
基于三种回归器和VotingRegressor优化Adaboost的血糖集成预测*
2021-05-08 07:49都承华龚谊承张冬阳
中国卫生统计 2021年2期
都承华 龚谊承,2△ 张冬阳
【提 要】 目的 透过众多的医学特征更准确地预测疾病指标,比如血糖值。方法 利用VotingRegressor优化Adaboost,将三种精度较高的学习器进行两种集成学习。其中,模型1是基于Adaboost视角集成三种精度较高的学习器(GBDT、KRR和SVR);模型2在模型1的基础上引入VotingRegressor算法优化Adaboost得到Ada-VotingRegressor模型。结果 以血糖值的预测为算例,模型1的(均方误差,预测时间)在训练集和测试集分别为(0.006748,43059.072s)和(0.006826,32.123s);模型2的(均方误差,预测时间)在训练集和测试集分别为(0.005256,306.688 s)和(0.005234,1.023 s)。结论 基于VotingRegressor优化Adaboost的模型2具有较高的预测精度和效率。
合理运用一些统计方法对疾病指标进行预测,有利于疾病的预防和控制,对我国人民群众整体的身体素质水平的提高具有重要贡献。在国内,糖尿病从十年前开始,一直高居国人十大死因第四位,到近期,因糖尿病诱发相关病变,占总死亡人数约8%,说明糖尿病已长期严重威胁国人健康与生命[1-3]。血糖浓度是反映病情状况的一个重要指标,本文拟采用Adaboost集成方法对血糖浓度进行预测,试图找到更加简单、高效的血糖预测方法。
资料与方法
1.资料来源
血糖数据来源于2017年天池精准医疗大赛(人工智能辅助糖尿病遗传风险预测),由阿里云和青梧桐健康科技有限公司提供。
2.研究方法
(1)预测分析
模型1基于Adaboost视角集成GBDT、KRR和SVR三种精度较高的基础回归器(其中KRR、SVR结合GridSearchCV方法进行调参,为了简洁,将第i个基础回归器(basic regressor)简称为bri(br1=svr,br2=gbdt,br3=krr);模型2在模型1的基础上引入可以将不同学习器更好融合的VotingRegressor算法优化Adaboost得到Ada-VotingRegressor模型。两个模型均采用Adaboost R2回归算法。
模型1 集成流程:(1)输入训练样本和迭代次数K,初始化样本权重,分别对基础回归器使用初始化权重进行训练,得到弱学习器G(bri)k(xi)。(2)计算训练集上最大误差E(bri)K,计算每个样本的相对误差e(bri)ki,弱学习器系数α(bri)k。(3)更新样本的权重分布D(bri)k,输出强学习器f(x)。
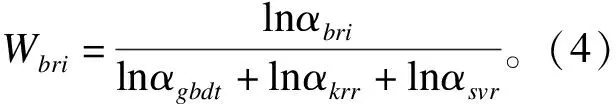
输出最终模型:
(2)缺失值处理:先将整个数据集中缺失数据达80%的指标进行剔除,量化定性数据和对数据标准化处理,再将其余的缺失数据由平均值代替。
结 果
1.集成模型1
为了确定最优的迭代次数,我们进行了大量的实验。表1为基于GBDT、KRR和SVR三种算法的Adaboost集成迭代次数实验结果。
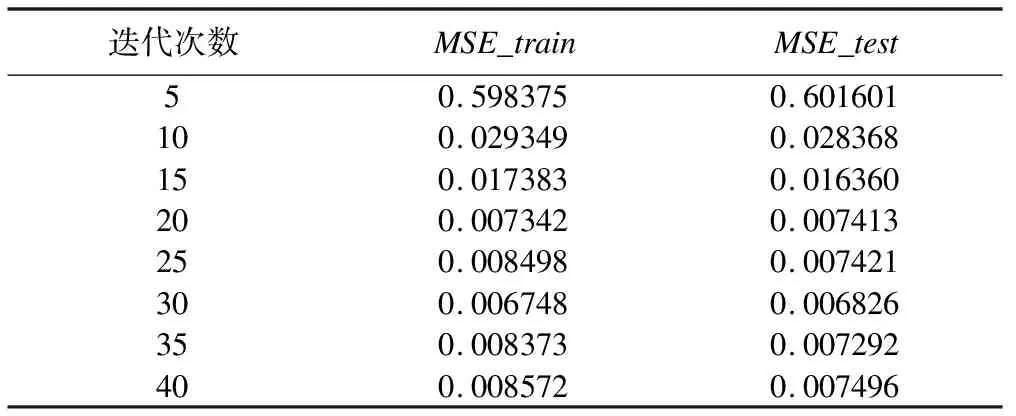
表1 Adaboost集成迭代次数实验结果
根据表1可知,随着迭代次数的增加,模型的训练集和测试集的MSE慢慢下降,当迭代次数为30 时,无论是训练集还是测试集MSE均达到最小,而后随着迭代次数增加,模型的MSE慢慢上升,因此最终选定模型1的迭代次数为30 次。最后我们做出迭代次数为30的模型1在训练集上和测试集上的预测图,如图1所示。
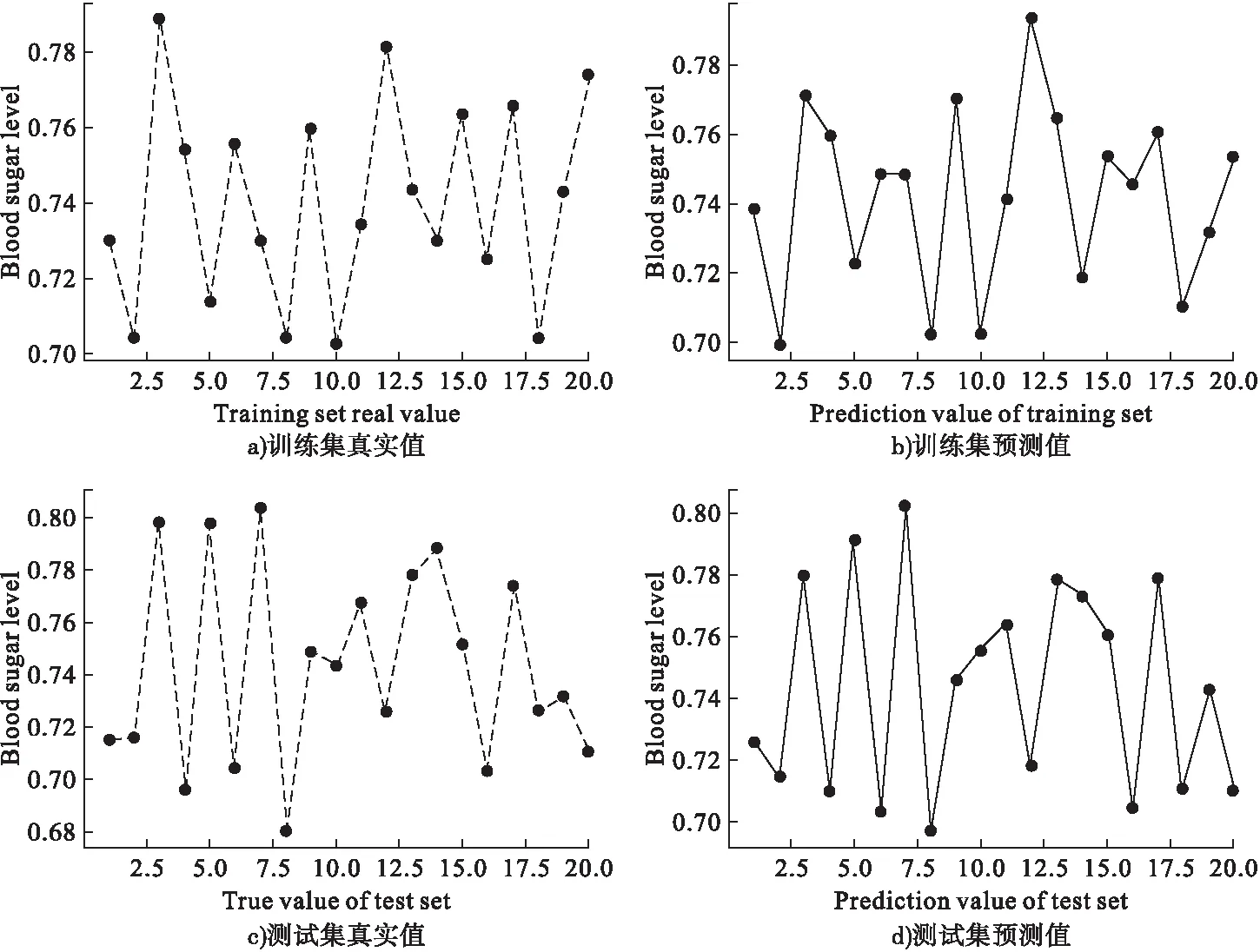
图1 模型1训练集和测试集预测图
图1中,实线表示血糖的预测值Y*,虚线表示血糖的真实值Y。其中,模型1训练集的均方误差为0.006748,拟合时间为43059.072s,测试集的均方误差为0.006826,模型预测时间为32.123s。
2.集成模型2
为了更加清楚地了解模型2的预测效果,我们依次做出模型2的血糖预测模型、预测值和学习曲线图。
首先,输出模型2在训练集上的学习出的预测模型。
f(x)=0.28785404model(krr)+0.3110837model(svr)+0.40106226model(gbdt)
(1)
接着,做出模型2在训练集和测试集上的血糖预测图,如图2所示。
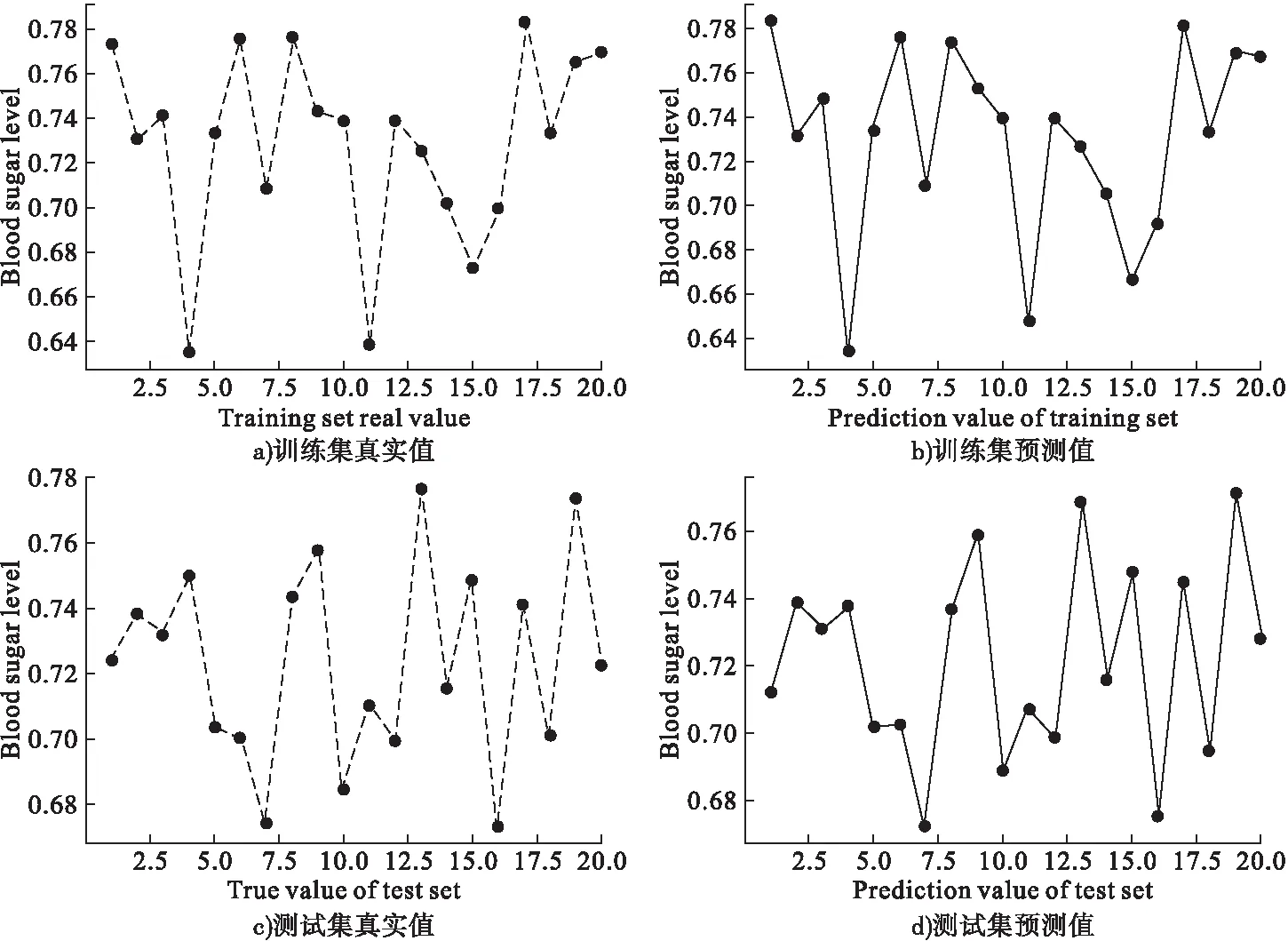
图2 模型2训练集和测试集预测图
图2中,实线表示血糖的预测值Y*,虚线表示血糖的真实值Y。其中,模型2训练集的均方误差为0.005256,拟合时间为306.688s,测试集的均方误差为0.005234,模型预测时间为1.023s。
最后,做出SVR、KRR、GBDT和模型2(Ada-VotingRegressor)学习曲线。由于四个模型的均方误差波动幅度不大,为了更加清楚地对比四个模型的学习曲线,我们将其放在一张图上,如图3所示。
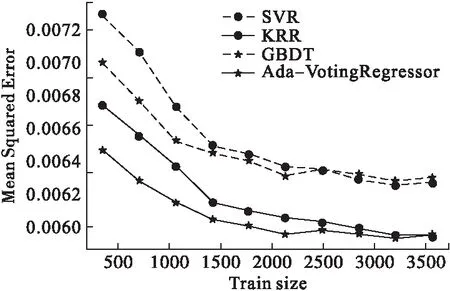
图3 三种基础回归器和模型2(Ada-VotingRegressor)的学习曲线图
从图3我们可以看出:(1)KRR模型曲线一直处于SVR模型学习曲线和GBDT模型学习曲线的下方;(2)当训练样本量小于2500时,GBDT的学习曲线处于SVR学习曲线的下方,当训练样本量超过2500时,GBDT的学习曲线处于SVR学习曲线的上方;(3)模型2(Ada-VotingRegressor)的学习曲线一直处于其他三条学习曲线之下。
就SVR和GBDT两个模型而言,在样本量为2500前后,学习曲线的上下位置互换,其原因可能有算法和样本容量两个因素。经过将训练集和测试集的样本划分调整为6.5∶3.5发现,SVR和GBDT的均方误差仍然随着样本量的变化而波动,因此SVR和GBDT的学习曲线的波动可能是由于算法问题导致。所以仍然在训练集和测试集划分比例为7:3时讨论问题,此时训练集处理的数据不仅维度较高,样本量也较大。SVR算法虽然可以有效解决高维度数据但它更适合于小样本,所以在样本量大于1500时,SVR模型的学习曲线下降幅度趋于平缓;而GBDT算法虽然适合的样本量较大,但不适合处理高维度数据,所以在样本大于2000时,GBDT的学习曲线呈现上升趋势,因此达到2500时,SVR和GBDT学习曲线的上下位置互换。
从图3可以进一步看出,模型2在训练样本量大约达到3600时与KRR模型学习曲线相交,因为模型2在样本量超过3500时呈现略微上升趋势。具体的原因是:在样本量超过3500 时,SVR模型和GBDT模型都有上升的趋势,只有KRR模型仍然呈现下降趋势;但最终模型融合时,由公式(1)可知,SVR模型和GBDT模型的权重系数相加超过0.7,大于KRR的权重系数,所以上升的总体趋势大于下降的总体趋势,使得最终的模型2也呈现上升趋势。
讨 论
为了考察选择GBDT、KRR、SVR(其中KRR和SVR均采用GridSearchCV方法进行自动调参)三种算法作为基础回归器后模型1和模型2集成的预测效果是否有所提高,本文将分别算出GBDT、KRR、SVR三种算法对血糖值的预测精度,具体结果表2所示。

表2 5种模型的均方误差
由表2可知,选用GBDT、KRR、SVR三种算法作为基础回归器进行迭代学习时,最终得到的模型1的精度反而有所降低,没有单个的GBDT模型、KRR模型、SVR模型精度高,这说明本文之前采用的GBDT模型、KRR模型、SVR模型已是高精度的回归模型,并不适合直接做 Adaboost集成的基础回归器。为了利用Adaboost提升已有的强学习器,本文引入可以将不同学习器更好融合的VotingRegressor模型,得到一个新的集成模型记为Ada-VotingRegressor(模型2)。由表2可知:模型2明显预测精度高于SVR、KRR、GBDT、模型1,预测时间和拟合时间也较短,模型效率高;由于受模型1和模型2所选基础回归器的影响,即SVR算法不适合大样本数据,GBDT算法不适合高维度数据,使得集成后的模型1和模型2的均方误差随着样本量的波动而变化,最终使得训练集和测试集之间的误差分别为万分之七和万分之二。
利用天池精准医疗大赛的数据所作的实证分析的结果表明:模型2不仅预测精度高于SVR、KRR、GBDT和模型1,预测时间和拟合时间也较短,模型效率高。在基础回归器的选择上,建议首选基础回归器的精度最好不要太高;其次,在同时选用几个基础回归器时最好考虑这几个回归器各自的优缺点,使集成模型各方面更完善;最后,取基础回归器时要考虑所选回归器与研究使用的样本量的大小与维度是否合适。本研究结合了Adaboost的权重更新算法和VotingRegressor加法集成原理对模型进行线性融合,得出的模型2,能够更准确地预测血糖值,同时该方法同样适用于其他疾病指标的预测。
在疾病指标值预测问题中,本文采用的是基于Adaboost视角的集成模型,但预测疾病指标值方法还有许多,比如杨光利用决策树模型建立2型糖尿病预测模型[4],冷菲利用极限梯度增强算法构建模型,研究两种不同癌症亚型中mRNA表达量[5];除此之外神经网络[6-7]、随机森林[8]、支持向量机[9]等也是常用于预测疾病指标的算法,也可以尝试利用这些算法作为集成算法的学习器,以优化Adaboost模型,提升模型的预测精度。虽然本文采用的基础回归器训练结果并不是最理想的,但是引入VotingRegressor算法的模型2预测疾病指标的精度有所提高,为糖尿病等疾病的预测和控制提供依据。
猜你喜欢
中华骨与关节外科杂志(2022年1期)2022-08-31
内蒙古统计(2021年4期)2021-12-06
今日中国·法文版(2020年7期)2020-07-04
文苑·感悟(2019年12期)2019-12-23
文苑(2019年23期)2019-12-05
读者·校园版(2019年17期)2019-08-13
测控技术(2018年4期)2018-11-25
上海精神医学(2017年5期)2017-11-29
系统工程与电子技术(2016年4期)2016-08-24
电力建设(2015年2期)2015-07-12
