
基于感兴趣区域的H.265样点自适应补偿算法优化
2021-04-29 03:37张红升邓宇静王国裕
重庆邮电大学学报(自然科学版) 2021年2期
张红升,陈 涛,邓宇静,王国裕
(重庆邮电大学 光电工程学院,重庆 400065)
0 引 言
H.265/HEVC(high efficiency video coding)采用基于块的混合编码框架,振铃效应是这种编码方式广泛存在的失真效应之一[1]。为了降低振铃效应对视频质量的影响,H.265/HEVC引入了样点自适应补偿技术,但同时也增加了编码复杂度[2]。文献[3]提到降低复杂度最明显的方法之一就是限制样点自适应补偿(sample adaptive offset,SAO)类型候选对象的数量,采用的是次抽样的方案进行优化。文献[4]对时间基层与高层时间层的关系进行了分析,优化了SAO的编码流程。文献[5]利用图形直方图,针对不同大小的树形编码块提出了一种边带补偿改进方法。文献[6]通过实验证明了编码单元深度的划分与纹理复杂度的关系,只对复杂的编码单元执行SAO滤波器以优化SAO,降低编码复杂度。文献[7]在文献[6]的基础上,进一步证明了量化参数(quantization parameter,QP)值与纹理复杂度之间的关系,通过跳过自适应滤波补偿值为0的像素,达到了降低编码复杂度的目的。上述方法仅分析了视频的空间域特性,而忽略了视频时域特性。为此,本文结合人类视觉系统(human visual system,HVS)特性[8],同时利用时域和空域信息,对样点自适应滤波算法进行优化,以提高编码效率。
1 样点自适应补偿算法相关技术原理
H.265/HEVC编码过程中,无论量化参数QP如何变化,都会因为高频量化过程中的失真产生振铃效应[1,9]。视频重建帧中振铃现象示意图如图1。图1中,实线表示像素在不同位置时的像素大小,圆点表示重构图像的像素值。可以看出,重构像素值在原始像素值附近波动,这种波动会造成图像质量的下降。
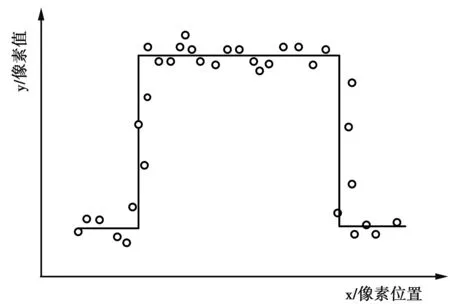
图1 视频重建帧中振铃现象示意图Fig.1 Schematic diagram of ringing in video reconstruction frames
解决振铃效应的基本思想是对波峰值像素添加负值进行补偿,波谷添加正值进行补偿,从而减少原始图像和重构图像之间的误差。主要有3种补偿形式:边界补偿(edge offset,EO)、边带补偿(band offset,BO)和参数融合技术(merge)[1]。
1.1 边界补偿
通过比较当前像素值和相邻像素值的大小对当前像素进行归类,然后对同类像素补偿相同值。共4种模式:水平模式(EO_0)、垂直模式(EO_1)、135°模式(EO_2)和45°模式(EO_3),如图2。其中,N1,N2表示相邻像素。每种模式又分为5个不同种类,如表1。
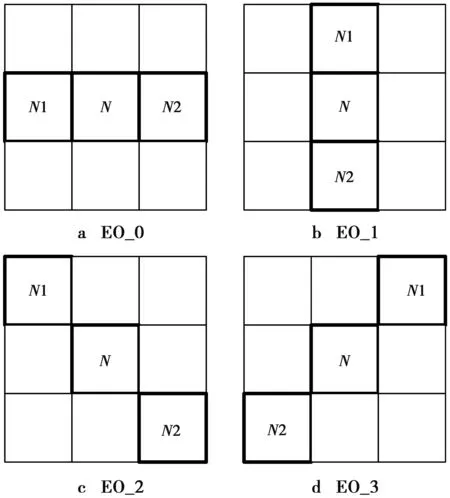
图2 4种边界补偿Fig.2 Four kinds of boundary compensation

表1 边界补偿分类
1.2 边带补偿
根据像素值强度,将像素值的取值范围等分为32条边带,每条边带都包含一组连续的像素值。例如,对于一个8 bit像素值,其值为0~255,总共32条边带,因此,一个边带包含8个连续的像素值。用8q~8q+7(q=0,1,2,…,31)的像素点范围表示第q条边带,然后对每个边带进行像素补偿值的计算[1]。根据同一编码单元像素点分布特性,在H.265标准中仅使用了4条连续边带进行补偿,如图3。

图3 边带补偿Fig.3 Sideband compensation
1.3 参数融合
参数融合模式(merge)采用上相邻块或者左相邻块来预测当前编码模块的SAO参数,如图4。其中,A,B是已经编码的模块;C是当前编码模块,如果采用参数融合模式,那C只需要传送融合标志位即可。
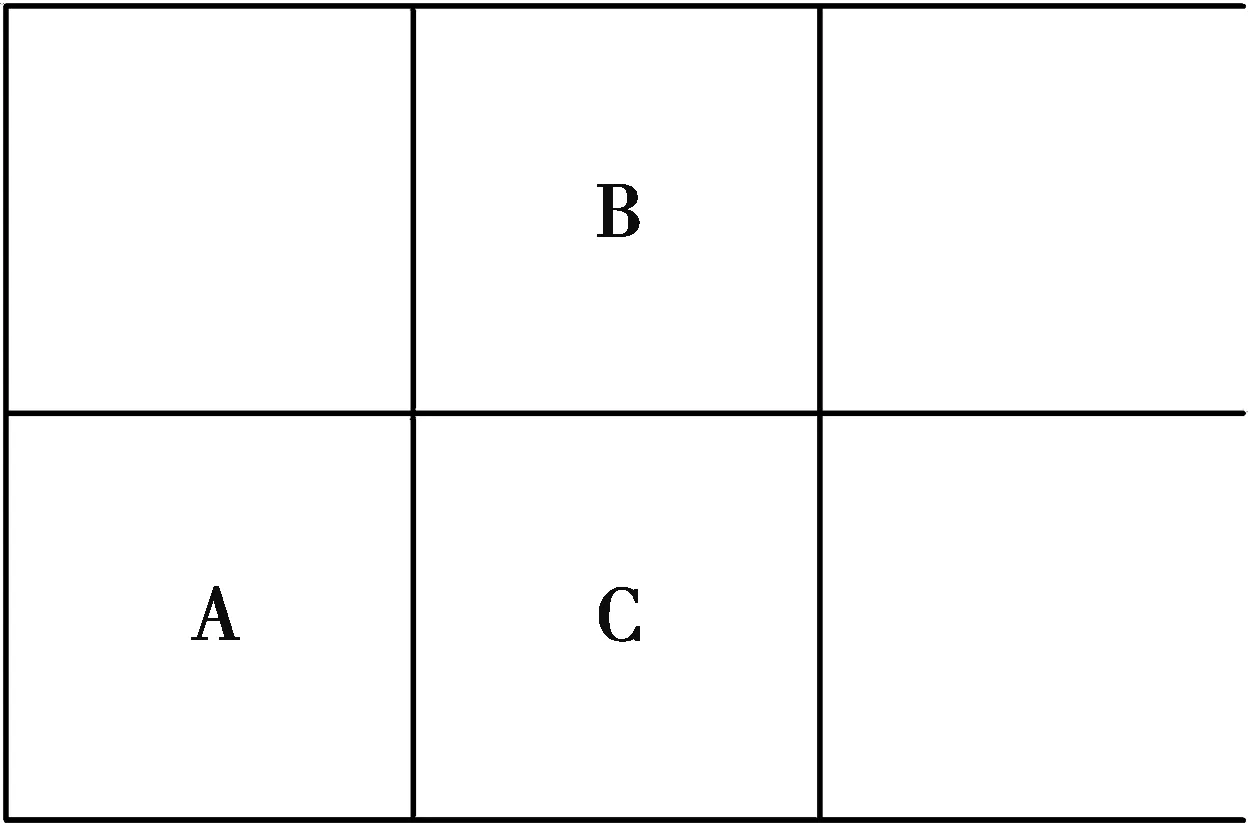
图4 参数融合模式Fig.4 Parameter fusion mode
2 基于感兴趣区域的算法思想
2.1 算法思想
人类视觉系统(human visual system,HVS)特性表明,人眼对图像的不同部分的感知度是不同的[8]。对人眼影响较大的区域称为感兴趣区域(region of interest,ROI),而相应的其他区域则称为非感兴趣区域或背景区域(background,BC)[10]。依据人类视觉系统的特点,在观看视频过程中,如果非感兴趣区域出现少量的失真情况,人眼不会特别敏感。目前已经确认影响视觉注意力的低层次原因主要包括对比度、形状、运动、尺寸、位置等因素[11]。这些因素在时间域可由图像的运动块来表征;在空间域,则与图像的边缘信息和纹理复杂区域密切相关[12-13]。
由于在H.265技术中,图像纹理越复杂,所使用编码单元尺寸越小,编码单元深度值Depth越大;而图像纹理越简单,编码单元的尺寸越大,编码单元深度值Depth则越小[14],编码单元划分示意图[7]如图5。因此,可以把运动区域和Depth较大的区域定义为人眼感兴趣的区域。按照这种思路,本文将从时域和空间域2个角度对SAO算法展开分析。
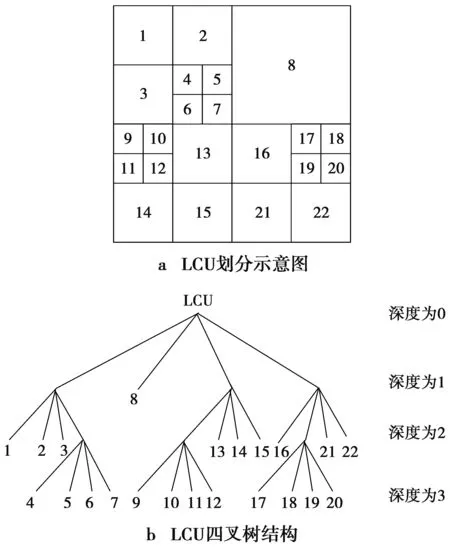
图5 编码单元划分示意图Fig.5 Schematic diagram of coding unit division
2.2 算法分析及优化
2.2.1 基于编码单元深度的空间域SAO优化
图6显示了BasketballPass测试序列视频帧编码单元划分。从图6中可以得知,人眼感兴趣的区域如人的轮廓、篮球等单元划分深度较深,而非感兴趣区域如地板等背景区域单元划分深度较浅甚至为0。

图6 BasketballPass测试序列第1帧IDR帧Fig.6 BasketballPass test sequence 1 IDR frame
针对空间域中单元划分深度和纹理特性分布,文献[14]详细分析了编码单元纹理特性,文献[7]证明了量化参数QP和单元划分深度Depth成反比例关系,文献[15]论证了图像纹理的复杂程度和编码单元深度Depth成正比例关系。从图6观察可知,在空间域中尺寸小于16×16的编码单元(coding unit,CU)块纹理较复杂,分布在人眼感兴趣区域;而尺寸为64×64的CU块,纹理特征简单,位于人眼不感兴趣的区域。

(1)
由公式(1)可知,对Depth≤2的区域可以不必做标准SAO处理,从而节约大量运算。
2.2.2 基于运动矢量的时间域SAO优化
图7显示了BasketballPass测试序列视频帧运动矢量分布图像。从图7中可知,人眼感兴趣的区域如人的轮廓、篮球等单元运动矢量较密集,而非感兴趣区域如地板等背景区域运动矢量疏松,其值较小甚至为0。可见,通过运动矢量参数MV可以从时间域的角度判断人眼感兴趣的范围[12]。

图7 BasketballPass测试序列第6帧P帧Fig.7 BasketballPass test sequence 6 P frame
H.265/HEVC在进行SAO处理过程中,采用最大编码单元(largest coding unit,LCU)(尺寸为64×64)作为基础来决定SAO补偿范围。在帧间预测的过程中,每个LCU块会产生并保存256个尺寸为4×4的CU块运动矢量。考虑到4×4的CU块运动矢量的乱序性,一般的方法是采用了256个CU块的运动矢量平均值作为当前LCU块的运动矢量,如公式(2)。
(2)
(2)式中,N为一个LCU中4×4大小的CU块数量。
文献[12]为了简化计算过程,仅计算了256个CU块的运动矢量的水平分量和垂直分量。如公式(3)。
(3)
此时每个LCU块仍需要累加512次,复杂度仍然很高,且由于运动矢量可能有正值也有负值,通过简单的求和并不一定能够表征当前LCU的运动矢量特性。
考虑到CU块运动矢量变化具有区域相关性,所以可以对LCU进行抽样处理,而不必计算每个4×4 CU块的运动矢量,这样整体的运算量将大为降低。同时,由于运动矢量的大小和运动程度成正比关系,本文定义了一个阈值β,如果当前CU块运动矢量小于β,则认为该CU块几乎没有运动,不属于人眼感兴趣区域。β值过大会导致判断某帧的运动块数量变少而影响视频质量;β值过小则会导致判断某帧的运动块数量变多而影响视频编码时间。为了确定一个合适的β值,本文测试了β从1到20对编码时间T,码率B、峰值信噪比PSNR以及结构相似性(structural similarity index,SSIM)(值越接近1,图像失真越小)的影响,如图8。图8中为了方便观察,将PSNR和SSIM分别扩大了10倍和600倍。
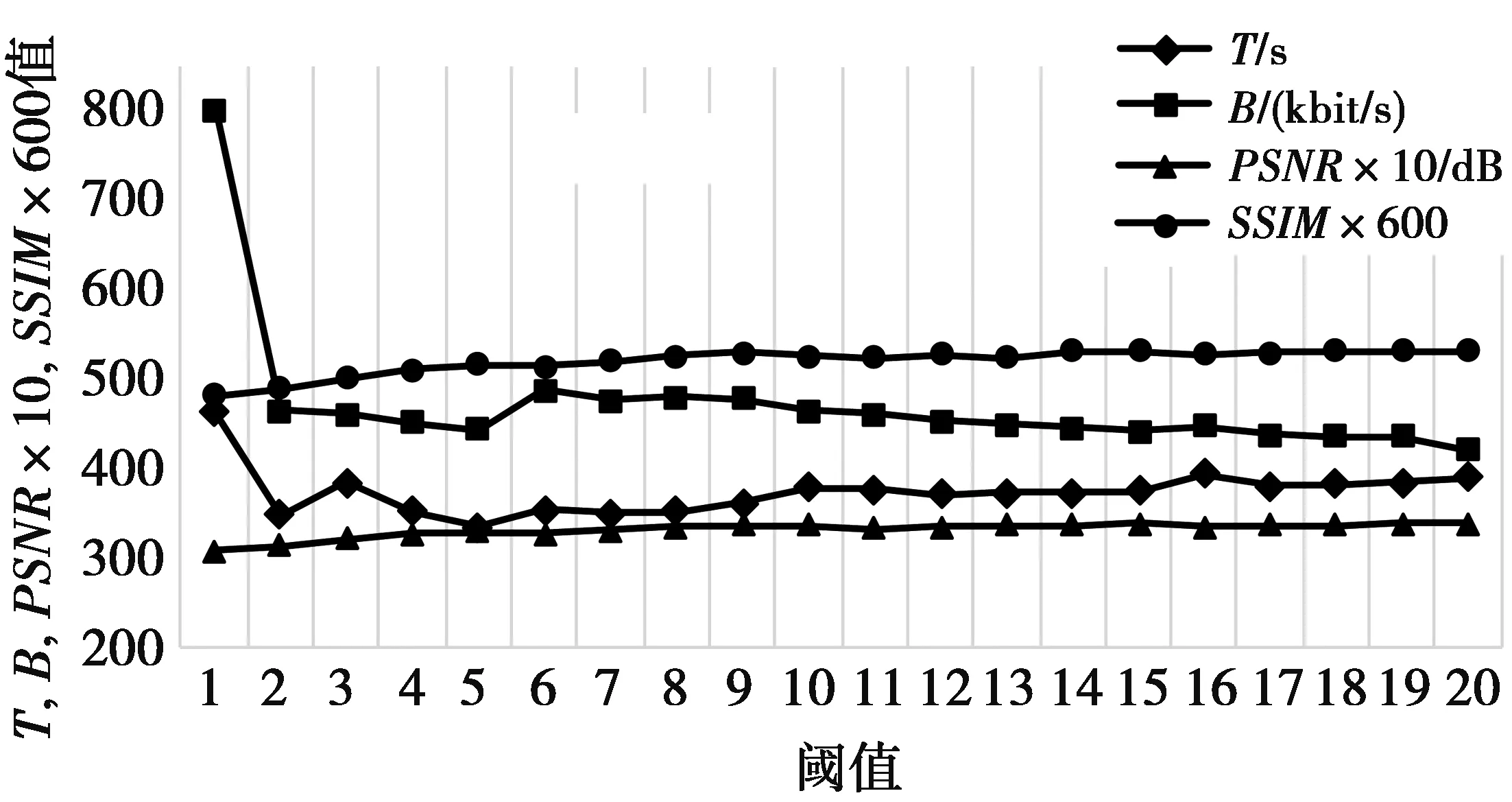
图8 阈值β- T/B/PSNR/SSIM关系曲线Fig.8 Threshold β-T/B/PSNR/SSIM relationship curve
根据图8中的数据,阈值β在10左右,PSNR以及SSIM相对平均,且10以后编码时间相对稳定,码率下降较快,因此,本文认为β取10较为合适。当水平分量和垂直分量上运动矢量小于阈值β(β=10)时,近似认为运动矢量为0,当大于阈值β时,标志位累计数θ加1。而因为间隔尺寸为1个4×4的CU块,所以在一个LCU中,共进行了64次采样,大大降低了复杂度。当累计数θ达到总采样数的1/3,即大于64/3时,认为此模块属于人眼的感兴趣区域。本文将图像分为3种区域:不感兴趣区域(R=0)、弱兴趣区域(R=1)和强兴趣区域(R=2和R=3),计算方法如公式(4)。
Rp=

(4)
(4)式中,Rp表示P帧的感兴趣区域的判断;Ri表示I帧的感兴趣区域的判断。
对R=0的区域,即视频中的不感兴趣区域,SAO效果不明显,可以跳过不予处理;对R=1的区域,需进行一定的弱补偿,只进行简化SAO处理,即忽略第1节所述的边带补偿模式BO以及merge参数融合模式,只处理EO_0,EO_1,EO_2和EO_3,处理方式与标准算法一样;对R=2和R=3的区域,纹理丰富或运动较大,是人眼感兴趣的区域,需要采用标准SAO处理的标准补偿区域,此时除了需要处理EO_0,EO_1,EO_2和EO_3外,还需要处理BO和Merge模式。
2.3 算法设计
经过上述分析,在本文中结合人眼感兴趣区域,从时域和空域2个角度对SAO进行了优化。具体优化SAO算法的过程如图9。
步骤1获取当前编码单元LCU视频帧的帧类型。
步骤2如果判断为I帧,获取当前LCU的划分深度Depth的值,然后判断是否在感兴趣区域。
①如果Depth=0说明不在感兴趣区域,直接进入下一个LCU;
②如果Depth≥2说明在感兴趣区域,LCU采用标准SAO处理,分别对EO_0,EO_1,EO_2,EO_3,BO和Merge模式进行计算,选择相对率失真代价最小模式的补偿值作为最优补偿值;否则,LCU进行简化SAO处理,只处理EO_0,EO_1,EO_2和EO_3,选择这4个模式中相对率失真代价最小模式的补偿值作为相对最优补偿值。
步骤3如果判断为P帧,获取当前LCU的运动矢量θ参数和深度Depth的值,然后判断是否在感兴趣区域。
①如果Depth=0说明不在感兴趣区域,接进入下一个LCU;
②如果Depth=3 ,说明在感兴趣区域,LCU采用标准SAO处理,获得补偿值;
③如果2≥Depth≥1且θ>64/3时,说明也在感兴趣区域,同样进行标准SAO处理;
④如果2≥Depth≥1且θ<64/3时,处于弱补偿区域,只需进行简化SAO处理,获得相对最优补偿值;
步骤4重复以上步骤,直到完成最后一个LCU为止。
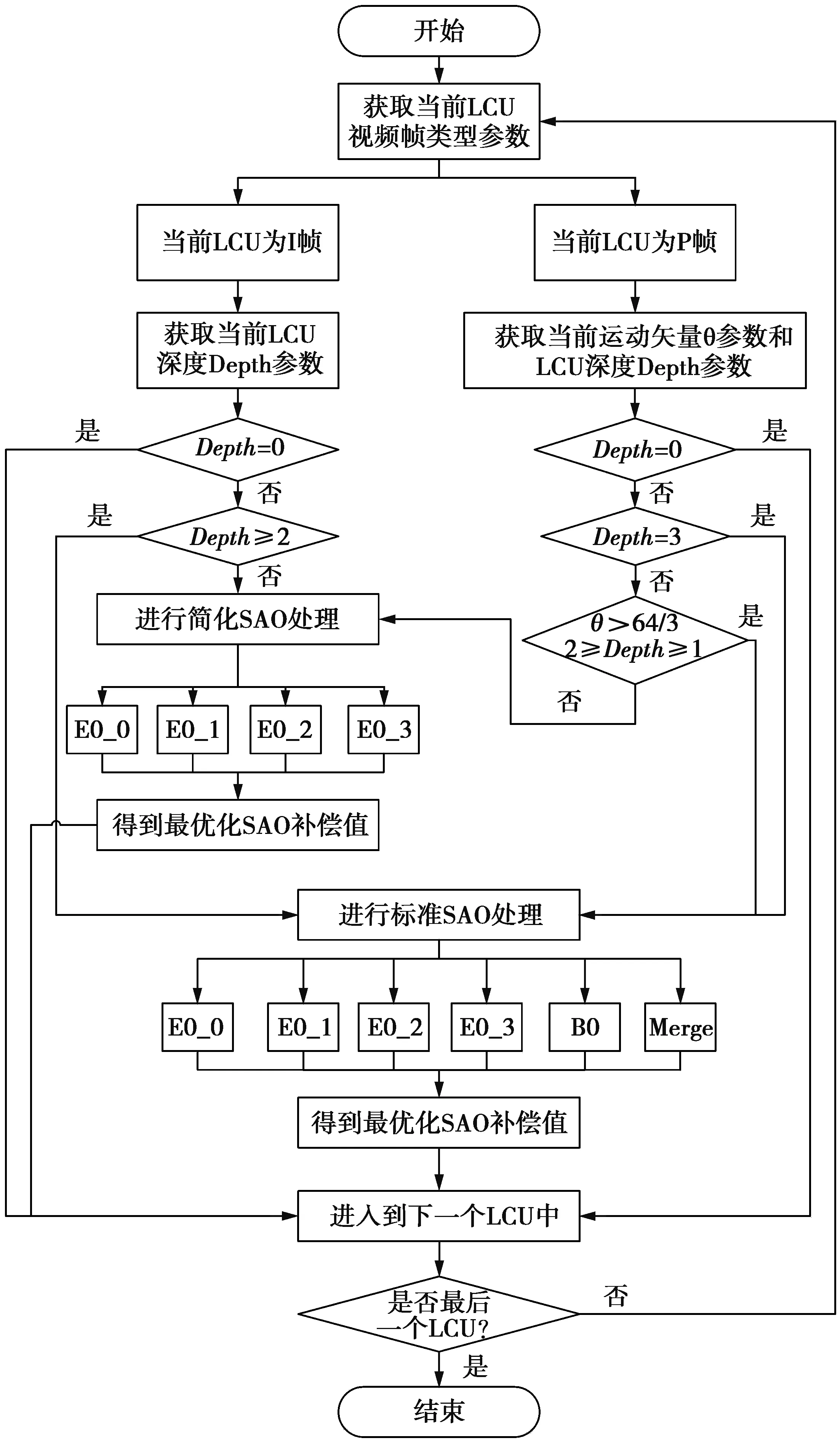
图9 基于感兴趣区域的SAO算法流程Fig.9 SAO algorithm flow based on region of interest
3 实验结果与分析
为了体现本文算法的普适性,选用了5个不同级别分辨率的测试序列数据在x265平台上进行测试,实验平台的内存为8.00 GB,CPU为Intel(R)Core (TM)i7—6700 CPU@3.40 GHz。实验数据为HEVC视频标准测试序列集。测试过程中x265的图像组(group of picture,GOP)大小设置为10,采用无B帧模式,即GOP结构为“IPPPPPPPPP”,同时还与量化参数 QP设置为 32的HM-16.0算法的数据进行了对比。本文以SAO编码时间减少的百分比、峰值信噪比的减少量和比特率减少的百分比这3个参数作为SAO算法客观质量评估标准。实验结果如表2。
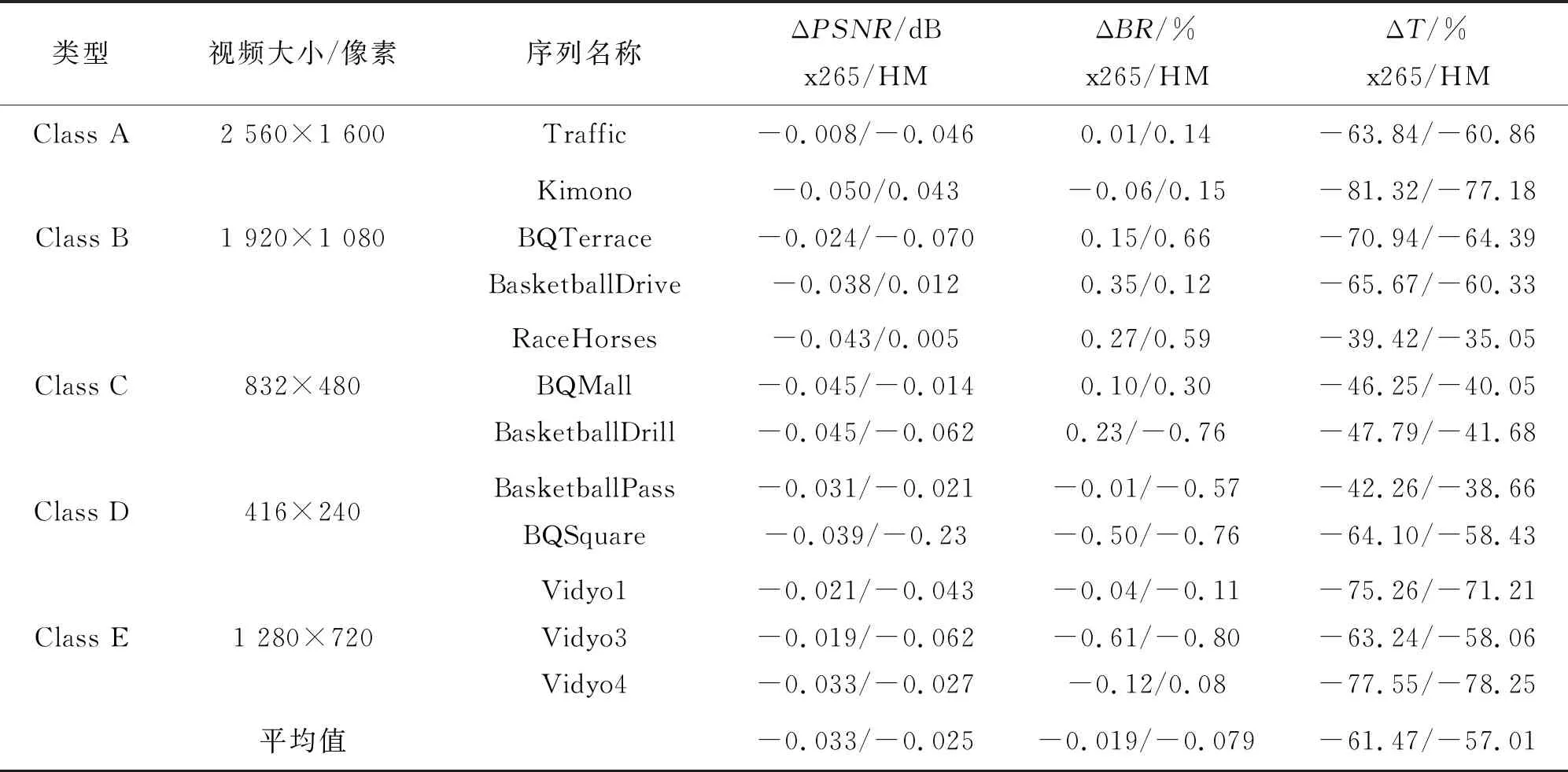
表2 本文算法与标准算法客观编码性能的对比(HM)
从表2中可以看出,本文算法相比x265/HM16.0提供的标准算法,PSNR平均减少了0.033 dB/0.025 dB,比特率平均减少了0.019%/0.079%,而编码时间平均缩短了61.47%/57.01%。
除了和标准算法对比外,所提算法还和参考文献[3-4,6]以HM标准SAO算法为参照进行了对比,结果如表3。可以看出,本文算法在节省时间方面明显优于文献[3,6],码率方面优于文献[4,6]。
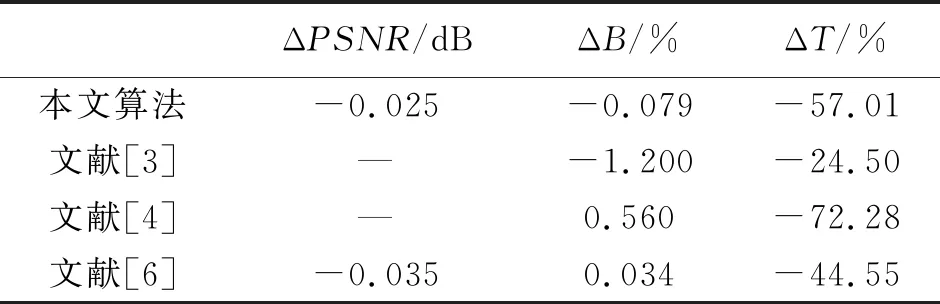
表3 本文算法与文献算法客观编码性能对比(HM)
此外,本文还与文献[7] 以x265标准SAO算法为参照进行了对比,结果如表4。可以看出,本文算法比文献[7]运算时间略长(由于考虑了视频帧的时间相关性),但在视频质量(对应PSNR指标)和最终码率方面具有优势。
由于PSNR是以图像像素值之间的误差进行质量评价,其值不能完全反映人眼主观感受,因此,本文还做了可以较好地反映人眼主观感受的SSIM的数据分析。SSIM是以原始视频数据和失真视频之间的结构相似性进行质量评价,其值越接近于1代表视频质量越好。图10是选取的3组较为典型的视频序列,采用本文的SAO优化算法的前100帧的SSIM值的曲线图,可以看出,视频的平均SSIM值能达到0.9以上,且场景较为简单的视频,例如Vidyo1序列,SSIM值更是能够稳定在0.97左右。

表4 本文算法与文献算法客观编码性能对比(x265)

图10 SSIM曲线图Fig.10 SSIM graph
图11a、图11b和图12a、图12b是x265标准算法和本文算法对于RaceHorses(832×480)序列和Vidyo1(1 280×720)序列的某帧整体对比图,图12c和图12d是Vidyo1(1 280×720)序列的细节部分对比图。对比可以看出,本文算法在较大程度地缩短了编码时间的同时,保证了视频质量只有极小的损失。

图11 x265标准算法和本文算法对于RaceHorses(832×480)序列某帧对比图Fig.11 x265 standard algorithm and the algorithm of this paper for a frame comparison of RaceHorses(832×480) sequence

图12 x265标准算法和本文算法对于Vidyo1(1 280×720)序列某帧对比图Fig.12 x265 standard algorithm and the algorithm of this paper for a frame comparison of Vidyo1(1 280×720) sequence
根据大量资料和测试结果显示,标准SAO平均可以节约2%~6%的码率,而编解码的复杂度增加2%左右[16]。图13统计了HEVC标准测试序列中各视频帧的3种补偿处理方式的分布。可以看出,利用本文算法,无需处理的图像帧平均占比为47.20%,需弱处理的图像帧占比27.30%,需强处理的图像帧占比25.50%。假设弱处理计算量为强处理计算量的α倍(α为0~1),当α=0时,整体编码复杂度增加量为2%×25.50%=0.51%;当α=1时,整体编码复杂度增加量为2%×(25.50%+47.20%)=1.06%。因此,本文的整体编码复杂度平均增加了0.51%~1.06%。结合图13和表2还可以看出,当场景较复杂(如序列RaceHorses),即不需要SAO补偿和需要弱处理的视频帧占比较多,可能会造成码率小幅度增加、编码时间降低量减少的现象。这也是本文算法急需优化的地方。
综上所述,本文提出的优化算法,更适用于时域或空间域中那些场景较简单,人感兴趣区域较小的视频序列。可以以较小的视频质量损耗为代价,较大幅度地降低SAO编码时间。
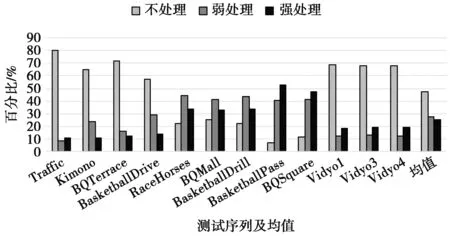
图13 3种补偿处理分布图Fig.13 Three compensation processing distribution map
4 结束语
本文通过分析人眼感兴趣区域,从时域和空间域角度对SAO算法进行优化,提出了一种基于人眼感兴趣区域的样点自适应补偿算法。通过跳过人眼非感兴趣区域的SAO计算,达到降低编码时间提高编码效率的目的。实验结果表明,在不改变主观视频质量的情况下,本文SAO编码时间比标准SAO算法平均减少了61.47%。目前当视频场景较复杂时,本文SAO算法复杂度仍较高,下一步将针对这个方向进一步进行研究优化。
猜你喜欢
含能材料(2021年1期)2021-01-10
快乐语文(2019年9期)2019-06-22
中国惯性技术学报(2019年6期)2019-03-04
中学生数理化·八年级物理人教版(2018年11期)2019-01-31
中央民族大学学报(自然科学版)(2017年2期)2017-06-11
优雅(2016年12期)2017-02-28
电影故事(2016年5期)2016-06-15
工业设计(2016年8期)2016-04-16
火控雷达技术(2016年3期)2016-02-06
浙江理工大学学报(自然科学版)(2015年10期)2015-03-01
