
基于深度特征融合的三维动态手势识别
2021-04-29 09:11:10席志红徐细梦
应用科技 2021年1期
席志红,徐细梦
哈尔滨工程大学 信息与通信工程学院,黑龙江 哈尔滨 150001
随着现代科学技术的快速发展,计算机和人之间的交互已经成为人类生活中不可或缺的一部分。早期的手工检测是基于可穿戴传感器[1],例如数据手套,虽然基于数据手套的手势识别方法获得了不错的效果,但是存在需要精确校准、价格昂贵以及对手有束缚等缺点。后来研究者们提出基于RGB视频的不同模型手势识别方法,比如条件随机场模型(conditional random fields model,CRFM)[2]、动态时间规整(dynamic time warping,DTW)[3]、动态贝叶斯网络(dynamic bayesian networks,DBN)[4]以及隐马尔可夫模型(hidden markov model,HMM)[5]等识别模型,但是考虑到颜色、光照、遮挡和复杂背景等不同的干扰因素,手势识别效果不是很好。近年来,微软Kinect深度相机的出现得到了这一领域学者们的高度关注,这种深度相机功能强大且价格相对实惠,在人机智能领域中有着更广阔的前景。
在本文中,将基于深度视频序列手势数据集生成深度运动图(depth motion map,DMM)[6],运用梯度方向直方图(histogram of oriented gradient,HOG)[7]和局部二值模式(local binary patterns,LBP)[8]进行特征提取,将提取到的特征送入极限学习机(extreme learning machine,ELM)[9]中 进 行 分 类 识别,提出了一种效率高的手势动态识别算法。首先,提出一种新的基于关键帧提取的多级时间采样(multilevel templing sampling,MTS)方法,用于生成长、中和短深度视频序列。然后,对于每个深度视频序列,将每一帧被投影到3个正交笛卡尔平面上,从而生成对应的3个投影视图(正面、侧面和顶部)的投影地图,计算连续投影映射之间的绝对差的和形成3个不同视角的深度运动图(DMMs,即DMMs、DMMf及DMMt)[10]。HOG特征描述符能够描述图像中局部形状和外观信息,而LBP能够描述图像的局部纹理特征,通过计算DMMs图像中的HOG特征和LBP特征,生成了6个不同的特征向量,通过特征加权融合的方式依次连接起来,形成最终的特征向量。最后,利用局部特征聚合描述符(vector of locally aggregated descriptors,VLAD)[11]进行编码主成分分析(principal component analysis,PCA)[12]对输入的 向量进行降维,用ELM算法对动态手势[13]进行手势识别。
本文研究的主要工作可概述为:
1)利用DMMs、HOG和LBP算法计算了2个特征描述子。DMM用来获取深度视频序列中的的特定外观和形状,然后在生成的3个不同视角的深度运动图中分别使用HOG和LBP来获取图像的轮廓和纹理特征,所获取的特征增强了对手势识别算法的能力。
2)将特征加权融合方法应用于特征串行融合中。通过提取到的HOG特征和LBP特征,进行2∶1权重分配,有利于实现对手势图像信息的融合与深度利用,有效提升最后特征表示的效果。
3)在公开具有挑战性的手势动作数据集MSR-Action3D[14]上采用交叉主题测试。将20个动作划分为3个动作子集(AS1、AS2和AS3),每种动作由10个不同的测试者录制。对于每个动作子集,采用5个测试者(1、3、5、7和9)用于训练,其余用来测试。这种类型的交叉主题测试有利于提高实验的准确性。
1 主要内容
1.1 系统介绍
本文手势识别系统框图如图1所示。

图1 手势识别系统
在手势识别系统中,通过输入深度手势视频序列,将对手势图像进行预处理以及手势分割,对分割出来的手势进行跟踪以追踪手势的去向,运用特征提取算法提取出相应的手势特征,最后利用分类算法对提取的特征进行分类识别。
1.2 多级时间采样
手势识别的一个难点在于识别同一手势由于不同的执行速度而产生识别结果的偏差。解决此问题的一个简单的方法是通过选择随机帧进行下采样;然而,可能造成未选择帧中的重要信息的丢失。为了解决这个问题并尽量保留未选择帧的重要信息,因此运用多级时间采样的方法。
首先,计算出每一帧的运动能量,通过累加来定义每一帧与下一帧在所有像素上的差异值:
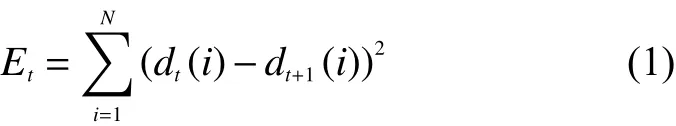
式中:dt代表的是输入视频的第t深 度帧;N代表的是每一帧中所有像素的个数;Et代表每一深度帧的运动能量。
然而为了选择相关视觉信息的帧(即识别不同手势,最大限度地利用原始视频中包含的信息),根据运动能量的变化率对输入帧进行采样,如式(2):

为了采集M帧视频,首先选择第一帧和最后一帧,然后从剩下部分取样最高ΔE值 的M-2帧。因此,从原始视频中提取3个级别的长、中、短时间样本。其中,长视频是原始视频,中视频包含原始视频长度的50%,短视频是包含原始视频长度的30%。如图2所示,其中图2(a)为长视频中一帧,图2(b)为长视频中一帧,图2(c)为短视频中一帧。
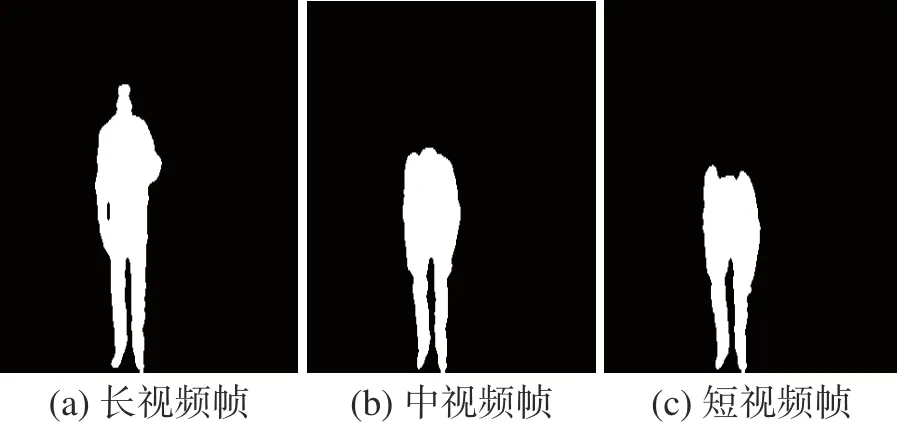
图2 长、中和短运动帧
1.3 时间深度运动图(DMM)
在DMMs构建过程中,深度视频序列投影到正交笛卡尔坐标系中,根据Kinect坐标系的3个不同视角的原理,可以生成3个不同的视角:正视、侧视和顶视。手势深度图的正视投影图、侧视投影图和顶视投影图分别记作 mapf、 maps、 mapt,对于正视图,可以通过计算连续投影地图序列之间绝对差来得到其运动能量,并接着积累整个动态手势深度视频序列的运动能量来构建深度运动图 DMMf。同 理,侧 视图 DMMs和 顶视 DMMt也 可 以构建出来。每个深度序列DMM使用以下的公式来构建:
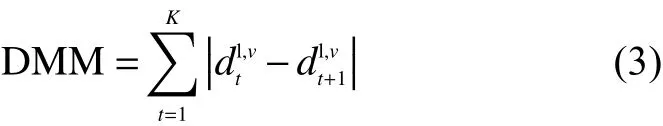
式中:K是剪辑的长度。长视频、中视频和短视频分别选择16、8和4。l2{long,middle,short},v2 ffront,side,topg,图3分别展示的是一个手势动作的的正视投影图、侧视投影图和顶视投影图。

图3 深度运动图构建过程
1.4 局部二值模式
深度运动图由于覆盖重写变得很模糊,应该用传统经典有效的算法来增强手的形状信息以便分类器能更好地进行分类识别。局部二值模式是一种非常有效的旋转不变纹理描述工具,因其计算简单、鉴别能力强等等优点而被广泛应用。为了获取图像的纹理特征,利用LBP进行编码图像,在LBP编码图像过程中原始像素用编码局部纹理信息的十进制数标注。原始的LBP算子工作在3×3的像素块,以中间像素f(x,y)为圆心,中心像素周围都被中心像素阈值化,并按2的幂进行加权,然后求和到标记中心像素。LBP运算符也可以扩展到大小不同的邻域,考虑由 (N,R)表示的圆形邻域,其中N是采样的数目,R是圆形的半径。像素 (x,y)的LBP标签的计算过程如图4所示,其中N=8,R=1。每个中心像素 (x,y)周围有8个邻域像素点,每个邻域像素点与中心像素点进行比较,当大于等于中心像素点时,则这个邻域像素点的值就被置为1。

图4 中心像素的LBP标签的生成过程
同理,当小于中心像素点时,则这个邻域像素点的值就被置为0,中心像素 LBPp计算为
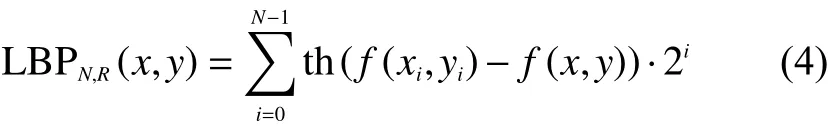
式中:当x≥0,则th(x)=1;当x<0时,则th(x)=0。中心像素点的标注值则由N个邻域像素点二进制的十进制形式,其中对原算子的另一个扩展则称为一致模式,当二进制模式有最多2个从0到1的转变时,则认为这个局部二进制模式是一致的,当位模式是圆形时则相反。比如,模式00000000(0过渡)和00010000(2过渡)是一致模式,而其他模式例如01010001(5过渡)则为非一致模式。通过计算图像中所有像素的LBP值后,得到图像或图像区域的直方图来表示所获得的图像纹理特征。
1.5 方向梯度直方图
在一幅图像中,局部目标的表象和形状能够被梯度或边缘的方向密度分布很好地描述。方向梯度直方图常用来描述图像特征的特征描述子,因其在局部单元格上进行操作,对局部光照、几何形变具有良好的不变性,跟其他特征提取算法相比具有一定的优势。
HOG特征提取的主要思想是将整个图像分成多个连通区域(即细胞元),然后通过计算每个连通区域中各像素点所对应的梯度方向直方图,最后依次顺序连接所获得的直方图构成特征描述器。
方向梯度直方图算法的具体实现过程如下:
1)将要分析的图像进行灰度归一化。
2)计算图像中每个像素的梯度。
对于每一幅图像而言,都可以用水平方向和垂直方向的梯度进行表示,这2个方向的导数可以表示为dx和dy,则可以通过梯度算子[ 1,0,1]T和[ 1,0,1]得出,每个细胞单元中像素的梯度信息z可以由dx和dy表示为

继而每个细胞单元中像素的梯度信息转化为极坐标信息,其中幅度A和 偏移角度 θ分别为
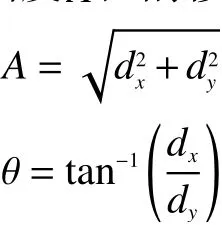
3)将图像划分为细胞元(cells)。
首先将图像划分为较小的单元格,假如本文图片大小为256×256的统一尺寸,再将图像分割成大小16×16的单元格,然后2×2个单元格构成一个块(block),最后所有的block组成图像。
4)将块(block)内所有的cell特征串联起来便得到该块(block)的HOG特征描述符。
5)同理,将图像中所有块的HOG特征描述符串联起来就得到该整幅图像的HOG特征描述符,这个就是最终用来进行分类识别所用的特征向量了,图像分割示意如图5所示。
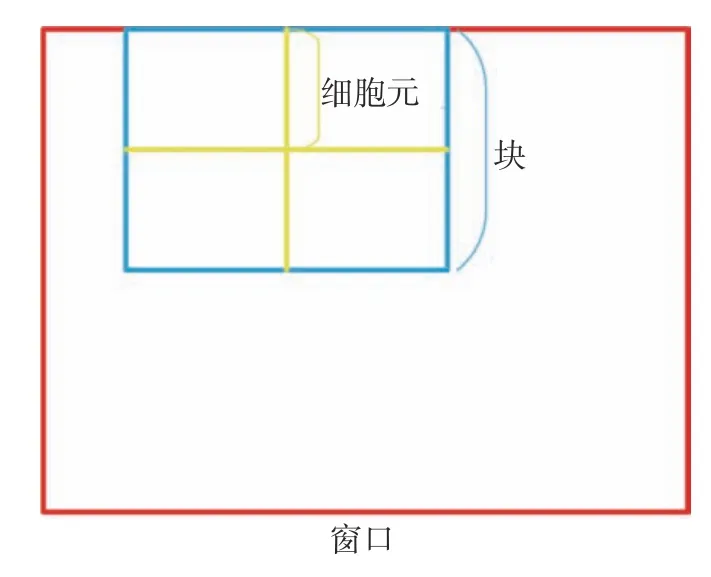
图5 图像分割示意
1.6 主成分分析
在提取特征后,需要降维来保留一些重要的特征,去除一些冗余信息,从而实现提高数据处理速度的目的。具有使得数据集更易使用、降低算法的计算开销和去除冗余信息等优点。本文PCA值设置为130,最终训练集降维到130×283,测试集降维到130×273。
主成分分析算法的具体实现如下:
1)将 原 始 数 据 按 行 组 成m行n列 样 本 矩阵X(其中每行为一个样本,每列为一维特征)。
2)求出样本X的协方差矩阵C和样本均值m。
3)求出协方差矩阵D的特征值及对应的特征向量V。
4)将特征向量根据对应特征值大小从按行排列成矩阵,取前k行组成矩阵P。
5)Y=(Xm)·P即为降维到k维后的数据。
1.7 极限学习机(ELM)
极限学习机最大的优势在于:1)输入层和隐含层的连接权值、隐含层的阈值可以随机设定,一旦设定完后则不用再调整。2)隐含层和输出层之间的连接权值β不需要迭代调整,而是通过解方程组方式一次性确定。这样的好处是提高了速度,且模型的泛化能力也得到提高。
ELM可以通过随机初始化输入权重和偏置得到相应的输出权重。对于一个单隐层神经网络,假如有N个任意的样本 (Xi,ki),其中:
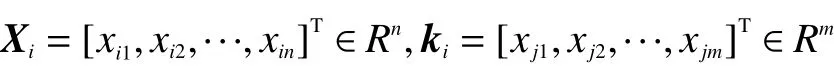
则对于一个有L个隐层节点的单隐层神经网络可以表示为
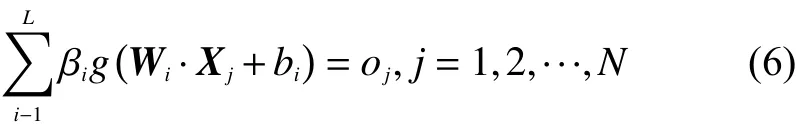
式中:g(·)为 激活函数;Wi=[wi,1,wi,2,···,wi,n]T为输入权重;βi为输出权重;bi是第i个隐层单元的偏置。Wi·Xj表示W和Xj的内积。单隐层神经网络学习的目标是使得输出的误差最小,可以表示为
2 实验与结果分析
在本节中,将给出手势识别系统实验结果来证明系统在公共数据集MSR-Action3D的动态深度序列数据集中的性能。所有实验均在CPU intel i7和16 GB内存的计算机上运行。
2.1 数据集和设置
MSR-Action3D数据集包含20个动作,每个动作由10个不同的被试者面对RGB-D摄像机执行2次或3次。20项动作包括高臂波、横臂波、锤子、手接、前拳、高抛、抽签X、抽签、画圈、手拍、两手波、侧拳、弯、前踢、侧踢、慢跑、网球挥杆、网球发球、高尔夫球挥杆和捡抛。每次由10名受试者表演2次或者3次,帧速率为15 f/s,分辨率为320×240。删除此数据集的背景,这个数据集最重要的挑战是相互作用的相似之处,它只包含深度视频序列。检抛动作如图6。
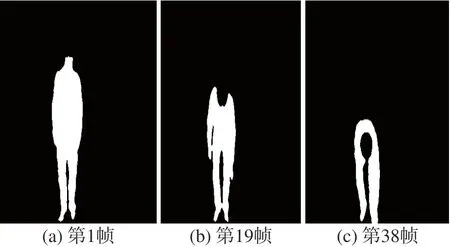
图6 捡抛序列过程
交叉主题测试的具体实现为:将20个动作划分为3个动作子集(AS1、AS2和AS3),如表1~3所示。对于每个动作子集,5个被试者(1、3、5、7和9)用于训练,其余用于测试。
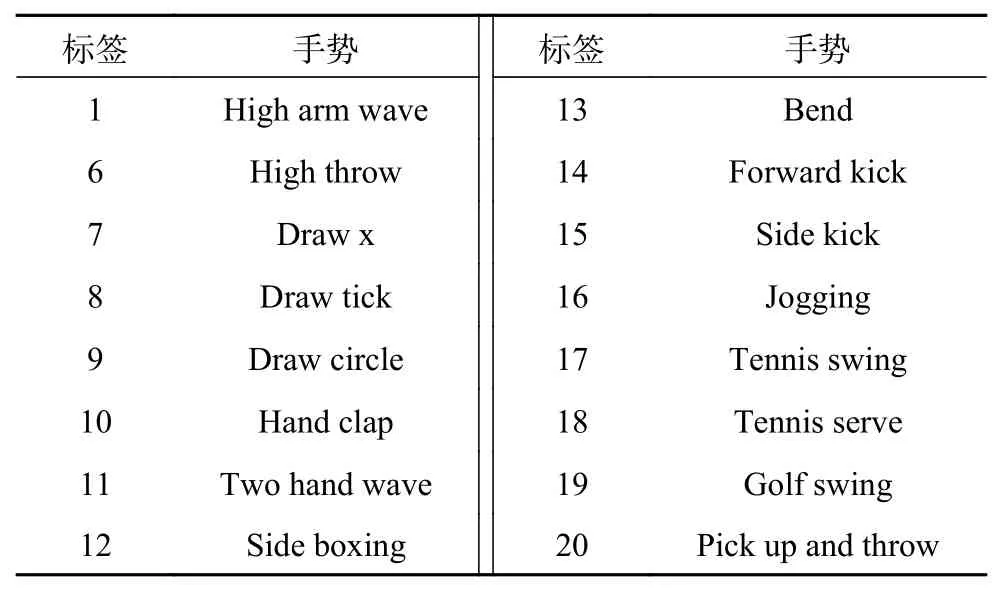
表1 MSR-Action3D子数据集1(AS1)
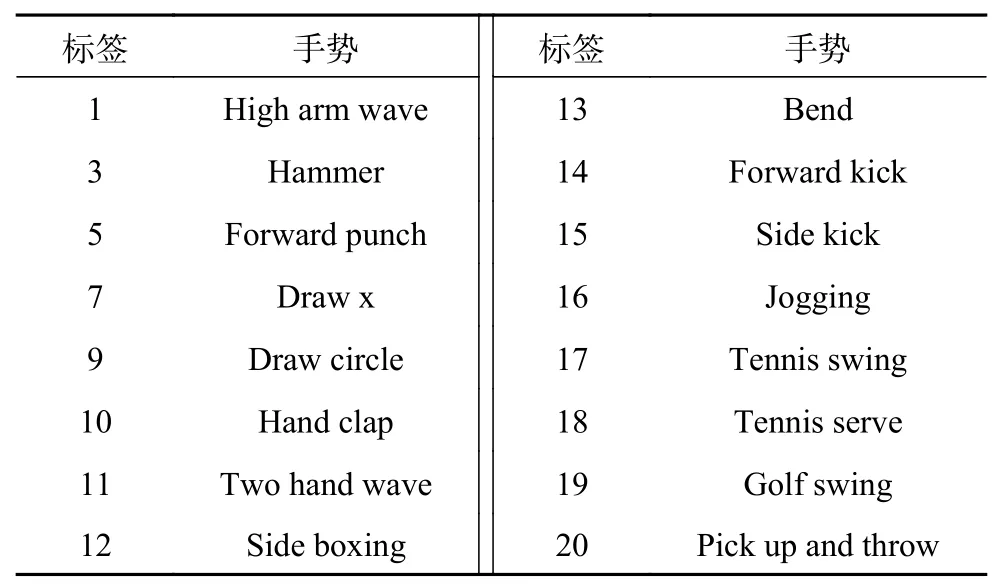
表2 MSR-Action3D子数据集2(AS2)
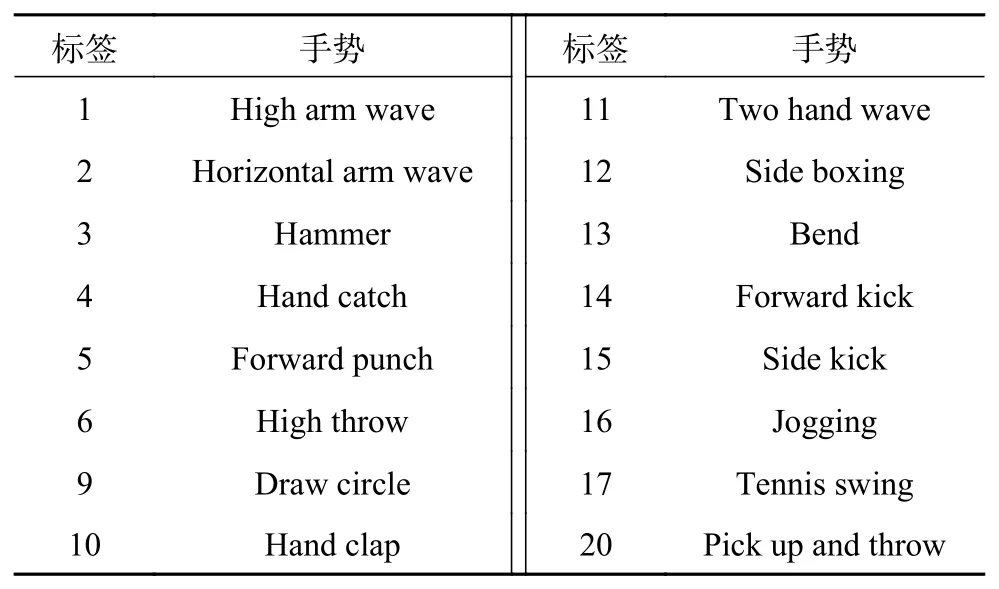
表3 MSR-Action3D子数据集3(AS3)
在所有的实验中,对每一个深度视频序列,删除第一帧和最后一帧。因为在动态手势视频序列中的开头或结尾,实验者大部分是处于静止站立的位置,运动的幅度特别小,这对于实验者的运动特性来说是完全没有必要的。其次,因为在DMM的计算过程中,开头和结尾运动特性小导致会存在大量的识别误差。
为了找到LBP计算中的参数N(采样点数)和R(半径)找到一个合理的值,本实验对 (N,R)的不同值分别进行了实验。分别对半径R选择了6个值{1,2,…,6},对采样点数N选择了4个值{4,6,8,10},通过观察可知参数对(4,8)的结果最佳。由于基于均匀模式的LBP直方图特征的维数是N(N−1)+3N,因此LBP特征的计算复杂度取决于采样点数,即是N。由于参数对(4,8)具有较高的识别效果和较低的计算复杂度,因此为整个实验设置了N=8和R=4。同时,为了提高实验分类步骤的计算效率,本实验采用主成分分析(PCA)方法来降低特征向量的维数。
2.2 计算复杂性分析
表4给出了手势识别中每个算法步骤所花费的时间百分比。多级时间采样(multilevel temporal sampling,MTS)的提取包括2个过程:计算序列中每个帧的运动能量,然后进行排序,选择运动能量最高的帧。第1部分是O(N), 其中N是帧内的像素数;第2部分是O(Tlog(T)) ,其中T是视频的长度,已知T=N。LBP和HOG特征提取的计算复杂度也是O(N)。VLAD编码包括2个部分:首先创建可视单词字典,然后将每个示例分配给可视单词。计算的复杂度为O(nk), 其中:n是数据集的全部样本数,k是可视单词的数量。

表4 算法步骤运行时间比例
2.3 不同方法的比较
本文实验首先针对20种手势动作组成的MSRAction 3D深度序列数据集进行研究手势识别系统的性能。该数据集的每类手势动作由10人进行2次或3次,帧速率为15 f/s,分辨率为320×240,删除了此数据集的背景,这个数据集最重要的挑战是相互作用的相似之处。实验1对手势深度序列进行多级时间采样,然后分别对长、中和短深度序列映射到笛卡尔坐标系进行正视、侧视和顶视深度运动图转换,此时有6种不同的深度运动图,将提取每种深度运动图的HOG特征和LBP特征,对提取出的每种特征向量进行VLAD编码和PCA降维,最后将2种特征向量进行串行融合,采用极限学习机进行分类识别。实验一动作识别结果如图7所示。实验2在实验1的基础上为了提取到的特征更好地识别,将提取到的2种特征2HOG:1LBP权重进行串行融合,最终生成了6个不同的特征向量:Front_RHOG为72×540、Side_RHOG为72×972、Top_RHOG为72×405、Front_RLBP为59×480、Front_RLBP为59×864、Front_RLBP为59×360,其中从深度运动图中提取的Front_RLBP纹理信息结果例子如图8所示。
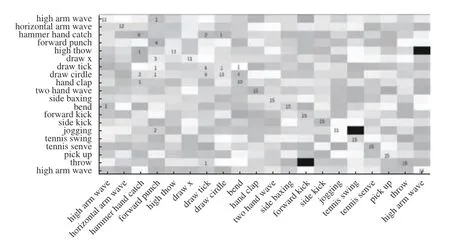
图7 实验1混淆矩阵

图8 LBP特征结果
实验3是在实验1的基础上将对556个深度序列划分为3个子集,分别对每个子集中的5个实验者(1、3、5、7和9)进行训练,其余用来测试,最后得出3个子集的平均识别准确率。
文献[13]中提出了一种实时骨架估计算法,新的骨骼表示法中利用三维空间中的旋转和平移,显式地模拟了不同身体部位之间的三维几何关系;文献[14]提出了一种基于稀疏编码的时间金字塔匹配方法(time pyramid mathing based on sparse codeing, ScTPM);文献[15]提出了基于深度运动映射(DMMs)、等高线变换(contour transformation, CT)和直方图(HOGs)的基于深度视频序列的人体动作识别框架;文献[16]提出了一种基于深度梯度局部自相关(gradient local autocorrelation characteristic, GLAC)特征和局部约束仿射子空间编码(locally constrained affine subspace coding,LCASC)的三维动作识别算法;文献[17]以基于线性支持向量机的人体检测为例,研究了基于特征集的鲁棒视觉目标识别问题;文献[18]提出从深度序列中组合局部相邻的超曲面法线来将表面法线扩展为多法线,以共同表征局部运动和形状信息方法;文献[19]提出一种基于深度序列关键帧运动能量的多级时间采样(MTS)方法。从实验结果来看,实验2和实验3的识别率均比实验1更高,且实验3识别率相较文献[13]方法和文献[17]方法从骨骼数据提取特征、文献[14]方法和文献[18]方法从手的时空体积提取位置、方向和速度等特征、文献[15]方法从DMMs提取轮廓特征和文献[19]方法利用二维卷积神经网络提取空间特征更好,详见表5。
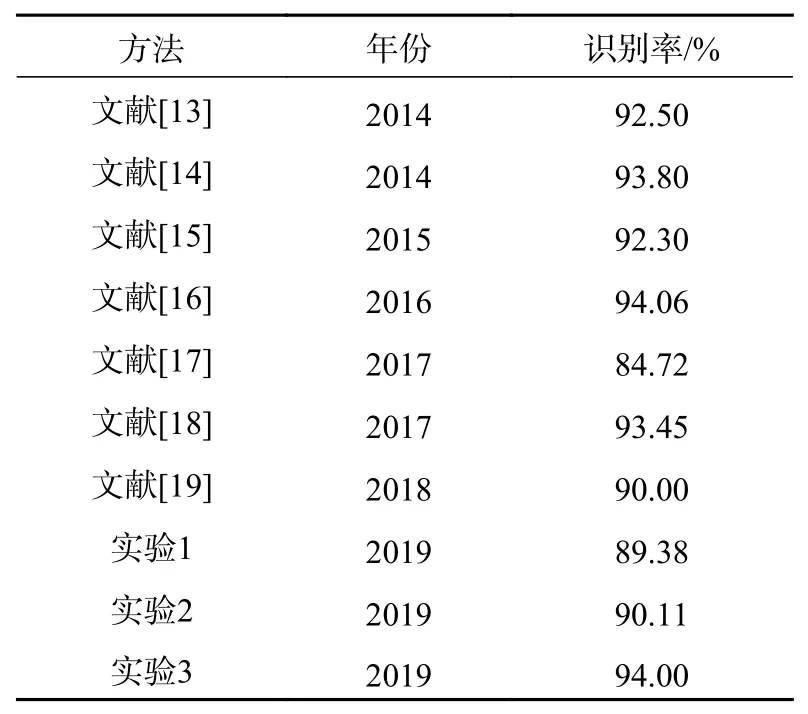
表5 MSR Action 3D性能比较
3 结论
本文针对深度视频序列采用多级时间采样提取3种不同长度的时间序列,并进一步提取深度运动图,采用HOG算法和LBP算法进行特征提取,将2种算法提取的特征进行加权融合输入到ELM分类器中进行分类识别,并在公开数据集MSR Action3D上进行交叉主题测试实验。实验结果表明,实验2和实验3在实验1进行HOG和LBP提取算法进行融合的方法基础上显示出了比较好的识别率,且实验3基本上比表5中所用的其他方法好,是能实现实时动作识别的一种高效的人体动作识别方法。下一步工作将继续提高动态手势识别的识别精度,增加更多的不同的手势类,并同时降低运行的时间。
猜你喜欢
艺术家(2023年8期)2023-11-02 02:05:28
小哥白尼(军事科学)(2022年2期)2022-05-25 13:19:30
中学生数理化·七年级数学人教版(2020年11期)2020-12-14 06:59:52
红领巾·萌芽(2019年9期)2019-10-09 03:42:56
红领巾·萌芽(2019年8期)2019-08-27 15:30:15
艺术品鉴证.中国艺术金融(2018年8期)2019-01-14 01:14:28
艺术品鉴证.中国艺术金融(2018年10期)2019-01-08 02:44:26
小学科学(学生版)(2018年12期)2018-12-19 05:13:50
艺术品鉴证.中国艺术金融(2018年12期)2018-08-26 06:03:48
小学阅读指南·低年级版(2017年6期)2017-06-12 01:39:24
