
基于SOC架构的智能图像处理和外设控制系统设计
2021-05-07 07:54王升哲唐中和刘书信刘云峰张承果
计算机测量与控制 2021年4期
王升哲,唐中和,郭 航,2,刘书信,3,刘云峰,4,张承果,张 枭,郑 杰
(1.北方激光研究院有限公司 控制与制导研究所, 成都 610011;2.四川大学 计算机学院,成都 610065; 3.重庆大学 光电工程学院, 重庆 400040;4.火箭军装备部驻成都地区第四军事代表室, 成都 610052)
0 引言
随着人工智能的崛起,对深度学习、大数据、神经网络芯片等相关技术成果的集成应用,人工智能的智能化水平进一步提升,对未来战争将产生全方位、颠覆性的影响[1]。弹载计算机SoC处理芯片作为制导武器的重要组成部分,采用高精度制导与控制系统,利用人工智能的训练和推理,通过对各种传感器获取的目标信息,以及对信息分析和处理后实时修正、控制导弹的飞行轨迹,完成对目标的有效攻击[2]。
目前,以卷积神经网络为代表的深度学习算法在形式上模拟了人脑的学习过程,也就是重复训练强化其智能思维,大大提升了人工智能系统的运行效率[3]。然而,深度学习算法需要专用硬件平台才能发挥其性能[4]。现有的人工智能芯片的技术路线大致可以分为三类:1)通用型的CPU及GPU芯片;CPU的架构和指令对神经网络计算的兼容度不够,性价比与运算效率偏低;2)FPGA芯片;具有可定制、可编程的特点,且并行效率适应神经网络运算。3)专用ASIC芯片;对特定计算的运行效率极高,不具备编程过程。
目前主流的方法是以FPGA和DSP作为智能图像处理和外设控制的器件,即由FPGA实现图像预处理功能,DSP实现图像处理算法和外设控制。由于图像数据量比较大,FPGA与DSP之间数据交互往往需要SRIO这种高速接口,这种高速接口对电路板设计要求高,而且DSP串行工作方式,导致对DSP性能要求比较高,从而成本高功耗大发热严重[5]。本文提出了一种基于SOC架构的智能图像处理和外设控制系统,所有图像运算和外设控制都在FPGA内部实现,进而成本降低,而且不需要高速的通信接口,而FPGA并行特性可以使整个系统的工作频率降低,从而发热少。
1 系统结构设计
1.1 系统结构及原理
实时图像处理和外设控制系统包括5部分,即图像输入模块、图像输出模块、图像存储模块、图像运算模块和外设控制模块。各个主要模块的功能如下:
1)图像输入模块:将前级器件输人的图像数据按照协议进行解析产生内部可以处理的图像时序和格式。
2)图像输出模块:对处理后的数字图像进行字符叠加,按照ITU-R BT.656协议显示在屏幕上。
3)图像存储模块:对图像数据进行存储,方便图像的运算。
4)图像运算模块:对解析后的图像进行预处理,并对目标检测、识别和跟踪等图像处理运算,产生参数。
5)外设控制模块:对外部器件进行初始化和控制,同时根据图像运算模块产生的参数对外设进行视野控制。
实时图像处理和控制系统微结构如图1所示。
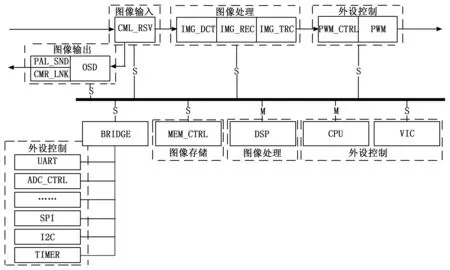
图1 实时图像处理和控制系统微结构图
1.2 工作流程
如图2所示,程序分为BOOT系统引导程序和APP应用程序两种。上电以后根据模式选择管脚跳到BOOT还是APP应用程序。BOOT分为两级BOOT,当其中一级出现损坏时,会引起标志寄存器变化,从而能够根据标志寄存器跳到另一级BOOT,保证在任何情况下都存在与主机通信的通道。当需要对APP程序升级时,跳转到BOOT程序,对FLASH中APP应用程序的数据空间进行改写。所有程序都存储在同一块FLASH上面,使用地址映射的方法实现不同地址的程序跳转[6]。
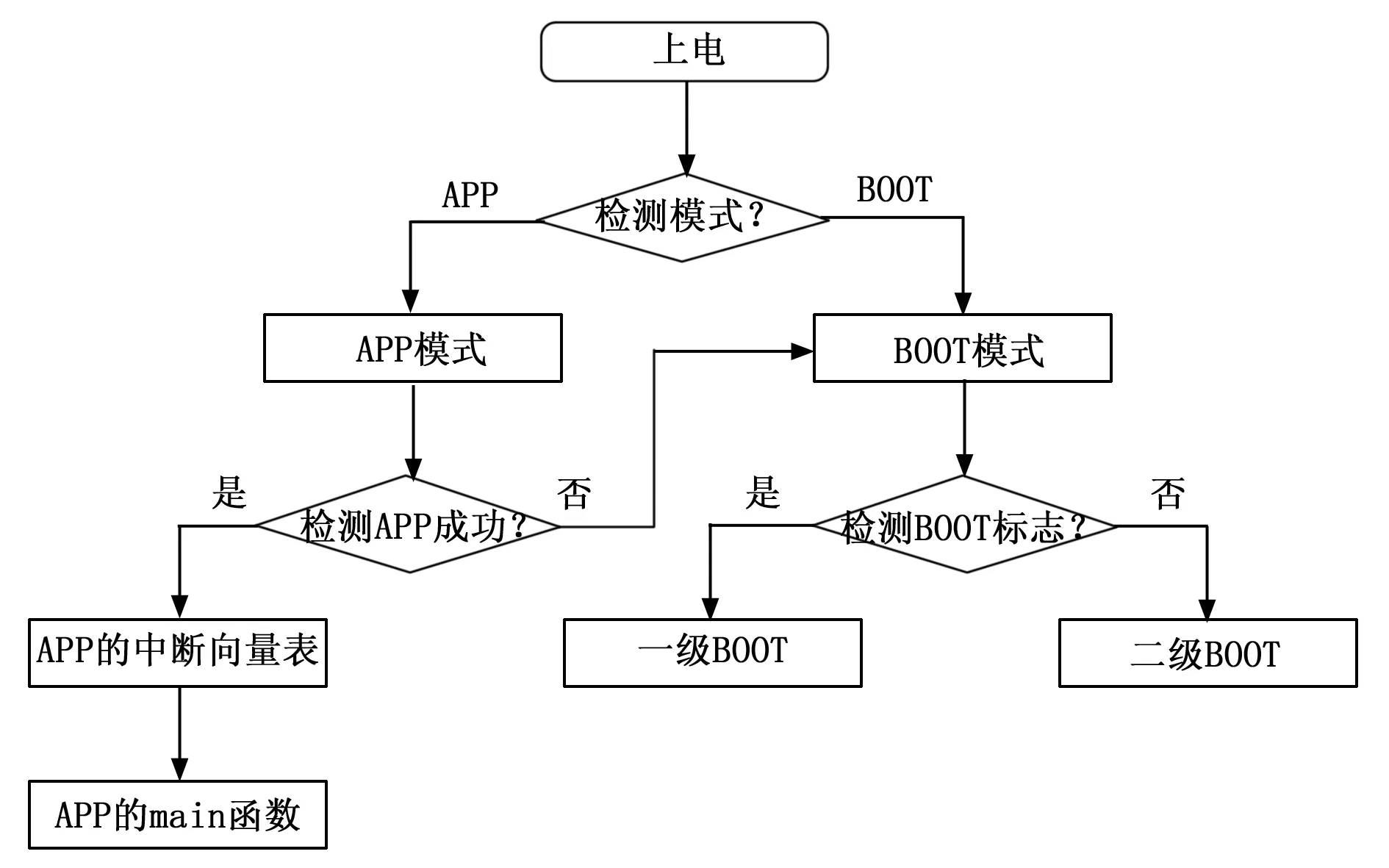
图2 工作流程图
2 实现方案
本部分主要介绍各部分的具体作用、工作方式和部件之间的配合,使得系统能够正常工作,同时根据软件配置满足各种场景。
2.1 图像输入模块
前级器件每隔一段时间产生一个数据包,该数据包协议符合CML协议[6]。图像输入模块可以对多路视频数据进行选择解析,产生帧头、行有效、图像数据。CML协议如图3所示。
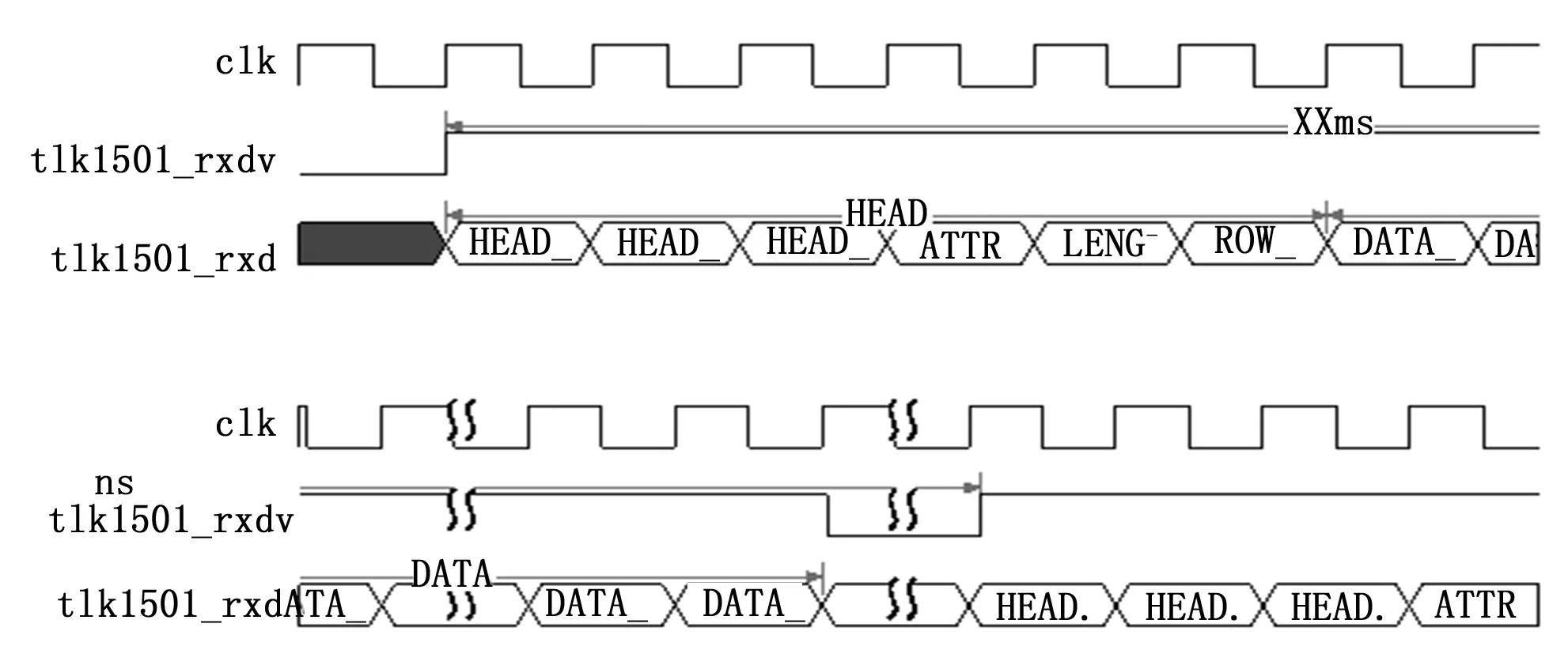
图3 CML协议输入时序
CML协议的数据包分为包头和包数据两部分。根据有效信号的上升沿来判断包头起始,当HEAD_0、HEAD_1、HEAD_2都匹配时,该数据包有效,可以进行解析,状态机如图4所示。

图4 CML协议解析状态机
数据包有效后,包头里面ATTR的属性来识别不同种类的包数据,包数据主要分为标识和图像两种。软件首先根据上报的标识信息,来配置不同的寄存器对图像进行解析。比如有多路视频输入,可以根据软件回读的标识来配置寄存器选择混合包解析方式还是纯种数据包解析方式。
2.2 图像输出模块
图像输出模块会根据软件配置值产生字符标识,该标识与图像处理后的图像数据合成形成PAL格式的视频信号输出到显示器[7]。
OSD是字符标识叠加模块,能够可以软件配置适应于不同的产品需求,如波门、虚十字等等。该模块根据场景分为四大功能部分:图形不变位置变化、图形变化位置变化、图形变化位置不变和图形不变位置不变。该电路总体结构如图5所示(深蓝色加粗为主数据通路)。
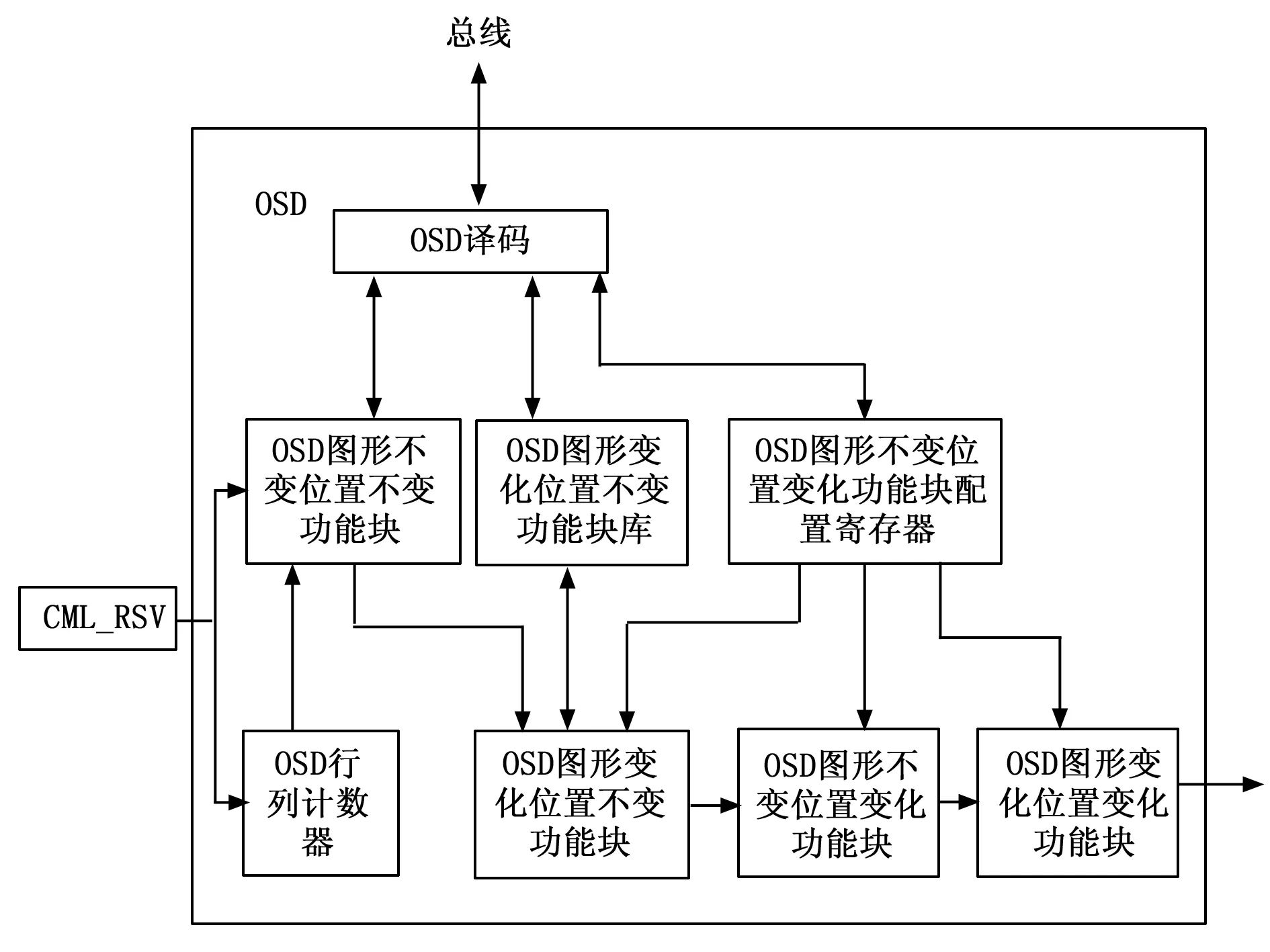
图5 OSD总体结构
上电以后,图像不变位置变化功能块和图形不变位置不变功能块图形都只需配置一次即可,而图形变化位置不变功能块需要配置字符库。计算开始以后,图像不变位置变化功能块根据软件配置相应的坐标即可完成功能,图像变化位置不变功能块需要根据软件配置的读取字符库的地址即可,图像变化位置变化功能块只需要给出坐标,逻辑即可计算出固定图形[8]。
PAL_SND作为视频信号输出端,由于PAL制式视频采用了隔行扫描方式,每帧图像由奇场和偶场合成。对于偶场,有效数据行就是一帧图像的所有偶数行,而对于奇场,有效数据行就是一帧图像的所有奇数行[9]。在FPGA上实现时,内部需要两个双口RAM,一个用来存储奇场有效数据,一个用来存储偶场有效数据。等写入一帧完毕以后,再根据ITU-R BT.656协议通过计数器选择发送消影数据、奇场有效数据和偶场有效数据,合成为一帧完整的图像。该电路总体结构如图6所示。
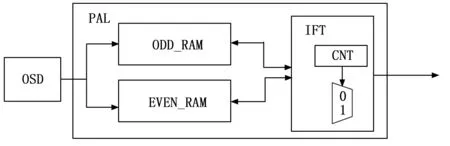
图6 PAL_SND总体结构
2.3 图像存储模块
由于目前需要计算图像数据使用FPGA片内的Block RAM即可满足,暂时没有用到FPGA片外的存储单元(比如DDR RAM或者SDR RAM)[10],而且使用FPGA片内的存储器可以减少存储器管理控制逻辑和电路板布线。
在FPGA设计中,开发了基于综合属性的CBB(common building block)[11]。通过例化模板,改变参数即可实现初始化、不同位宽和深度的Block RAM,可以极大节约时间。以SP RAM为例,其模板如下所示:
module FPGA_SPRAM_1000
(
prarameter RAM_INIT = 0,
parameter BIN_NAME ="spram_ini.bin”,
parameter ADDR_WIDTH = 4,
rarameter DATA_WIDTH = 16
)(
Input clk,
Input ram_en,
Input wh_rl,
Input [ADDR_WIDTH-1;0] addr,
Input [DATA_WIDTH-1;0] din,
output reg [DATA_RIDTH-1:0] dout
);
reg [DATA_WIDTH-1:0] ram_mem[2**ADDR_WIDTH-1:0]
/*synthesis syn_ramstyle= “block_ram"**/;
Initial begin
if(RAM_INIT==0) begin
end
else begin
readmemh(BIN_NANME,ram_mem);
end
end
always @(posedge.clk).begin
if(ram_en=1,b1) begin
if(wh_rl = 1’b1) begin
ram_mem[addr] <=din;
end
end
end
always @(posedge.clk)begir
if(ram_en=I’b1 begin
if(wh_rl=1'b0) begin
dout <=ram_meml[addr]:
end
end
end
end module
综合属性格式是,syn_ramstyle属于attribute,后面value可以是register、block_ram、select_ram。综合工具根据这三种value选择不同的存储单元综合电路。其中register用寄存器搭成存储阵列,block_ram使用18Kbit或者36Kbit的块RAM,select_ram使用32bit或者64bit的分散式RAM。有一点值得注意的是,不同工具的综合属性是不一样的,需要查看工具手册用以区分。
在FPGA中,readmemh函数能够将RAM初始化。将软件产生或者自己编写的bin导入到FPGA电路中,对RAM进行初始化,上电以后RAM存在预期值,从而直接进行读取RAM,而不需要先写值再读取[12]。
2.4 图像运算模块
由于图像预处理以及目标检测、识别和追踪大部分用verilog实现,而不是用C语言,所以在FPGA形成电路以后,工作频率低,不必使用高性能的DSP,使用性能稍差的DSP软核便可完成相应的计算功能。软件可以根据场景改变图像运算模块的参数配置值,同时也能够选择数据通路的路径和各子模块的工作状态。由于这部分内容复杂就不展开讨论,本节仅仅以中值滤波的verilog实现为例[13]。
中值滤波是一种非线性数字滤波器,是图像处理中一个常用的步骤,能够有效地去除斑点噪声和椒盐噪声,而且不模糊图像的边缘,保持图像的清晰度。
中值滤波器算法需要对3×3方形窗的9个像素灰度值进行排序,然后找到中间值替换原始像素。本系统采用一种快速中值滤波的方法,采用二分法进行比较,逐级交叉二分比较,利用并行和流水线的处理方法,完成一次中值滤波器需要36次比较,经过9次比较后便可得出结果,大大加快了中值滤波的计算速度。可以根据FPGA的时序,选择插入寄存器的级数,从而实现不同的运算速率[13]。
假设A>B>C>D>E>F>G>H>I,要求按照从左到有进行由小到大排序,考虑最恶劣场景即为A、B、C、D、E、F、G、H、I,先进行两两比较,最后得出计算结果。计算原理如图7所示。
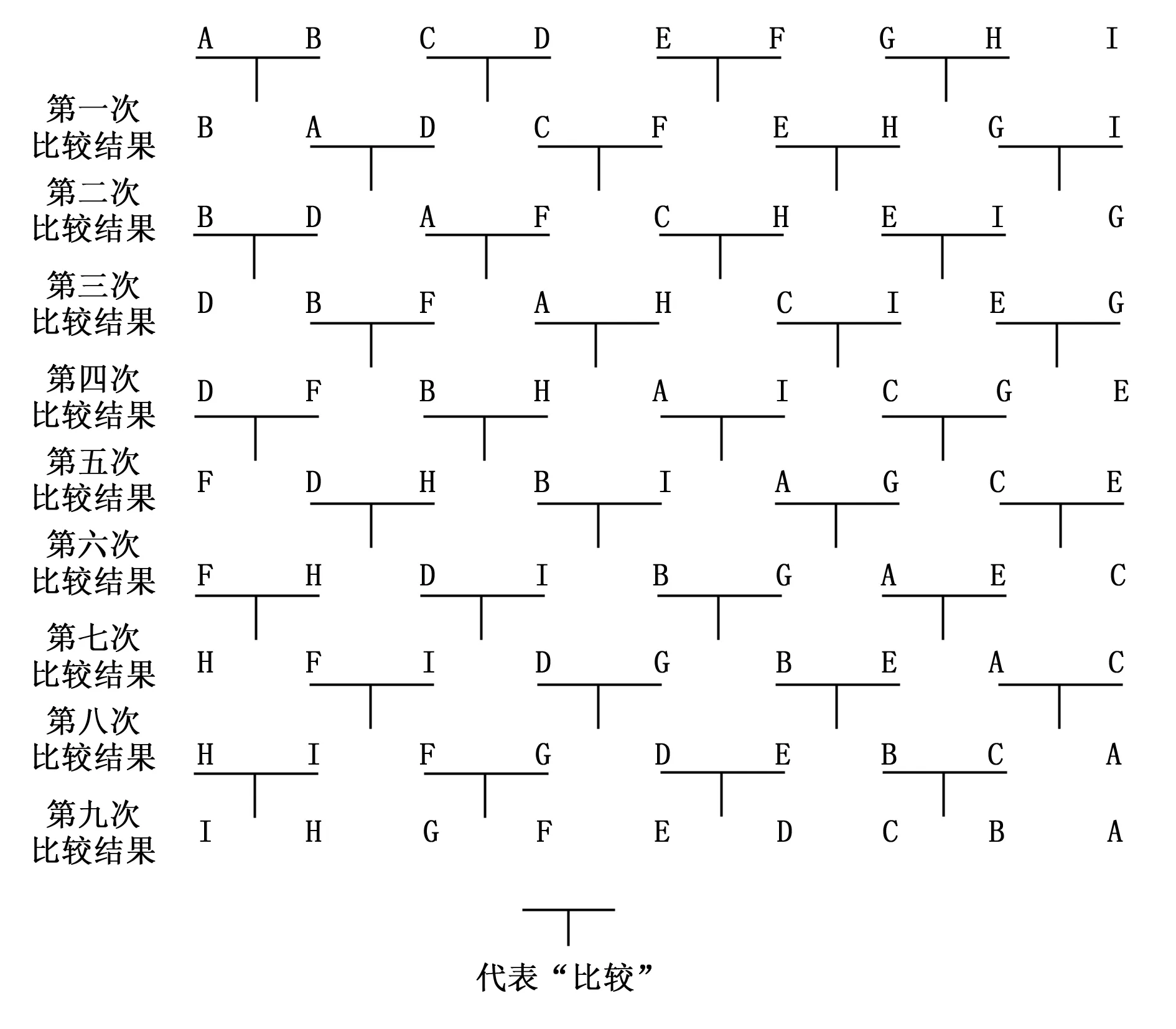
图7 中值滤波器比较算法
2.5 外设控制模块
上电时,FPGA对外设器件需要进行初始化,而且在正常工作时也需要与周边器件交互获取信息检测状态,所以需要设计CPU作为主控,I2C、UART、SPI等作为外设接口。
CPU作为主控单元,使用软核在FPGA内部实现。UART模块能够用于与PC机通信,执行参数写入以及向上位机发送数据等功能,能够实现对系统的FLASH程序升级、程序调试、数据回读。I2C总线是器件互联中常用到的一种总线,用于对外设器件如视频编解码芯片进行初始化。SPI可以实现对符合SPI器件的读写控制,用于对SPI FLASH数据的改写和读取等[14]。
VIC(vector interrupter controller)是中断向量控制器,是管理多个中断请求的模块,能实现每个中断源优先级调整、使能和屏蔽等功能[15]。处理器配置这些中断请求的优先级,VIC确认当前中断请求的最高优先级,将其中最高的中断请求提交处理器。当处理器响应此中断请求以后,保护当前程序或者中断的现场,进入其相应的中断服务程序,在中断服务程序运行结束以后,恢复现场。中断向量控制器主要由中断请求寄存器、中断使能寄存器、中断屏蔽寄存器、中断服务寄存器以及控制逻辑组成,其结构如图8所示。
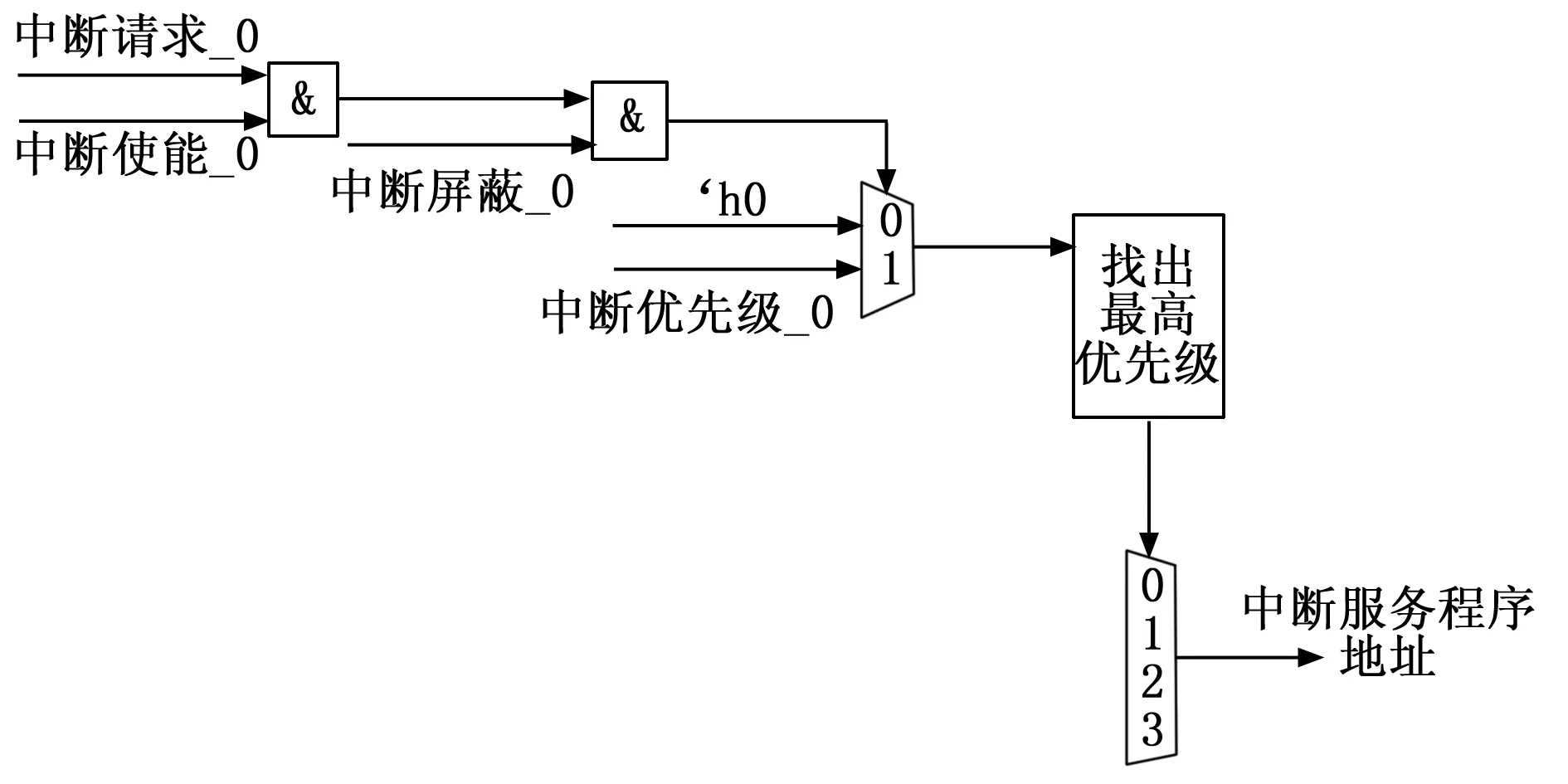
图8 VIC中断框图
PWM_CTRL是脉冲宽度调制的控制器,能够根据图像处理传来的参数,利用PID算法计算出PWM的周期和脉宽,然后将该值传递给PWM模块,从而PWM模块产生PWM波对外部进行控制。
3 实验结果与分析
3.1 实验目的
为了验证本文基于SOC架构的智能图像处理和外设控制系统的设计效果,本章将利用该平台实现大尺度卷积运算,并对其资源消耗进行分析。同时,本文设计的硬件平台的计算性能也将与DSP的计算性能进行比较。
3.2 大尺度卷积运算的性能分析
卷积运算是图像处理领域中非常常见的低层次处理算法。由于卷积操作在遍历时非常耗时,这就使得嵌入式运算时卷积核的尺寸不易过大。然而,以卷积神经网络为代表的深度学习含有大量的卷积操作。本实验将在SOC平台基础上设计一种大尺度的二维卷积硬件模块并对其性能进行分析。
二维卷积运算如式(1)所示。虽然原理很简单,但二维卷积计算并不容易。对于M×N卷积核,单个点的卷积输出不仅需要M×N次输入数据的读取,还需要M×N次乘法与M×N-1次加法。这意味着3×3卷积核需要超过1.35 GOP/S的吞吐量才能对1 280×720的图像实时处理。随着内核尺寸的增加,卷积操作的计算负载和内存访问的复杂度呈指数增长。FPGA内部结构使其非常适合处理低层次像素级并行卷积操作。
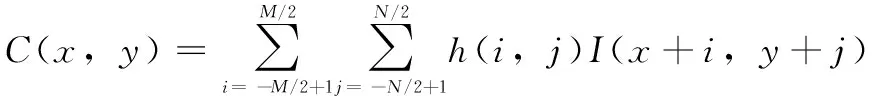
(1)
目前,基于FPGA的卷积操作都是经过裁剪的快速卷积。为了便于相同运算流程下硬件平台的性能分析,本实验采用文献[16]提出的快速卷积运算进行编码。快速卷积的表达式允许估计配置所需的最大资源并评估每个参数的影响,但占用率结果最终取决于优化程度。根据这些性能评估值,就可以在设计的SOC平台上对数据路径进行配置,并且综合和布局布线工具可以修剪不必要的逻辑。
表1展示了不同配置的占用资源平均值和最小时钟周期。Post-place和Route计时结果表明,该方案具有较高的吞吐量。例如,30×30大小的8 bits卷积运算中每个像素的计算时间是14.65 ns,这意味着每秒产生超过1.15亿的输出数据;对于15×15的卷积核,计算一个数据只需要14.01 ns。这意味着在连续数据流和输入数据带宽没有限制的情况下,并行性和流水线使得卷积核的大小对运算时间的影响不是比例增加,但代价是需要更高的资源。
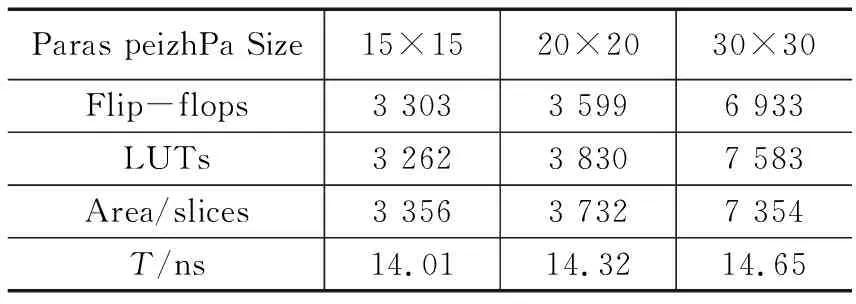
表1 不同卷积尺寸下的资源配置
本文设计的实时SOC架构能够实时处理大尺度二维卷积运算。由于在不同层次上设计并行运算,该平台可以在低时钟频率下实现高性能。同时,该设计能够实现分布式算法,即便采用FPGA通用资源也能实现复杂运算。由于采用模块化卷积操作以及系数独立,因此该平台设计的卷积模块可以实现任何内核大小的卷积操作。通过调整流水线深度和并行度,还可以在特定应用程序的处理数据速率和特定FPGA器件的可用资源之间达到平衡。
表2展示了不同卷积尺寸下DSP卷积运算与FPGA卷积运算的性能对比,其中DSP的芯片型号是TMS320C6678遍历执行执行卷积操作,SOC架构下的卷积操作采用传统的卷积运算,并不是采用文献[16]的快速算法,便于性能比较算法一致性。可以看出,采用本文设计的SOC平台可以将计算时间锁定在微秒范围内,具有非常高的实时性,而DSP运算即便开优化也在毫秒级的计算时间。时序分析结果也表明,该架构具有很高的吞吐量,能够实时处理高清图像。通过对不同尺寸的卷积处理结果也表明内核大小和数据分辨率的增加都不会影响处理性能。
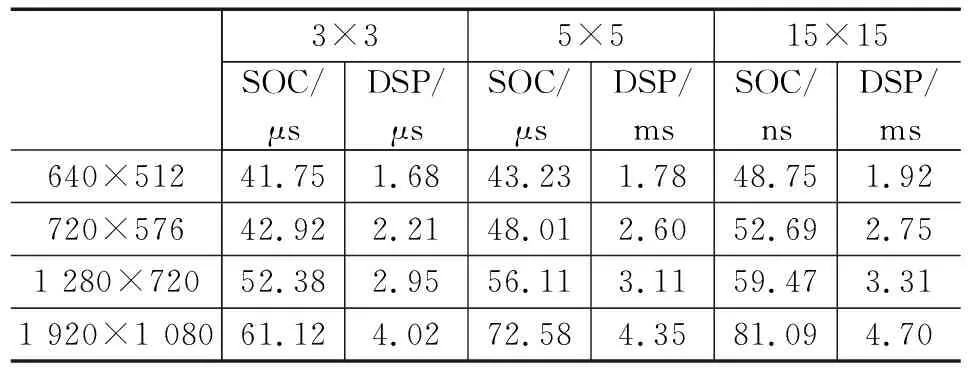
表2 不同平台下卷积运算性能对比
4 结束语
本文设计了基于SOC架构的智能图像处理和外设控制系统,该系统可以在一片FPGA上实现,结构比较简单,外设模块功能清晰明了,而且可以根据需求的变化进行调整,同时在片上集成实现了图像处理算法使得对DSP依赖程度下降成为可能。电路设计结构精简,模块化和参数化高,能够根据场景配置不同的算法通路和参数,可推广诸多图像处理领域。通过对大尺寸卷积运算的验证试验结果表明本文设计的SOC架构具有通用性好、可靠性高、处理速度快和控制精准的特点,能够完全适应高复杂的卷积运算。
猜你喜欢
农业工程学报(2022年7期)2022-07-09
电脑知识与技术(2022年9期)2022-05-10
电脑知识与技术(2022年9期)2022-05-10
计算技术与自动化(2022年1期)2022-04-15
科技创新与应用(2018年23期)2018-09-13
电子技术与软件工程(2018年1期)2018-03-22
科教导刊·电子版(2016年36期)2017-04-22
现代计算机(2009年9期)2009-12-02
现代计算机(2009年5期)2009-08-27
现代计算机(2009年6期)2009-08-22
