
一种目标识别推理平台设计
2021-04-26 07:57王伟伟郑芳只王海娟
智能物联技术 2021年6期
王伟伟,郑芳只,王海娟,李 婷
(中国电子科技集团公司第五十二研究所,浙江 杭州 311100)
0 引言
目标识别是计算机视觉和数字图像处理技术的重要应用方向,广泛应用于机器人导航、智能视频监控、工业检测、航空航天等诸多领域。随着计算能力的发展,人工智能技术逐步应用到目标识别领域中来。目前国内基于目标识别研究较多采用成熟的GPU(Graphics Processing Unit)平台,应用嵌入式平台推理端的研究不多。本文介绍一种目标识别推理平台,适用于航空机载、海军舰载以及陆军战车等推理环境下的自主识别应用。
1 目标识别推理平台的发展趋势
近年来,伴随着人工智能和深度学习在目标检测与识别领域的发展和应用,目标检测识别技术得到了快速发展,检测与识别算法发生了很大改变。深度学习算法已成为目前主流的目标检测与识别算法。
随着算法的改变,对底层硬件的需求也发生了很大变化,传统的硬件架构已无法支撑深度学习等大规模并行计算的需求。硬件架构也由原来的CPU为主GPU为辅,逐渐转变为GPU为主CPU为辅。
目前应用于目标检测和识别的芯片主要分为以下3类,并且预计在较长一段时间内,也将会持续这种三足鼎立的局面。
第一,并行加速计算的GPU。随着英伟达、AMD等公司不断推进其对GPU大规模并行架构的支持,面向通用计算的GPU已成为加速可并行应用程序的重要手段。目前,GPU已经发展到较为成熟的阶段。谷歌、FACEBOOK、微软、Twitter和百度等公司都在使用GPU分析图片、视频和音频文件,以改进搜索和图像标签等应用功能。此外,很多汽车生产商也在使用GPU芯片发展无人驾驶。
第二,半定制化的FPGA(Field Programmable Gate Array)。FPGA可同时进行数据并行和任务并行计算,在处理特定应用时有更加明显的效率提升。此外,由于FPGA的灵活性,很多使用通用处理器或ASIC(Application Specific Integrated Circuit)难以实现的底层硬件控制操作技术,利用FPGA可以很方便的实现。
第三,全定制化的ASIC。针对深度学习和并行计算的专用芯片,相比于GPU和FPGA,在速度、功耗以及并行计算方面有着自身的优势。随着人工智能算法和应用技术的日益发展,以及人工智能专用芯片ASIC产业环境的逐渐成熟,全定制化人工智能ASIC的优势也在不断显现。
2 目标识别推理平台设计
2.1 基本原理及系统组成
以无人机为例,目标识别系统如图1所示。其中,光电载荷负责采集侦查数据,采集各类视频后发送给目标识别推理平台。目标识别推理平台对输入视频中的军事目标进行实时分析识别,包括停机坪飞机、机场跑道、油库、地空导弹车、地/海面防空雷达车、桥梁、运输舰船,对重要的目标进行实时跟踪,并得到检测跟踪识别结果。同时,目标识别推理平台向后端转发视频图像数据和目标识别的结果。通过无人机的测控链路,视频图像及检测结果下传到地面站,供显示分析。在地面情报处理系统中,原始图像和检测结果进行叠加显示,显示识别的目标和参数。
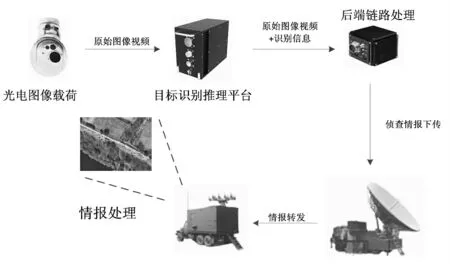
图1 目标识别系统组成示意图Figure1 Target recognition system composition diagram
目标识别推理平台(以下简称“平台”)上运行深度学习神经网络识别算法,主要实现对前端光电图像载荷的接收采集和对视频进行预处理、目标检测、区域检测等处理,实时产生识别的结构化信息,叠加到图像视频后进行输出。平台采用Hi3559A+FPGA为核心处理器平台,主要硬件包括Hi3559A核心模块、FPGA载板模块和电源模块。其中核心处理芯片包括华为海思的Hi3559A芯片和复旦微电子JFM7系列FPGA芯片。
平台的目标识别算法为深度学习检测识别算法。在平台使用环境下,深度学习检测识别算法可以对大范围多种类目标识别场景提供针对性支持。设备通过Hi3559A处理器完成深度学习检测识别算法的部署。除此之外,Hi3559A处理器上还部署有嵌入式操作系统和主控应用软件。基于Hi3559A SDK编写的主控应用软件实现对平台的内部资源配置、命令数据流等控制功能。FPGA视频预处理软件部署在JFM7芯片上,主要用于视频数据的接收、预处理和发送。视频预处理主要包括视频接口转换、视频数据复制、缩放、OSD(On-Screen Display)叠加、视频同步输出等。
平台采用自研端到端CNN(Convolutional Neural Network)网络HikNet-LMS算法实现目标检测识别推理,部署在Hi3559A处理器上,调用NNIE(Neural Network Inference Engine)加速引擎对深度学习卷积神经网络进行加速处理。HikNet-LMS算法本身具备强大的小目标检测能力,检测效果优于当前最优开源算法,同时具备较强的多尺度目标检测能力,网络前向计算耗时短,识别能力强,能满足实时多目标检测识别以及多类别目标检测识别的应用需求。
2.2 硬件设计
平台硬件方案在小型化、国产化设计方面进行详细的分析调研并遵循模块化设计思路。平台的硬件组成框图如图2所示,主要包括:Hi3559A核心模块、FPGA载板模块和电源模块。各模块的基本信息见表1。下面主要对前两个模块进行介绍。

图2 平台硬件组成示意图Figure2 The sketch map of platform hardware compose
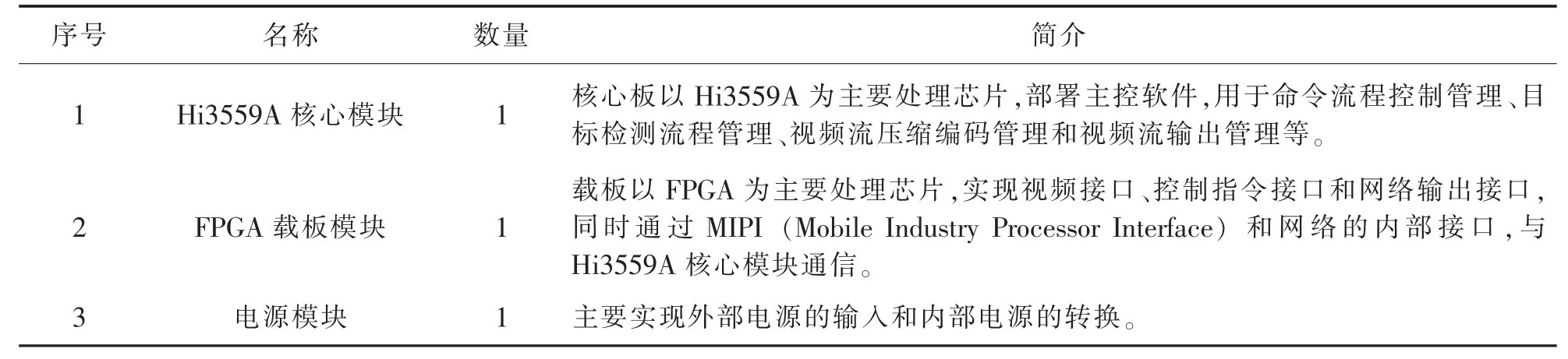
表1 各模块的基本信息Table1 Basic information of each module
2.2.1 Hi3559A核心模块
平台的视频处理和目标识别的逻辑推理,主要由Hi3559A芯片实现。Hi3559A拥有双核A73+双核A53+单核低频A53的CPU架构和双核Mali G71的GPU架构,能更快实现目标检测等复杂运算,采用12nm工艺制程,功耗极低。华为海思Hi3559A的逻辑框图如图3所示。
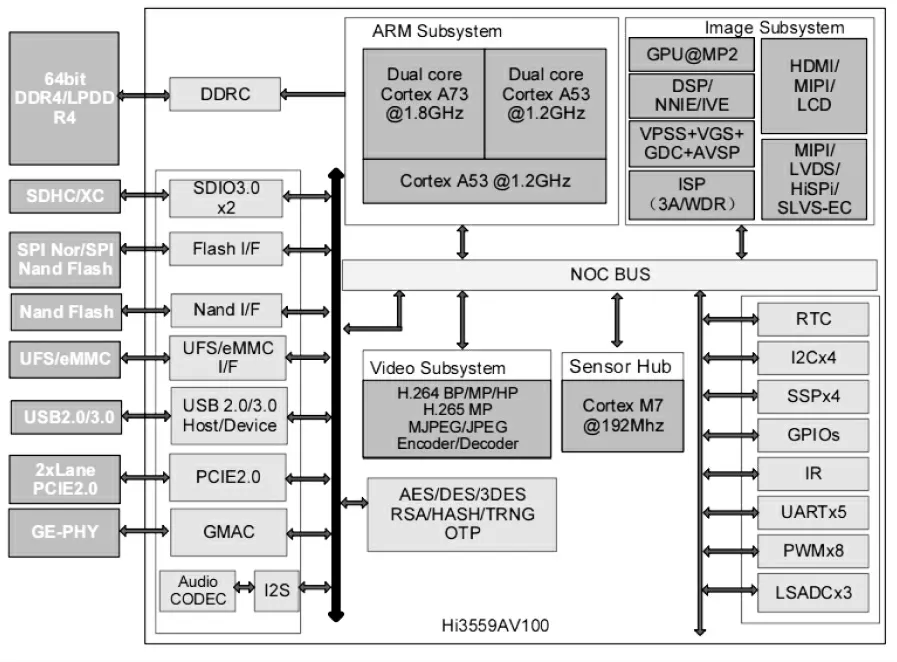
图3 Hi3559A芯片逻辑框图Figure3 The logicframeof Hi3559AChip
(1)CPU:双核A73@1.8GHz,双核A53@1.2GHz;
(2)智能处理:四核DSP@700MHz,双核NNIE@840MHz神经网络加速引擎,算力可达4TOPs;
(3)视频接口:支持8路sensor输入,最大分辨率支持到32M(7680×4320)或者36M(6000×6000);
(4)视频压缩:H.264 BP/MP/HP,H.265 Main Profile/Main 10 Profile MJPEG/JPEG Baseline;
(5)视频码率:最大200Mbps。
Hi3559A核心模块中处理器设计成一个最小核心系统,该核心系统包含处理器Hi3559A芯片所能工作的最小单元。本平台方案中主要为Hi3559A芯片、DDR(Double Data Rate)颗粒、网络PHY芯片(Physical Layer Transceivers)和电源芯片等芯片,通过连接器扣在FPGA载板模块上,Hi3559A核心模块的应用框图如图4所示。
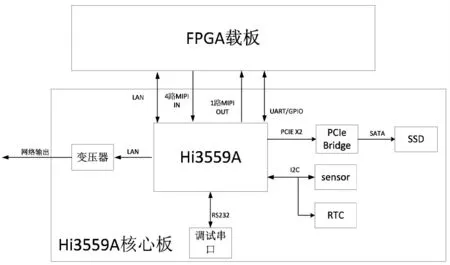
图4 Hi3559A核心模块应用框图Figure4 The frame of Hi3559A core module application
Hi3559A核心模块硬件接口包括MIPI视频接口、网络接口以及其他外围接口。视频接口主要为MIPI接口,同时保留1路网络接口用于实现数据的接收和发送,支持10/100/1000Mbit/s工作模式可配置,可实现和外部设备间的数据通信。Hi3559A支持2个NNIE加速引擎,它是海思媒体SoC中专门针对神经网络特别是深度学习卷积神经网络进行加速处理的硬件单元,支持现有大部分的公开网络,如AlexNet、VGG16、GoogleNet、ResNet18、ResNet50等分类网络和Faster RCNN、YOLO、SSD、RFCN等检测网络,以及SegNet、FCN等场景分割网络。Hi3559A主要通过MIPI接口接收FPGA的视频数据,最大可支持串行输入16Lane MIPI,支持多种工作模式,可满足4路1080P@60fps的视频输入。2.2.2 FPGA载板模块
该模块以FPGA为主要器件,加上对外视频接口。如图5所示为FPGA载板模块框图。
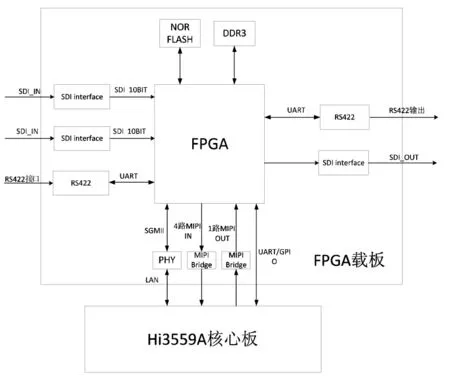
图5 FPGA载板模块框图Figure5 The frame of FPGA board module
FPGA采用复旦微电子的JFM7系列FPGA芯片,支持多路高速接口。方案中主要有2路视频SDI(Serial Digital Interface)输入接口,通过MIPI接口输出到Hi3559A核心模块,1路SGMII(Serial Gigabit Media Independent Interface) 接口与Hi3559A进行数据的交互,1路RS422接口作为视频输出。FPGA外置DDR3存储阵列,用以存储视频输入到视频处理完成再到视频输出整个数据处理过程中的视频数据。FPGA的JTAG(Joint Test Action Group)接口通过隔离芯片连接到机箱面板的调试接口,用来支持整机调试。FPGA中的MIPI接口通过IP核实现,最高支持4路数据Lane,每路可达1.25Gbps,视频分辨率最高支持4k@30fps,满足与Hi3559A的通信需求。
2.3 软件设计
2.3.1 软件组成
目标识别推理平台软件由部署在FPGA K7325T的FPGA预处理软件、部署在海思Hi3559A的目标识别主控软件以及部署在地面站的视频播放插件组成。目标识别系统软件部署如图6所示。
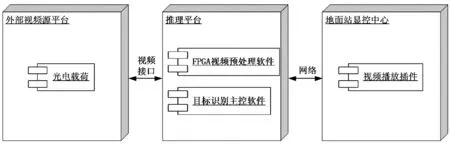
图6 目标识别系统软件部署图Figure6 The software deploy frame of target recognition system
推理平台软件CSCI(Computer Software Configuration Item)软件部件如图7所示。推理平台引入FPGA预处理架构,一方面减轻目标识别软件预处理计算能力的负担,将最大算力应用在目标识别上面,另一方面为目标识别软件适配不同视频接口提供解决方案。其中各软件模块主要功能如下:
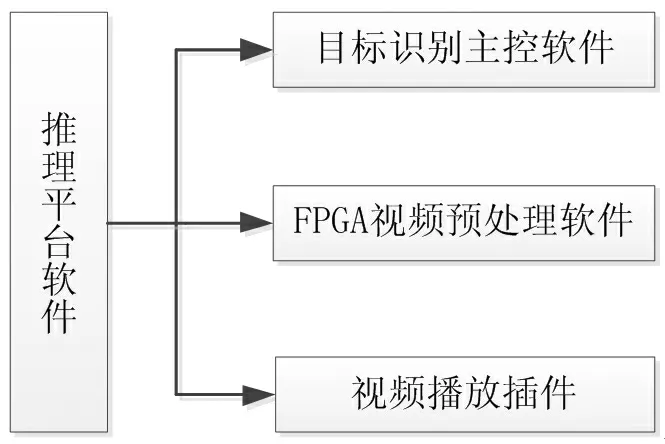
图7 目标识别推理平台CSCI软件部件图Figure7 The deploy frame of CSCI software for target recognition and reasoning platform
(1)目标识别主控软件
目标识别主控软件部署在海思Hi3559A平台CPU模块上,基于海思Hi3559A SDK编写的嵌入式应用程序对平台资源配置、命令数据流等进行控制。主要功能有命令接收解析及控制、动态模板更新控制、电子稳像、视频数据获取、单目标多目标识别控制、区域识别控制、实时目标跟踪控制、添加目标跟踪框控制、视频网络数据输出控制等。
(2)FPGA视频预处理软件
FPGA视频预处理软件部署在FPGA K7325T模块上,实现外部视频接口采集、视频帧完整性预处理和添加固定信息OSD,并按照MIPI接口协议要求输出视频数据。
(3)视频播放插件
视频播放插件部署在地面站显控中心,用于实时显示接收到的视频数据流,并根据目标识别结构信息提供预警功能。
2.3.2 目标识别
(1)目标识别流程
视频信号接入到FPGA视频预处理软件,FPGA视频预处理软件在固定位置添加字符信息(如刻度、十字框等),然后打包转换成MIPI格式发送到海思Hi3559A进行处理。目标识别主控软件配置相应VI(Video Input)输入通道:将一路数据复制成两路数据,其中一路数据按比例缩放(分辨率小,识别速度快)用来进行目标检测识别,目标识别结果保存在共享区域;另外一路原始数据获取共享区域目标识别结果,将目标识别结果叠加到原始数据上,然后调用海思Hi3559A SDK压缩编码后网络输出。
目标检测识别数据流图如图8所示。海思Hi3559A视频预处理主要针对视频进行防抖处理。摄像机在拍摄视频时由于环境或人为的影响,视频会出现抖动或不稳定现象,影响到后续视频的目标检测及观看效果。海思Hi3559A在对图像进行数字处理过程中,采用防抖算法(GME+陀螺仪)(Global Motion Estimation,GME)计算出当前图像的运动偏移,然后对图像进行平移、旋转等变换,从而起到防抖的效果。
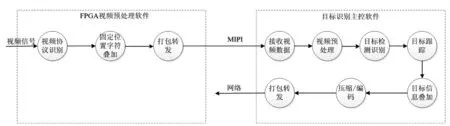
图8 目标检测识别数据流图Figure8 The data flow chart of target recognition
(2)目标识别算法
在目标检测识别领域,主流方法是one-stage系列的目标检测算法,其中在小目标检测识别领域综合表现最好的算法是YOLOv3。采用自制训练测试样本集,对YOLOv3训练测试的结果表明,算法表现良好,但仍不能完全满足本平台的多类别高精度检测识别需求。
本文的目标识别推理平台中采用卷积神经网络,网络结构本身基于YOLOv3改进而来,主要改进有:
第一,基础特征网络Darknet-53中加入2组HRFB(Hik Receptive Field Block),即深度学习神经网络的一个网络层,它是特征提取网络的一种结构,采用三分支的结构,分别为1×1卷积核分支、1×1卷积核加3×3卷积核分支、1×1卷积核加3×3卷积核加3×3卷积核分支。这样的结构能够有效保障训练收敛、特征表达等多个方面。经过实践验证,适量加入HRFB结构能够有效增强网络的特征表达结构,提升网络特征表达能力。
第二,去除YOLOv3上采样操作,增强小目标检测的能力。
第三,保留YOLOv3训练trick,包括多尺度缩放增广训练等,提高训练模型参数的鲁棒性等。
目标检测识别功能的实现主要包括地面服务器端的数据准备、训练以及海思Hi3559A推理运算,如图9所示。

图9 目标识别功能实现流程Figure9 The realization flow of target recognition function
数据准备即是将包含检测识别类别目标的图像数据进行人工数据标定,形成标准VOC(Visual Object Class)格式标定数据,之后对标定完成的数据进行样本增广,确保数据整体的均衡性和广泛性;训练阶段利用标定好的数据对神经网络模型参数进行训练,训练过程中利用超参数调整以及训练trick,使模型参数充分收敛;目标检测识别过程中,首先对神经网路进行初始化,加载训练阶段的模型,之后将逐帧视频图像数据传入网络,获取网络输出的结构化信息,包括帧号、目标框信息、目标类别、目标类别置信度、目标标识ID等。
2.3.3 目标跟踪
多目标跟踪功能主要是基于目标识别输出的结果,综合分析场景中的目标表观、运动特征等信息特点,实现适应场景中跟踪目标数目多变,跟踪过程中目标多尺度、形变、易遮挡等特点的实时鲁棒的多目标跟踪功能。多目标跟踪功能的实现方法主要分为预测和更新两部分,如图10所示。
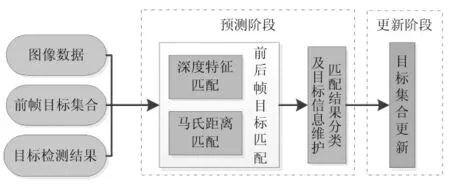
图10 多目标跟踪流程图Figure10 The flow chart of multi-target tracking
在预测阶段,给定前帧跟踪状态和当前帧检测结果,通过匹配将目标分为三类:第一类,前一帧目标与当前帧目标匹配上;第二类,前一帧目标在当前帧未找到相匹配目标;第三类,当前帧新出现的新生目标。同时,记录各目标的维护信息,包括特征数组、丢失帧数、连续检出帧数、历史坐标等。
在匹配环节,采用深度特征和马氏距离的综合相似度来度量目标间的匹配程度,能较好的表征目标的特征,达到较好的匹配效果。同时存储了目标最近N帧的深度特征来用于匹配,能较好适应目标形变、尺度变化带来的匹配误差。另外,设计了适应不同运动模型的卡尔曼滤波器和级联匹配策略,较好适应跟踪过程中遮挡较多的情况。
在更新阶段,根据预测阶段的匹配结果对目标集合进行更新维护,用于输出及下一帧的预测。
最终在地面站显控中心实时播放的多目标识别跟踪效果如图11所示。

图11 多目标识别跟踪效果图Figure11 The effect chart of multi-target recognition tracking
3 目标识别推理平台的创新
3.1 支持任务运行状态下目标模型的动态更新
推理平台目标检索训练模型采用动态加载的方式,可根据不同环境需求在线加载不同环境下训练的模型,提高设备的易用性和复用性。在线加载检测模型流程如图12所示。操作员可通过远程操作界面发送指令,指令通过传输链路(有线或者无线链路)传输到推理平台,目标检测主控软件停止当前目标检测跟踪流程,根据指令加载需要的场景模型,重新开启检测跟踪流程。经测算,模型在线加载时间延时在秒级别,适用于多场景的侦察检测任务。
推理平台目标检测模型调用关系如图12所示。在数据预备阶段收集各类应用场景数据,根据优化后的目标识别算法,训练出目标检测模型,将各类检测模型收集归类存放到目标检测模型库中。在实际使用中,根据用户使用场景,业务层动态加载该应用场景的目标检测模型。后续有新的检测模块也可直接添加到目标检测库中,方便应用场景的扩展和推广。
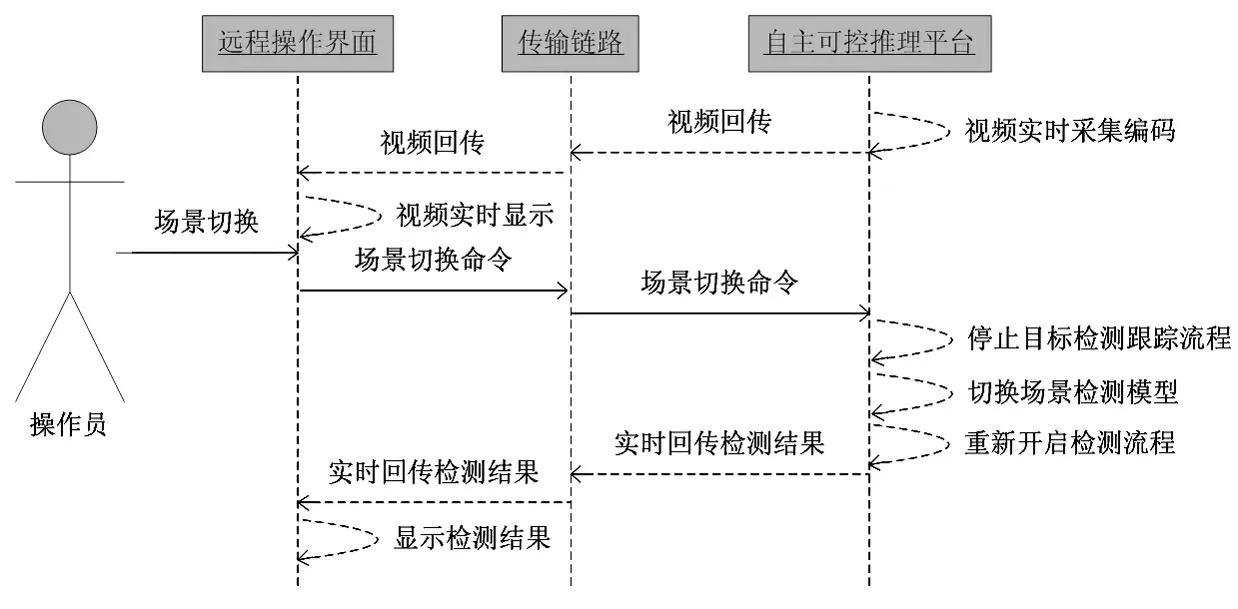
图12 在线加载检测模型流程图Figure12 Theflow chart of online load detectmodel
3.2 基于YOLOv3优化网络结构,识别更小目标同时提高识别置信度
在小目标检测识别领域综合表现最好的算法是YOLOv3。基于YOLOv3,本文的目标识别推理平台采用一套适应于小目标和多尺度检测识别的更优算法,达到多类别、高精度的识别效果。算法具备的主要特点是:强大的小目标检测能力、较好的多尺度目标检测能力、网络前向计算耗时较短、网络训练稳定收敛。算法本身采用特征提取能力更强的Backbone,对小目标和多尺度两项需求进行了多项针对性设计。总体设计要点如下:
(1)以小目标检测领域实测效果最好的YOLOv3为网络结构设计原型,进行特征表达和小目标检测的优化改进;
(2)基础特征网络Darknet-53中加入2组HRFB(Hik Receptive Field Block)结构,提升网络特征表达能力;
(3)去除YOLOv3上采样操作,增强小目标检测能力;
(4)保留三尺度特征输出的设计,增强多尺度目标检测的能力;
(5)加长特征回溯的检测头,增强小尺度输出特征图的特征表达能力,增强小目标检测能力;
(6)保留YOLOv3训练trick,包括多尺度缩放增广训练等,提高训练模型参数的鲁棒性;
(7)保留训练锚框的聚类计算,加快训练收敛速度,同时获得更好的收敛效果。
4 结语
本文设计的目标识别推理平台,可满足多接口视频采集、视频处理、目标识别和跟踪等机载自主侦察推理的应用需求。本系统采用复旦微电子FPGA与海思处理器芯片搭建小型轻量化的推理系统,针对小目标侦察,采用YOLOv3优化网络结构,既解决推理系统中的元器件系统功耗高等瓶颈问题,也解决了小目标识别置信度低的瓶颈问题,从而扩大了应用领域,适用于航空机载、海军舰载以及陆军战车侦察等环境下的自主侦察、识别应用。
猜你喜欢
环球时报(2022-09-29)2022-09-29
英语文摘(2021年10期)2021-11-22
军民两用技术与产品(2021年12期)2021-03-09
中国计算机报(2019年40期)2019-12-09
作文与考试·初中版(2019年23期)2019-08-12
摄影之友(影像视觉)(2019年3期)2019-03-30
湖北工业大学学报(2016年5期)2016-02-27
CHIP新电脑(2015年10期)2015-10-15
通信世界(2014年16期)2014-06-09
电信工程技术与标准化(2013年2期)2013-03-24
