
基于K-means的动态资源分配策略
2021-04-22 08:54朱新峰吴名位王国海
计算机工程与设计 2021年4期
朱新峰,吴名位,王国海
(1.扬州大学 信息工程学院,江苏 扬州 225100;2.中电科航空电子有限公司 航空电子事业部,四川 成都 610000)
0 引 言
移动边缘计算(MEC)是5G时代的一项新兴技术,该技术将云计算中心的部分功能迁移至基站,使基站具备相应的计算、存储、处理等功能。MEC可以近距离为移动用户提供云计算和IT服务,允许用户在基站内或一定范围内使用边缘云服务,使得移动用户感知到的端到端延迟减少。近期,如何对基站内的资源进行科学合理分配、如何实现资源分配的低时延和高带宽成为近期研究热点,尤其是在一些对时延敏感、数据量大的应用中,如:车联网、远程医疗、公共安全和CloudMES[1]等应用场景。但MEC因其属性和用户的移动性为资源的合理分配和充分利用带来诸多挑战[2],考虑到MEC的计算压力和用户密集度成正比,本文结合MEC的频谱资源分配,综合不同场景、不同用户量、不同用户和用户的不同任务等多种因素,采用K-means算法对用户进行聚类,利用拍卖算法对资源进行分配,不仅使得资源得到较好利用、用户获得较好体验,且在有效提高吞吐量、降低传输时延方面获得较好效果。
1 相关工作
本章介绍在MEC环境下,边缘服务器的计算资源分配、频谱资源分配、基于k-means算法的用户分类和拍卖算法的相关研究。文献[3]提出的MEC平台的体系结构描述以及支持上述特性的关键功能,说明了应用程序开发人员可以利用来自MEC的实时无线接入网信息提供上下文感知服务,支持使用涉及云服务器的协作计算在资源约束设备中执行计算密集型应用程序。文献[4]利用局域网络收集用户数据,使能源互联网的数据压缩成为可能,在不增加额外能耗开销的情况下,可大幅度提高随机访问的可能性,降低传输延迟。文献[5]提出MEC环境下如何保证q(quality of service),把计算迁移到边缘和基础设施去中心化,能够支持新兴的应用程序,实现了可接受的服务质量。文献[6]在WLAN中,将多种类型的网络资源共同分配给用户以实现q的公平性,将用户q需求转化为多资源需求,并应用优势资源公平方案为每个用户分配网络资源。文献[7]使用了一种根据总功率和误码率约束系统参数进行参数化的联合方法,根据每个用户的实际需要来调整每个服务的平均吞吐量,通过最大数量的子载波进行传输保证了q的子载波共享调度。文献[8]将移动应用程序的计算密集型任务从资源稀缺的移动设备转移到位于边缘网络的服务器上,结合通信通道和边缘服务器的容量限制,实现最小化应用程序的平均完成时间。文献[9]采用分布式资源分配的容错算法——时隙算法,以可执行协议,使用简单的启发式和捐赠方法合理的在成员之间分配资源。文献[10]提出了一种基于Nim博弈获胜策略的云资源分配机制为所有客户端提供了有效数量的运行云服务器,并通过使用预配对方法快速有效地分配云资源,不需要搜索正在运行的云服务器的剩余资源,减少了调度资源所花费的时间。文献[11]利用流量规范参数化每个无线体域网络的流量源,得到每个无线体域网络所需的服务速率,采用优先资源分配算法,根据无线体域网络的服务优先级分配信道资源。文献[12]以器件特性的数据传输方案,采用k-均值聚类算法,根据流量特征对设备进行分类。每组分类设备具有不同的优先级,无线信道访问时间由该优先级决定,根据优先级使用不同的信道访问时间可以避免终端设备的冲突,提高传输效率,并对随机组合拍卖机制[13]、多市场动态双向拍卖机制MobiAuc[14]、云环境下虚拟机资源分配与定价机制[15]等问题进行了研究。本文提出KDSAA策略,采用“流体”模型[16],有效提高了计算资源和频谱资源的利用率。
2 数据表示
在移动边缘计算中,评判算法性能的主要指标为:吞吐量和时延。本文实验以边缘云的吞吐量和传输时延为主要评判标准,结合算法在不同条件下的表现,综合评判算法性能。本文K-means算法以用户的实际资源请求量和用户的优先级为主要属性,模拟边缘云部署在基站上,对用户进行聚类,再根据用户坐标,使用类欧式距离公式计算用户到基站的距离,筛除超出基站范围用户,使用拍卖算法将资源按照对应比例拍卖给用户,结合动态频谱资源分配降低传输时延。为获得较好实验效果,该实验只考虑了单时隙下的单基站资源分配。以下为数据表示的主要部分:
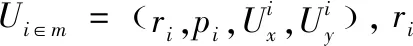
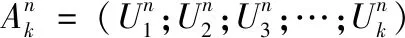
3 动态的计算资源和频谱分配策略
本文中动态计算资源和频谱分配主要有两个策略。一是根据用户的资源请求量和用户优先级两个基本属性,采用K-means算法把用户聚类成n个不同类型用户簇,二是针对不同类型用户簇的资源请求量,采用荷兰式拍卖算法,把基站中的计算资源和带宽按照不同类型用户簇的竞价比例进行分配,将基站资源进行“流体”化,从而基本达到根据不同用户的实际资源需求量进行分配的要求,即“用多少分多少”,以此来实现基站较大的吞吐量和较低的传输时延。
实验主要分为5个步骤:
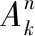
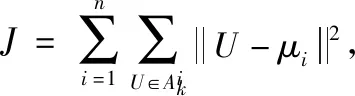
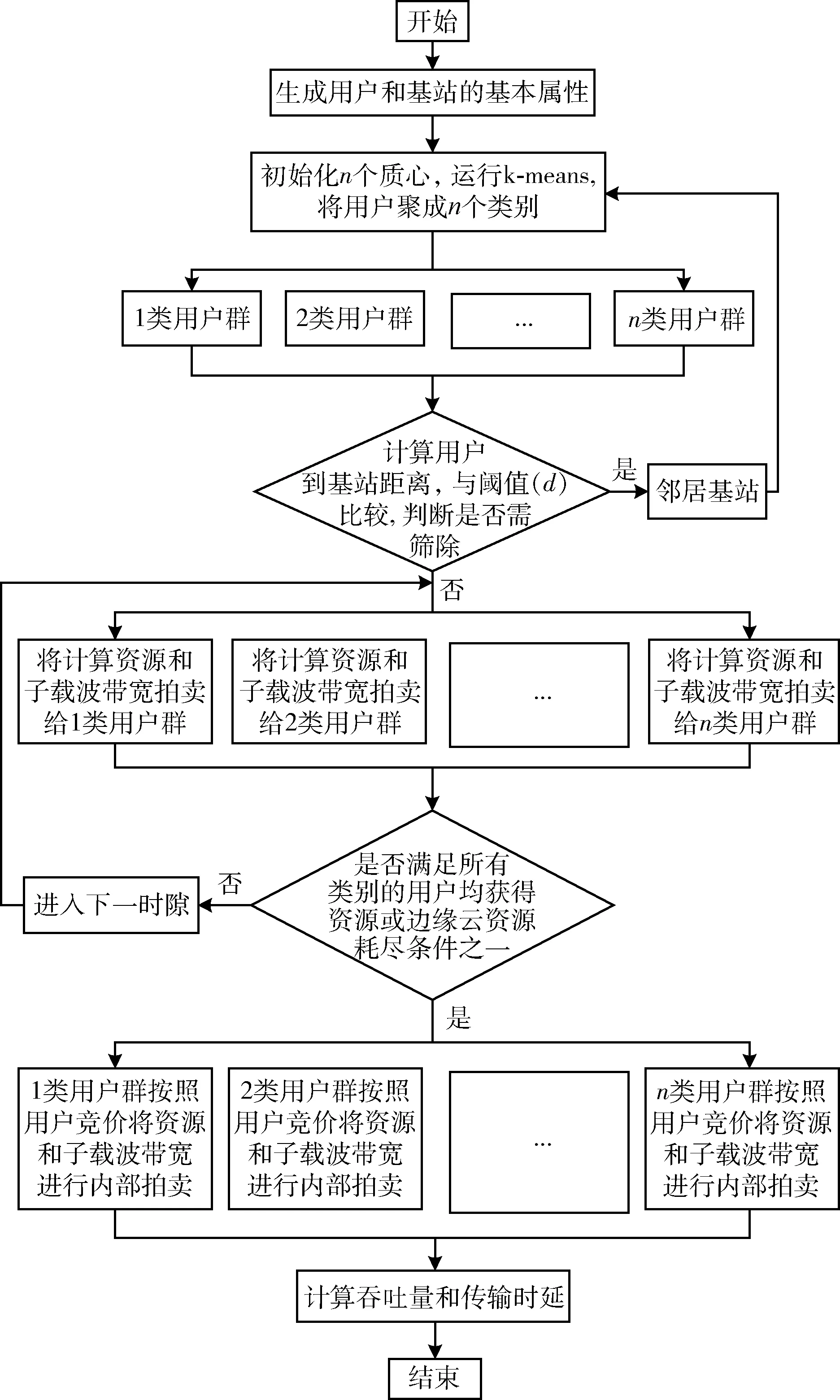
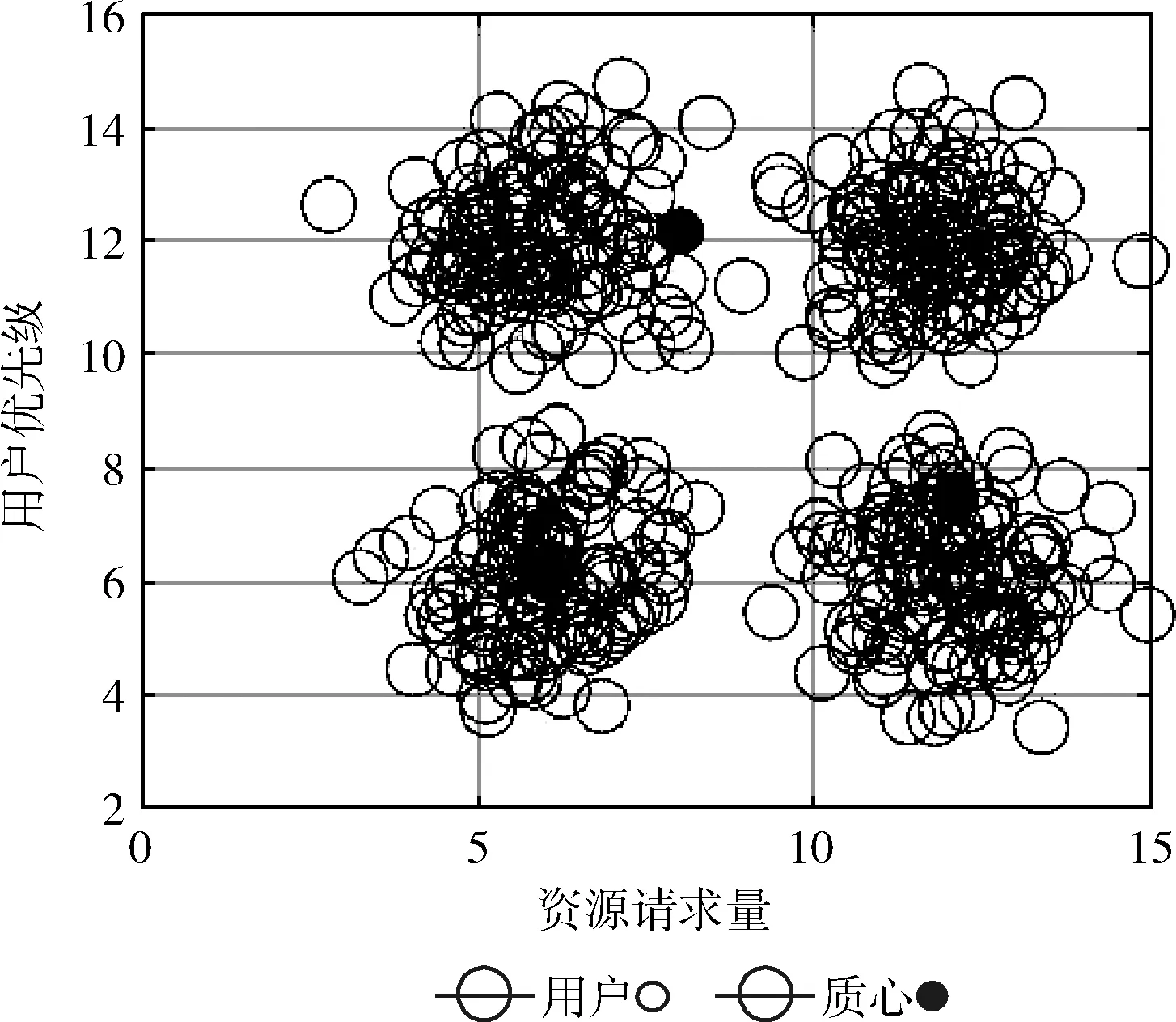
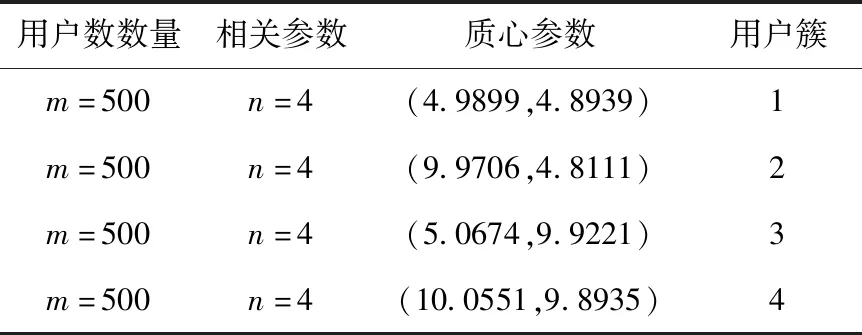
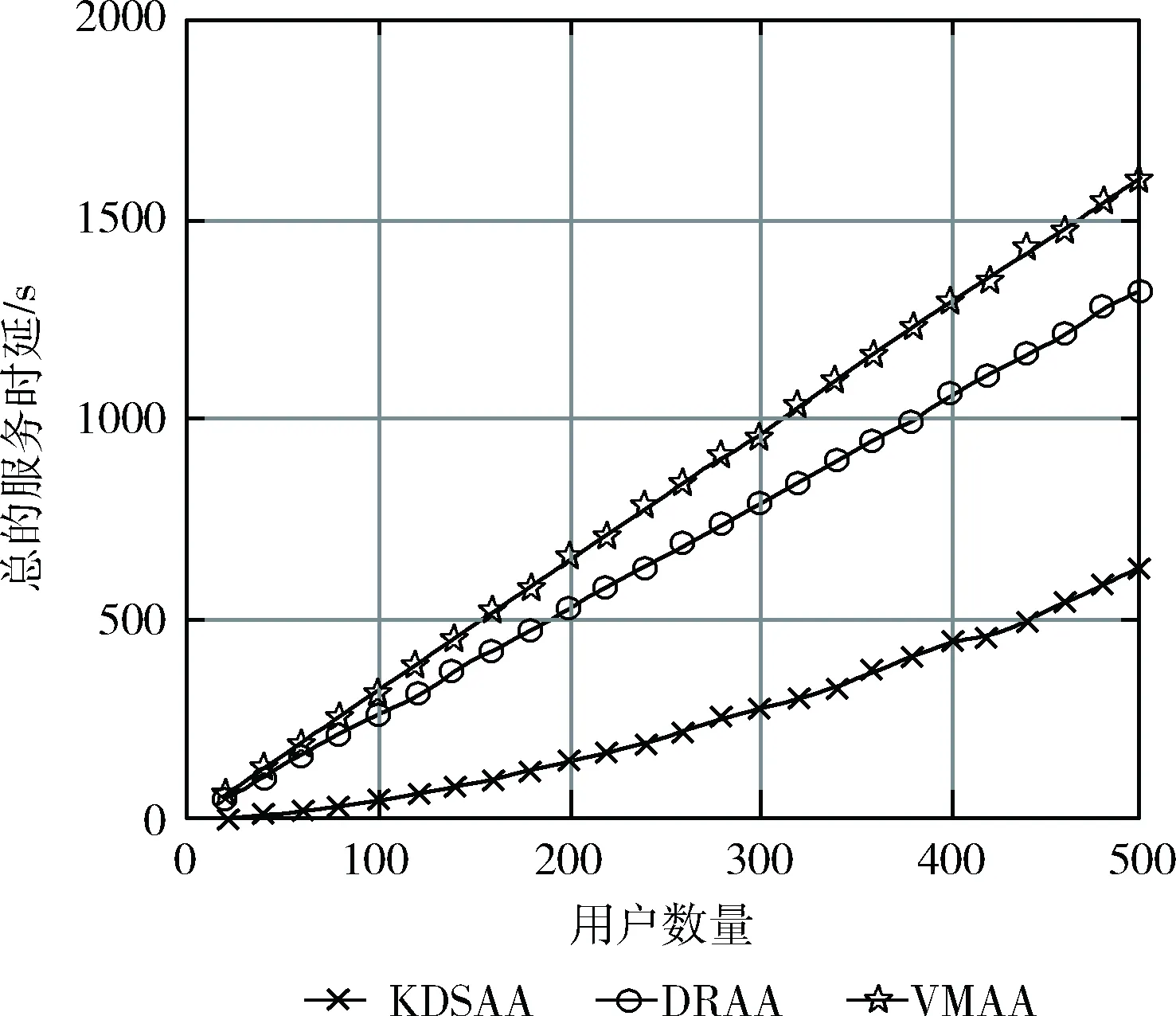
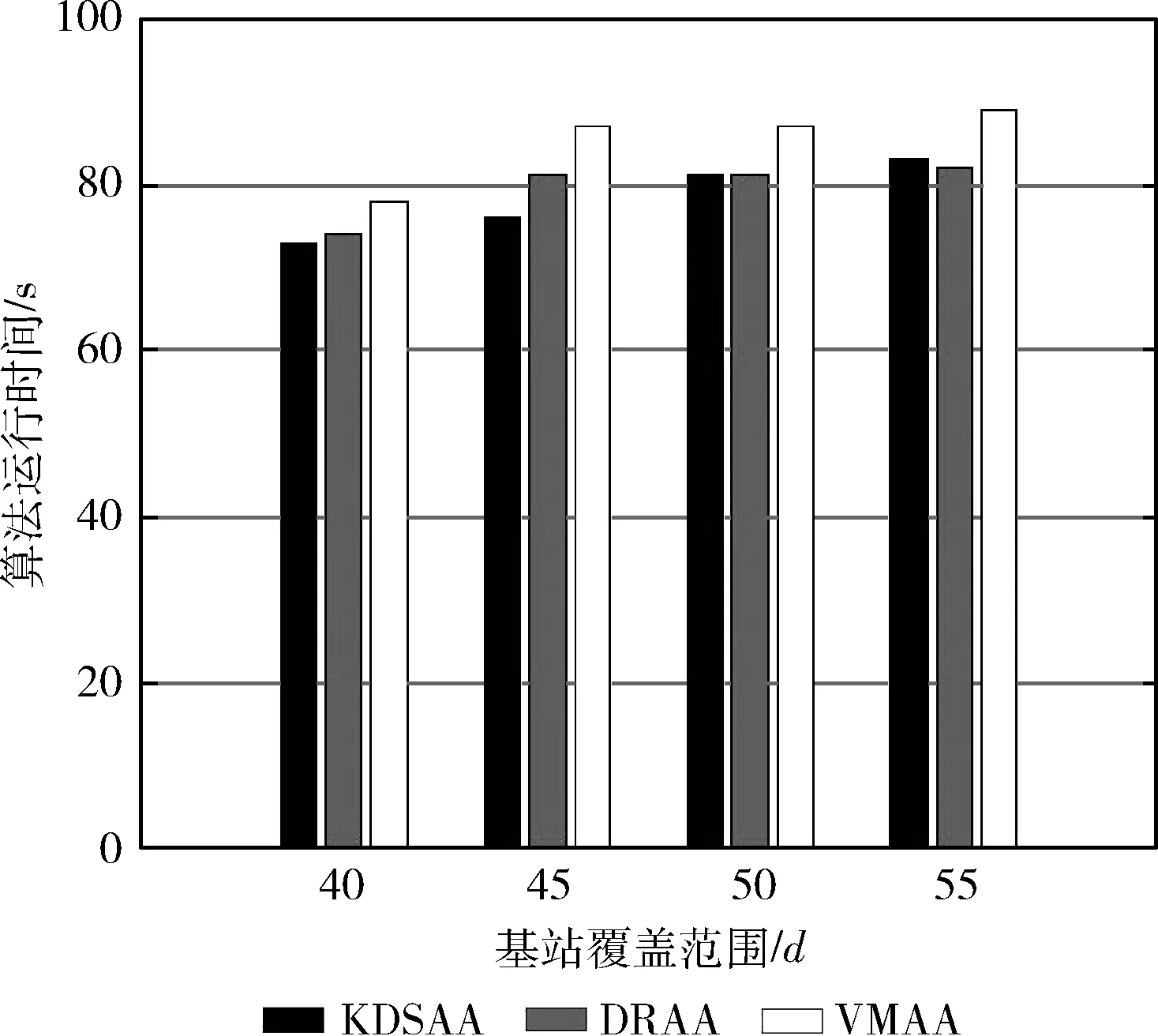
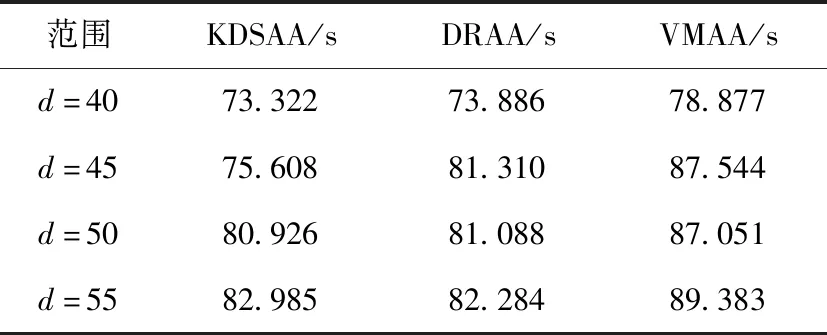
(2)使用类欧氏距离计算每个用户与基站的距离D=(D1,D2,…,Dm),为了保证实验效果,目前只考虑单个基站范围内的用户,并设置基站覆盖阈值d(Di 接下来我们把基站资源(BSresource)和带宽(BSband)对应不同类型用户簇按照比例分成n份,同样使用“用多少分多少”的方法,即每份中均包含相应数量的“资源块”,表示为Rn(分配资源量)和Bn(分配带宽),如式(1)和式(2)所示 (1) (2) 考虑到基站计算资源量和带宽有限,所有用户簇分配的计算资源量总和、带宽总和均不能超过边缘云的资源总量,应满足式(3) (3) (4)参照(3)分配方法将基站频谱资源进行“流体”化分配,即“用多少分多少”,不同用户簇把簇内资源按照每个用户的竞价分配子载波带宽,子载波带宽b如式(4)所示 (4) 为保证实验效果,用户分配到的子载波带宽总和不超过基站子载波带宽总量,子载波最大分配个数不超过Num,如式(5)所示 (5) (5)线性求出基站吞吐量最大值和传输时延的最小值:基站吞吐量和传输时延在式(1)和式(5)约束下,求得目标函数Rc(边缘云吞吐量)的最大值和Rt(传输时延)的最小值。 1)求出边缘云的最大吞吐量Rc 2)求出所有用户的最小传输时延Rt 算法步骤和流程如下: 步骤1 初始化参数m、n、k、d、e、N0、h0,用户和基站的基本属性。 步骤2 初始化n个质心,运行K-means算法,将用户聚成n个用户簇。 步骤3 将不同用户簇存入不同矩阵,计算用户竞价、计算用户到基站距离,筛除大于阈值d的用户,计算每类用户簇竞价总和。 步骤4 参照不同用户簇的计算资源总和,基站按式(1)和式(2)把“流体”化的资源进行按比例分配,确保每个用户簇均可获得合适资源量。 步骤5 用户簇结合簇内最大竞价将资源进行内部拍卖,直到所有用户均获得合理计算资源或该基站资源耗尽时终止。 步骤6 计算子载波带宽和用户竞价,按式(4)进行分配。 步骤7 计算基站吞吐量最大值和传输时延最小值。 步骤8 结束算法。 在实际环境中边缘云的资源分配由多个基站协调配合,动态完成对用户需求资源的分配任务,但本文实验只考虑了单基站、单时隙,因此在KDSAA算法整体实现流程示意图中判断框后的邻居基站和下一时隙在本文实验中不体现。KDSAA算法整体实现流程如图1所示。 图1 KDSAA算法整体实现流程 为验证本算法在动态资源和频谱分配策略中的性能,本文使用MATLAB2016a为实验平台,PC配置为联想启天T5000,16 G内存,酷睿i7CPU,Windows10操作系统。本实验使用数值计算,将KDSAA、DRAA和传统的虚拟机分配算法(VMAA)进行比较,分别计算吞吐量和传输时延,观察3种算法随着用户量变化时的性能状况。 实验参数设置如下:用户基本属性资源请求量r和用户优先级p设置:均值为10,相关系数为1的高斯数据,坐标x,y为50以内的随机值。边缘云基站基本属性值见表2,程序运行次数所用时间总和为该算法计算结果所用时间,算法复杂度为O(n2)。为采集较好的实验效果,本次实验以循环100次求均值为结果,并将所得结果单位化处理。 在K-means算法中,设定合理的聚类个数n值是NP问题。n值的确定需要相关的专业知识来猜测和预判,而预判的结果往往是不准确的,得到的结果也不理想,本实验根据相关先验知识,采用启发式算法,对不同n值进行适当的枚举实验验证,最终确定n值设为4时聚类效果最好,这里例举n值为3、5时的聚类效果:n=3,聚类如图2所示。n=5,聚类结果如图3所示。 图2 当n=3时聚类结果 图3 当n=5时聚类结果 通过实验发现,将质心个数n设置为4时聚类结果达到最优。此时,考虑到基站性能和实际生活环境,将边缘云覆盖用户上限设为m=500。仿真参数见表1。 表1 仿真参数 本实验设置聚类质心个数n=4,分别定义为:n=1为普通用户簇,n=2为重要用户簇,n=3为一般重要用户簇、n=4为较重要用户簇。用户的资源请求量不同,对应的优先级也不同,因此使用mvnrnd函数产生均值为10,相关系数为1的高斯数据。我们选取4个初始质心,从序号为1的用户开始,每隔m/n个选取一个,直到选够4个。然后运行K-means算法对用户进行聚类,通过不断更新质心位置,直到4个质心参数值基本不再变化或迭代次数超过用户量m时结束聚类。聚类结果如图4所示。 图4 用户聚类结果 聚类结束后,我们用4个聚类出的质心作为不同类型用户簇的表征,分别对应1、2、3、4,质心参数和不同用户簇对应结果见表2。 表2 不同类型用户簇对应 由表2中结果分析可知,聚类出的4类用户簇和我们预测的基本吻合,分析入下: (1)当用户资源请求量较小,用户优先级也较低时,被划分到普通用户簇中; (2)当用户资源请求量较大,用户优先级也较高时,被划分到较重要用户簇中; (3)当用户请求量或用户优先级其中一个较低时,就被划分到重要用户簇或一般重要用户簇中。 根据用户实际需求将用户分类,不仅可以有效提高用户体验,也可以使基站资源得到合理的分配和充分使用。接下来,考虑单个基站的覆盖范围有限,且用户到基站的距离对信道质量会产生影响,我们对超过基站覆盖范围的用户进行筛选,通过改变实验中基站覆盖范围阈值d分别来测试对比3个算法的性能,这里列举d=45和d=50时的实验对比结果,如图5~图8所示。 图5 用户数量和边缘服务器吞吐量的关系(d=45) (1)不同阈值d,吞吐量对比; 图6 用户数量和边缘服务器吞吐量的关系(d=50) 图7 用户数量和边缘服务器传输时延的关系(d=45) 图8 用户数量和边缘服务器传输时延的关系(d=50) (2)不同阈值d,传输时延对比; 由以上实验结果我们看出,KDSAA算法在吞吐量和传输时延上要优于DRAA和VMAA。因考虑到单个基站所能承受的用户量有限,所以本实验中用户数量m值上限设置为500。在实验中,当基站覆盖范围阈值d不同时,基站所覆盖用户数量也不同,因此该实验结果也间接验证了当用户数量递增时,KDSAA算法在吞吐量和传输时延上的表现也优于DRAA和VMAA。传统的虚拟机分配方式是将资源分块,再拍卖给用户,用户的资源请求量的变化不会对基站的分配产生较大影响,这使得资源利用率较低。DRAA将计算资源“流体化”,是根据用户的实际需求量进行分配,所以DRAA的吞吐量和传输时延的指标均优于VMAA。KDSAA根据用户的资源需求量和相应优先级进一步细分用户,为用户提供了更精准、更高效的服务,同时也大幅度提高了基站资源利用率。其次,KDSAA将频谱进一步分配,根据用户实际资源请求量计算竞价大小,使每个子载波都会获得合理的带宽,让频谱资源也得到了充分利用,尤其是在基站覆盖范围阈值d值变大时,即使距离基站较远的用户依然可以获得较好的资源分配。综上所述,在基站覆盖范围一定时,KDSAA在吞吐量和传输时延指标上的表现更好。 实验将程序运行时间模拟为基站处理器运行时间,在改变基站覆盖范围d(用户数量同步变化)的情况下,对比3种算法的运行时间。3种算法执行100次的时间对比如图9和表3所示。 图9 算法执行时间 表3 算法执行时间数据 由以上实验结果我们可以看出3种算法的执行时间无明显差距,随着基站覆盖范围和用户数量变化时,KDSAA的执行时间略低于VMAA的执行时间,与DRAA执行时间基本一致。虽然计算时间上无明显优势,但足以提高对时效要求较高的用户体验,且KDSAA相较于DRAA和VMAA有着较高吞吐量和较低传输时延,综合各项实验指标,KDSAA 更适用于在MEC环境下的动态资源分配。 随着5G通讯技术的到来,在MEC环境下,用户对服务质量和应用体验要求越来越高,需根据用户的实际场景和需求对资源进行合理分配,才能达到较好的资源分配效果。文中我们对用户进行合理的聚类后,结合计算资源和频谱资源分配策略,获得了较好的分配效果。下一步工作将进一步研究MEC环境下动态时隙中多基站博弈的资源分配问题。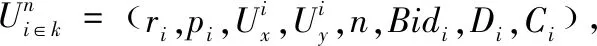
4 仿真实验






5 结束语
猜你喜欢
英语文摘(2020年10期)2020-11-26
电子制作(2019年23期)2019-02-23
测控技术(2018年7期)2018-12-09
测控技术(2018年6期)2018-11-25
智富时代(2018年3期)2018-06-11
智富时代(2018年3期)2018-06-11
电子制作(2017年8期)2017-06-05
计算机应用(2016年10期)2017-05-12
探索科学(2017年4期)2017-05-04
系统工程与电子技术(2016年7期)2016-08-21
