
基于主成分降维模型的手写数字识别研究
2021-04-21 00:16:26杨济萍
网络安全技术与应用 2021年3期
◆杨济萍
基于主成分降维模型的手写数字识别研究
◆杨济萍
(兰州交通大学 甘肃 730070)
手写数字识别是光学字符识别技术的一个分支,因其受不同国家背景、个人书写习惯等因素的影响,脱机手写数字识别依旧是模式识别领域的重要难题.因此如何利用适当的图像预处理过程消除冗杂信息对特征提取的影响,为不同形态的手写体数字提供精准高效的算法模型是本文所研究的重点。
手写数字识别;K近邻;支持向量机;主成分分析
1 绪论
1.1 光学字符识别
计算机文字识别是一类光学字符识别(Optical Character Recognition,简称OCR),是一个结合模式识别的基本理论和许多典型处理技术的应用,数字识别是模式识别领域中的冰山一角,在各类字符识别理论和技术的推广上有着不可小觑的潜力。其中,数字识别中的脱机手写数字识别因其不同国家背景、个人书写习惯等因素的影响,对比人脑数字识别准确率较低,因而寻找较高识别准确率和较快识别速度的系统算法一直是学者们研究的热点。
1.2 本文研究意义与论文组织结构
本文选取阿拉伯数字为对象,采取KNN、SVM等经典算法与PCA-KNN、PCA-SVM优化模型实现阿拉伯数字的脱机手写数字识别,本文拟从手写数字图像预处理、单一识别算法模型和PCA“降维”优化后的手写数字识别模型三大模块进行。
文章通过对手写图像的处理还原了MNIST数据集的创建过程,在基本预处理如图像规范化、“平滑去噪”等步骤后。本文通过SVM算法与KNN算法,对比单一模型实现图像识别效果。主要研究PCA“降维”对单一算法的优化效果,从PCA“降维”的原理到PCA-SVM优化模型的实现,并将结果与单一模型进行比较。
2 基于单一分类算法的手写数字识别模型
2.1 基于KNN算法的手写数字识别
2.1.1 KNN算法的基本步骤
KNN算法的基本原理,简单概括为:在确定训练集中样本分布和特征的情况下,先把测试数据输入并与训练集中对应的特征进行互相对照,再比对训练集中与其最为相似的前K样本,那么K样本中出现次数最多的那个类别,就是该测试数据最终得到的分类类别。
2.1.2 KNN算法的系统实现与结果分析
本文在Anaconda.Python3.6集成开发环境(Integrated Development Environment,简称IDE)实现对MNIST数据集中训练集的训练,并且利用测试集对模型进行了误差分析。
对于KNN模型的实现,本文通常采用两种方法进行建模:一种是利用Numpy结合KNN分类原理,通过设定待分类数据,利用Numpy模块构造矩阵进行距离运算,最后对距离排序得出最优结果;另一种是利用sklearn工具中的KNN函数:“neighbors.Kneighbors”将数据集导入,然后进行K值的设定,并且计算欧氏距离,再对距离进行排序,得到最终分类结果,单独利用KNN算法进行脱机手写数字识别准确率在98%以上。对Numpy与KNN原理结合的算法,当K值选定为“3”时,最高准确率为98.73%,可以说对10000个测试样本中9873个样本进行了正确的识别;而在sklearn工具包中,K值选定为“4”时,最高准确率为98.9315%,可以解释为对10000个测试样本中9893个样本进行了正确的识别,可见正确率有所上升。但KNN算法整体上来看,该算法耗时太长,平均在半小时左右,并且对设备要求较高,不利于系统的推广应用。
2.2 基于SVM算法的手写数字识别
SVM在解决非线性、高维模式识别及小样本数据集中有许多特有的长处,在处理线性可分的问题时有一定的优势,并且能通过构建函数来解决非线性问题的学习分类。
2.2.1 SVM算法基本原理
SVM分类原理是要找出一个能够将两类样本进行完全精确分类的分界线即超平面。优化的目标就是要求分界线将两类样本准确分开并使安全间隔(Margin)越大越好。
2.2.2构建SVM分类模型
对于本文中的手写数据集来说,就是将多个二分类问题不断地进行拆分,转化为有限个十分类问题进行分类判别的实现。实验中常用的拆分方法主要有以下两种:一对一拆分法(One Versus One,简称OVO)和一对多拆分法(One Versus Rest,简称OVR)

2.2.3结果展示与分析
利用SVM进行手写数字字体识别从精度和时效方面来看还是切实可行的,模型识别准确率为94.9843%,用时仅需196.58s,可以说对10000个测试样本中9498个样本进行了正确的识别。相比较单独运用KNN进行识别时的98。73%高准确率和30分钟的识别时长,SVM在准确率损失下大大减少了识别所需要的时间,对于人脑0.02s的反应速度来说,SVM模型更适合于图像识别分类。由此可见相比较KNN算法SVM模型更具有推广性和实用性。
3 基于PCA-SVM的手写数字识别系统模型
3.1 PCA-SVM算法的基本思想
基于SVM算法对脱机手写数字识别的实现发现:当数据涉及高维度特征向量的问题时,算法学习所需要的数据量增加,使得大数据集训练学习需要较高的实验设备,例如在运行KNN传统算法对手写数字进行分类时,时长均在30分钟以上,可见该算法虽然可靠性较高,但识别效率不高,因此希望通过PCA实现在保留更多变量的同时,将“高维数据”集映射到“低维空间”,结合SVM计算原理,以实现手写数字识别算法的优化。
3.2 PCA-SVM模型生成步骤
在对数据进行读取的同时输入数据标签,抽取一部分数字组成n×n矩阵,对数据在不同维度下的精确率进行排序选取,精确率最高的维度即为该数据集最适合进行特征提取的维度,对PCA处理“降维”后的数据利用SVM算法进行距离的计算与排序,得到基于PCA“降维”优化后,再通过SVM运算得到脱机手写数字识别可靠度。
3.3 PCA-SVM算法的系统实现与结果分析
3.3.1分类模型的实现
此处沿用第三章中提到的MNIST数据集,该数据集每行代表一幅数字,一幅数字图像是28×28像素,即共有784列(维)。在输入数据和标签后,本文选取了前64维数字组成一个8×8的矩阵。
通过PCA“降维”的方法对数据进行多次尝试,测试过程中发现从784个维度至10维度随机选取的9个维度准确率结果如表1显示,在维度的变化中,在选取25维度时准确率已经达到96%,“降维”效果较好。

表1 PCA 维度对准确率的影响展示表
而在25维度之后,由于PCA维度骤减导致方差较小但重要的信息被过滤,从而使得准确率降低,如图1所示:
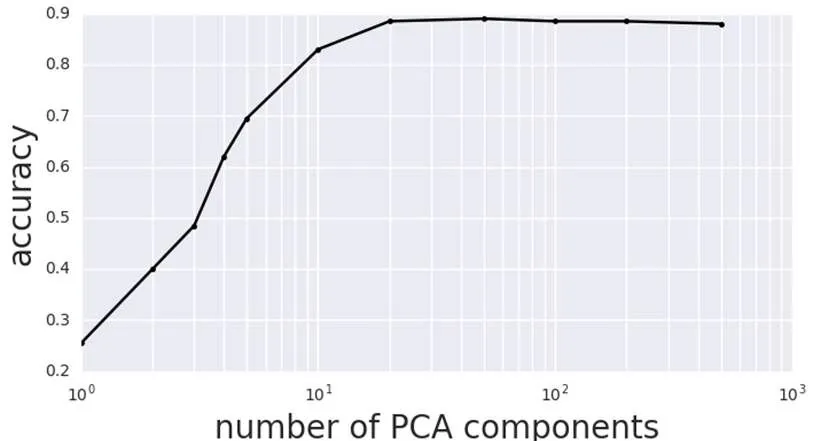
图1 PCA维度对准确率的影响
3.3.2结果展示与分析
为了进一步证实PCA“降维”对分类模型的优化,本文运用算法进行了数据集的识别,相比较单独运用KNN(k=4)算法实现手写数字识别结果可见,虽然在PCA维度缩减和KNN(k=4)模型重建之后的数据特征会损失2%左右的预测准确性,但是对于原784特征的实验数据来说,PCA数据维度的运用大大减少了冗杂数据对数字骨架特征提取的影响,使得模型便于对数据集进行特征提取与划分,并且在时效的提高和实验设备的运行损耗上有了明显的改善。在同样运用SVM运算模块前提下,PCA“降维”后的模型在准确度上有明显的提高,错误数减少了195个,虽然所用时间变长,但其确保了对数据识别的准确率,由此可见PCA“降维”处理对模型优化效用明显,在不同单独算法模型的推广和运用上可行性较高。
4 总结与展望
4.1 总结
本文着重探讨了如何利用PCA“降维”对脱机手写数字识别算法模型进行优化。在此期间运用经典算法例如KNN、SVM分别实现对MNIST数据集识别、分类,由此证明PCA“降维”对手写字符数据的优化处理能提高原模型的识别精确率,并且,PCA-SVM模型可靠性最高,时长最短。
4.2 展望

[1]章仁飞.基于支持向量机的多类数字调制识别方法[J] 世界科技研究与发展.2013(1):1-3.
[2]赵晓娟.手写体数字及英文字符的识别研究[D].吉林.东北师范大学.2010.
[3]刘荷苇.基于CUDA编程的神经网络手写数字识别[D].成都.西南交通大学.2013.
[4]白天毅.基于神经网络的手写数字识别关键技术研究[D].西安.西安工业大学.2014.
猜你喜欢
学苑创造·A版(2024年5期)2024-06-10 21:55:57
汉语世界(The World of Chinese)(2024年2期)2024-01-01 00:00:00
故事作文·低年级(2021年12期)2021-12-21 23:04:39
健康之家(2021年19期)2021-05-23 11:17:39
医学食疗与健康(2021年27期)2021-05-13 18:46:23
农业科技与信息(2021年2期)2021-03-27 07:27:38
作文成功之路·小学版(2020年7期)2020-08-24 08:19:18
海峡姐妹(2019年12期)2020-01-14 03:24:40
电子制作(2018年18期)2018-11-14 01:48:08
中国交通信息化(2018年5期)2018-08-21 03:37:40
