
TMS320C6678平台软件设计优化策略综述
2021-05-12 08:07:56杭州应用声学研究所徐雅南李恒光范泽亚
电子世界 2021年7期
杭州应用声学研究所 徐雅南 李恒光 范泽亚
德州仪器公司2010年推出的8核DSP芯片TMS320C6678是目前商用市场上计算性能最高的DSP之一,已在图像处理、无线电通信基站、雷达和声纳等领域得到了一定范围的应用。相比上一代被广泛应用的TS201芯片,其优点是硬件规模大、工作主频高、对外传输能力强和大容量外部存储空间,缺点是平均内存小、架构复杂、共享资源竞争激烈和调度复杂。随着芯片使用的日益频繁,如何有效优化软件架构,降低经济成本,受到了软件设计人员的广泛关注。针对该问题,提出了一系列针对TMS320C6678的编程优化策略,为实现资源利用最大化提供了技术支撑。
TMS320C6678是德州仪器公司2010年推出的8核处理芯片,理论上单核具有128Gb/s(@1GHz)的单精度计算能力,是目前商用市场上计算性能最高的DSP(Digital Signal Processer)之一,已在图像处理、无线电通信基站、雷达和声纳等领域得到广泛应用。作为上一代被广泛应用的TS201芯片的替代产品,TMS320C6678芯片的优缺点明显,其优点是硬件规模大、集成度高,工作主频高、操作数宽度大,对外传输能力强和大容量外部存储空间,缺点是平均内存小,架构复杂,共享资源竞争激烈、调度复杂以及程序复杂度高。尽管TMS320C6678(4片)的理论运算能力约是TS201(6片)的16倍,但是不合理的软件架构往往使得处理性能得不到有效发挥。针对该问题,本文提出了一系列编程优化策略,为实现资源利用最大化提供技术支持。
1 TMS320C6678简介
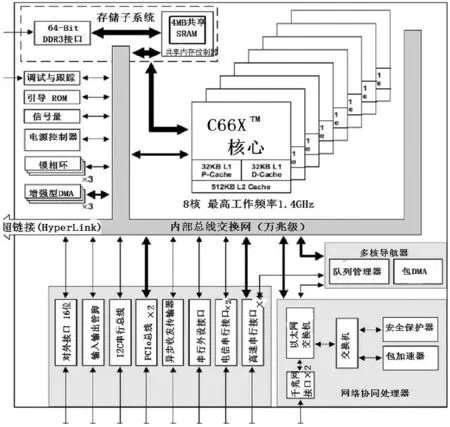
图1 C6678处理器架构示意图
TMS320C6678(以下简称C6678)是TI公司的8核高速数字信号处理器之一,支持高速定点和浮点计算,单核主频高达1GHz,拥有独立的操作系统和L2SRAM空间,支持通过GPIO响应硬件中断,外部通过EMIF和SRIO实现高速通信,核间通过消息队列和共享内存进行同步和数据共享。C6678架构图和工业用信号处理板分别如图1所示,包括:32KB一级内存(Cache,L1D,L1P),512KB二级内存(本地内存,L2)、4MB三级内存(共享内存,MSMC)和2GB DDR3外挂存储空间,3个EDMA控制器(10个通道)用于片内传输,4个SRIO快速串行输入/输出接口用于片间传输。C6678和TS201的主要参数对比见表1所示。目前工业上比较主流的C6678软件开发环境(带操作系统)主要以中电32所的锐华Rede和中科海讯的HaixunIDE为主,两者虽然风格不同,但均满足同一行业标准,核心能力和传输方式一致。
2 软件设计优化策略
2.1 基础优化策略
(1)合理使用MSMC区
C6678芯片8核共享4MB内存MSMC区别于外存DDR3,合理控制EDMA与CPU的访问方式,可以实现MSM与L2之间数据传输的零开销。建议将频繁操作的全局变量定义在MSMC,以提高运算速度。
注意,两两变量做运算时,MSMC区变量的运算速度≥分别位于MSMC和DDR3的运算速度≥DDR3区变量的运算速度,但是不合理的使用会弱化MSMC的计算性能。
(2)优先使用“向量”
建议优先使用“向量”,不建议执行单点、跨步或转置等操作,原因是C6678执行Cache刷新的基本单位为“块”,单点、跨步或转置等操作均会增加Cache开销。此外,TI官方提供的基础数学函数库包含一系列向量操作函数,可显著提高运算速度。
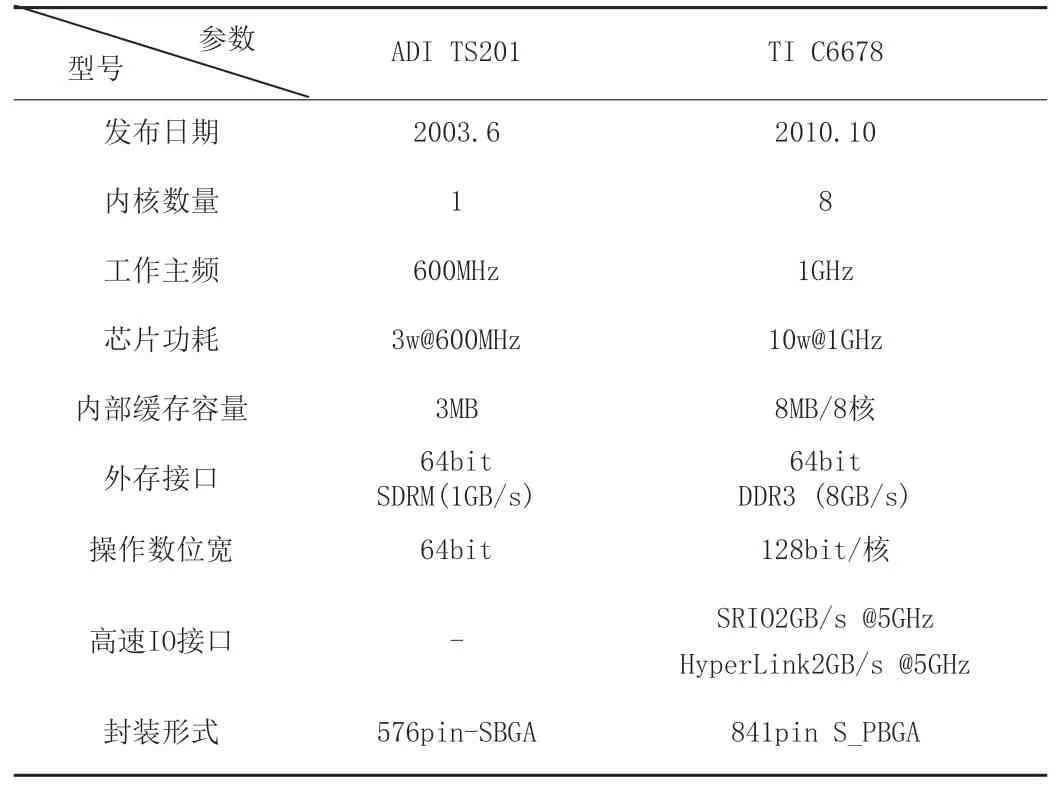
表1 C6678和TS201主要参数对比
(3)优化操作顺序
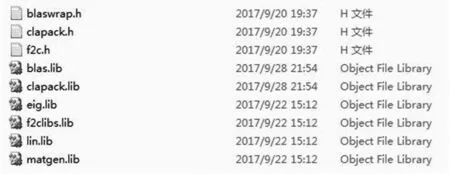
图2 CLAPACK函数库列表

图3 并行计算架构示意图
建议优化操作顺序,减少多余Cache开销。当CPU操作不同变量时,先将原Cache变量刷回原地址,再将后操作变量刷进Cache,因此,尽可能减少反复的变量切换操作可有效减少多余Cache操作。如:执行A、B、C、D求和,执行(((A+B)+C)+D)相比执行((A+B)+(C+D)),其Cache开销更少,相应地运算性能更高。
2.2 使用CLAPACK等开源数学核心库
Intel、AMD等公司针对自己的硬件处理器,Pentium、Xeon、Itanum开发了诸如BLAS和LAPACK等线性代数功能、离散傅里叶变化(DFT)以及向量超越函数(向量数学库/VML),向量统计函数(VSL)。MATLAB之所以拥有强大的矩阵运算能力,主要是使用了BLAS、LAPACK和MKL等高度优化的数学矩阵运算库。截止目前比较出名的核心数学库以OpenBLAS、LAPACK和MKL为主。其中,LAPACK提供了Fortran和C语言两个版本,本文主要是移植了一套适用C6678处理板的LAPACK的C语言版本——CLAPACK,结合编译器O2优化选项(软件排流水,删除全局共有的表达式),有效提高C6678的数学运算效率。
首先,通过开源环境下载CLAPACK,解压获得/SRC、/BALS、/F2CLIBS、/LIB、/INCLUDE、TESTING和/INSTALL目次。再根据C6678底层宏定义对CLAPCK宏定义稍作修改。最后,利用REDE等开发环境自带的交叉编译器封装形成blas.lib、clapack.lib、eig.lib、f2clibs.lib、lin.lib和matgen.lib共6项lib函数库,如图2所示。CLAPACK函数库支持多级多类型向量、矩阵运算和向量矩阵等上千种复杂运算,弥补了C6678自身高性能函数库缺乏的短板,其运算速度是普通函数运算的2到5倍。
2.3 软件架构设计
C6678是一种典型的8核并行计算处理器。以下给出2种典型的软件架构:
(1)并行计算架构。受8核共享数据总线和存储空间限制,当并线计算开销接近饱和时,8核并线计算无法将运算提高8倍(实测运算速度为6至7倍),此时建议采用如图3所示软件架构:单核作为对外数据传输模块,负责片间数据传输及片内数据共享(Cache),其余7核作为核心计算模块,负责片内并行计算并由单核汇总计算结果。由于单核同时负责内外部传输,一般建议单核启用多线程,分别负责外部数据接收、内部数据共享和结果信息发送,其中外部数据接收、内部数据共享可以共用一个线程。

图4 流水线架构示意图
(2)多核流水线架构。通过控制8核流水线访问DDR3外存,可以避开外存总线竞争,实现外存数据的全带宽读取与运算的并行,示意图如图4。
结束语:本文论述了TMS320C6678的编程优化策略,给出了通用软件设计优化手段,为实现资源利用最大化提供了技术支撑。
猜你喜欢
舰船电子对抗(2020年5期)2020-11-26 10:54:20
电子技术与软件工程(2020年16期)2020-11-25 11:41:38
电脑报(2020年34期)2020-09-12 14:03:42
当代陕西(2019年13期)2019-08-20 03:54:22
现代电子技术(2019年2期)2019-04-04 01:46:10
首都医科大学学报(2015年4期)2015-12-16 13:00:08
无机化学学报(2014年12期)2014-02-28 17:33:53
无机化学学报(2014年7期)2014-02-28 17:32:11
测绘科学与工程(2014年5期)2014-02-27 07:06:14
食品科学(2013年23期)2013-03-11 18:30:07
