
一种基于卷积自动编码器的推荐系统攻击检测方法
2021-05-10 07:14缪骞云刘学军
小型微型计算机系统 2021年5期
费 艳,缪骞云,2,刘学军
1(南京工业大学 计算机科学与技术学院,南京 211816)
2(南瑞集团有限公司(国网电力科学研究院),南京 210003)
1 引 言
基于协同过滤的推荐已经成为解决现代互联网上信息过载的有效途径之一,目前已经被广泛应用于电子商务领域.但是,协同过滤推荐系统本身所具有的高度开放性,使得恶意攻击用户极容易利用这一点,为攻击系统而注入大量的虚假用户概貌,一方面极力伪装成正常用户的邻居用户,另一方面伪造用户对于项目的虚假评分信息,试图令推荐系统有利于攻击用户,产生虚假的推荐.
目前大多托攻击检测方法都是采用人工方式来提取用户特征,认为攻击概貌与真实概貌在评分方式上有着显著的差异,并将其作为特征属性来区分出攻击用户并剔除,但是,人工特征往往有很大局限性:1)攻击者为了避免被检测出来,往往会模仿真实用户的评分行为,使得人工特征的区分能力降低;2)不同的攻击类型往往需要采用不同的特征指标,而构建合适的特征指标往往是非常困难的,而且,也需要较高的知识成本.在混合攻击、类型未知的攻击中,构建人工特征就更为困难,但是,特征工程的质量却很大程度上决定了检测性能.因此,采用自动、半自动策略提取用户特征已经引起人们的关注.
深度神经网络具有非常强的计算能力以及非线性映射等优点,在手写数字识别、模式识别等分类问题中有着广泛的应用,同时也适用于多变的攻击检测环境.因此,本文引入卷积自动编码器从原始的评分矩阵中自动提取特征,降低分析和设计特征指标的难度,尤其适用于混合攻击、类型未知的攻击.实际上,如果能够人工设计出有效的特征检测指标,对于提高检测性能会产生非常大的作用.因此,本文将自动提取特征和人工设计特征指标相结合,以提高攻击检测的性能.人工设计的特征指标只考虑通用的检测指标,不同攻击类型的特征指标由评分矩阵自动提取,提高了算法的鲁棒性.
本节将原始用户评分矩阵与人工设计的特征指标矩阵合并为新的数据矩阵,利用卷积自动编码器(CAE)进行特征提取,通过全连接层的分类来实现攻击检测.本节的主要工作可归纳如下:
1)提出了一种自动特征提取和人工设计特征相结合的攻击检测特征构造方法;
2)将自动编码器与卷积神经网络相结合,以卷积神经网络的卷积操作完成自动编码器的编码和解码功能,形成卷积自动编码器神经网络结构,实现特征自动提取和有效攻击检测的功能.
2 相关工作
结合人工提取的特征属性在传统的托攻击检测方法中,Williams[1]等学者提出了一种基于逆向工程攻击模型的属性生成方法,结合RDMA等六种通用特征及KNN、SVM、C4.5 3种分类方法实现托攻击检测.论文验证了这些属性的组合优势以及分类器的选择对提高推荐系统的鲁棒性的影响.Wu[2,3]等学者基于Williams等学者提出的特征,利用期望最大化的方法对特征进行筛选,同时针对筛选的特征利用贝叶斯分类器实现托攻击的检测.彭飞[4]等学者提出KCI兴趣峰度系数这一特征属性用来描述用户兴趣集中程度,并与已有的用户特征属性相结合,提出一种特征子集的无监督检测方法.李文涛[5]等人提出区分正常用户和攻击用户基于流行度的分类特征属性MUD,RUD,QUD,得到基于流行度的托攻击检测方法.以上这些方法都需要人工从用户的评分或者项目的流行度等方面,使用不同的数据分析方法特区特征,这些方法普适性不强,因此面对新的攻击类型时会出现不太理想的检测效果.
深度神经网络学习技术近年来在自然语言处理、计算机视觉、个性化推荐等领域都取得了巨大成功[6].目前,已有学者将这些技术应用到推荐系统的攻击检测领域.Tong等人[7]等人提出了一种基于卷积神经网络和社会感知网络(SAN)的新方法CNN-SAD,由于所实现的深层特性能够比人工设计的特征更准确地描述用户的评分行为,该方法能够更有效地检测托攻击;Hao等人[8]从用户评分矩阵、用户邻接矩阵等多个角度分析用户的行为,利用利用堆叠的去噪自编码器自动提取用户特征,在主成分分析的基础上对多视图提取的特征进行有效的组合,利用SVM作为分类器生成检测结果;Xu等人[9]针对诽谤性用户在评分和评论之间给出相反评价的行为,设计了双注意递归神经网络(HDAN),利用改进的GRU网络来计算评论是积极或是消极,在此基础上提出了联合过滤的方法捕捉评分与评论之间的差距从而检测出攻击.郝耀军[10]等人基于用户评分项目的时间偏好信息,提出了一种利用深度稀疏自编码器自动提取特征的托攻击集成检测方法.但是,总的来说,这方面的工作还刚刚开始.
3 基于CAE推荐系统托攻击检测方法
本节详细介绍了基于卷积自编码器的推荐系统托攻击检测方法(A Attack Detection Method based on Convolutional Autoencoder,简写ADM-CAE),包括特征的提取、模型的构建和算法的描述等.ADM-CAE攻击检测的框架结构如图1所示,主要分为训练学习以及预测分类两部分,训练学习主要包括如下步骤:注入攻击后,首先为了捕捉托攻击用户的潜在属性特征以便于更好地构造分类模型,本文首先将电影按照类型分类,将相同类型的电影分到一起,这样分到同一个簇集的操作便于后续捕捉数据的二维相关性,然后对分类好的数据进行分析,参考现有的用户评分属性特征从多个角度提取不同用户的属性特征;其次将提取到的用户属性以特征矩阵的形式,与原评分矩阵一起合并为最终的数据矩阵,类似于一个二维图像的输入,将得到的数据矩阵输入卷积自编码器托攻击检测模型,完成正常用户与虚假用户的分类操作.本节的最后部分会给出本文所使用的ADM-CAE算法的卷积自编码器结构和算法的详细描述.
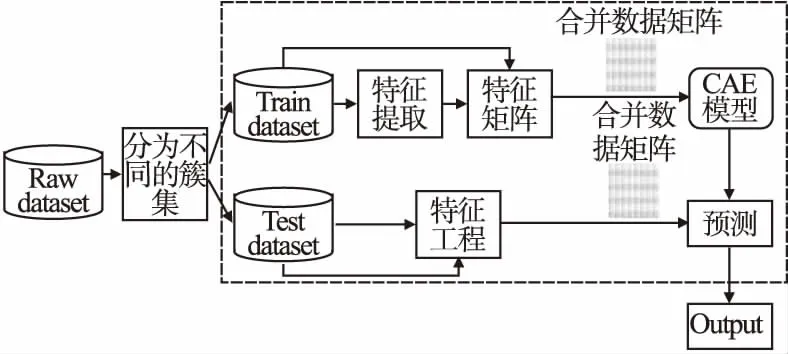
图1 算法整体框架
3.1 特征选取
在推荐系统领域,庞大的用户行为数据可以用来描绘用户,例如用户对某项电影的评分通常可以反应用户对这部电影的喜好.但是一个用户的行为数据可能涉及各种各样成千上万条信息,同时面对极其稀疏的用户高维数据,处理起来也十分复杂,这种情况加大了数据分析处理的难度,而特征提取(Feature Extration)技术的出现就恰恰缓解了这样的现状,它能够通过变换将原始数据转换为一系列具有统计意义的用户特征,这些特征可以用来区分正常用户和攻击用户.而正常用户和攻击用户的差异性通常可以通过评分反映出来,本文根据相关研究者们提出的人工特征,从用户之间的评分差异性角度,分析原始评分矩阵,提取5个通用的用户属性特性[11],包括平均评分偏离度(RDMA)、评分向量长度方差(LengthVar)、加权平均评分偏离度(WDMA)、加权评分偏离度(WDA),以及与其他用户的评分偏离度(DAOU),进一步结合原始评分矩阵,采用卷积自编码器结构实现攻击检测.
通过统计用户评分数据,可以得到上述5种通用特征属性.将5种通用特征属性与评分矩阵组合,即在用户-项目评分矩阵增加5列,每列表示一个通用特征属性.为了后续更好地发挥卷积神经网络的作用,依据项目类型的不同,将相同类型的项目划分到相同的簇集中,将原始的用户-项目评分矩阵按簇重新排序,相同簇集的项目列相邻.生成最终的数据矩阵用于神经网络的输入,特征矩阵以及最终的数据矩阵的构造过程如图2所示.

图2 特征矩阵以及最终数据矩阵构造过程
3.2 CAE模型结构和算法描述
在卷积神经网络中,卷积层是核心,同样也是卷积自编码器的核心.网络对输入数据利用卷积核执行卷积计算,提取攻击特征.卷积核相当于一个滤波器,卷积计算就是通过将卷积核作用于输入数据并沿着宽度方向及高度方向滑动,每次滑动都计算卷积核与其覆盖部分的内积.在本文提出的模型中,用户useru对电影itemi的评分矩阵表示为R,rui表达的是用户u对项目i的评分,则rui∈R,特征矩阵用Q表示,则R、Q合并后的数据矩阵为T,大小设为(H,W),每次卷积同时还需要以下超参数:filter的大小f1×f2,filter数量为k,步幅s,zero Padding的填充数为p,矩阵T作为输入会首先经过卷积层的特征提取,转换为(OH,OW)大小,则:
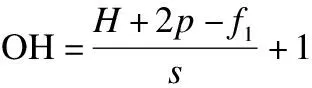
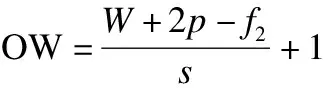
(1)
假设有k个卷积核Wk,则输入x经过卷积后形成的第k个feature maphk为:
hk=F(x⊗Wk+bk)
(2)
其中,x代表输入,⊗符号表示卷积计算,bk是偏置,是一个实数.本文的零填充p设为1,步幅s设为1,则经过公式计算后,输出的feature maphk的大小OH=H,OW=W,则发现可通过卷积实现自动编码器尺寸无损的特征提取效果.卷积操作后的feature map会受到下面一层激励层的激励作用.该层是一种非线性的激活函数,通过在模型中引入非线性因素,解决了线性模型表达能力不够的的问题,激活函数能够将特征保留并映射到下一层.通常的激活函数有Sigmoid函数函数,Relu函数,以及Tanh函数,如式(3)所示:
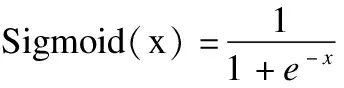
Relu(x)=max(0,x)
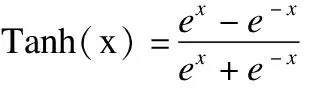
(3)
本文所选用的激活函数是Relu函数,令pk表示第k个经过卷积操作后的特征图的激活结果,即:
pk=max(0,x×Wk+bk)
(4)
编码部分为3层卷积层以及2层激励函数层的叠加.经过编码部分一层层地卷积提取特征以及激活函数的作用后,卷积自编码器的编码部分就结束.得到的数据特征的间接表示输入解码部分.首先进入解码器进行反卷积操作,则经过第k′个卷积核反卷积后的feature maphk′可表示为:
(5)
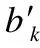
(6)
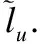
loss=-∑xm(x)logq(x)
(7)
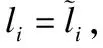
网络结构如图3所示.
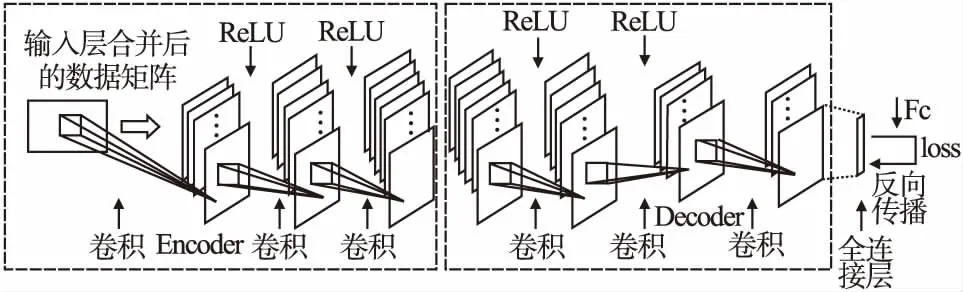
图3 CAE网络结构
ADM-CAE托攻击检测算法具体描述如下:
算法.托攻击检测算法(ADM-CAE)
输入:用户评分矩阵R;特征矩阵Q;两者合并后的数据矩阵T;所有的输入记作x.
输出:攻击检测算法的召回率(Recall)、准确率(Precision)
过程:
1.data preprocessing
2.for e<=epoch do
3. for eachuserido
4.hk=F(x⊗Wk+bk)//卷积操作
5.pk=max(0,x*Wk+bk)//激活操作
……
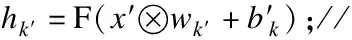
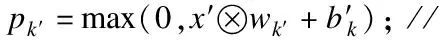
8. loss=-∑xm(x)logq(x)
9. 计算损失并反向传播更新网络权值,优化模型
10. end for
11.end for
第2步的e代表设置的迭代次数,第4步和第5步是模型的编码阶段,卷积操作的目的是提取特征并通过激活函数的作用加入非线性因素,从而提高模型的表达能力.中间省略了一部分的卷积操作以及激活操作.第6步和第7步是模型的解码阶段,反卷积还原数据,第8步是计算损失,通过反向传播算法优化模型,不断地参数更新优化,直至迭代数不满足迭代条件.最终经过不同情况下实验的对比,分析召回率(Recall)以及准确率(Precision)的差异评价该模型.
4 实验与评价
4.1 实验数据集
本次实验采用的数据集为MovieLens100k(1)https://grouplens.org/datasets/movielens/数据集,包含了943个不同用户对1682部不同电影的评分,评分区间为[1,5],分数由低到高分别表示用户对电影的喜爱程度的不同.其中,既包括普通的用户如一般的大学生或者上班族等,也包括专业的影评用户,且每个用户在这1682部电影中至少有20条评分记录,数据真实可靠,所以我们假定这数据集中的用户全部为真实用户.
4.2 实验配置
实验中数据的处理、特征的提取、托攻击检测模型的训练以及测试过程均采用Python环境来实现.具体硬件环境为:i7-6800k,16G DDR4,单路1080ti;软件环境为Window10,pytorch1.0,Cuda9.0,Cudnn7.0.
在实验中,为了确定CAE的结构,对卷积核的大小,卷积层层数以及步幅等大小进行了多次试验对比,最终确定设置ADM-CAE托攻击检测模型的参数为:filter为大小始终是3×1的一维卷积核,每一层的filter数量为分别设置为1->16->32->64->32->16->8,步幅s始终为1,zero Padding的填充数p也始终为1.实验中,为了验证该算法检测能力的有效性,将前期经过数据预处理后的数据矩阵T在输入CAE模型前划分为训练集与测试集,其之比为7∶3,利用训练集训练好的CAE模型作用在测试集上,并输出测试集的检测结果.
在机器学习、推荐系统或者数据挖掘完成建模后一般会需要对模型的效果进行评价,目前常常采用的评价指标有准确率(Precision)、召回率(Recall)、F值(F-Measure)等.本节采用召回率以及准确率作为评价指标.
4.3 实验结果分析
4.3.1 精确性和有效性分析
在MovieLen100k的数据集上,通过比较ADM-CAE算法在对数据集注入不同攻击规模和不同填充规模下的检测能力来评价模型性能,结果如图4和图5所示.
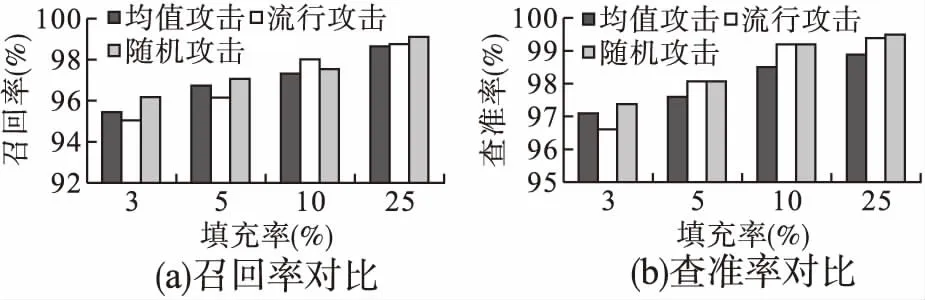
图4 攻击规模为5%时的3种攻击对比
图4(a)和图4(b)为ADM-CAE托攻击检测模型采用注入攻击规模为5%的同时,分别注入不同填充率(3%、5%、10%和25%)的均值攻击、流行攻击以及随机攻击的攻击检测结果.以准确率和召回率为评价准则,可以看出ADM-CAE算法随着攻击概貌的填充规模的增大,召回率和准确率会逐渐提高,检测效果逐渐增强.我们也可以看出较高的填充率更容易检测出攻击行为.
图5(a)和图5(b)为ADM-CAE算法对不同攻击规模的3种攻击在两种评价标准下检测效果的对比.在一般的系统中,注入3%的的攻击已经很不容易,有些攻击的攻击成本更是高.这里选择的攻击强度分别为1%、2%、5%以及10%,填充规模选择5%.可以看出在较低的攻击强度下,该算法依然具有较高的检测能力,这也验证了算法的有效性.
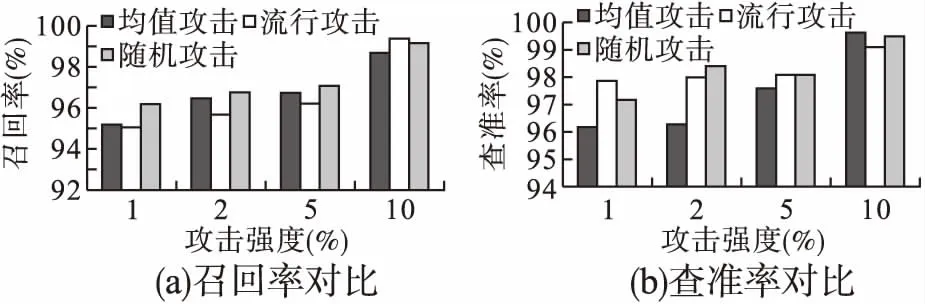
图5 填充率为5%时的3种攻击对比
相对于流行攻击和均值攻击,随机攻击更容易被识别,这是因为随机攻击所需的知识成本最低,知识成本越低越容易检测.
4.3.2 与多种攻击检测算法比较
为了更好地体现出本文提出的检测算法的优越性,决定与以下算法进行对比:
1)DSAE-EDM[10]一种深度学习托攻击集成检测方法,该方法则直接消除了本文前期所采用的的传统的人工特征工程,采用深度学习技术深度自动编码器自动提取特征以达到攻击检测的效果.
2)PCA VarSelect[12,13]作为典型的无监督托攻击检测算法,该算法可自动构建用户特征,该方法通过PLSA找到具有相似偏好的用户群体,结合PCA VarSelect从多元统计学角度重新描述评分矩阵,这种方法的泛用性很好,但是需要预先知道攻击规模.
实验参数设置如下:注入的攻击规模分别是1%、2%、5%和10%;注入的填充规模分别是1%、3%、5%、10%和25%;攻击类型分别是流行攻击和均值攻击.以准确率为评价指标,实验结果如表1和表2所示.
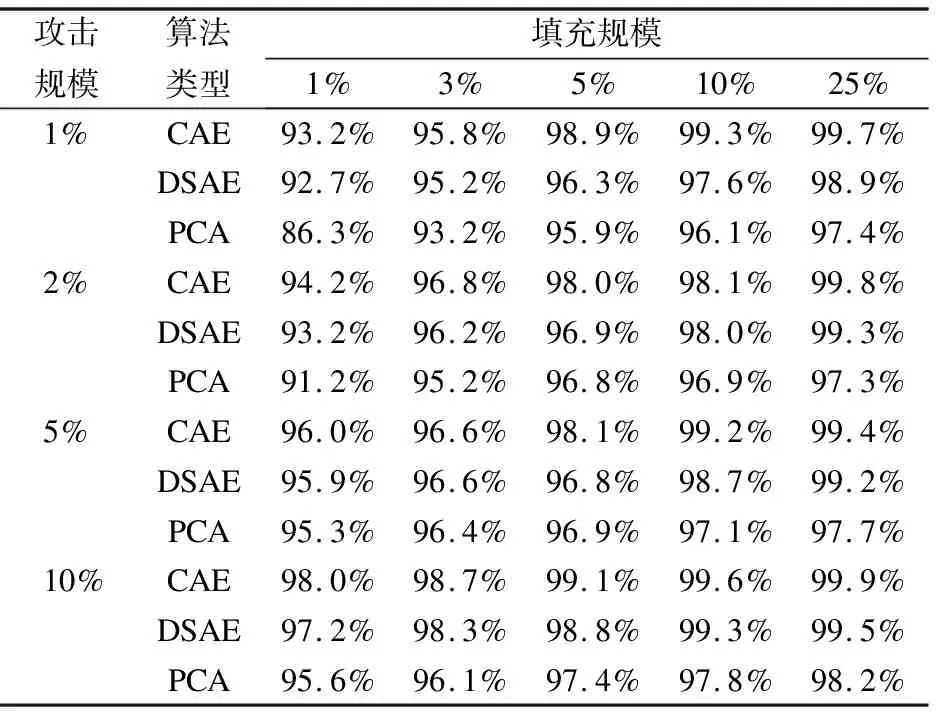
表1 流行攻击对比
通过表1和表2可以看出,ADM-CAE算法的攻击检测效果优于PCA VarSelect方法,这是因为传统的攻击检测算法PCA VarSelect对数据的降维是线性的,在恢复数据的时候会有一定程度的失真,而ADM-CAE是非线性的,信息丢失得更少,特征学习得效果也更好,所以取得更优的攻击检测的效果.且与DSAE-EDM算法相比,无论是哪种攻击,本文的检测算法都比DSAE-EDM表现地更有优势,这是因为ADM-CAE算法在前期添加了DSAE-EDM算法所没有的传统的人工特征工程,达到了强化数据特征,增加数据分类的准确性的效果,再与深度学习技术卷积自编码器的自动学习特征相结合,不但使得人工特征在面对不同的攻击时所表现出来的普适性不强的特征可以忽略不计,更是增加了攻击识别的准确性.
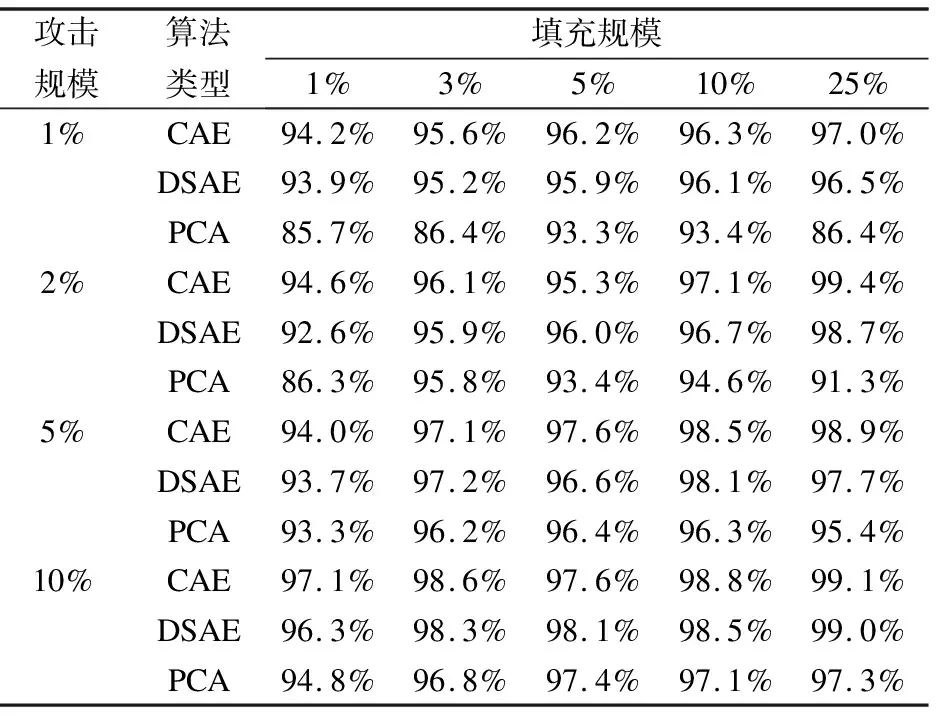
表2 均值攻击对比
4.3.3 ADM-CAE中反卷积层的效果
此外,为了理解与评估ADM-CAE中的反卷积层给实验带来的效果与影响,本文在有反卷积层作用和无反卷积层的作用下,在攻击规模为5%,填充规模为5%的情况下进行了对比实验,图6给出了在随机攻击,均值攻击以及流行攻击3种攻击下的Precision值的对比情况.
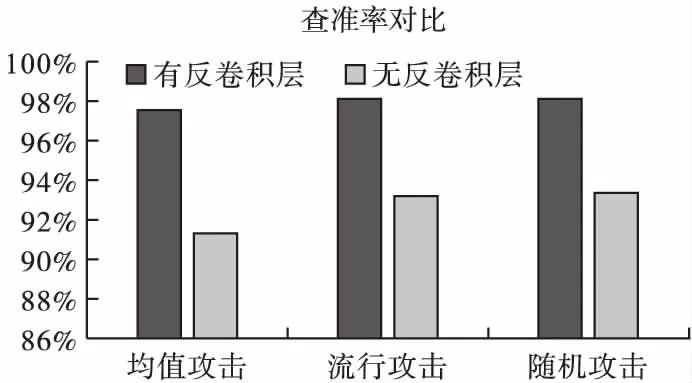
图6 ADM-CAE在有无反卷积层作用下的查准率对比
从图6可以看出,在3种不同类型的攻击检测中,没有反卷积层的ADM-CAE查准率位于92%-94%之间,而有反卷积层的ADM-CAE查准率位于97%-98%之间,没有反卷积层的检测效果并没有在有反卷积层进一步学习特征的作用下效果显著.由此可见反卷积层在ADM-CAE中的重要作用,它可以进一步学习特征,提高整体的攻击检测能力.
5 小 结
本文结合使用了传统的人工特征提取和深度神经网络方法,利用RDMA等属性首先分析出用户评分的显著特征,得到用户特征属性数据集,再结合原始的评分构造新的数据矩阵作为数据集输入.利用卷积层代替全连接层,完成自动编码器的编码以及解码功能,为了实现自动编码器的输出数据矩阵的大小与输入相同的目标,从卷积层的卷积核尺寸、步幅、填充以及激活函数等方面选择恰当的CAE结构,结合了卷积神经网络权值共享以及自动编码器无监督快速提取的优点,最后通过全连接层实现二分类,实现攻击检测.
猜你喜欢
农业工程学报(2022年12期)2022-09-09
农业工程学报(2022年12期)2022-09-09
计算技术与自动化(2022年1期)2022-04-15
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
数字技术与应用(2021年1期)2021-03-24
读与写·教育教学版(2017年10期)2017-11-10
科技与创新(2017年5期)2017-03-28
南都周刊(2015年4期)2015-09-10
南都周刊(2015年3期)2015-09-10
