特征,而不是预处理时间。CatBoost允许使用整个数据集进行训练。Prokhorenkova等人[10]认为,目标统计(TS)是处理分类特征的一种非常有效的方法,信息损失最小。具体来说,对于每个示例,CatBoost执行数据集的随机排列,并计算示例的平均标签值,将相同的类别值放在排列中的给定值之前。如果存在一个排列公,则采用以下公式进行代替:
其中P是先验值,β是先验的权值。对于回归任务,计算先验的标准技术是取数据集中的平均标签值。
(2)特征组合。所有的分类特征都可以合并成一个新的分类特征。当为树构造一个新的分支时,CatBoost使用一种贪婪的方式来考虑组合。对于树中的第一次拆分不考虑组合,但对于第二次和后续拆分,CatBoost将预先设置的所有组合与数据集中的所有分类特性结合起来。在树中选择的所有劈叉都被视为具有两个值的类别,并在组合中使用。
(3)无偏差提升分类特征。在使用TS方法将分类特征转化为数值时,其分布会与原始分布不同,这种分布的偏差会导致解的偏差,这是传统GBDT方法不可避免的问题。Prokhorenkova等人[10]通过理论分析,提出了一种克服梯度偏差的新方法,称为有序助推。
(4)快速得分。CatBoost使用健忘树作为基本预测器,在树的整个层次上使用相同的分裂标准[11]。这样的树是平衡的,不容易过度拟合。在健忘树中,每个叶索引被编码为一个二进制向量,其长度等于树的深度。这一原则在CatBoost模型求值器中被广泛使用,用于计算模型预测,因为所有二进制文件都使用浮点、统计和一次性编码特性。
2 实验分析
2.1 数据采集
本文研究的数据来源于2019年某省电信运营商客服中心通话记录数据,并且对其进行脱敏。
2.2 数据预处理
当原始数据集中的数据出现不完整、凌乱、数据冗余以及数据规模庞大等多种问题,那么通过数据预处理这个步骤,将会提高模型预测精度。此外原始数据存在于不同的表中,因此需要通过对数据进行预处理进行整合。本文主要在以下方面做了数据预处理工作:删除缺失值过多的样本和特征列、采用众数、平均数填充缺失值、剔除冗余样本、以及对二元属性值进行数据类型转换。
2.3 特征选择
特征选择将会在以后的建模和预测中起着关键的作用,尤其是在数据集小而特征多的情况下。此外消除噪声和正确选择特征能够定性地提高模型的整体精度和稳定性。
特征选择过程是个极其复杂的过程,需要考虑的因素很多,例如特征的预测能力,特征之间的相关性,特征的简单性、特征在业务上的可解释性等等。但是,其中最主要和最直接的衡量标准是变量的预测能力。IV就是这样一种指标,IV表示信息价值,它是衡量自变量的预测能力的一种指标,即某个特征对预测目标的影响程度。
其基本思想是根据该特征所命中黑白样本的比率与总黑白样本的比率,来对比和计算其关联程度,其公式如下所示:
其中,n代表样本在该特征上分成的组数,表示该样本第ni组数据中白样本占所有白样本的比例,表示该样本第yi组数据中黑样本占左右黑样本的比例。其IV值的预测能力表如表1所示。
由表可知,并不是IV值越大越好,当IV大于0.5时,由于太好了而显得不够真实,我们将会对此表示可疑,通常我们会选择IV值在0.1到0.5之间。
本文采用IV值分析的方法进行特征选择,最终选出40个对话务量有影响的特征变量作为模型的输入特征变量。
2.4 模型预测
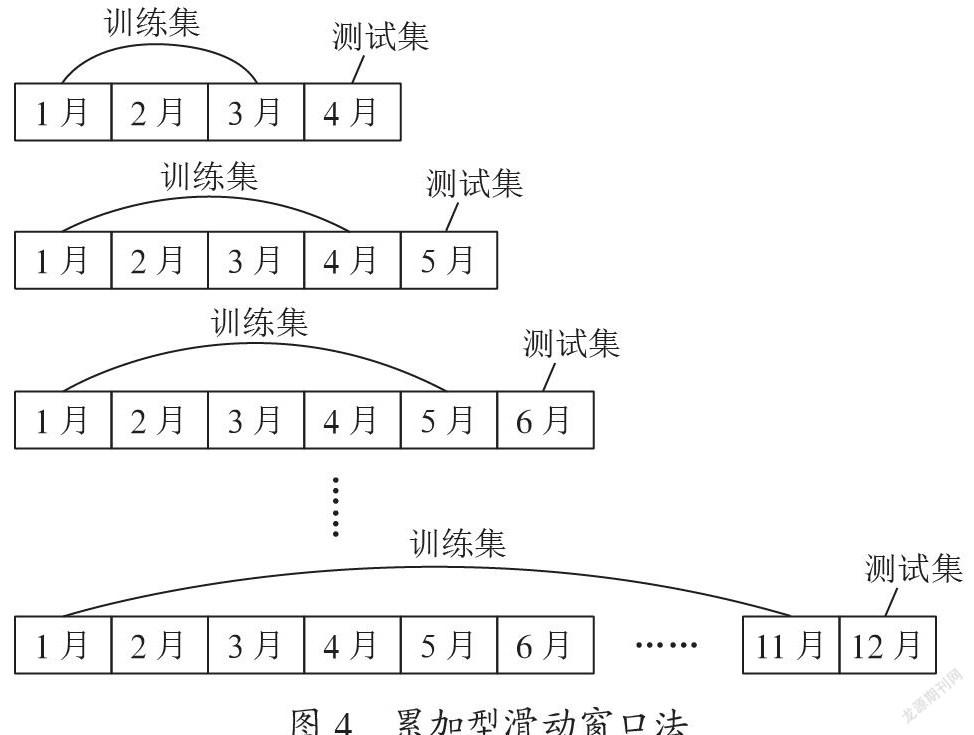
经过前面的分析介绍,以上算法均适合用于对话务量预测的研究。通过对数据进行预处理和特征选择,并采用累加型滑动窗口法构建样本集,其中训练样本集随着时间的推移,数据在不断地进行累加,在训练集的基础之上,随机抽取30%作为验证集。然后把处理后的包含40个特征变量的训练集作为输入变量输入到模型中进行训练,再用验证集进行验证,最后用测试集进行测试。累加型滑动窗口法原理如图4所示。
2.5 评价标准
评价标准的选取是整个实验环节的重要部分,会直接影响到实验的结果分析。本文选取均方误差 MSE(Mean Square Error)、均方根误差RMSE(Root Mean Square Error)、平均绝对百分比误差MAPE(Mean Absolute Percentage Error)、对称平均绝对百分比误差SMAPE(Symmetric Mean Absolute Percentage Error) 值等评价指标。各公式如下:
其中n表示样本数量,是模型的预测值,yi是实际真实值。当真实值与预测值的差值越接近0时,即模型比较优越,误差越大,该差值越大。
2.6 结果分析
经过以上步骤的数据处理、特征选择和模型预测,得出了使用XGBoost算法模型的预测结果,并且与Catboost、 LightGBM 两个算法模型得出的结果进行了对比,结果如表2所示。
从表中可以得出,XGBoost模型在MSE、RMSE、MAPE和SMAPE四个评价标准上,均优于LightGBM和Catboost模型,即得出XGBoost模型在预测话务量问题上具有更好的效果。
3 结 论
考虑到电信网络服务在当今社会已然成为人民生活的基础服务,其中呼叫中心的有效管理对于电信运营商持续改善网络信息服务起到关键作用。对话务量的估计因此成为管理者关心的问题,它直接影响到呼叫中心的运营成本和具体排班。本文介绍了XGBoost、LightGBM和Catboost模型的算法核心以及使用信息价值分析法选择特征,并最后对真实话务量数据进行建模。结果表明,在电信运营商呼叫中心的业务场景中,推荐使用XGBoost模型为管理者提供更准确的话务量预测信息。
参考文献:
[1] BUIST E,CHAN W,L’ECUYER P. Speeding up call center simulation and optimization by Markov chain uniformization [C]//2008 Winter Simulation Conference.Miami:IEEE,2008:1652-1660.
[2] AKTEKIN T,SOYER R. Call center arrival modeling:A Bayesian state‐space approach [J].Naval Research Logistics(NRL),2011,58(1):28-42.
[3] CHASSIOTI E,WORTHINGTON D J. A new model for call centre queue management [J].The Journal of the Operational Research Society 2004,55(12):1352-1357.
[4] CHEN T,GUESTRIN C. Xgboost:A scalable tree boosting system [C]//Proceedings of the 22nd acm sigkdd international conference on knowledge discovery and data mining.New York:Association for Computing Machinery,2016:785-794.
[5] KE G,MENG Q,FINLEY T,et al. Lightgbm:A highly efficient gradient boosting decision tree [J].Advances in neural information processing systems,2017,30:3146-3154.
[6] RANKA S,SINGH V. CLOUDS:A decision tree classifier for large datasets [C]//Proceedings of the 4th knowledge discovery and data mining conference.Syracuse University,1998:1-34.
[7] LI P,WU Q,BURGES C. Mcrank:Learning to rank using multiple classification and gradient boosting [J].Advances in neural information processing systems,2007,20:897-904.
[8] Microsoft-Corporation. Latest Document of LightGBM [EB/OL].[2021-08-27].https://lightgbm.readthedocs.io/en/latest/Features.html.
[9] SHI H. Best-first decision tree learning [D].Hamilton:The University of Waikato,2007.
[10] PROKHORENKOVA L,GUSEV G,VOROBEV A,et al. CatBoost:unbiased boosting with categorical features [J/OL].arXiv:1706.09516 [cs.LG].(2017-06-28).https://arxiv.org/abs/1706.09516v4.
[11] KOHAVI R,LI C H. Oblivious decision trees,graphs,and top-down pruning [C]//Fourteenth IJCAI.Montreal:IJCAI,1995:1071-1079.
作者簡介:赵龙(1982—),男,汉族,安徽铜陵人,副总裁,硕士,研究方向:通信运营商IT咨询规划、软件系统设计、智慧社区、云计算和数据智能;周源(1991—),男,汉族,安徽合肥人,算法工程师,硕士,研究方向:数据挖掘和自然语言处理;李飞(1982—),男,汉族,安徽利辛人,总经理,硕士,主要研究方向:通信运营商IT咨询规划、软件系统设计、大数据平台建设、数据建模和数据智能;范文斌(1990—),男 ,汉族,安徽黄山人,部门经理,本科,研究方向:软件系统设计、数据智能、知识图谱。
