
倾向性评分匹配法在非随机对照研究中的应用*
2021-05-08 05:55复旦大学公共卫生学院流行病学教研室公共卫生安全教育部重点实验室200032施婷婷刘振球袁黄波吴学福吴明山张铁军
中国卫生统计 2021年2期
复旦大学公共卫生学院流行病学教研室,公共卫生安全教育部重点实验室(200032) 施婷婷 刘振球 袁黄波 吴学福 吴明山 张铁军
随机对照试验(randomized controlled trial,RCT)是最理想的金标准设计方案[1]。但在实际工作中,由于伦理学等因素的影响以及研究设计的理想性,RCT的应用受限。而非随机对照研究(包括观察性研究和非随机试验研究)的研究对象所具有的各种特征与真实世界研究(real world study,RWS)结果更为接近,实用性更广。但由于无法随机化,如何处理混杂偏倚成为此类研究亟待解决的难题[2]。
传统的控制混杂偏倚的方法包括在研究设计阶段进行配比,或在数据分析阶段按照混杂因素分层,或采用多因素数学模型进行调整等。但是当混杂变量较多或处理组与对照组的某些变量差异较大时,传统方法便不再适用,倾向性评分(propensity score,PS)法由此应运而生,广泛应用于医学、经济学、社会学等多个领域的非随机对照研究中[3-4]。
方 法
1.倾向性评分原理与方法
1983年,Rosenbaum和Rubin首次提出倾向性评分这一概念,他们将PS定义为被研究的个体在控制可观测到的混杂变量(confounding variables)的情况下,通过将混杂变量纳入logistic回归模型来产生一个预测个体受到自变量影响的概率[5-6]。PS的基本原理是指在一定可观察协变量(Xi)的条件下,研究对象i(i=1,2,…,n)被分配到特定处理组(Zi=1)或对照组(Zi=0)的条件概率。因此,第i个研究对象被分配到处理组的概率可以表示为:e(xi)=Pr(Zi=1|Xi=xi),若给定的特征变量(xi)与分组变量(Zi)是相互独立的,则:
其中,xi为个体i的协变量,e(xi)为个体i被分入处理组的概率,也叫做倾向性评分值[3]。
倾向性评分是一个平衡评分,在倾向评分的条件下,观察到的基线协变量在处理组和对照组之间的分布是相似的[2],从而排除混杂变量的影响,获取“净效应”。但倾向性评分法本身不能控制混杂,而是通过匹配、分层、利用回归模型直接调整混杂变量以及逆概率加权等方式,不同程度地提高两组间的可比性,削弱或平衡协变量对所估计效应的影响,达到“类随机化”的效果[6]。其中,倾向性评分匹配法在分析和结果的呈现及解释方面比较简单,并且平衡结果可靠[7],因而越来越多地应用于非随机对照研究中。倾向性评分匹配是通过多变量logistic回归模型,根据众多基线协变量对处理组与对照组中PS值相同或相近的研究对象进行匹配,理论上,匹配后的两组研究对象在各个特征变量的分布趋于均衡,从而削弱或抵消混杂因素的分布不均衡对研究结果的干扰[8]。
2.倾向性评分匹配常用匹配方法
(1)最近邻配比法(nearest-neighbor matching)
最近邻配比法是PSM最常用的一种匹配方法,具体方法是:首先将两组研究对象分开,根据协变量计算PS值;然后,依据PS值大小分别对两组研究对象进行排序,从处理组中依次选出1个研究对象,从对照组中找出1个(或多个)与处理组个体倾向评分值最相近的个体作为匹配对象[12]。从源人群中移去匹配成功的对子,再依次进行处理组剩余研究对象的匹配过程。最邻近匹配法按处理组研究对象进行匹配,所有个体都可以成功匹配,可以充分利用处理组信息,但如果配对组与处理组的PS值分布差距较大,将影响匹配质量,降低研究精确度[13]。
(2)马氏矩阵配比法(Mahalanobis metric matching)
马氏矩阵配比法是将评分值作为一个变量同其他重点平衡的变量一起,利用矩阵计算两个研究对象的马氏距离的一种匹配办法[14]。马氏距离是由印度统计学家Mahalanobis提出的,表示m维空间中2点间的协方差距离,不受量纲的影响,还可以排除变量间相关性的干扰。
(3)卡钳匹配(caliper matching)
卡钳值是指当两组研究对象根据PS值进行匹配时所允许的误差范围,卡钳匹配是在最近邻匹配法的基础上应用的匹配法。该方法解决了最近邻匹配法在配对组与处理组的PS值分布差距较大时难以保证匹配质量的问题,但也可能使部分观察对象落在卡钳值范围外而被剔除,导致无法充分有效利用数据,产生抽样偏倚[4]。
实例分析
倾向性评分匹配的实施可以通过R软件的MatchIt程序包实现[10]。数据选择R软件内置的由Dehejia和Wahba(1999)创建的数据集“lalonde”。该数据集是用于评估倾向评分匹配的经典数据集,包括研究对象共614例(处理组185例,对照组429例),其分组变量为treat(是否接受培训),定义“1”为处理组,“0”为对照组;基线协变量包括age(年龄),educ(教育年限),black(是否为黑人)等共9个协变量。
实施倾向性评分匹配的具体步骤如下:
(1)根据临床经验或实际要求,以处理因素(分组变量)作为因变量(y),混杂因素作为自变量(x)来构建logit或probit回归模型;
(2)拟合回归模型的参数;
(3)根据拟合的回归模型计算每个研究对象的倾向性评分值(即条件概率);
(4)以倾向性评分为依据,通过相应匹配方法来均衡混杂因素(协变量)在两组的分布[9]。
使用logistic回归对前述9个基线变量的匹配前后情况进行回归分析[11],结果见表1。在匹配前,仅变量“age”、“re75”(1975年收入)在两组间均衡,其他协变量在两组间均不均衡。通过最邻近匹配法进行匹配,匹配比例为1∶1,结果显示,仅“black”变量未能在两组间达到均衡。样本匹配前后均衡性检验及匹配效果见图1-3。图1为倾向性评分分布QQ图,表示处理组与对照组间变量“age”、“educ”、“black”的PS分布,可看出单个变量匹配前后的均衡情况,如“educ”变量在匹配后更接近正态分布,说明匹配效果较好;图2为倾向性评分分布抖点图,其中点的位置表示个体的得分情况,匹配后处理组与对照组点的分布相似,表示两组间PS值分布均衡;图3为倾向性评分分布直方图,表示处理组与对照组间匹配前后PS值的分布,可以看出匹配前两组间PS值分布差异较大,匹配后的对照组PS值分布更接近对照组。以上结果的R软件实现过程见附录。
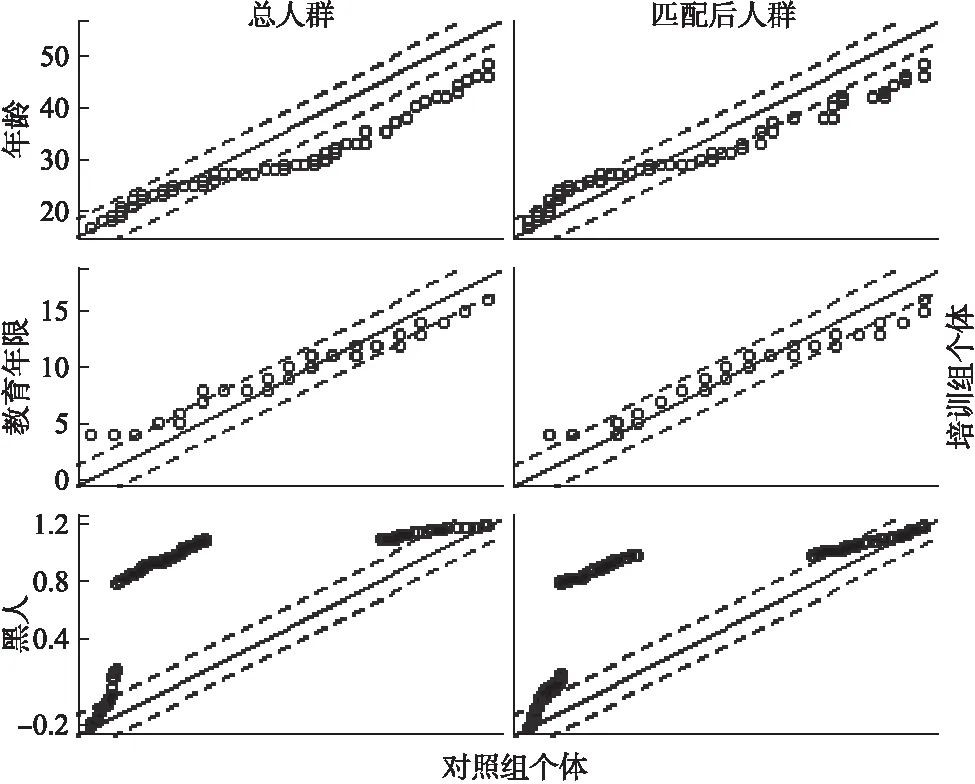
图1 倾向性评分分布QQ图

图2 倾向性评分分布抖点图
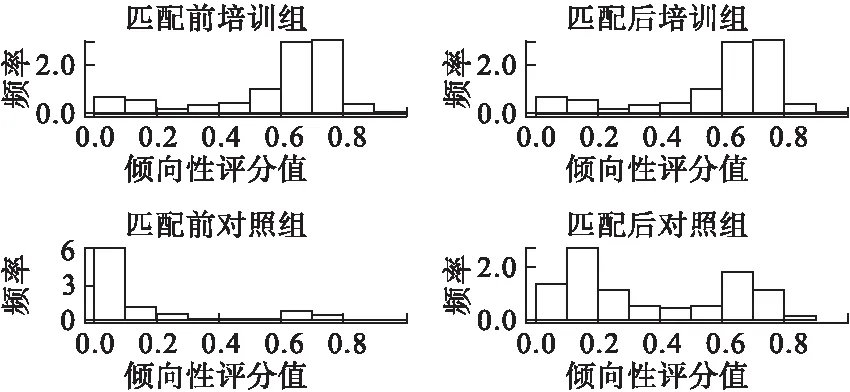
图3 倾向性评分分布直方图
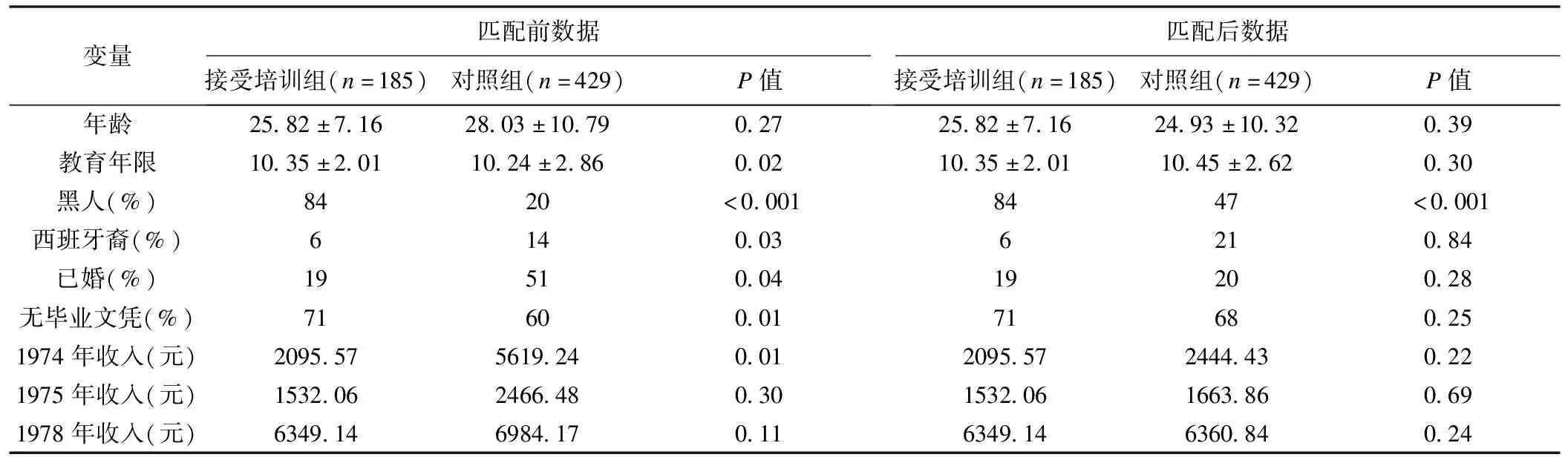
表1 倾向性评分匹配前后研究对象基线特征情况分布
讨 论
倾向性评分匹配法作为一种均衡基线混杂因素的半参数方法,在非随机对照研究中的应用越来越广泛,常用于处理组研究对象较少且对照组样本量远大于处理组的研究中。本研究选取R软件内置经典数据集“lalonde”,通过构建logistic回归模型将9个协变量“降维”转化为倾向性评分值,采用1∶1匹配的最邻近匹配法从对照组中选取与处理组可比性更佳的研究对象。结果表明,经匹配后,两组间“educ”(教育年限)等5个基线协变量的分布差异不再具有统计学意义,两组之间具有较好的均衡可比性。倾向性评分匹配法可以使研究设计阶段无法实现随机化的非随机对照研究获得“类随机化”的效果,也可以降低协变量较多带来的数据分析难度,这对于公共卫生领域中基于人群的研究具有较好的应用前景,在除医学外的其他领域也可发挥独特的作用。
但是,倾向性评分匹配也有限制因素。对于样本量较小的研究,倾向性评分匹配法便无法解决两组之间协变量失衡的问题,因而不再适用。当存在重要混杂因素无法测量或者未知时,PSM法也难以应用。在匹配过程中,处理组与对照组间的倾向性评分重叠范围常称为“共同支持域”(common support region),“共同支持域”的大小是影响匹配方法估计效果的重要因素[15]。PSM根据重叠范围剔除对照组个体,会丢失部分观测值,导致剩下样本的代表性减弱。若期望达到高质量的匹配效果,则需要较大的样本量来产生较大的PS值范围。只有当不存在未观测到的混杂因素且两组共同支持域够大时,才能保证PSM结果的正确性。此外,PSM多应用于结局为分类变量研究,如果存在缺失值,倾向性评分同样无法处理。
倾向性评分匹配有多种匹配方法,每种方法都有各自的优缺点,在实际应用中,研究者一定要根据样本数据的情况选择适合的方法,科学运用倾向性评分匹配法,才能有效控制混杂因素,提高研究结果的准确性。
猜你喜欢
湖南税务高等专科学校学报(2021年4期)2021-08-30
有色金属(矿山部分)(2021年4期)2021-08-30
科学(2020年5期)2020-11-26
中国惯性技术学报(2019年3期)2019-10-15
意林(2018年3期)2018-03-02
舰船电子对抗(2016年5期)2016-12-13
厦门理工学院学报(2016年1期)2016-12-01
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
新闻研究导刊(2015年17期)2015-12-25
语言与翻译(2015年4期)2015-07-18
