
基于批量计算的网络状态细粒度感知方法
2021-04-22 07:38吴礼华陈源宝江伟健
无线电通信技术 2021年2期
吴礼华,陈源宝,黄 双,谢 刚,江伟健
(1.武汉第二船舶设计研究所,湖北 武汉 430000;2.武汉大学 电子信息学院,湖北 武汉 430000)
0 引言
近年来,随着网络用户和应用数量的显著增长,网络运营商不得不对基础设施进行大规模升级,以满足不断增长的用户需求。Cisco公司的调研报告指出,到2021年全球移动数据流量将进一步增长63%[1]。通过网络监控技术来感知网络的性能对于现代化的运维体系而言至关重要,我们不仅希望了解关于网络流量的信息,还需要知道他们在网络传输过程中所经历的细节。因此,建立一个强大的网络监控系统有3个必须考虑的因素:测量信息的覆盖面、测量值的精确度和测量任务所消耗的资源开销。
然而,如今的很多监控解决方案迫使用户在这三者中做出取舍,其根本原因在于目前的方案过于依赖外部服务器对于数据的处理,当网络流量速度很快时,将会率先成为系统的性能瓶颈。因为目前的分析系统在面对高速流量时,要么使用采样的方式来降低收到的流量速率,要么必须采用针对性强的专用硬件,这样不得不损失部分信息,抑或增加系统成本。因此,考虑在可编程交换机上实现一种能让这两种目标兼顾的遥测系统,即利用交换机中的可编程转发流水线(Programmable Forwarding Engine,PFE)和运行在交换机操作系统中的CPU等本地计算资源,结合网络带内遥测(In-band Network Telemetry,INT)技术以及报文合并与压缩技术在本地生成包含足够信息量的遥测报告,即无需通过外置的服务器,直接在本地即可生成。这种方法无疑可以显著降低成本,但是又会带来新的挑战,即交换机本地计算资源难以承担高速流量(Tbit/s级)下的报告生成任务。因此本文主要研究如何在面对高速流量时,在交换机本地生成高精度、特征参数丰富的测量报告,提出了一种可部署在硬件交换机上的批量计算测量报告生成方法。
1 相关工作
数据平面的主要功能是实现数据包的处理和转发,一般由交换机或路由器等组成,它将数据包作为输入,经过流水线式的处理后将它们从指定端口输出。在传统数据平面设备中通常由专用集成电路(ASIC)负责实现。这些ASIC通常是可配置的,但是其能够执行的转发逻辑在设计之初是固定好的。
软件定义网络(SDN)[2]是一种全新的网络体系架构,它的核心思想包括将网络中控制平面和数据平面的解耦以及可编程的特性,它将控制平面从封闭的网络设备中剥离出来,而数据平面以通用“白盒”硬件的形式存在。网络监控系统的主要功能是掌握网络中各种流量的当前状态,并为其建立模型来描述当前和未来网络的运行状态。这些被监控系统感知到的状态信息可以用来进行深度分析,解决比如网络故障定位等问题。
P4.org推出了一种专用的编程语言P4(Programming Protocol-Independent Packet Processors)[3]来配置可编程数据平面,这是一种用于网络数据平面的特定域编程语言,它可以描述网络中的可编程转发设备(如硬件或软件交换机、可编程智能网卡及路由器等)处理数据包的方式和流程,让数据平面的功能得到进一步开放。
可编程交换机上实现一种遥测系统能同时兼顾测量精度、覆盖范围和降低硬件成本,即利用交换机中的可编程转发流水线和运行在交换机操作系统中的CPU等本地计算资源,结合网络带内遥测技术、报文合并与压缩技术在本地生成包含足够信息量的遥测报告,即无需通过外置服务器,直接在本地生成。
网络带内遥测[4]是一种典型的背负式测量方法,其核心思想是在普通数据包的转发过程中,利用可编程流水线能识别的指令在数据包头中插入一些需要的元数据(比如时间戳),从而使测量能力拥有数据包级别而不是流级别的细粒度。由于整个过程只在数据平面内部完成,无需控制平面参与,使得数据平面自动拥有了端到端的数据搜集能力,能够实时掌握网络状态信息。然而,这种方法虽然带来了高精度、高细粒度、高实时性的好处,同时也会带来采集数据冗余的问题。为了节省不必要的处理开销,针对不同测量需求,需要在处理测量报告时,在采样精度方面做出针对性的调整。
测量指标的丰富程度,用于评价测量报告中包含的自定义统计信息和元数据的种类多少。拥有自定义测量参数的功能就可以支持更多的应用,因为不同功能的应用程序需要不同的测量参数,以BOT Net检测[5]、QoS测量[6]和Incast故障调试[7]三种常见任务为例。BOT Net检测主要依靠系统分析主机之间的通信模式,仅使用报告中数据包的基本属性(例如数据包计数器、字节计数器和时间戳)就能实现。QoS测量需要一些网络性能的统计信息,如丢弃数据包计数和路径延迟。而Incast问题的调试则需要使用平均队列深度这个指标来评价交换机的内部运行情况。除了支持更多的应用之外,丰富的测量指标还可以提高许多应用程序的性能,例如基于机器学习的分类器[8]或网络异常检测器[9],它们可以同时利用多种特征参数。
2 基于批量计算测量报告生成方法
2.1 问题描述
我们的需求是在不牺牲测量信息丰富度的情况下,实现高覆盖、高精度的网络监控。结合可编程数据平面的特点以及INT的优势,考虑利用P4的灵活性对可编程交换机的功能进行优化,使其能够在本机上为超高速流量(即>1 Tbit/s)生成可定制的测量报告(INT report),而且无需进行采样操作或依赖外部服务器的支持。
如果要使用可编程交换机中的计算资源直接以Tbit/s速率生成测量报告是很难的[10]。可编程交换机内部有两种计算资源:可编程转发引擎(Programmable Forwarding Engine,PFE)和通用CPU(例如,多核心的XEON处理器)。这两个处理器本身都不能支持测量报告的生成,一方面因为PFE本身没有足够的内存来跟踪所有并发的流量,并且其计算模型往往受限(为单一功能准备),这些模型不支持测量报告生成所需的复杂数据结构。另一方面,交换机上的通用CPU也无法提供足够的吞吐量。
2.2 解决方法
我们的目标是将产生INT report的功能直接部署到数据平面的交换机上。所以,需要将整个报告的产生工作分解成两个互补的部分,让这两部分分别被两种处理器处理。首先可利用PFE对INT包头中携带的测量数据进行预处理,以减少后续CPU所需的工作量,而CPU则专注于处理那些PFE无法计算的复杂逻辑,每种处理器都依靠另一个处理器来克服其自身的局限性。
如图1所示,首先让PFE在流水线上生成Mini report,但每次生成只考虑每条流中最近到达的一批数据包(小型批处理)。这样在PFE中生成Mini report而不是完整的测量报告减少了对于内存的需求,并允许使用更适合PFE处理的数据结构(例如哈希表)。每当两条流发生冲突时,PFE会将较旧流的Mini report优先发送到交换机CPU并更新表项。这种精简的计算逻辑可以在计算资源和模型严重受限的可编程交换机的PFE上实现。然后,PFE的DMA引擎再将Mini report传输到CPU的主存储器,在该内存中配置有一个聚合器,使用针对测量任务优化过的哈希表将它们重新组合成完整的INT report。最后,这些INT report可以直接导出到外部收集器或分析服务器,而无需任何额外的处理。使用这种方案,即使在交换机的CPU上运行的聚合器也不需要用采样的方式来减缓高速流量。
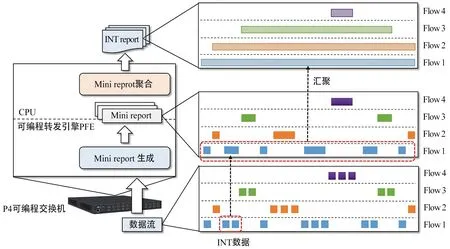
图1 本地生成INT report示意图Fig.1 Generate INT report schematics locally
如图2所示,为可编程交换机系统结构图,整个系统分为两层,下层是可编程的硬件流水线PFE,可用P4语言描述其功能,支持全线速转发,用于对收到的流量进行分段生成Mini report,上层是交换机内置Linux操作系统和通用CPU,用于将多个Mini report组合成完整的INT report后导出到外部数据分析平台。
可编程交换机上的通用CPU和专用可编程转发引擎(PFE)。如前所述,这两种处理器单独运行都不能支持生成完整INT report的工作。交换机CPU无法满足支持所需的处理速度,例如,对于Tbit/s级速率的流量而言,每秒会收到数亿个数据包。主要的瓶颈是将数据包转换成INT report的过程,由于内存延迟高,键值对比较的操作需要花费很多个时钟周期。例如,在Wedge100 BF-32x的CPU上使用Redis所支持的吞吐量约为500 packge/s,比要求的速度低两个数量级。另一方面,PFE虽然可以使用片上内存,以很高的速率执行键值对查找的任务,但这个内存太小,无法存储足够的INT report以满足整个测量任务的需要。此外,PFE属于受限计算模型[5],该模型阻止了PFE,以线速实现除查找(例如插入)以外的对完整键值(key-value)数据结构的操作。
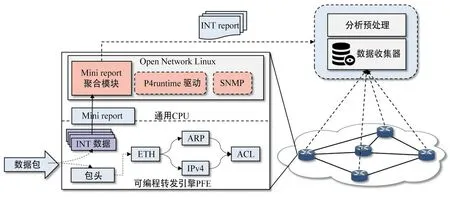
图2 系统结构图Fig.2 System structure drawing
通过将INT report生成算法分解为适合PFE和CPU的两个部分,其中,PFE仅仅负责产生微报告(Mini report),用于收集短时间内的活动流量,这样可以减少并发处理的次数,以降低内存开销,同时这样做有利于将更简单的数据结构映射到PFE硬件上。在交换机CPU上运行的Mini report聚合器使用优化过的key-value数据结构,负责最后将它们组合在一起形成完整的INT report,以发挥CPU适合做复杂运算的特点。由于在Mini report上操作而不是直接在数据包上操作可能会降低CPU键值操作的速率,所以需要对CPU线程进行优化,降低单条报告的计算成本,以最大限度地提高总吞吐量。
2.3 CPU层对于INT report的生成
如图3所示,交换机的CPU上主要运行Mini report聚合器,并将从PFE中收到的Mini report片段组合成完整的INT report。
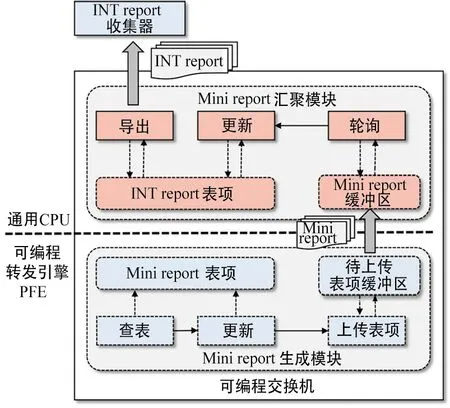
图3 内部结构图Fig.3 Internal structure diagram
设计Mini report聚合器的挑战在于优化键值运算的数据结构,使其能够将Mini report合并成完整INT report的速率最大化。主要分为以下步骤:
(1) 从提交缓冲区读取Mini report
PFE的DMA引擎从提交缓冲区中读取Mini report,然后拷贝到交换机主内存中的环形缓冲区。Mini report聚合器以批处理的方式对Mini report进行合并,然后将空闲单元的地址重新发送到DMA引擎,这种工作方式与某些高性能网卡的工作方式类似,只要存在可用的空闲单元,DMA引擎就可以动态地调整拷贝速率。基于多核处理器的优势,多个Mini report聚合器可以与独立的缓冲区同时工作,PFE会基于键值对的判断标志来自动平衡提交的Mini report与这些缓冲区的关系。
(2) 以哈希表的形式存储Mini report
聚合器以哈希表的形式存储那些活动流量的Mini report,对于每个Mini report,聚合器要么通过插入新INT report来更新现有报告的特征参数,要么直接拷贝INT report到输出缓冲器,然后移除其对应的哈希表。
然而,这样的操作方式,导致哈希表的效率成为聚合器的性能瓶颈,所以对其进行优化是需要关注的重点问题。考虑了4种优化哈希表性能的方法:
① 线性探测法(Linear Probing,LP):线性探测法对哈希表进行线性搜索,它可以显著提高INT report的输出吞吐量。当哈希表出现匹配失败时,下一个待处理的报告已经被CPU读入缓存了。
② Flat Table:在这种方法中,聚合器会直接在哈希表中存储报告内容,如每个表项中存储一个报告文件,而不是通过指向容器地址的指针。这样做的好处是提高多份报告之间的关联性,节省了时钟周期的数量,并进一步减少了缓存失配的可能性。
③ 键值合并法(Integer Key,IK):该方法让聚合器使用两个64 bit整型数组表示流的键值,第一个数组存储IP地址,第二个存储端口ID、协议类型以及物理链路ID。这样就可以利用SSE4.1来进行128 bit键值对处理,这样就只需要两个指令周期。
④ 查找表预读取(Lookup Prefetching,LPre):聚合器通过批处理查找的方式来降低内存延时,它会预先从哈希表项中读取那些最有可能被提前处理的报告,预读取哈希表的方法可以算是对线性探测法的补充,因为当报告不在预期的表项中时,预读取的方法仍然会加载它。
(3) 重新封装合并成INT report
CPU中有一个独立线程用于将提交的INT report合并成数据包的形式,然后发送到外置的分析服务器。同时,它还会周期性地扫描哈希表项,并删除那些因为未处理而超时的流。
3 实验与性能评估
3.1 实验环境设置
实验平台基于5台Edgecore公司生产的可编程交换机Wedge 100BF-32X,它拥有32个100 Gbit/s端口,使用Barefoot公司的TofinoP4可编程交换芯片,和Intel D1517四核CPU,内置8GB RAM。实验平台拓扑如图4所示,Mini report聚合器模块在Linux系统上使用C++实现。生成的INT report中包含IP五元组和另外几种测量参数: CPU利用率、数据包总数、字节总数、入口时间戳和出口时间戳。测试流量的设置如表1所示。
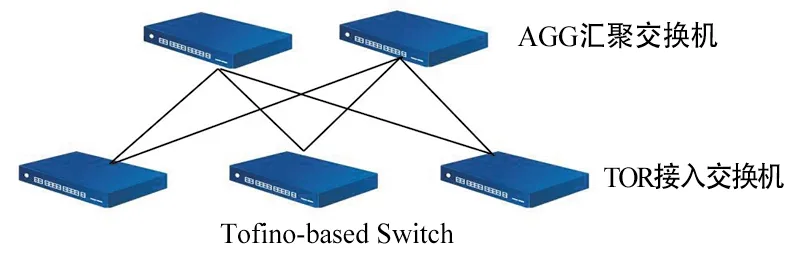
图4 实验平台结构图Fig.4 Experimental platform structure diagram
实验中使用Ixia公司的IxLoad工具包来产生测试流量,流量模式为数据中心模式。为了模拟出数据包速率和活动流的数量随着链路容量线性变换的场景,提前对Mini report表项进行了设置,为有流量接入的链路提前分配了不同的段,并在每个活跃链路的Mini report与CPU缓冲区之间配置了静态负载均衡。

表1 测试流量Tab.1 Test flow
3.2 实验结果分析
首先测量Tofino的PFE,用于生成Mini report时消耗的片上资源。在Tofino的PFE上,Mini report生成器可以达到线速运行,因此问题通过统计消耗的Tofino片上资源来确定还剩余多少资源可供其余功能单元使用。此处以Tofino中4种主要的片上资源为对象:可编程转发表(Match-Action Table,MAT)、超长指令字(Very Long Instruction Word,VLIW)、带状态算术逻辑单元(stateful Arithmetic and Logic Unit,sSLU)以及三态内容寻址存储器(Ternary Content Addressable Memory,TCAM)。
由表2可以看出哈希的计算不需要额外的资源,而Tofino中大部分的sALU被消耗,这是因为在访问寄存器数组时,通过配置sALU的方法来计算数据包的哈希,因此避免了这些计算步骤。

表2 Tofino PFE的资源消耗Tab.2 Resource consumption of Tofino PFE
然后,测试Tofino的PFE中Mini report的生成效率,PFE通过生成Mini report的方式,明显减少了交换机CPU的计算负荷。利用Mini report与数据包的比率随着PFE中内存消耗的变化来描述这种效果。图5描述了TOR和AGG交换机的Mini report生成率。由图5可以看出,初期每10个包就会生成一个Mini report,随着消耗PFE内存的增加,处理能力逐渐增强到每50个包产生一个Mini report,此时仅需要消耗100 K PFE内存,然后生成效率趋于稳定,随后即使占用更多的内存也不会再提高生成效率,说明已经达到最佳值,大约每65个包产生一个Mini report。

图5 Mini report生成效率Fig.5 Mini report generation efficiency
由于CPU层的聚合器模块是采用哈希表存储的方式处理Mini report,所以如何优化哈希表的性能非常重要。因此对比了2.3节介绍的4种不同哈希表优化方法,其中加入了使用Redis数据库做存储的数据作为参考。由图6可以看出,4种优化方法的吞吐量都是随着CPU核心数的增加而增加,其中优化效果最好的是LPre方法,在4个核心全部启动时可以接近40 Mrps。
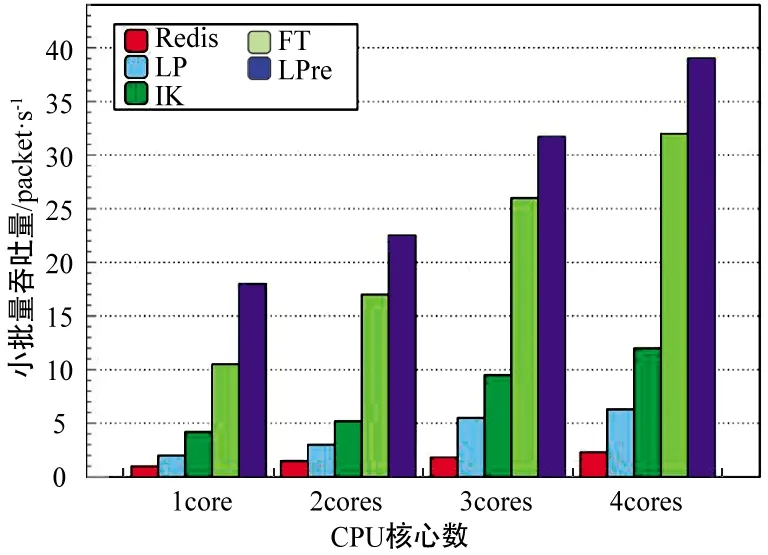
图6 吞吐量对比Fig.6 Throughput comparison
表3 统计了添加多种额外特征参数时生成INT report所需要消耗的硬件资源的变化。由表3可以看出,在Tofino的PFE中,为了添加新的特征参数,需要额外消耗8个MAT和sALU。对于交换机的CPU而言,新参数的加入对吞吐量的影响较小,因为瓶颈的出现是由大量针对Mini report的操作造成的,而不是针对单个Mini report中的字节进行操作造成的。

表3 添加特征参数引起的开销变化Tab.3 Changes in overhead caused by adding feature parameters
表4的统计结果表明,即使只使用少量的PFE内存,Mini report与CPU之间的传输速率相比于Tofino PCIe3.0X4接口可达32 Gbit/s的速度而言也很低。同时可以发现,将经过交换机本地处理后的INT report发送到外部收集器时所消耗的网络带宽很低,只相当于同等信息量下原始报告流量的1/1 000,说明这是一种对外部服务器要求不高的解决方案。

表4 通信开销Tab.4 Communication overhead
4 结论
利用P4可编程交换机来实现一种批量计算测量报告的方法,该方案将网络测量报告的生成工作转移到交换机本地进行,设计了一种二段式报告生成方法。先让交换机的PFE对接受到的INT包数据进行小规模批处理,生成微报告;然后通过DMA的方式上传至CPU层,利用CPU对它们做二级聚合,将这些微报告合并成完整的测量报告。实验表明,这种方案可以使商用可编程交换机支持Tbit级别的处理任务,从而能够在单节点上实现高覆盖率的网络测量,既保障了测量指标的丰富程度,又降低了计算成本。
猜你喜欢
大数据(2021年6期)2021-11-22
电脑爱好者(2021年8期)2021-04-21
电脑爱好者(2020年20期)2020-10-22
电脑爱好者(2020年18期)2020-09-26
电子制作(2019年24期)2019-02-23
网络安全和信息化(2018年6期)2018-11-07
电脑爱好者(2017年9期)2017-06-01
中国公共安全(2017年11期)2017-02-06
电脑爱好者(2015年13期)2015-09-10
自动化博览(2014年9期)2014-02-28
