
基于神经网络的电动汽车造型意象预测模型
2021-05-07 02:58程永胜徐骁琪陈国强吴俭涛
计算机集成制造系统 2021年4期
程永胜,徐骁琪,陈国强,孙 利,吴俭涛
(1.厦门大学嘉庚学院 设计与创意学院,福建 漳州 363105;2.燕山大学 艺术与设计学院,河北 秦皇岛 066004)
0 引言
在世界能源转型的背景下,汽车行业正面临着巨大变革,消费者对汽车的选择正逐渐从燃油汽车向电动汽车转移。然而,燃油汽车至今已经发展了一百多年,多数消费者对汽车审美认知固定在燃油汽车造型基础上,而电动汽车因其供能系统和结构布局等变化使得其造型设计产生明显转变。因此,如何让消费者摆脱固有燃油汽车造型的刻板印象,接受电动汽车造型[1],又能在汽车造型设计当中凸显出燃油汽车与电动汽车的差异化,设计出符合消费者偏好的电动汽车造型成为了行业持续发展的关键性问题。
围绕这一问题,有关学者进行了积极的研究。文献[2-3]基于遗传算法,将进化计算与产品族外形基因理论相结合,提出以消费者偏好驱动的SUV外形基因设计方法;文献[4]通过获取汽车侧面轮廓多意象目标需求和产品样本造型参数,建立了意象造型神经网络评价系统,并利用非支配排序遗传算法建立了多意象造型进化设计系统;文献[5-7]中运用模糊集和神经网络方法,对汽车造型风格、色彩和意象表达进行了研究;文献[8]通过探讨用户的感性意象偏好与汽车的造型设计要素间的关系,为设计出符合用户预期感受的汽车造型提供了参考;文献[9-10]以汽车特征线为研究对象,运用遗传算法结合感性工学,提出了用户期望意象驱动的汽车造型基因进化思想及方法;文献[11]提出了以顾客偏好为导向的产品感性设计支持技术,并以数量化I类理论建立了轿车感觉与设计变量的关系模型。
围绕上述研究发现,目前电动汽车品牌大致可分为两类:传统品牌电动汽车和全新品牌电动汽车。传统品牌电动汽车在进行造型设计时,不仅要延续品牌固有造型特征,还要考虑匹配电动汽车造型意象,来满足消费者潜在的偏好需求。而全新品牌电动汽车进行造型设计时,无需考虑品牌固有造型特征的延续性,可以自由设计全新的造型特征,但全新的造型特征能否得到广大消费者的认可存在较大的风险性,而当前研究对此类问题还尚未涉及。因此,本文提出一种基于神经网络的电动汽车造型意象预测模型,通过对其造型特征和感性意象进行多维度、多成分分析,降低用户对造型特征认知维度,以获得更加准确的用户感性意象评价。结合神经网络挖掘汽车造型特征和用户感性意象之间的隐性关系,并予以数据量化表达,帮助设计人员快速识别出关键造型特征与感性意象目标,进行设计决策。
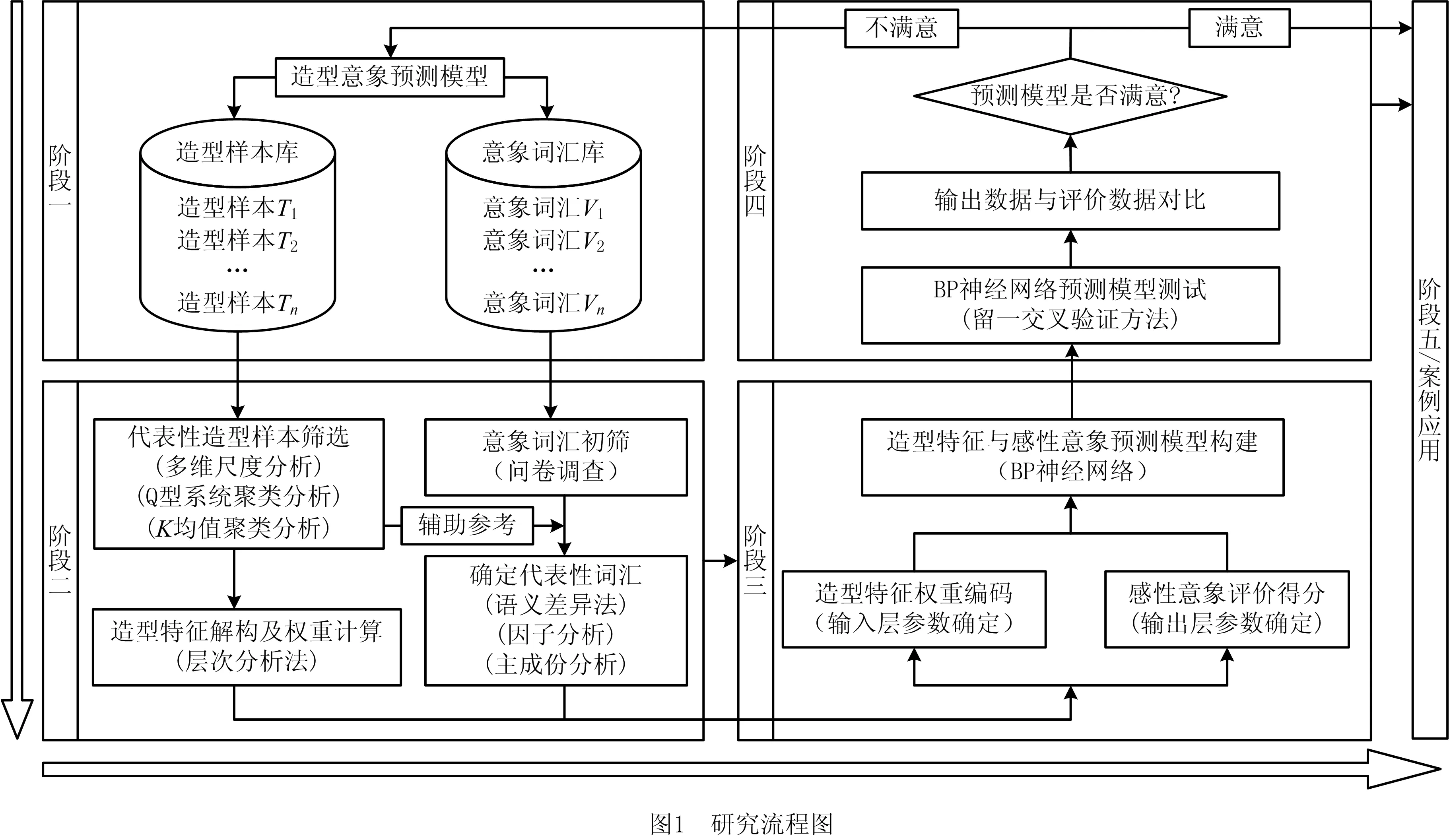
1 预测模型构建流程
本文主要针对电动汽车造型意象研究,从建立造型样本库和意象词汇库、获取造型特征权重和感性意象量化、BP神经网络搭建及训练、预测模型测试与验证四个层次开展。
具体构建流程:
(1)首先确定研究对象,并建立造型样本库和意象词汇库。
(2)通过多维尺度分析和聚类分析对样本库进行筛选,确定代表性样本,并对其进行造型特征解构,提取其造型因子,以层次分析法计算各造型特征权重系数;接着对词汇库进行初选,以代表性造型样本为基础结合语义差异法对意象词汇库进行主成分分析,确定代表性意象词汇。
(3)将样本库内30个训练样本进行造型特征因子编码,作为神经网络输入层;运用语义差异法建立训练样本与代表性词汇映射关系,通过目标用户评价得到评价均值,作为神经网络输出层。
(4)运用BP神经网络建立样本造型特征与用户感性意象之间的预测模型,采用留一交叉训练方法对预测模型进行检测,验证了该预测模型的精确度。
(5)最后结合实际设计案例示范该预测模型在设计实践中的应用。
综上,如图1所示为电动汽车造型意象预测模型构建研究流程图。
2 造型特征和感性意象分析
汽车造型较为复杂,同时对前脸、侧面、后围等视角展开研究难度较大,文献[12-13]研究表明汽车前脸是造型特征最为复杂的视角,所包含的汽车造型意象信息最为丰富,对研究造型特征与感性意象匹配问题具有重要意义[14]。此外,不同车型所呈现的视觉感官也有差异,因此本文选取电动SUV前脸造型作为研究对象,展开案例研究。
2.1 造型样本库和意象词汇库建立
通过网络搜索及实地参观等方式,从汽车市场在售电动SUV车型中,收集大量前脸造型图片,筛选掉造型特征模糊、款式老旧、角度较差等图片,最终确定30款前脸造型图片作为本文研究样本库,如表1所示。
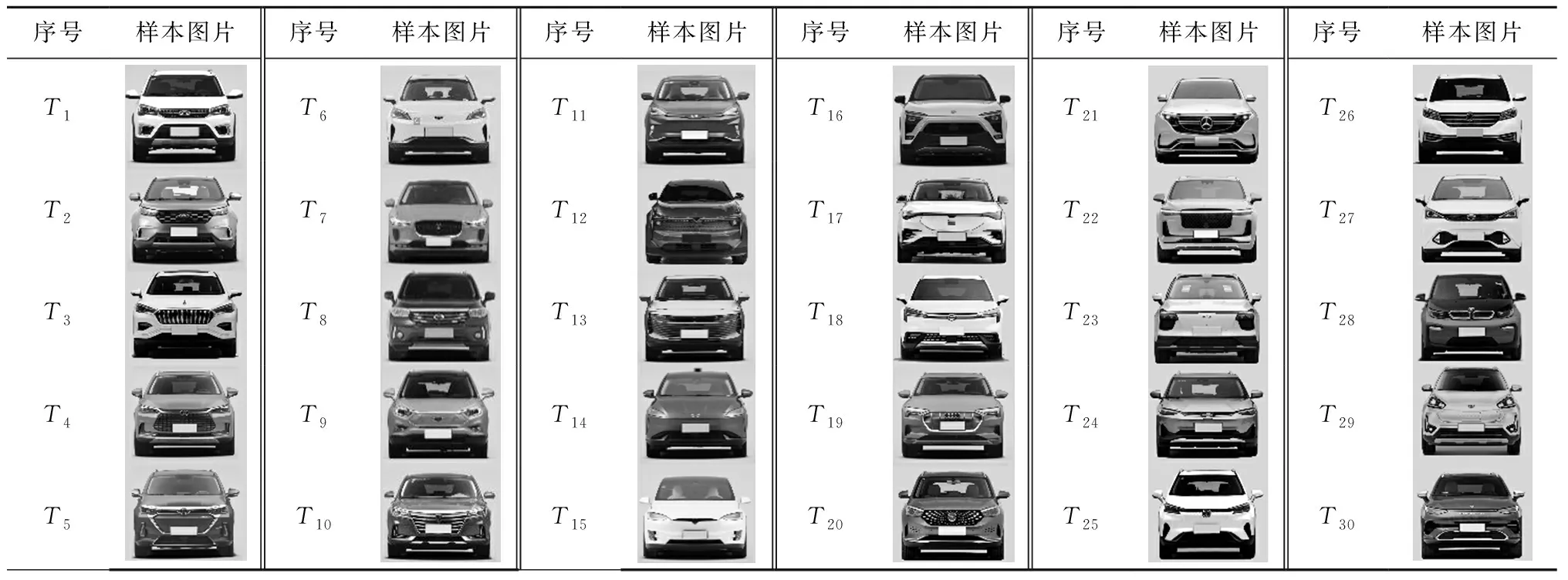
表1 电动SUV前脸造型样本库
根据电动SUV汽车前脸造型特征,以用户访谈,文献查阅和网络查阅等方式结合前人研究结果,收集描述电动SUV造型有关感性意象词汇共40对,组成感性意象词汇库,如表2所示。
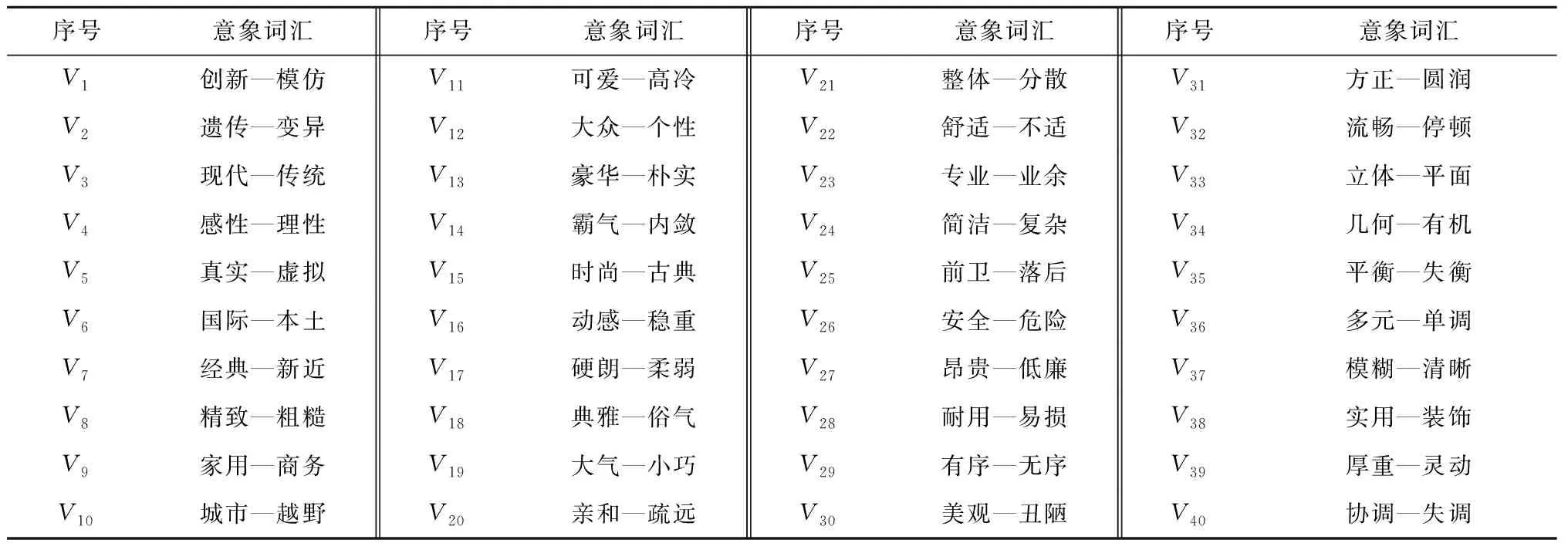
表2 电动SUV感性意象词汇库
2.2 电动SUV前脸造型样本筛选
2.2.1 样本多维尺度分析
通过问卷调研,对造型样本库内的电动SUV前脸造型进行相似性分类,邀请40名汽车行业相关从业人员根据自身的判断对样本进行归类,分类组数和每组具体数量不做要求。然后,将分组数据进行整理,统计两个样本分在同一组的次数并建立三角相似程度矩阵A=(aij)(i=1,2,…,30;j=1,2,…,30),其中aij表示第i个样本和第j个样本被分到同一组的次数,次数则表示两个样本之间的相似程度。最后,将三角相似程度矩阵A转换为多维尺度分析计算所需的“距离矩阵B”。矩阵C(30×30)表示所有样本完全相似矩阵,任意cij=40。距离矩阵B中对应的值为:B=C-A。
将距离矩阵B(30×30)数据输入到SPSS软件中,进行多维尺度分析(ALSCAL)。运算过程中,当压力指数(Stress)的改进量小于指定值0.001,模型迭代停止,输出不同维度下的压力指数(Stress)与拟合度(RSQ),如表3所示。
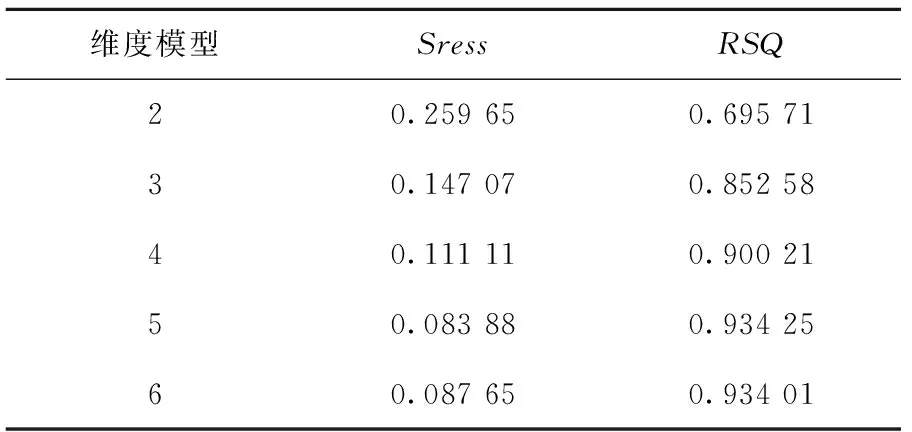
表3 不同维度压力指(Stress)与拟合度(RSQ)
多维尺度模型共进行了5次迭代,由表4所示压力指数(Stress)与拟合度(RSQ)关系可知,二维模型的拟合度不好,三维模型和四维模型的拟合度中等,五维模型和六维模型的拟合度较好。其中五维模型Stress最小,且RSQ>0.8,说明在五维模型下进行多维尺寸分析是最合适的。表5所示为30个样本在五维模型下多维尺度分析结果。
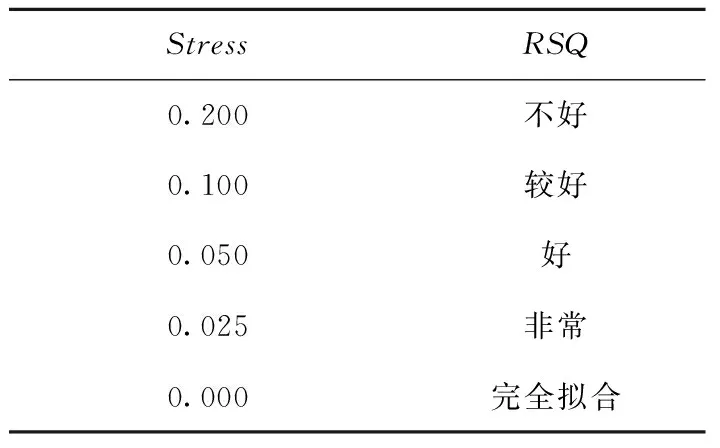
表4 压力指数(Stress)与拟合度(RSQ)关系
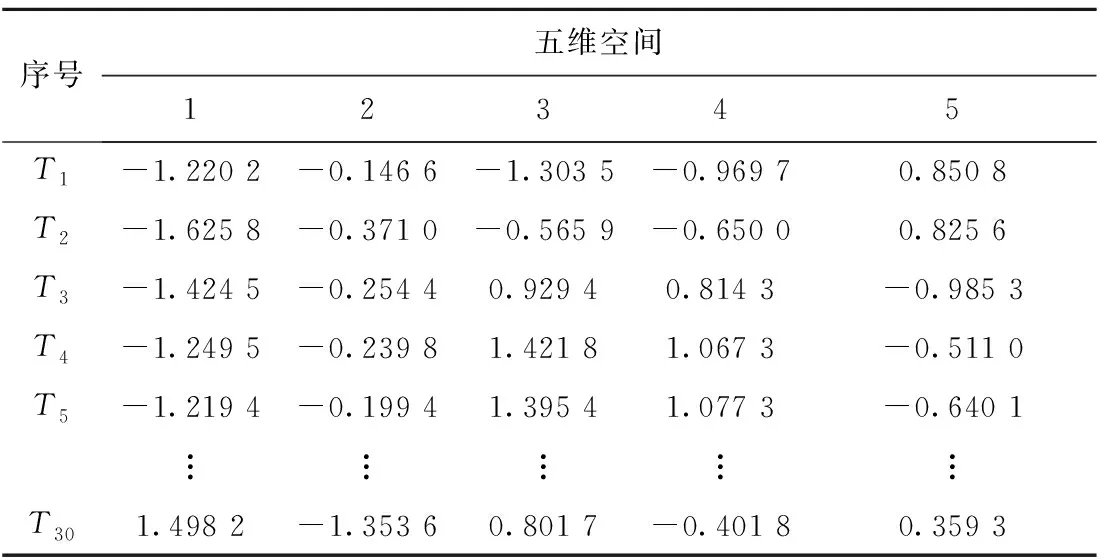
表5 样本在五维空间中的坐标值(部分)
2.2.2 造型样本聚类分析
将实验样本在五维空间中的坐标值结果作为分类变量,对30个样本进行聚类分析,对维度数据进行简化,确定代表性样本。先采用Q型层次聚类分析中的Ward’s method方法结合欧式距离平方进行区间测量,输出树形图,如图2所示。树状图种类间距离由4増加至12的过程中,聚类结果很稳定,说明这5类的特点比较突出,因此考虑将30个样本分成5类。为了从每一类中选取一个样本作为该类的代表,使用K均值聚类分析,将聚类数量设置为5,得到各样本与其所属类别中心点的距离,具体结果如表6所示。
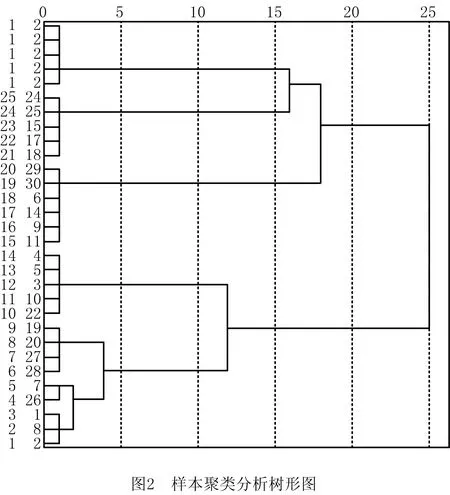
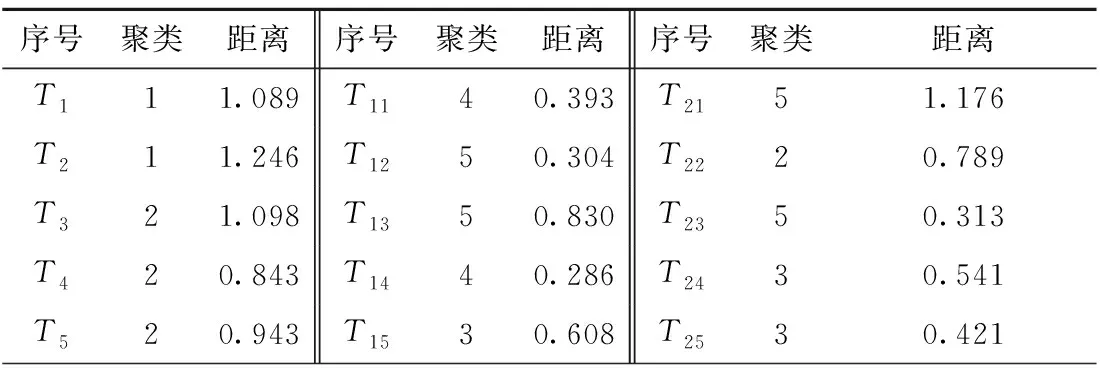
表6 样本K均值聚类结果
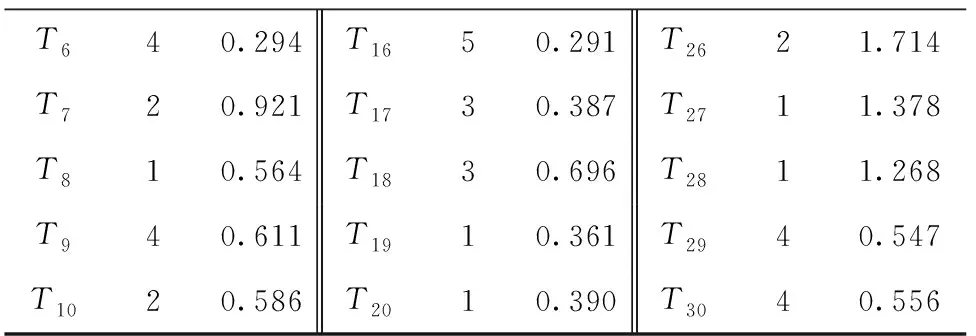
续表6
根据表6各样本K均值聚类结果,选取每个类别中距离中心点最近的样本作为代表性样本,最终确定T10、T14、T16、T17、T19为电动SUV前脸造型代表性样本,如表7所示。为进一步提升代表性样本的显著性,运用阿恩海姆提出的视知觉简化原理[15],对代表性样本进行线框图绘制,归纳电动SUV前脸当中的主要造型特征。

表7 代表性样本和线框图
2.2.3 代表性样本造型因子解构
汽车前脸造型特征是由主要造型特征和次要造型特征组合构成,其中主要造型特征对造型意象的影响较大,次要特造型征则影响较弱。因此,本文通过汽车造型相关文献研究及和汽车企业专业设计人员探讨,并采用层次分析法对前脸涵盖的主次造型特征进行筛选,去除对造型意象影响较弱及容易干扰目标用户进行判断的次要特征,确定最能体现前脸造型特征的主要特征,包括:前挡风W1,引擎盖W2,上进气口W3,大灯组W4,下进气口W5,雾灯W6,如图3所示,并根据形态拆解法对代表性样本造型特征所包含的不同造型因子进行解构,用轮廓线归纳出不同的造型因子类型,如表8所示。
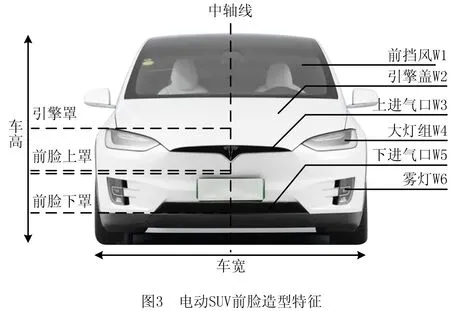
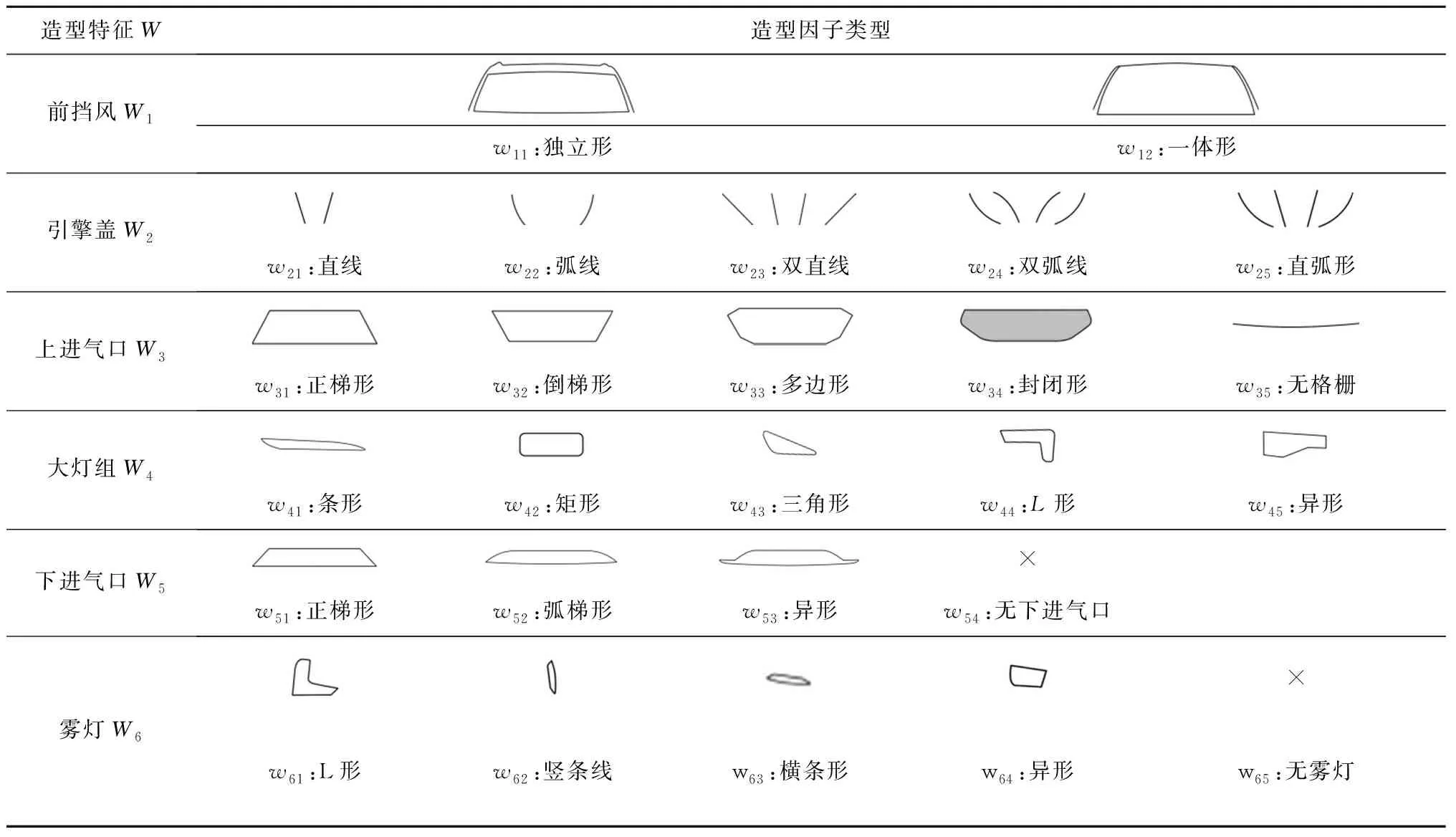
表8 造型特征描述及造型因子提取
2.2.4 造型特征权重计算
运用层次分析法计算电动SUV前脸中各造型特征的重要程度。以两两比较的方式,建立造型特征判断矩阵,如电动SUV前脸A与造型特征W中的各特征元素W1,W2,…,Wn之间两两比较,得到判断矩阵A:
为了使两两造型特征重要性判断定量化,采用九级标度法,即标度值采用数字1~9及其倒数表示,判断矩阵标度说明如表9所示。为了保证各造型特征权重计算结果的准确性,邀请汽车设计师5人、汽车油泥师3人、汽车驾驶员6人、设计专业教师6人组成20人评价小组,经过评价小组讨论,决定各造型特征的相对重要性。
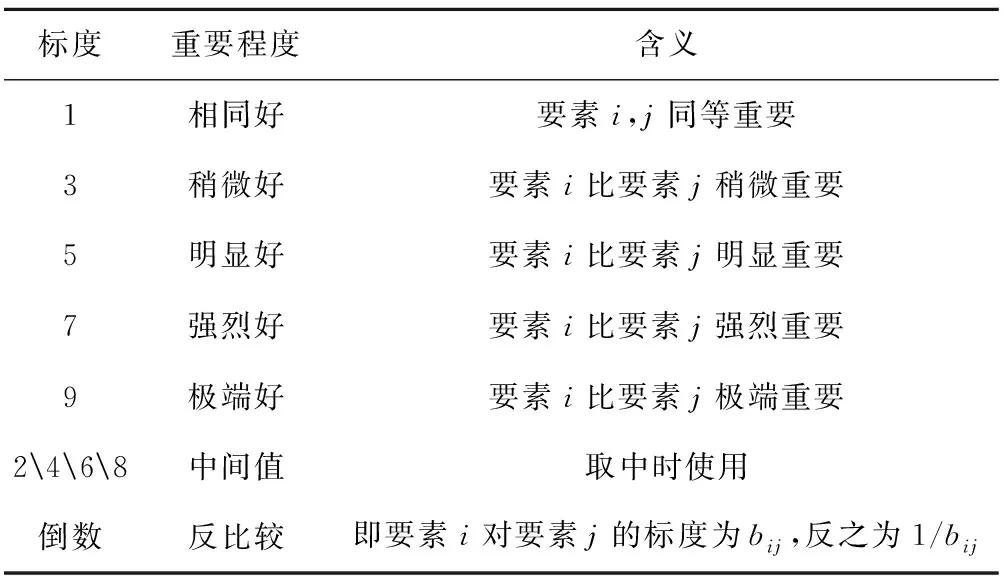
表9 判断矩阵标度说明
本文采用几何平均法求解权重向量,几何平均数是指n个观察值连乘积的n次方根。计算求得评价小组对前挡风W1,引擎盖W2,上进气口W3,大灯组W4,下进气口W5,雾灯W6六个造型特征的权重得分,并将所得结果进行归一化处理,使结果值映射到[0,-1]之间,最终结果如表10所示,具体计算过程如下:
(1)求判断矩阵A中每行指标的乘积Ai:
(1)
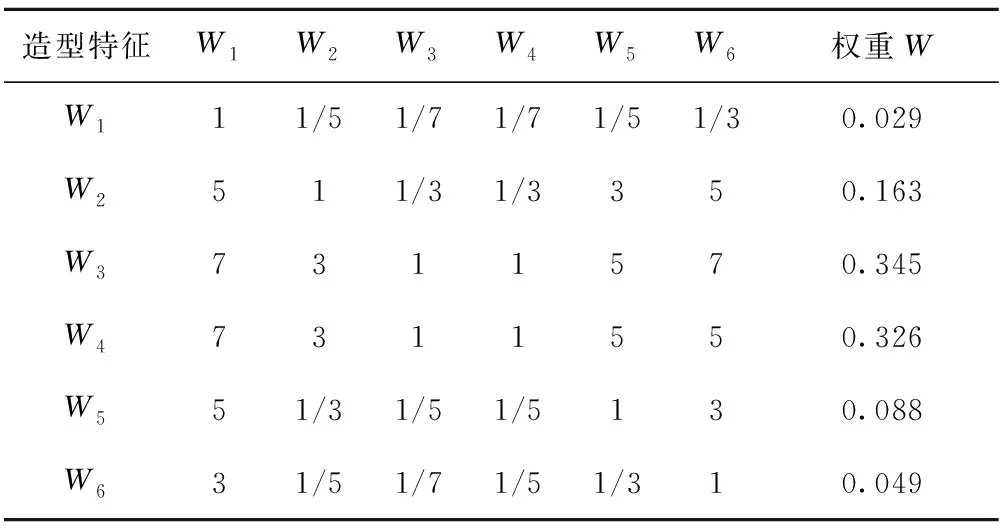
表10 各造型特征评价矩阵和权重得分
式中Wij为判断矩阵中第i行第j列指标,m为指标数量。
(2)得出各行乘积Ai后,求判断矩阵各行指标的几何平均值ai:
(2)
(3)结果进行归一化处理,得到相对权重W:
(3)
2.3 电动车造型意象词汇筛选
2.3.1 代表性意象词汇初筛
由于词汇库范围过于宽泛,不利于针对性研究,需对表2电动SUV造型意象词汇库进一步筛选。筛选方式通过网络问卷调查的形式进行,问卷中将各个意象词汇随机排序,要求测试者从词汇库中选择10个能最能描述电动SUV前脸造型的词汇;测试者囊括了汽车企业设计人员、汽车相关行业从业人员以及电动汽车实际用户等。本次问卷调查共发放100份问卷,收回96份有效问卷,将调研结果输入到SPSS软件中,最终意象词汇选择频数条形图如图4所示。

由图4意象词汇与频数条形图,可以发现词汇库中:V1创新—模仿、V2遗传—变异、V7经典—新近、V12大众—个性、V17硬朗—柔弱、V21整体—分散、V24简洁—复杂、V30美观—丑陋、V33立体—平面、V38实用—装饰,这10个意象词汇组选择频数明显高于其他词汇,因此选择这10个意象词汇作为意象词汇初选结果。
2.3.2 代表性意象词汇确定
将上述10个意象词汇通过语义差异法与五款代表性样本建立映射关系,邀请28名电动汽车目标用户按照“3,2,1,0,-1,-2,-3”7级量表评分标准进行打分,得到各代表性样本在10个意象词汇得分数据,如表11所示。
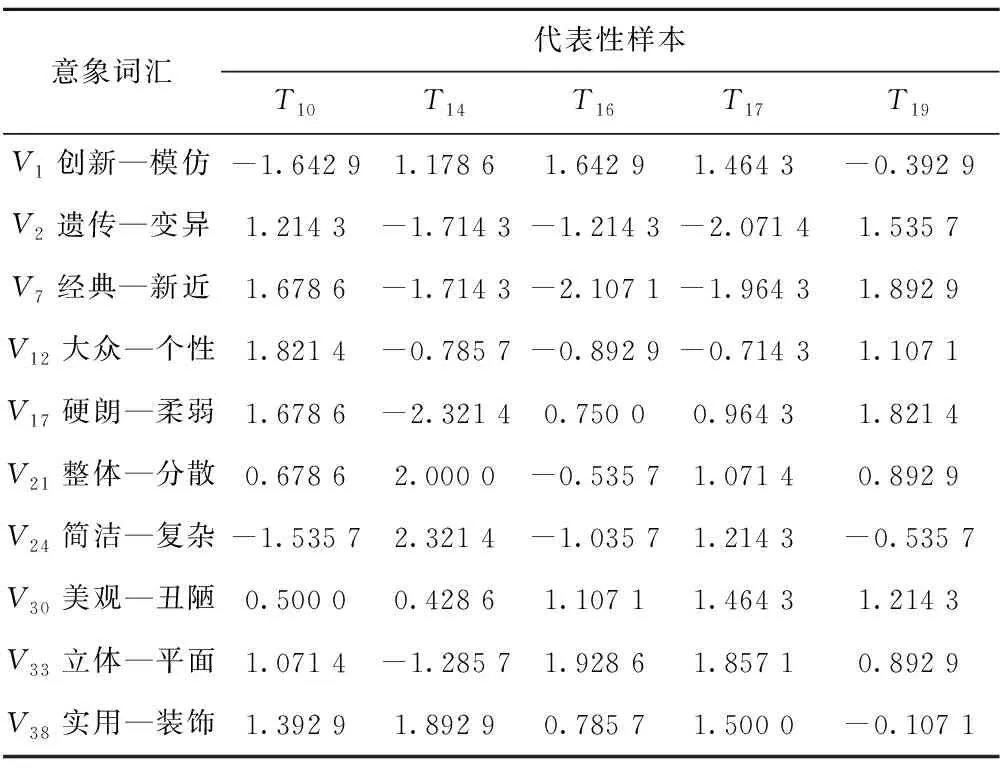
表11 样本评价均值
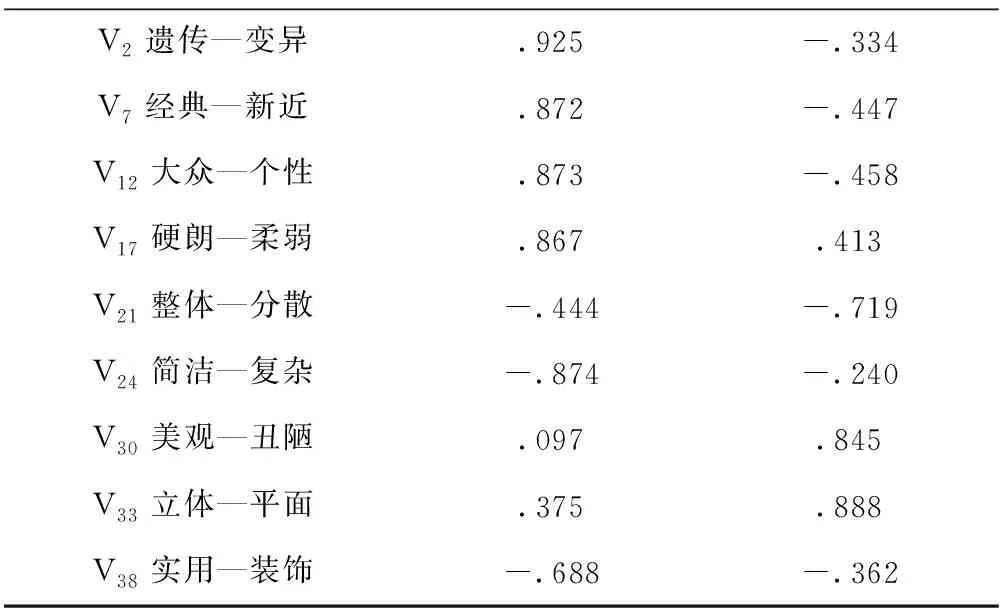
将所得数据进行主成分分析,得到解释的总方差和意象词汇成分矩阵,如表12和表13所示。选取成分1和成分2中选择正负值最极端的两个意象词汇,得出最能代表样本的造型意象词汇分别为成分1当中:V2遗传—变异、V24简洁—复杂;成分2当中V21整体与分散、V33立体与平面。
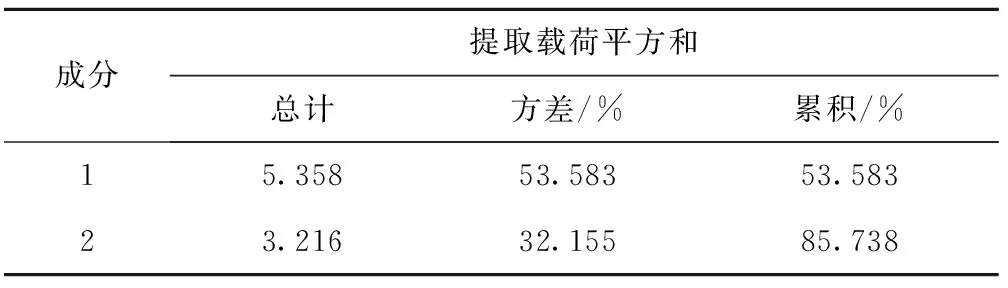
表12 解释的总方差
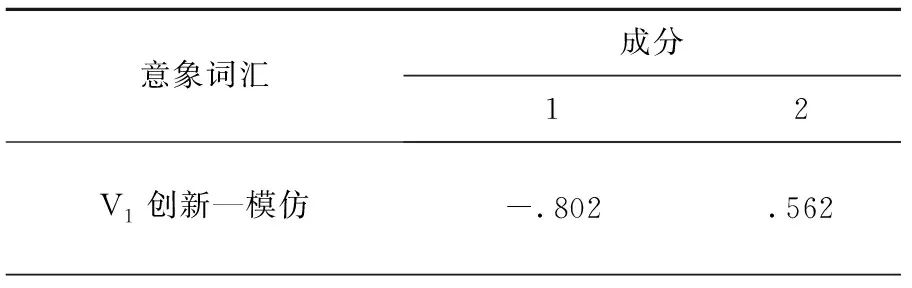
表13 意象词汇成分矩阵
续表13
3 电动SUV造型意象预测模型构建
3.1 神经网络模型的选择
根据电动SUV前脸造型意象研究特点,选用含有隐藏层的BP神经网络较为合适[18-19]。BP神经网络是建立以权重描述变量与目标之间关联关系的一类神经网络,适合解决非线性预测问题,其结构如图5所示。

BP神经网络结构由输入层、输出层和隐含层组成[20]。隐含层的第j个节点与输入层第i个节点的连接权值
Wji(i=1,2,…,n1;j=1,2,…,n2)。
输出层第k个节点与隐含层第j个节点之间的连接权值
Wkj(j=1,2,…,n2;k=1,2,…,n3)。
3.2 神经网络模型的选择
神经网络输入层和输出层单元数量是由实验样本数量和意象词汇得分确定的,隐含层单元数量是由使用者设定,正常隐含层的单元数量应满足经验公式[21]:
(4)
式中:i为隐藏单元数量;m为输入单元数量;l为输出单元数量。
BP神经网络的学习过程为正向传播和误差反向传播组成,选用的标准学习算法为最速下降静态寻优算法,公式为:
(5)
式中:W为权重;n为样本数;η为学习效率;α为惯性因子;E为误差。
但该算法运用在造型意象神经网络预测模型训练过程中时,收敛速度很慢,因此通过比较研究最终选用L-M优化算法(trainlm),其公式为:
W(k+1)=W(k)+(JTJ+uI)-1JTe(k)。
(6)
式中:W(k)为k时刻的权值向量;e(k)为k时刻的偏差向量;J为误差对权值微分的Jacobian矩阵;I为单位矩阵;u为一个标量,当u很大时,JTJ可以忽略,式(6)接近最速下降静态寻优算法,当u很小时,式(1)接近高斯—牛顿法。
3.3 BP神经网络模型参数设定
3.3.1 输入层数据确定
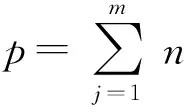
δx(i,j)=

(7)
根据式(7)样本造型因子编码原则,“0”表示该造型特征不包括该造型因子,“1”表示该造型特征包含该造型因子,由此得出训练样本造型特征编码如表14。
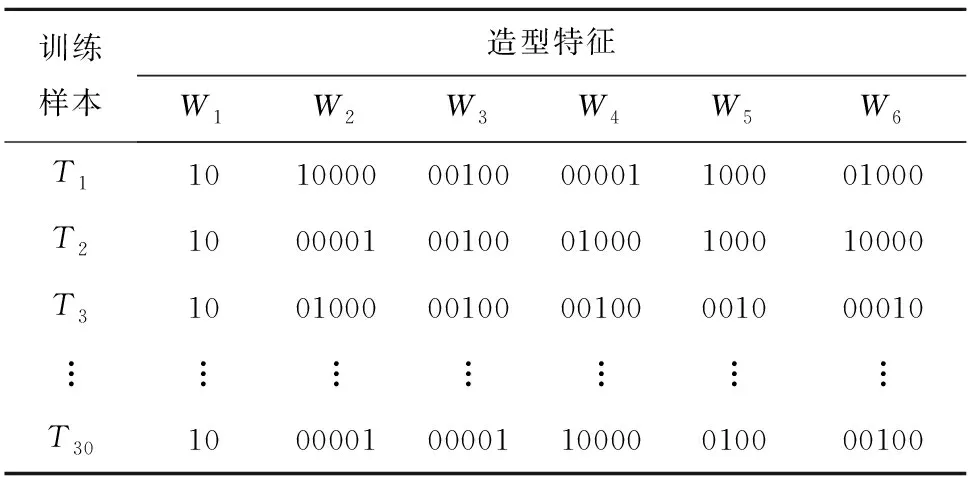
表14 造型特征编码
电动SUV前脸中造型特征的重要性存在差异,因此需要将造型因子原始数据乘以造型特征权重值,得到最终BP神经网络的输入数据,具体数据如表15所示。
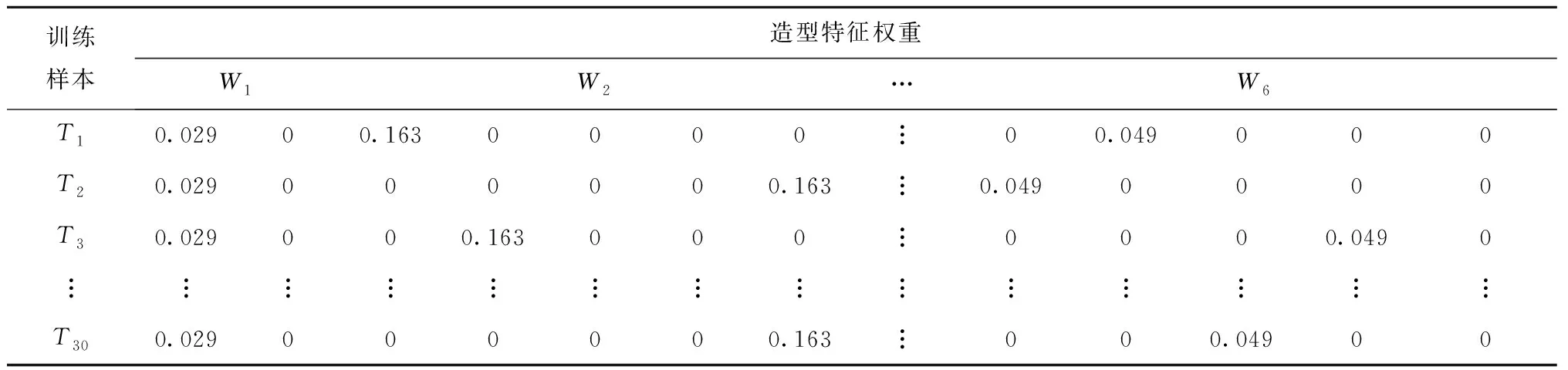
表15 转换后的造型特征权重编码
3.3.2 输出层数据确定
以“3到-3”7级量表评分标准对训练样本进行打分,获得训练样本各代表性意象词汇得分均值,作为BP神经网络输出数据,如表16所示。
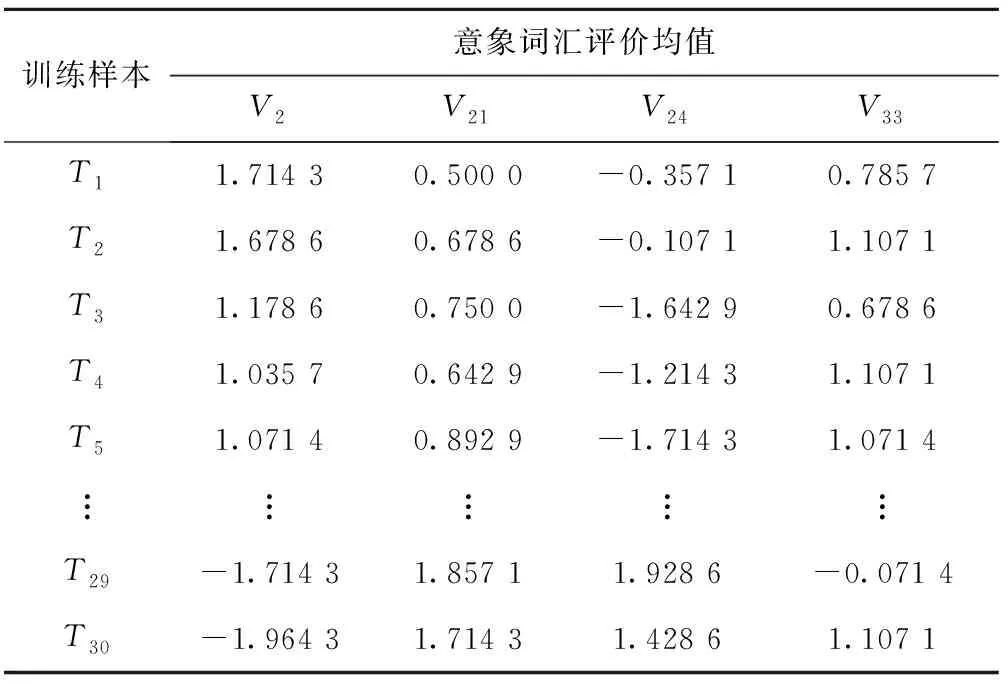
表16 训练样本评价均值
3.4 BP神经网络模型参数设定
选用MATLAB R2018b作为BP(back propagation)神经网络模型建立平台,以造型特征权重编码为BP神经网络训练输入数据,以训练样本意象词汇评价均值为输出数据。电动SUV前脸造型特征包含造型因子26个,则输入层单元数量为26;电动SUV前脸造型代表性意象词汇4个,则输出层单元数量为4。由式(4)可计算得出隐藏层单元数量为13个左右较为合适。通过隐含层单元个数的调节,降低训练误差。
应用newff创建BP神经网络,隐含层采用tangent sigmoid作为传递函数,输出层采用purelin线性函数,设置学习次数为5 000次,误差值为0.001,采用trainlm优化算法进行训练,计算得到BP神经网络预测模型层间之间的权重值。为了验证该预测模型的可行性,下面通过测试样本检验该预测模型的预测精度。
3.5 BP神经网络预测模型测试
由于预测模型数据集存在数量少且维度低的特点,若像正常一样将数据集划分成训练样本和测试样本进行训练,可能会因为训练数据过少而导致模型泛化能力降低。为此,本文采用留一交叉验证方法对预测模型进行测试,该方法实质上是将数据集划分为N组,其中N-1组数据作为训练样本,剩下的1组数据作为测试样本,进行N次循环测试,并将N次的平均交叉验证识别均方误差作为评价标准[22]。留一交叉验证方法不仅可以充分利用数据提升模型可靠性,还可以有效地避免陷入局部最优,得出的结果与训练整个测试集的预测值最为接近。
按照留一交叉验证方法要求,将数据集中样本分别作为预测样本输入到预测模型中,通过对预测模型进行30次交叉验证,训练得到各预测样本感性意象输出数据,并将预测模型输出数据汇总,如表17所示。然后,计算每组预测模型输出数据与目标用户评价数据的相对误差,结果如表18所示。此外预测模型测试样本集的均方误差MSE=0.011 4,MSE表示输出数据与评价数据之差平方,数值越小则说明预测模型输出数据准确度越高,实用性越强。表18所示,预测模型输出的感性意象数据与实际用户评价所得的数据误差较小。因此,综合上述结果表明,该神经网络模型符合预测精度要求,可行性较高。
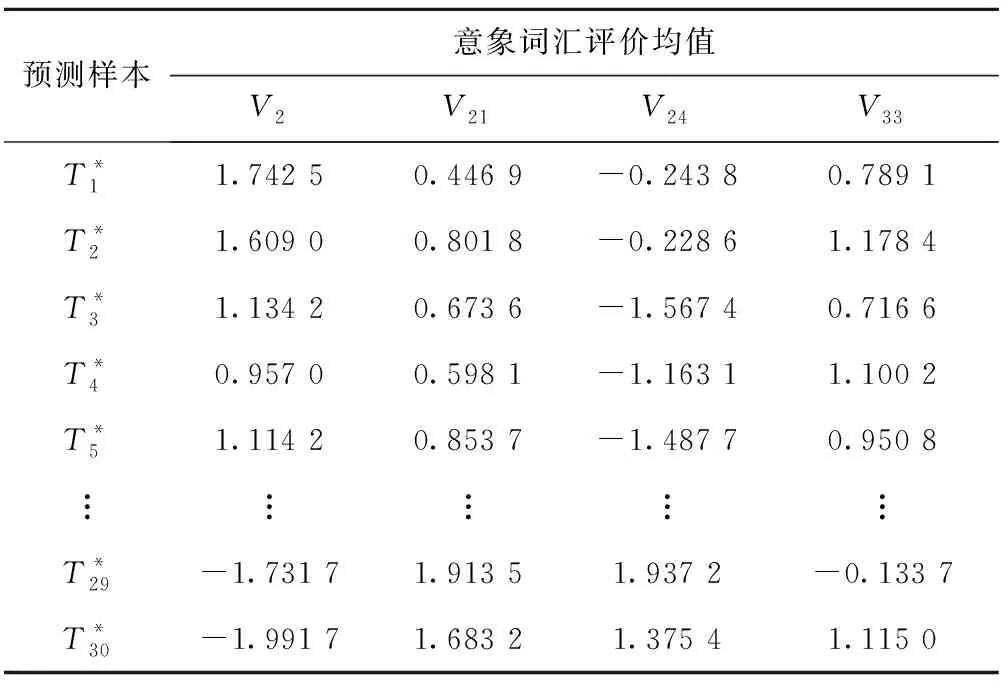
表17 预测模型输出数据汇总
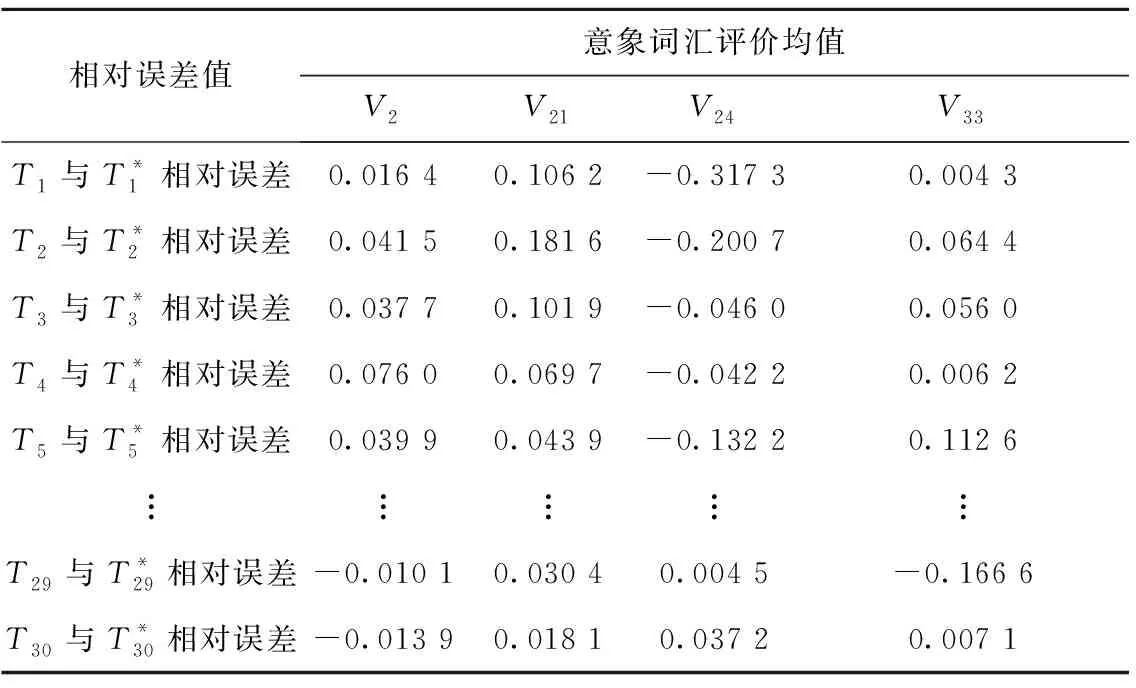
表18 评价数据与输出数据相对误差值
3.6 案例应用
由于汽车造型设计周期较长且项目投入较大等特点,促使前端设计成为汽车开发极其重要的阶段之一。同时,对设计师模糊的前端创意思维进行定量研究,可有效避免在设计流程中出现不必要的重复和浪费。因此,将预测模型应用到汽车造型前端设计流程中,可提升设计人员对于造型风格意象把控,同时提升设计效率及决策准确性。此外,草图阶段是汽车造型前端设计中最重要的流程之一,直接影响到汽车造型设计风格意象的走向。为此,本文邀请汽车企业前瞻造型设计师以代表性意象词汇作为设计目标,结合相关联的特征因子进行电动SUV前脸造型创新设计,经过设计师反复推敲和思考,最终得到3款草图设计方案,如图6所示。

通过留一交叉验证法得到最佳预测模型后,可用于对具体设计方案的预测。将3款草图设计方案造型特征编码数据导入预测模型输入层,得到3款设计方案在4个代表性意象词汇下的评价得分,如表19所示。
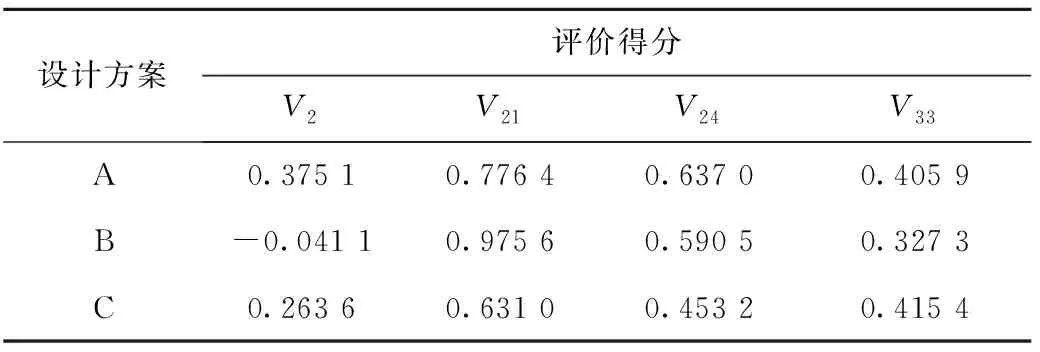
表19 三款设计方案评价得分
结果显示,设计方案A最能体现“遗传”和“简洁”的造型意象;方案B则存在轻微“变异”的造型意象;同时方案B在3款方案当中最能凸显“整体”的造型意象;而方案C更能体现“立体”造型意象。同时,由于方案A和方案C方案前挡风和上进气口相似度较高,显示意象词汇评价得分并未出现较明显的差异。方案应用结果表明,预测模型可以在前端设计阶段很好地辅助汽车造型设计人员做出正确的方案决策,提升设计效率。
4 结束语
本文以电动SUV前脸造型为例,通过多维尺度分析,确定了代表性样本及其造型特征,运用主成分分析从意象词汇库筛选出最具代表性的意象词汇,并以层次分析法计算出电动SUV前脸中各造型特征的权重系数,结合训练样本造型特征编码,得到神经网络输入层数据。以7级评价量表获取训练样本代表性意象词汇得分均值,作为神经网络输出层数据,从而构建BP神经网络预测模型。最后通过留一交叉验证方法验证了该预测模型的可行性,并进行了案例应用。研究表明:
(1)通过统计学方法和神经网络的结合,可将大量感性数据进行降维处理,有效降低用户认知维度,更好地定量化描述造型特征和感性意象两者之间的隐性关系。
(2)通过计算前脸各造型特征权重系数,可以优化加权预测模型概念,对于设计人员快速识别关键造型特征具有切实可行的价值。
(3)利用BP神经网络建立造型意象预测模型,不仅可以明确造型意象设计目标,还可为造型意象开发提供理性数据参考。
未来,尝试研究将电动汽车前脸造型和车身其他造型进行组合,进一步改进和优化该造型意象预测模型, 形成系统性和通用性的电动汽车造型设计决策方法以指导设计实践。
猜你喜欢
青年文学家(2022年9期)2022-04-23
中华胰腺病杂志(2021年1期)2021-02-26
山东医药(2020年34期)2020-12-09
电子制作(2019年19期)2019-11-23
中华胰腺病杂志(2019年4期)2019-08-29
重型机械(2016年1期)2016-03-01
大连工业大学学报(2015年4期)2015-12-11
陕西教育·高教版(2015年7期)2015-02-28
海军航空大学学报(2015年4期)2015-02-27
山西大同大学学报(社会科学版)(2015年2期)2015-01-22
