
论大数据智能算法在通信应用预测场景的运用
2021-04-27 07:19李杰吴威关伟杰
广东通信技术 2021年4期
[李杰 吴威 关伟杰]
1 研究背景
在教育、医疗、金融、社科等领域都涉及了大量的通信资源使用,通信网络在人们的生活中占据了越来越重要的位置。如何创建一个更优秀的网络体系、更高效的维护体系、更良好的用户感知体系,已经成为一个非常值得研究的课题。如何从海量数据中采集到信息、又如何从信息中归纳知识,是一项高技术并且劳动强度很大的工作。为了减轻人们的劳动量,同时也为了节约社会成本,出现了一些载有能代替人类脑力劳动算法的机器硬件,这些算法被称为智能算法。将智能算法与传统的通信领域相结合,将大量的通信数据进行统计分析处理,从而转化成的具有特定用途和使用价值的数据,并其与已知的信息进行比较后得出相应的结论用于支撑通信领域的相关工作,使其更加自动化、智能化。
2 研究意义和目的
2.1 研究意义
通信网络经历了长期的发展,衍生出各大分支。技术的进步不仅带来了电信业务种类的增加,随着数据库等技术的发展,通信数据量也呈现了爆发性的增长。而通信网络属于一个动态的网络,网络资源紧张,业务密度分布不均、网络负荷过载等问题,在业务量逐年增加的情况下尤显突出。虽然各大运营商已投入了大量的人力物力进行优化,但仍有较大的改善空间;此外,在人们使用通信网络越来越频繁的背景下,用户感知也成为一个不容无视不容忽视的问题。通过对主流机器学习算法的理论研究,可以将智能算法融入到日常的网络优化、维护等工作中,为广东移动的网络质量提升工作提供帮忙帮助,具有一定的现实意义。
2.2 研究目的
智能化是中国移动集团公司发展战略的一项重要内容,是驱动移动公司优化服务质量、高效运维的有效手段。而人工智能主要依托于计算机超凡的存储能力,记忆大量的数据或是方案,再从中选取最匹配数据与最佳方案反馈输出。人工智能主要依托于大数据,而通信网络具备海量的数据源,将通信网络与基于人工智能技术的深度学习算法和机器学习算法结合,将进一步推进通信领域朝着自动化、智能化的演变方向迈进。
3 机器学习算法类别及适用场景分析
应用建模主要依据如下算法选择原则。
(1)依据任务需求进行算法类别的选择;
(2)根据数据特征以及计算条件等评判依据进行具体的详细算法选择;
(3)一般可以选择多个算法进行模型搭建;
(4)结合业务需求以及算法验证结果对模型进行最终的确定。
3.1 分类算法
分类是一个有监督的学习过程,目标数据库中有哪些类别是已知的,分类过程需要做的就是把每一条记录归到对应的类别之中。由于必须事先知道各个类别的信息,并且所有待分类的数据条目都默认有对应的类别。
适用场景:在具体有哪些类别是已知的的情况下预测目标数据的归属类别,适用于投诉用户预测、离网用户预测等。
常用算法特征如图1所示。
3.2 回归算法
回归通常是机器学习中使用的第一个算法。通过学习因变量和自变量之间的关系实现对数据的预测。
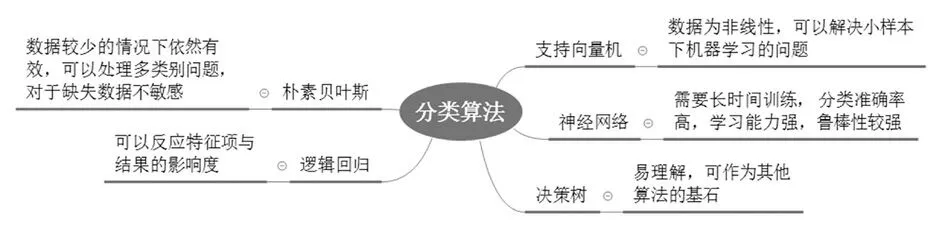
图1 分类算法特征
适用场景:判断自变量和因变量之间的关系,以及不同自变量对因变量影响的强度,适用于指标劣化预测、告警关联预测等。
常用算法特征如图2所示。

图2 回归算法特征
3.3 聚类算法
聚类是无监督学习的典型算法,不需要标记结果。试图探索和发现一定的模式,用于发现共同的群体,按照内在相似性将数据划分为多个类别,判断其内相似性。
适用场景:将一系列点分成若干类,事先是没有类别的。有时候也作为监督学习中稀疏特征的预处理。适用于用户标签分类、呼叫记录详细分析、警报自动化聚类预测等。
常用算法特征如图3所示。

图3 聚类算法特征
3.4 关联规则算法
关联分析又称关联挖掘,就是在交易数据、关系数据或其他信息载体中,查找存在于项目集合或对象集合之间的频繁模式、关联、相关性或因果结构。
适用场景:从大量数据中发现项集之间有趣的关联和相关联系。适用于业务推广、入网拉新等。
常用算法特征如图4所示。

图4 关联算法特征
3.5 时间序列算法
时间序列是按照时间顺利排列的一组数据序列。时间序列算法就是发现这组数据的变动规律并用于预测的统计技术。,且具有假设事物发展趋势会延伸到未来、预测所依据的数据具有不规则性和不考虑事物发展之间的因果关系的特点。
适用场景:通过时间延展的方式找到数据中的变化规律。一般都用于流量、话务量等基于时间的预测。
4 算法模型实际应用案例介绍
4.1 基于时间序列的流量预测模型
项目目标:由于用户群体的分布以及用户行为的变化,可能导致网络资源配置无法满足实际资源需求,亦可能存在部分资源浪费的情况。本模型根据历史数据分析流量使用的规律性来预测用户的实际使用情况,并以分析结果作为调整参照,可以更合理地分配网络资源,避免资源浪费以及减少用户投诉问题,达到提前预知提前准备的目的。
模型创建依照如下步骤进行。
(1)数据预处理:缺失值、异常值进行分析,并进行插补替换处理。如图5所示。
(2)绘制时间序列图观察趋势:采用时序平滑化与季节性分解。如图6所示。
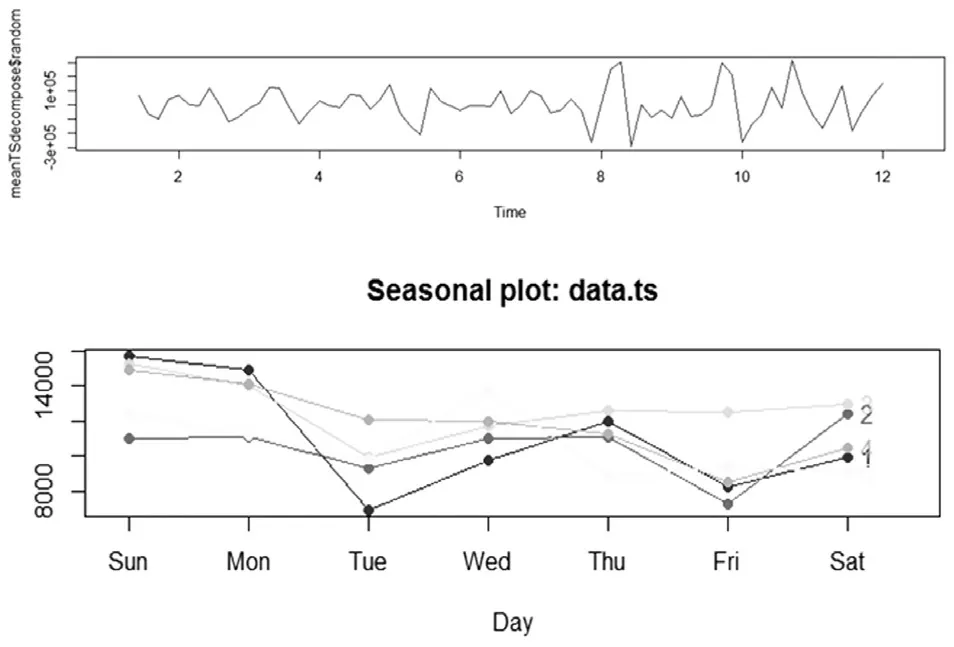
图6 时间序列图
(3)分析序列平稳性并进行平稳化:通过平稳性检验、白噪声检验。
通过根检验(ADF)方法进行平稳性检验,观测序列根检验对应p值小于0.05,属于非平稳序列,二阶滞后差分满足平稳序列,如表1所示。

表1 根检验(ADF)
为了验证序列中有用的信息是否已被提取完毕,需要对序列进行白噪声检验。采用LB统计量的方法进行白噪声检验,二阶滞后差分后的p值系数小于0.05,如表2所示。

表2 LB统计量
(4)ARIMA模型定阶
针对一阶差分后的时序输出自相关与偏自相关图,计算得到ARIMA(1,0,0)模型,如图7所示。
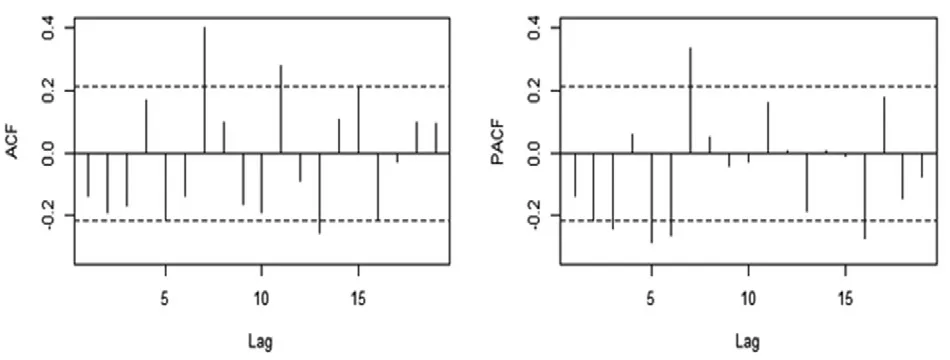
图7 一阶差分后的时序输出自相关与偏自相关图
计算ARMA(p,q)取p和q均小于等于15的所有组合的BIC信息量,如图8所示。

图8 计算ARMA(p,q)的BIC信息量
选取显著变量为Φ1、Φ9、Φ12和θ5、θ12,输出模型ARMA(1,5),ARMA(1,12),ARMA(9,5),ARMA(9,12),ARMA(12,5),ARMA(12,12)。
(5)模型评估与预测
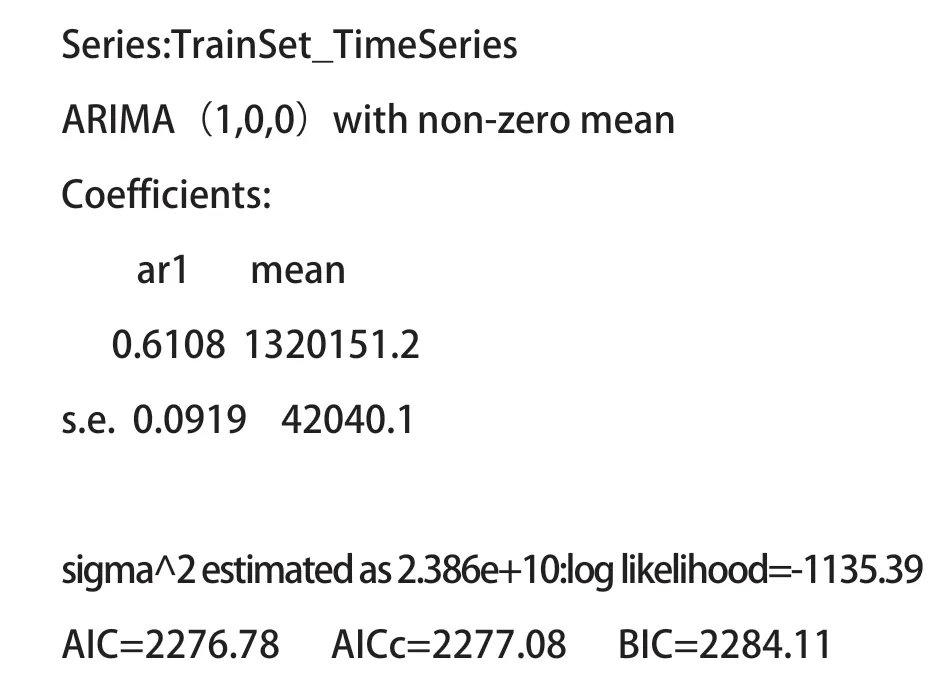
检查其残差序列是否为白噪声,是否满足平稳序列。如果不是白噪声,说明残差中还存在有用信息,需要修正模型或者进一步提取。针对选出的模型进行拟合,模型的AIC值,ARIMA(1,1,12)的AIC值为最优,如表3所示。
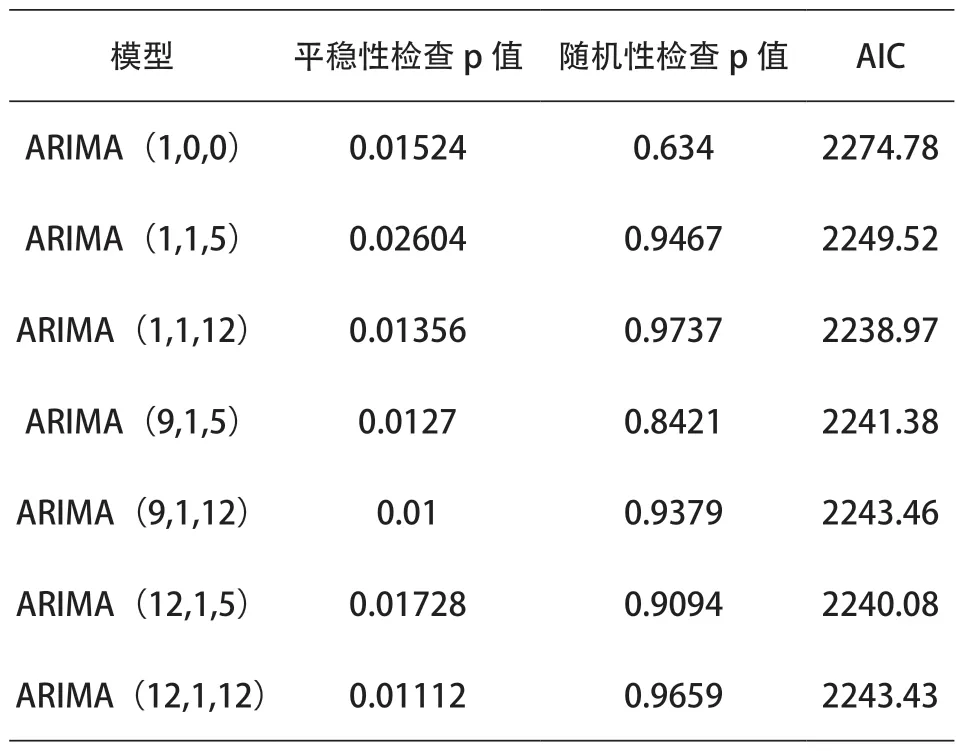
表3 模型评估与预测表
通过预测结果并结合经验分析,可以针对网络资源进行针对性的调整,如图9所示。

图9 针对性调整
4.2 基于线性回归的信号强度预测模型校正
项目目标:采用线性回归模型对无线传播模型进行校正。通过无线信号采集数据带入线性回归模型,从而对SPM模型进行K值的求解,最终实现传播信号的预测。能有效的模拟用户实际的信号使用情况,对网络规划以及网络优化都起到了重要的参考作用。
基于采集数据将其带入SPM模型,如图10所示。

图10 SPM模型
采用线性回归算法创建信号强度的预测模型,通过如下指标进行综合评估,如表4所示。

表4 评估模型
最终确定的模型输出结果如图11所示。
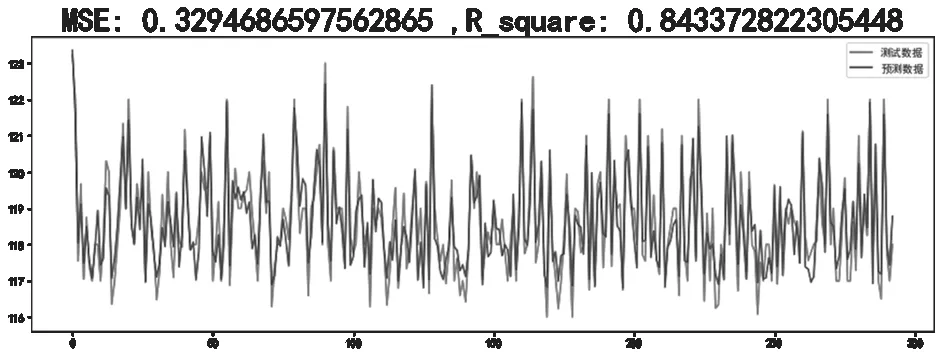
图11 模型输出
红色为现网数据,蓝色为预测数据。从结果上可以看到,预测偏差为可接受范围内,该模型可投入实际的规划仿真工作中使用。

4.3 基于决策树的用户投诉预测模型
项目目标:用户感知目前已经成为生活用中越来越关注的话题,如果要能让用户用得开心,预防胜于治疗是关键。通过DPI指标结合告警信息进行模型创建,采用决策树分类器预测潜在投诉用户,可以做到先知先预防的作用。
(1)采集用户投诉记录、投诉前对应时段的DPI指标、投诉前时段的告警数据作为数据集,并将其进行关联处理形成信息宽表,如表5所示。
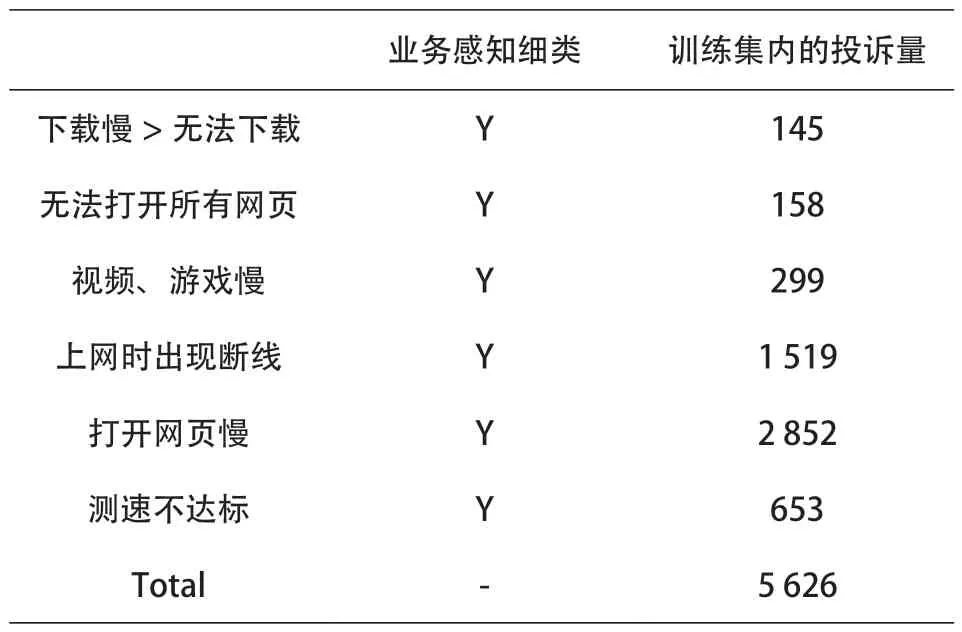
表5 信息宽表
(2)针对采集数据进行预处理,围绕缺失值、异常值、数据规范化三部分进行,处理后的训练集保留1:1比例,如表6所示。
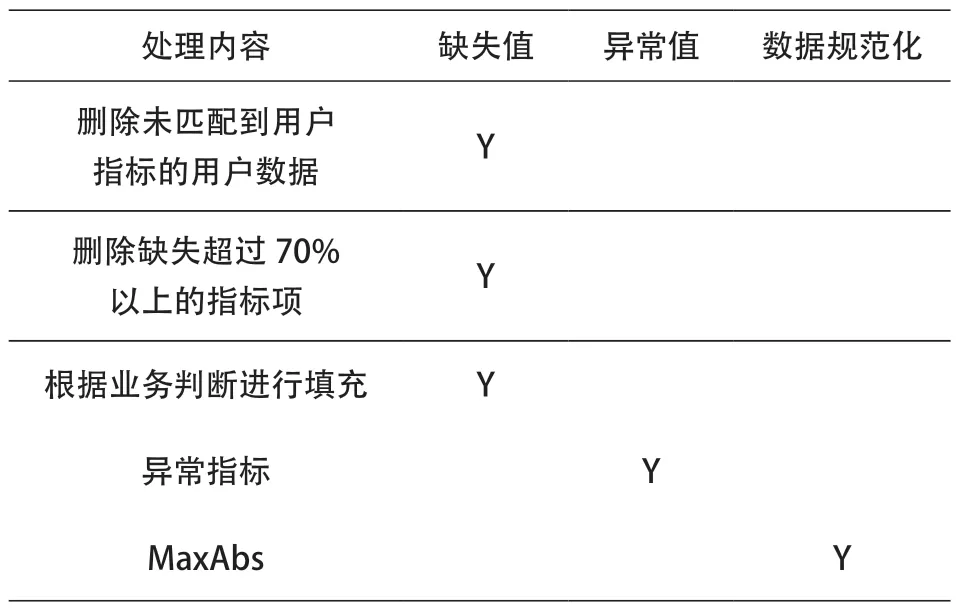
表6 采集数据预处理
(3)考虑到数据集的特征,优先选取随机逻辑回归的结果,再结合建模情况增加部分信息增益和卡方检验特征。通过前剪枝与后剪枝的两种方式进行决策树建模,输出树形结果,如图12所示。
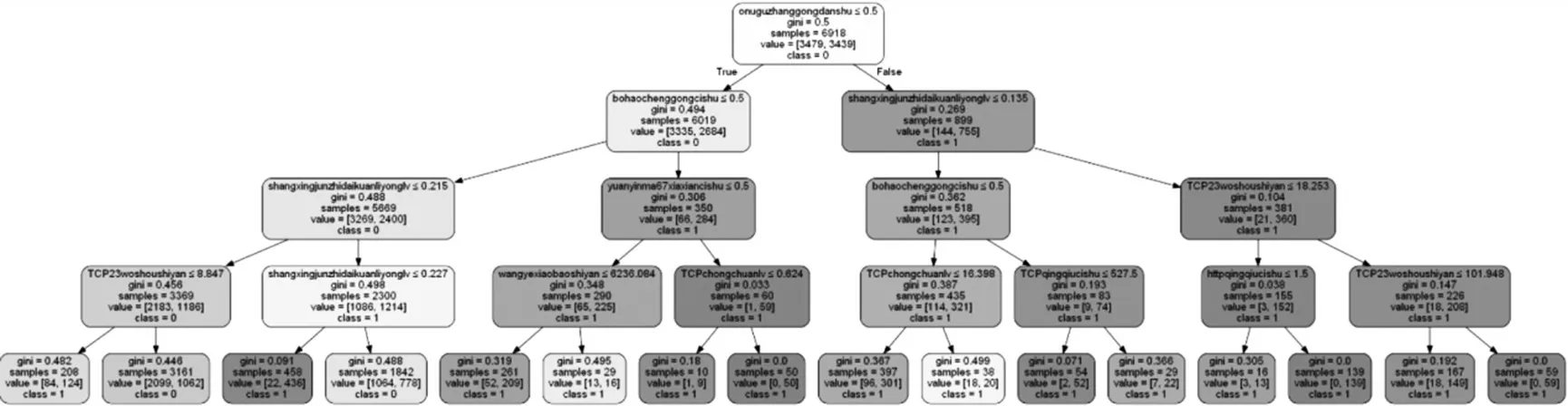
图12 决策树
(4)将原有训练集中的0.3部分划分为交叉训练集,针对划分后的训练集进行模型训练,选取优质模型参数,并在交叉训练集中进行验证,如图13所示。

图13 交叉训练集验证
(5)挑选准确率大于70%且召回率较高的单项规则进行组合训练,模型输出如图14所示。

图14 组合训练模型输出
猜你喜欢
中学生数理化·中考版(2022年9期)2022-10-25
黄河之声(2022年10期)2022-09-27
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
疯狂英语·新策略(2019年10期)2019-12-13
当代陕西(2019年10期)2019-06-03
民族古籍研究(2018年1期)2018-05-21
数学小灵通·3-4年级(2017年9期)2017-10-13
中学生数理化·八年级物理人教版(2017年11期)2017-04-18
新校长(2016年8期)2016-01-10
