
基于对象特征的深度哈希跨模态检索
2021-05-14 03:42白弘煜张仲羽谢博鋆张俊三
计算机与生活 2021年5期
朱 杰,白弘煜,张仲羽,谢博鋆,张俊三
1.中央司法警官学院信息管理系,河北保定071000
2.河北大学数学与信息科学学院,河北保定071002
3.中国石油大学(华东)计算机科学与技术学院,山东青岛266580
近年来,互联网中图像、文本等多种模态的数据量急剧增长,多模态数据之间的交互也应运而生。跨模态检索已经成为人工智能领域的一个热门课题,其目的是为了确定来自不同模态的数据是否指向相同内容。在跨模态检索过程中,一种模态的数据会映射到另一种模态去检索,但是,由于不同模态的数据分布在不同的特征空间上,因此多模态检索成为了一项非常有挑战性的任务。
基于哈希的多模态数据表示因其快速、有效性受到了信息检索领域的广泛青睐。目前的多模态哈希主要分为多源哈希[1-2]和跨模态哈希[3-4],其中多源哈希致力于综合数据的不同模态产生哈希码。与多源哈希不同,跨模态哈希在检索中提供的数据源通常只有一种(如文本),而需要检索其他模态中对应的数据(如图像)。在解决实际问题的过程中发现,大部分情况下无法提供样例的全部模态数据,因此跨模态检索就显得尤为重要。跨模态检索成败的关键在于能否将不同模态的数据映射到相同的特征空间,从而避免语义鸿沟的问题。
传统的方法尝试利用人工特征将不用模态的数据映射到相同的空间,如:集体矩阵分解哈希(collective matrix factorization Hashing,CMFH)[5]、语义相关性最大化(semantic correlation maximization,SCM)[6]与跨视角哈希(cross view Hashing,CVH)[7]。
近些年深度学习不断发展,并且被广泛应用于计算机视觉领域,如:图像分类[8-9]、图像分割[10-11]、人脸识别[12]与图像检索[13-14]。越来越多的研究表明深度神经网络在特征表示方面有很好的性能,因此被广泛应用于跨模态检索。
跨模态深度哈希检索方法将不同模态的数据通过深度网络映射为一系列的二进制码,并通过汉明距离衡量数据相似性。融合相似性哈希法(fusion similarity Hashing,FSH)[15]采用了一种无向非对称图的方式将多模态的特征进行加工,用于生成鲁棒性较强的哈希码。相关自编码哈希法(correlation autoencoder Hashing,CAH)[16]通过最大化特征相关性和相似标签所传达的语义相关性,用于生成非线性深度自哈希码。三元组损失也被应用于跨模态网络的学习中,三元组深度哈希(triplet-based deep Hashing,TDH)[17]使用三元组标签来描述不同模态实例之间的关系,从而捕获跨模态实例之间更一般的语义关联性。哈希方法的本质在于生成二值化的哈希码,离散潜在影响模型(discrete latent factor model,DLFH)[18]基于离散潜因子模型,学习跨模态哈希二进制哈希码,用于交叉模态相似度搜索。为了去掉不必要的信息,从而提高跨模态检索精度,注意力机制被应用于跨模态检索,堆叠注意力网络(stacked attention networks,SANs)[19]采取了多个步骤,将注意力逐步集中在相关区域,从而为图文问答任务提供了更好的解答。Sharma 等[20]提出了一种基于注意力的动作识别模型,该模型使用具有长短期记忆(long short-term memory,LSTM)单元的递归神经网络(recurrent neural networks,RNNs)来获取时间和空间信息。Noh 等[21]提出了一种注意力模型,该模型采用加权平均池化的方式生成基于注意力的图像特征表示。
深度跨模态哈希(deep cross modal Hashing,DCMH)[4]提出了一种基于深度神经网络的端到端的学习框架,算法将特征学习与哈希码学习统一到相同的框架中用于跨模态检索。随后出现了DCMH 算法的一系列变种,成对关系深度哈希(pairwise relationship guided deep Hashing,PRDH)[22]在DCMH 的基础上,通过降低二进制码之间的关联性,提高了跨模态检索性能。深度有监督跨模态检索方法(deep supervised cross-modal retrieval,DSCMR)[23]在DCMH的基础上,提出了一种有判别力的损失函数,使生成的网络能够更好地生成跨模态特征。但是这些方法提取出的图像特征为全局特征,无法突出图像中的对象内容即语义内容,这导致以上方法无法真正实现语义上的跨模态。
为了解决此类问题,本文提出了一种基于对象特征的深度哈希(object feature based deep Hashing,OFBDH)跨模态检索方法。与大多数跨模态检索方法不同,本文将深度图像特征、深度文本特征和深度对象特征进行融合,用于训练深度神经网络,从而生成更加优秀的跨模态哈希码。
1 跨模态检索问题描述
本文算法只关注于图像和文本两种模态的跨模态检索。假设每个训练样本都具有图像和文本两种模态,分别用代表,其中n代表样本数量。S为样本之间的相似性矩阵,如果第i个样本与第j个样本拥有至少一个相同的类标,则认为Sij=1,否则Sij=0。图像和文本的跨模态哈希检索模型的本质在于,学习图像哈希函数h(I)(x)和文本哈希函数h(T)(y),从而使得h(I)(xi)与h(T)(yi)的表达尽量一致。
2 深度网络结构
本文提出的OFBDH 学习框架如图1 所示,它是一个端到端的学习框架,此框架由三部分组成:图像特征学习部分,用于学习深度图像特征;对象特征学习部分,用于提取卷积特征并加工输出深度对象特征;文本特征学习部分,用于学习深度文本特征。
在图像特征学习部分,对应的深度神经网络由8个层次组成,其中包括5个卷积层(Conv1~Conv5)和3个全连接层(fc6~fc8),网络的前7 层与卷积神经网络融合(convolutional neural network fusion,CNN-F)网络完全相同,第8层用于输出学习到的深度图像特征。fc6 和fc7 每一层都含有4 096 个节点且均使用ReLU作为激活函数,fc8 则使用恒等函数作为激活函数。
在图像特征学习部分,数据来源为图像模态Conv5 层的卷积特征,经过两个全连接层fc1 和fc2 之后生成深度对象特征表示。其中fc1 层包含256×K个节点,K代表标签的数量。fc2 层包含512 个节点,且均使用ReLU 作为激活函数。
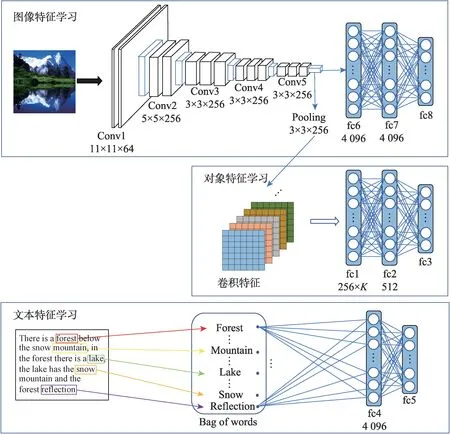
Fig.1 Architecture of OFBDH图1 OFBDH 网络结构
文本特征学习部分,使用词袋(bag of words,BoW)模型来对文本进行表示,从而作为神经网络的输入,fc4 与fc5 为两个全连接层,用于输出深度文本特征。其中,fc4 层使用ReLU 作为激活函数,fc5 层使用的激活函数为恒等函数。
3 深度神经网络学习
这部分内容首先介绍了利用卷积层特征映射生成有判别力的MAC 特征的过程,然后分析了跨模态损失的构造,最后分析了深度网络的学习过程。
3.1 有判别力MAC 特征
以每一批次(batch)中的输入图像为研究对象,通过分析不同维度卷积特征之间的关系,生成有判别力的卷积特征表示。假设每一个批次包含的标签集合为L={l1,l2,…,lj,…,lK},其中K代表标签的数量。在每一批次中存在m幅图像,每幅图像都含有一个或多个标签。之前的研究普遍认为极大激活卷积(maximum activations of convolutions,MAC)特征[24]能够更好地突出对象内容。MAC 特征生成的基础为最后一个卷积层提取出的一系列特征映射,每一个特征映射中提取一个最大值,组成的向量即为图像的MAC 特征。对于任意图像i,从图1 中的Conv5 层提取特征映射,并生成MAC 特征pi。由于特征映射之间存在依赖关系,因此MAC 特征不同维度之间也存在相互依赖的关系。为了解决以上问题,本文首先提出了一种有判别力的MAC 特征。
若图像i中存在任意标签lj,则将此标签在图像i中的向量表示为,否则,qij中的所有元素均设置为0。其中ni为图像i的标签数量。每一批次中任一标签的表示由本批次内各图像针对此标签的向量表示共同表示,进而得到每一批次中标签的向量表示QL={ql1,ql2,…,qlj,…,qlK}。

其中,mj为本批次内存在标签lj的图像数量。
方差较大维度的特征有较好的判别性,标签lj在不同维度的方差表示如式(2)所示,其中V={v1,v2,…,vC},vk代表第k个维度的方差,C为特征的总维度。

在特征选择的过程中,针对所有标签,首先按照方差大小对不同维度进行排序,然后选择方差最大的前N个维度作为此标签最有判别力的特征维度,在标签表示的时候这些维度的特征保持原值,其他C-N个维度的特征则设置为0。为了获得不同标签的有判别力特征集合,本文算法设计了如下目标函数用于求解N,目标函数如下:
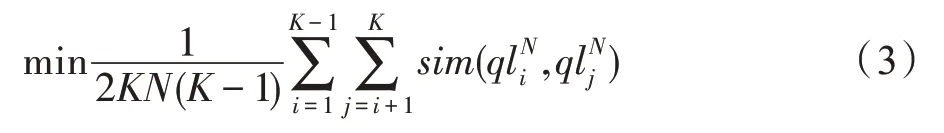
对于任意图像i,其有判别力MAC 特征用QLi=表示,其维度为256×K。如果图像i包含标签lj,则为pi保留了标签lj的N个维度后生成的有判别力的特征;反之,如果图像i不包含标签lj,则中的每个元素均设为0。
最后,将有判别力的MAC 特征作为图像特征学习部分的数据输入,因此MAC 特征的维度与fc1 层的维度相同。
3.2 跨模态损失构建
OFBDH 用f1(xi;θx)∈ℝc表示图像模态的深度神经网络学习到的深度图像特征,用f2(zi;θz)∈ℝc表示对象模态的深度神经网络学习到的深度对象特征,用f3(yi;θy)∈ℝc表示文本模态的深度神经网络学习到的深度文本特征。其中,θx、θy和θz分别表示图像模态、文本模态和对象模态的深度神经网络的网络参数,c为生成的特征维度。
跨模态损失[4,25]可以作为不同模态数据的桥梁,用于训练跨模态深度神经网络,构造了如下跨模态损失函数:
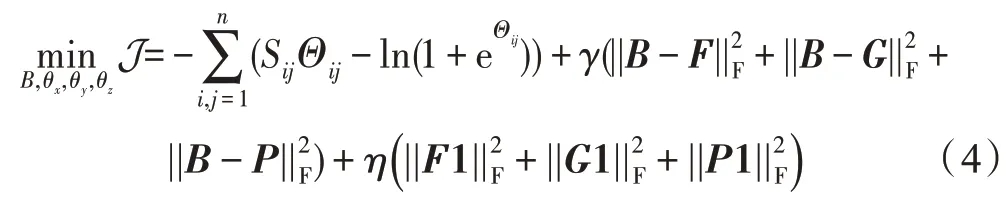
式中,F∈ℝc×n和G∈ℝc×n分别代表生成的深度图像特征和深度文本特征,B∈{-1,+1}c×n代表三种模态数据生成的统一的哈希码。n为批的大小,γ和η为超参数,论文中的值均为1。1 为全1 向量。

3.3 网络参数的学习
本节将介绍OFBDH 如何对θx、θy、θz以及B进行学习。在学习的过程中,采用迭代优化的方法依次将4 个参数中的3 个进行固定,从而学习剩余的1项,以下为参数的具体学习过程。
3.3.1 θx 的学习
在θy、θz和B固定的前提下,采用随机梯度下降与反向传播算法学习图像模态的参数θx。对于每个随机样本xi,给出以下梯度计算方式:
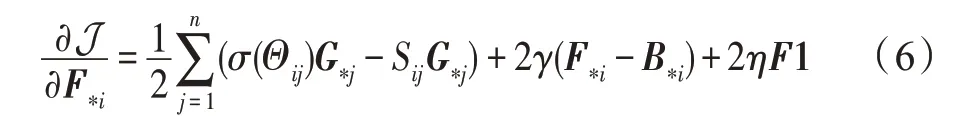
3.3.2 θy 的学习
与θx的学习方法类似,在θx、θz和B固定的前提下,可以利用随机梯度下降与反向传播算法学习文本模态参数θy。对于每个随机样本yj,有如下梯度计算公式:
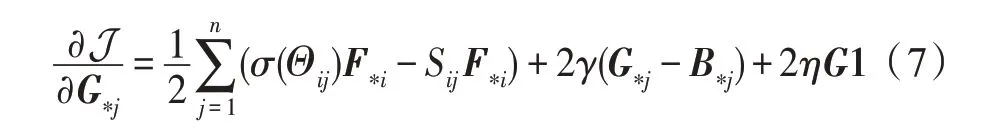
3.3.3 θz 的学习
与更新θx和θy所使用的方法一样,对于每个随机样本zi,有如下梯度计算公式:

3.3.4 B 的学习
在θx、θy和θz的前提下,可以将式(4)中的问题重新描述为:
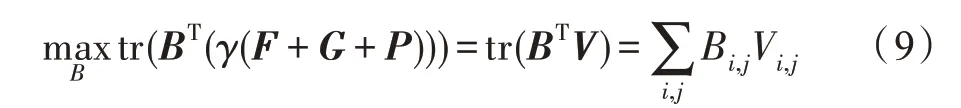
其中,V=γ(F+G+P)。B可以最终表示为如下公式:
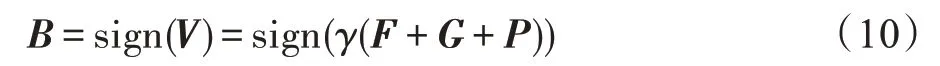
其中,sign(·) 代表元素的sign 函数,如果a≥0,则sign(a)=1,否则sign(a)=-1。
3.4 多模态数据的哈希码生成
在跨模态检索的过程中,对于图像和文本模态的数据,需要通过对应模态的网络生成哈希码。给定图像xi,生成的哈希码如式(11)所示,对于任意文本yi,则用式(12)的方式生成哈希码。
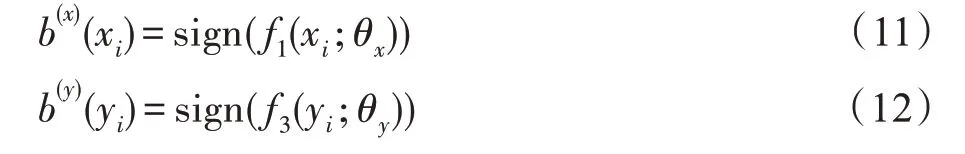
4 实验
为了验证OFBDH 的效果,分别在3 个数据集MIRFLICKR-25K、IAPR TC-12 和NUS-WIDE 上进行了实验。
4.1 数据集
MIRFLICKR-25K[26]数据集由25 000 张图像组成,每一幅图像都含有一个或多个文本标签,这些标签共分为24 类,所有数据来源于Flick 网站。与大部分跨模态检索算法相同,本文只选择至少包含20 个文本标签的样本用于实验,这样就构成了20 015 个图像-文本对。每一对样本的文本标签由1 386 维词袋向量表示。
IAPR TC-12[27]数据集含有20 000 个图像-文本对,这些图像文本对使用255 个标签进行注释,文本标签由2 912 维词袋向量表示。
NUS-WIDE[28]数据集包含来自Flickr 网站的269 648 张图像,每张图像都含有至少1 个文本标签,这些文本标签与对应的图像构成图像-文本对,这些样本分为81 类。选用样本数量最多的10 类进行实验。文本标签则由1 000 维词袋向量表示。
4.2 实验设置
在MIRFLICKR-25K 数据集和IAPR TC-12 数据集中,本文随机选取2 000 个样本作为测试对象,其余作为检索对象,从检索对象中随机选取10 000 个样本用于训练。在NUS-WIDE 数据集中,本文选取2 100个样本作为测试对象,其余作为检索对象,并且从检索对象中选取10 500 个样本用于训练。
为了与DCMH 进行比较,本文采用了与DCMH相同的参数,即γ=η=1。在进行图像模态的网络训练时,使用CNN-F[29]作为图像模态的神经网络架构基础。而文本模态则将BoW 向量作为网络输入。在实验过程中,将批大小设置为64。实验性能评估方面,本文采用平均精度均值(mean average precision,MAP)和精度-召回曲线(precision-recall curve)这两种评估指标对算法的有效性进行评估。所有的实验均运行10 次,并取平均值作为最终结果。
4.3 检索性能比较
本文与6 种优秀的跨模态哈希检索算法进行比较,这6 种算法分别是DCMH[4]、SDCH(semantic deep cross-modal Hashing)[30]、AADAH(attention-aware deep adversarial Hashing)[31]、DLFH[18]、SCM[6]和CCA(canonical correlation analysis)[32]。其中,CCA、SCM 与DLFH算法采用人工特征如SIFT(scale-invariant feature transform)[33]等作为图像特征,其他算法均采用深度神经网络作为特征提取的手段。
表1 展示了不同算法在3 个数据集上的MAP 比对。表中I→T 表示查询为图像模态数据,而检索数据集为文本模态数据。
与之相反,T→I 表示查询为文本模态数据,而检索数据集为图像模态数据。从表1 中可以看出OFBDH 比其余6 种算法的检索性能更好。CCA 和SCM 将标签信息融入到了文本、图像表示中,但采用的图像特征为人工特征,因此在众多算法中MAP 值较低。DLFH 的优势在于可以为多模态数据直接生成哈希码,减少了哈希过程中的特征损失,因此在NUS-WIDE 数据集上取得了最好的MAP,但是,由于此算法采用底层特征对图像进行表示,因此在数据集MIRFLICKR-25K 和IAPR TC-12 中难于获得较好的效果。
OFBDH 的研究基础为DCMH,由于OFBDH 在DCMH 基础上加入了对象特征的学习,使学习到的哈希码能够更加突出对象内容,因此OFBDH 在3 个数据集下比DCMH 获得了更好的MAP 值。与本文的工作类似,AADAH 尝试通过卷积特征发现对象内容,但是AADAH 将图像和文本特征分别区分为显著特征(对象特征)和非显著特征(背景特征),并没有生成图像和文本的全局表示。而OFBDH 既考虑了全局特征,又考虑了对象特征,因此MAP 值仍然高于AADAH。SDCH 将类标信息用于改进深度特征的质量,并采用多种损失函数用于更新网络,因此能够生成第二好的MAP,但由于此方法考虑的依然是全局信息,因此OFBDH 的MAP 值在3 个数据库中比SDCH 高出2 个百分点、2 个百分点和3 个百分点。
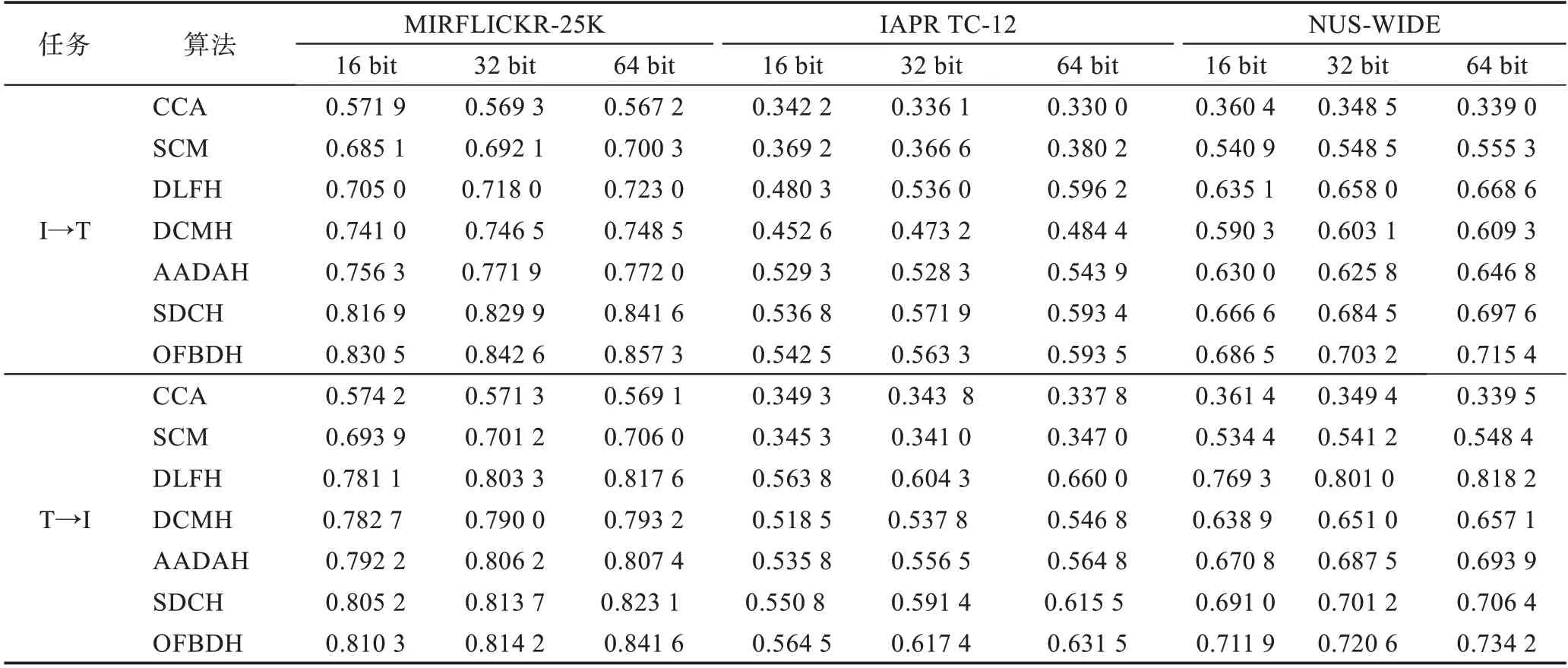
Table 1 MAP value comparison of different algorithms in database表1 不同算法在数据库中的MAP 值比对
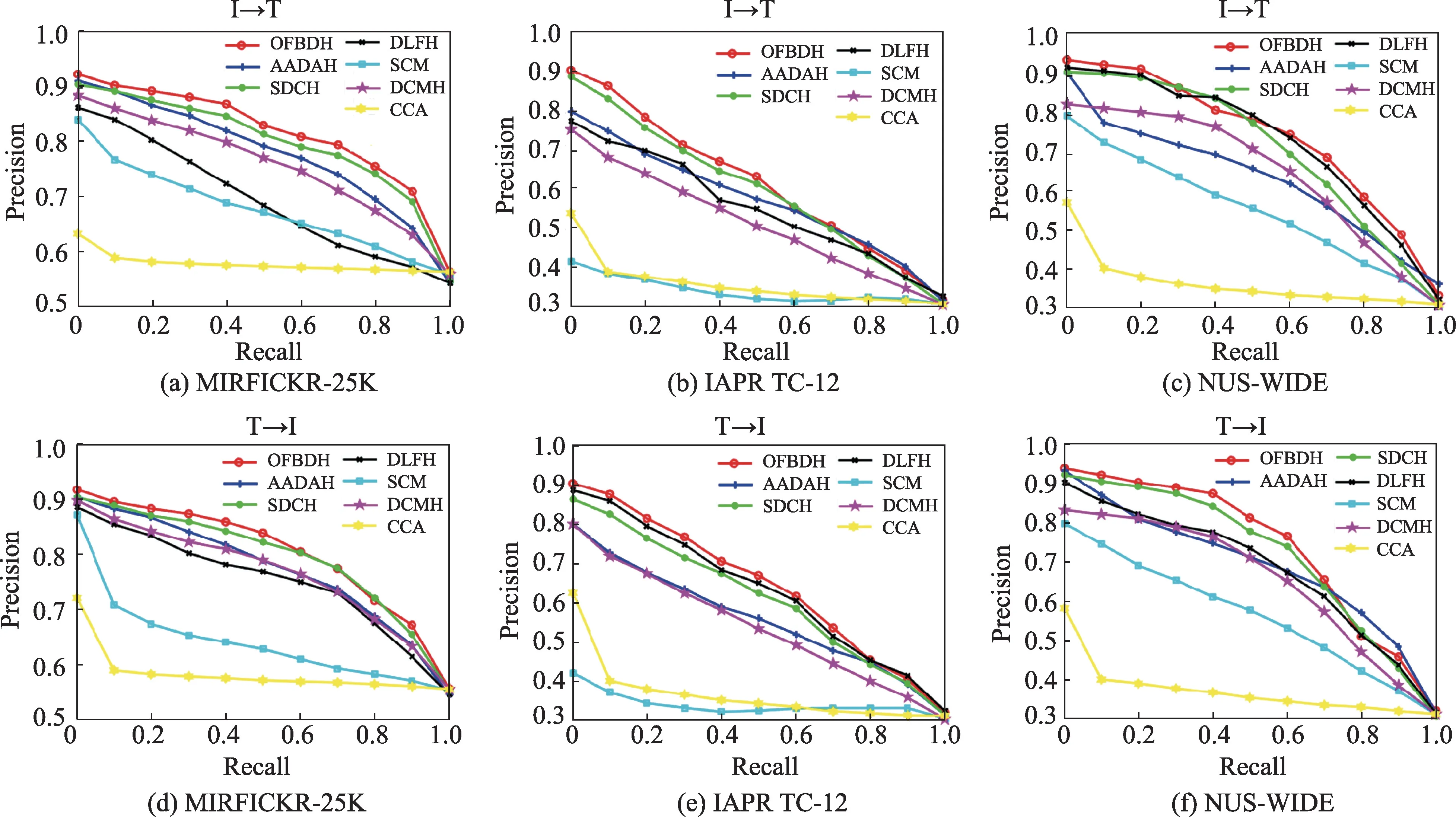
Fig.2 PR curves with code length 16 bit图2 哈希长度为16 bit时的PR 曲线
此外,随着哈希码长度的增长,大部分算法的MAP 值在增加。这个现象的原因有两点:首先,更长的哈希码使得图像、对象和文本特征能够更好地匹配;其次,更长的哈希码能够保存更多信息,这是因为更长的哈希码能够保存更多的细节信息,更利于图像的精准检索。表1 中,通常情况下I→T 的检索性结果低于T→I,这是因为相对于图像,文本能够包含更高级的语义信息,能够更好地刻画图像内容,因此,T→I可以取得更好的结果。
图2 为哈希码为16 bit 前提下,不同算法在3 个数据集上的PR 曲线。从图中可以发现OFBDH 的检索结果仍然优于其他算法。
4.4 参数调整
γ和η的取值对于检索结果有着重要影响,受DCMH 启发,本文在0.01 ≤γ≤2 和0.01 ≤η≤2 的范围内调整结果,发现当γ和η的取值均为1 的时候能够得到最好的检索效果。由于卷积特征可以用于生成深度对象特征,在实验的过程中,尝试用深度对象特征取代深度图像特征,即不考虑深度图像特征与深度文本特征之间的关系。实验结果表明,此方法比OFBDH 的MAP 值小了4 个百分点左右。因此,代表全局信息的图像特征和代表内容信息的对象特征对于跨模态检索性能都有重要的影响。
为了进一步验证卷积神经网络在跨模态检索中的作用,本文采用AlexNet[34]与VGG19[35]代替CNNF,称这两种算法分别为OFBDH_ALE 和OFBDH_VGG,MAP 值比对如表2 所示。通过此表可以发现,当采用不同的卷积神经网络的时候会产生不同的结果,并且OFBDH_VGG 的MAP 在3 个数据库中比OFBDH 分别高出约2 个百分点。
5 结束语
本文提出了一种基于对象特征的深度哈希跨模态检索方法,该方法通过卷积特征生成图像表示,并且将深度图像表示、深度对象表示与深度文本表示有机地结合起来用于跨模态网络的训练。在三个数据集上的实验结果表明,OFBDH 有着优于其他算法的检索性能。在未来的工作中,将研究如何将文本信息进行有效提取,从而与对象特征进行精准匹配。
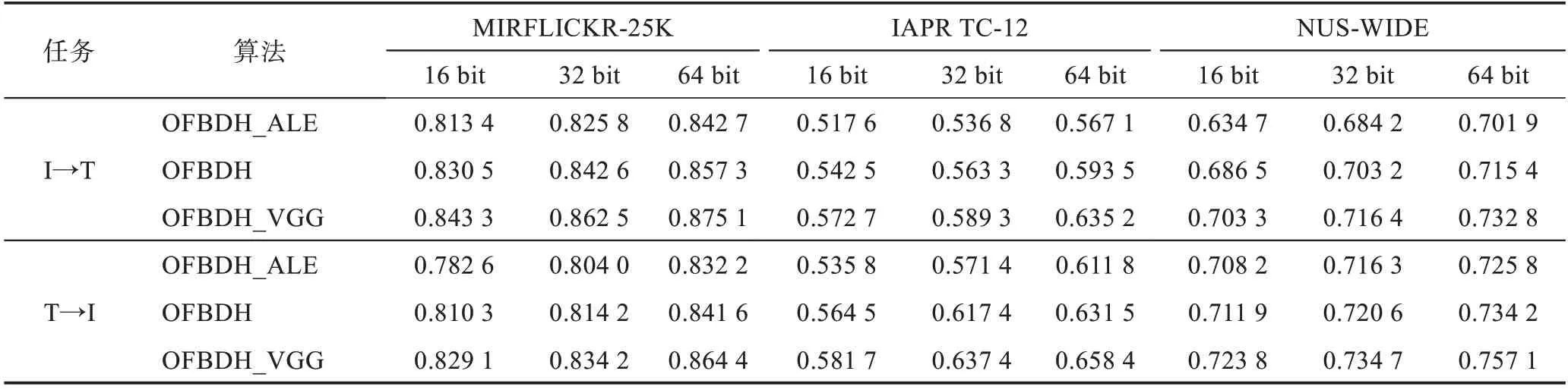
Table 2 Comparison of MAP when using different CNN表2 采用不同卷积神经网络的MAP 值比对
猜你喜欢
汽车实用技术(2022年10期)2022-06-09
汽车工程师(2021年12期)2022-01-17
电脑爱好者(2021年8期)2021-04-21
电脑爱好者(2021年1期)2021-01-13
电脑爱好者(2020年20期)2020-10-22
技术与创新管理(2020年5期)2020-10-09
商情(2020年24期)2020-06-30
科学与财富(2019年27期)2019-10-25
成长·读写月刊(2018年8期)2018-08-30
科学与财富(2017年28期)2017-10-14
