
MongoDB与Hadoop MapReduce的海量非结构化数据处理方案
2021-04-20 02:23宋辰萱孔祥文
电子技术与软件工程 2021年2期
宋辰萱 孔祥文
(中国市政工程华北设计研究总院有限公司 天津市 300074)
1 MongoDB与MapReduce数据传输机制
MongoDB 与MapReduce 的整合主要由MongoDB Cluster、MongoDB-Connector for Hadoop 以及MapReduce Cluster 组成,MongoDB-Connector for Hadoop 充当数据读写存储的重要组成部分,MongoDB Cluster 承担对非结构化数据分片存储的工作,MapReduce Cluster 负责并行计算的任务。[1]该连接器同时支持Pig以及Hive,从而可通过简单的脚本执行相对复杂的MapReduce 工作流。
2 基于MongoDB分片技术的性能改进
MapReduce 使用javascript 语法编写,其内部基于javascript V8引擎解析并执行,javascript 语言的灵活性使mapreduce 可以处理更加复杂的业务场景。
MapReduce 主要分为以下几个阶段,如图1所示。
Map:识别各种操作并将其分散至数据集群的各文档中。
Shuffle:根据Key 值将数据集分组,同时为每一Key 值生成与其对应的值表。
Reduce:数据表中的数据元素经过反复处理解析,将数据表回写至Shuffle,最终每个Key 有且只有一个数据表与其对应,同时该数据表只存在一个元素。
Finalize:获得数据最终计算结果并对该结果进行加工整合。
图2清楚地说明 Map-Reduce 的执行过程。
针对现有的分片技术提出性能改进方案,如图3所示。
2.1 设置合适的分片方式以及chunk size
由于数据执行或更改时,频繁拆分及迁移数据信息,输入输出资源会在splitting 和balancing 的过程中被大量消耗,因此数据迁移时,数据块的大小设置对资源的开销有一定的决定作用。数据块大小默认是64M,但实际运用时为避免输入输出资源的大量消耗则灵活选择分片方式,结合各自的业务特征,通常选择基于范围的分片方式或者基于Hash 索引的分片方式。
2.2 合理部署MongoDB分片集群Sharded Cluster
分散存储Sharded Cluster 中的数据,实现系统性能最大化,当用户发起数据读写请求时,mongos 在Config Server 即时访问数据接口,获取该数据集群中数据节点的路由信息,并将获取的读写请求转发至相关的数据分片中。用户可通过其中一个或者多个mongo访问到整个数据集群,将对数据的读取请求均匀分布于多个mongo中并将目标数据分散存储至分片中,从而达到负载均衡的目的[2]。
以下是连接分片集群的代码(图4):
由此,为了是实现负载均衡,系统会自动将用户请求分散至数据集群中所有mongos 中。当某个mongos 发生故障时,系统会自动转移故障,将应用请求转发至正常运行的mongos 中。
2.3 平衡CAP

图1
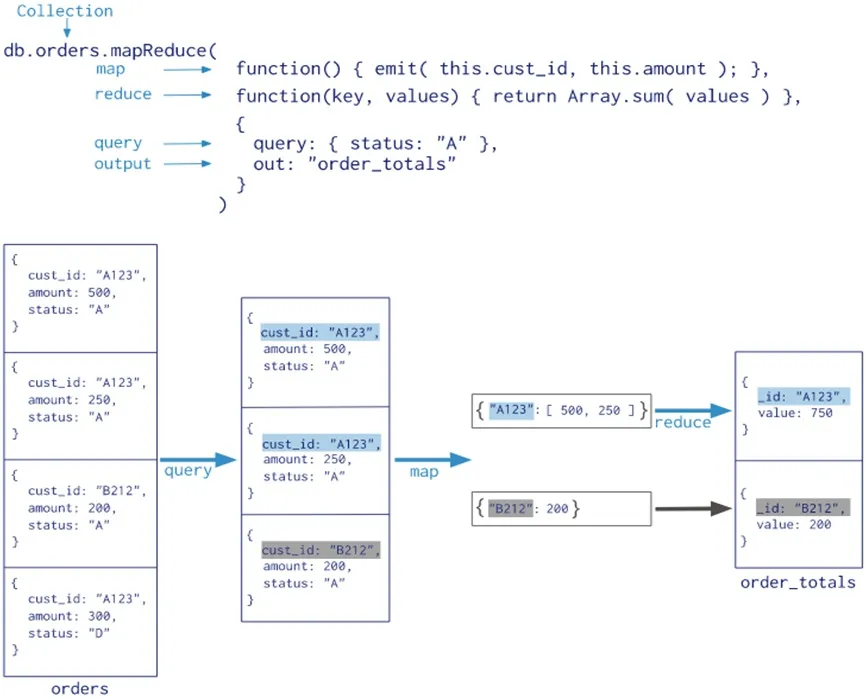
图2
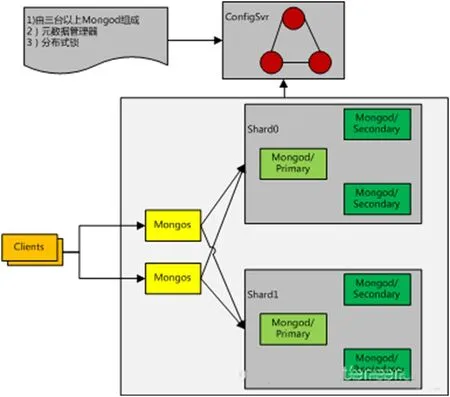
图3

图4
同一系统中一致性、可用性、分区容忍性往往不可同时兼得,这就要求我们在分布式架构设计时须考虑取舍,牺牲其中一个或两个要素来争取另一要素的最大性能。在以上三种性能中,系统对分区容忍性及可用性依赖较高甚至不可或缺,而对一致性的需求相对较低。因此,对MongoDB 读写操作时需要因地制宜地进行性能优化配置,可牺牲一致性来争取最大的可用性。为全面提高系统性能,对MongoDB 读写操作时设置用作数据写入的数据节点,由此可将写入的数据信息即时更新至其他用于备份的数据节点,而后的数据读取可在其他的数据备份节点实现。
2.4 构建内存数据库(Memory DB)与磁盘数据库(Disk DB)的混合分区
为避免主机掉电或者系统重启导致数据丢失,可设置读取数据操作在Memory DB 中进行,若在Memory DB 中找不到搜索的数据信息,再去访问Disk DB,执行写入操作时将数据或者内存计算结果直接写入Disk DB 则不会影响Memory DB 的访问速度,Disk DB与Memory DB 的数据定期同步,由此在确保数据完整性与准确性的前提下突破了数据读写速度的瓶颈。传统的分区模式使系统性能无法最大化地发挥,形成了水平扩展行差,对数据存取速度及系统性能可谓是降维打击,为打破这一技术僵局,所有的数据分区都将以Memory DB 和MySQL 关系数据库的组织模式进行分区,从而该混合分区的水平方向形成多个分区,垂直方向则形成二级数据库分区,极大提高了数据访问的效率(如图5所示)。
2.5 构建有向无环图以降低系统开销
在MapReduce 框架中,存储中间计算结果而后根据请求调入相关内容,这种操作会数据大量冗余海量复制、磁盘输入输出以及序列化不必要的开销。可参考弹性分布式数据集(RDD)设计理念构建有向无环图(GDA),以管道化的方式将前一个操作的计算结果转发至下一操作作为下一阶段的计算输入,省去中间计算结果的存储,避免了海量数据复用及存储,极大减少了序列化开销。
2.6 计算本地化
数据节点放置计算代码减少因数据移动导致的资源消耗,同一数据范围设置相匹配的Hadoop 及MongoDB,同一数据节点覆盖相应的数据节点与计算机节点且尽量chunk size 值相同,同集群同节点的部署方式便于实现计算向数据靠拢,数据节点直接计算极大程度上减少了数据中间计算存储转发导致的数据冗余。
3 基于MongoDB与Hadoop 的整合方案
如图6所示,MongoDB 和Hadoop 的整合依赖于10gen 公司发布的中间件产品MongoDB Hadoop Connector,它负责将MongoDB和Hadoop 的整合依赖于10gen 公司发布的中间件产品MongoDB Hadoop Connector,使Hadoop 更全面地发挥其分布式运算的能力。MongoDB Hadoop Connector 进行资源整合,将MongoDB 取代了HDFS,在数据处理中扮演数据源的角色,数据集群在MongoDB中被切割为固定大小的数据块,Mappers 根据数据的不同路由信息解析处理数据,经过解析加工的数据结果通过Reducer 整合至期望的数据状态将计算结果返回至数据源中。
在完整的数据整合流程中,Hadoop HDFS 没有充当任何角色,从而增加了Hadoop 与MongoDB 整合模式的可变性,在一定层面提高数据处理的效率。[3]
由图5可见,Hadoop 与MongoDB 的整合框架由3 部分组成,MongoDB 与Hadoop 的整合可通过配置的方式提供以下四种方案:
(1)于HDFS 读取目标数据经过数据处理解析,将解析结果回写至HDFS。
(2)于HDFS 读取目标数据经过数据处理解析,将解析结果回写至MongoDB。
(3)于MongoDB 读取目标数据经过数据处理解析,将解析结果回写至HDFS。
(4)于MongoDB 读取目标数据经过数据处理解析,将解析结果回写至MongoDB。
4 总结
本文通过项目研究的实践经验,以分片与整合方式为研究视角,探索基于MongoDB 与Hadoop MapReduce 的海量非结构化数据处理方案,以设置合适的分片方式以及chunk size、合理部署MongoDB 分片集群Sharded Cluster、平衡CAP、构建内存数据库(Memory DB)与磁盘数据库(Disk DB)的混合分区、构建有向无环图以降低系统开销、计算本地化等方面进行论述,并对这些改进措施在实践中的应用情况进行详细分析。

图5
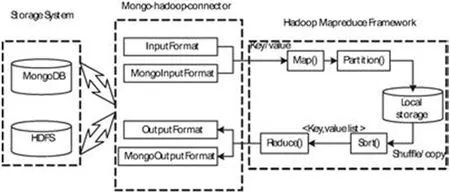
图6
猜你喜欢
词学(2022年1期)2022-10-27
心理学报(2022年4期)2022-04-12
水泵技术(2021年3期)2021-08-14
数学物理学报(2020年5期)2020-11-26
广东通信技术(2020年10期)2020-10-26
火控雷达技术(2018年4期)2019-01-15
铁道通信信号(2018年10期)2018-12-06
中国惯性技术学报(2015年1期)2015-12-19
中国石油企业(2014年4期)2014-11-30
河南科技(2014年24期)2014-02-27
