
融合多信息的个性化推荐模型
2021-04-12 06:48乔少杰元昌安许源平王珏岚
重庆理工大学学报(自然科学) 2021年3期
沈 杰,乔少杰,2,韩 楠,元昌安,许源平,覃 晓,王珏岚
(1.成都信息工程大学,成都 610225;2.软件自动生成与智能服务四川省重点实验室,成都 610225;3.广西教育学院,南宁 530007;4.南宁师范大学,南宁 530299;5.四川省医学科学院·四川省人民医院,电子科技大学附属医院,成都 610072)
随着人工智能、云计算与大数据技术以及移动互联网等先进技术的迅速发展,各种信息数据的规模也呈现爆炸式的增长[1]。在享受这些数据带来的便利的同时,需要处理数据量过大而导致的“信息过载”问题。推荐系统则正是解决“信息过载”问题的有效方法之一,可以根据用户以及项目(item)的相关属性找到用户的兴趣点,并且将用户感兴趣的项目以个性化目录的方式推荐给用户[2]。
目前,基于协同过滤的推荐系统考虑到用户与项目的历史交互,然后根据其潜在特征为用户提出推荐建议,已经取得一些效果[3]。但是基于协同过滤的推荐系统通常会面临用户和商户历史交互数据的稀疏性问题及伴随的冷启动问题。为了解决这些局限性,研究人员将诸如用户/项目属性[4]、社交网络[5]、图像[6]、背景[7]等辅助信息纳入基于协同过滤的推荐系统。
在各种辅助信息中,知识图谱(knowledge graph,KG)由于其具有效率极高的事实描述能力以及可解释项目之间的关联信息,得到研究人员的广泛关注。知识图谱是一种定向异构图,其中节点对应于实体,边对应于关系。研究人员已经提出了诸多知识图谱,例如:NELL、Dbpedia、以及诸如Google Knowledge Graph和Microsoft Satori的商业知识图谱。这些知识图谱已成功应用于多个领域,例如知识图谱填充[8]、人机问答[9]、单词嵌入(word embedding)[10]和文本分类[11]。
深度学习是当前互联网和人工智能的一个研究热点[12]。深度学习主要是通过将低层的属性特征生成高层语义抽象,自动挖掘出数据的分布式特征表示,解决了传统机器学习中需要人工设计特征的问题,在图像识别、机器翻译等诸多领域取得了较大进展。基于深度学习的推荐系统近期得到广泛关注,将与用户和商品项目相关数据作为输入,通过深度学习模型获得具有相应属性特征的用户和项目的隐表示,再基于这类隐表示为用户推荐项目。
本文的研究包括:传统基于协同过滤的推荐算法会由于数据稀疏产生推荐效率低下的问题,可以通过添加辅助信息(如:文本,时空信息)改进这一缺陷;传统基于知识图谱的推荐算法仅着重于结构化知识,然而用户-项目评论等文本知识是普遍存在各类社交网站以及电子商务系统中,其中蕴含着丰富的语义特征信息,考虑从评论的文本知识中获取特征可以极大地提高推荐的准确性。
针对现有推荐算法的不足,本文主要贡献包括:
1)将知识图谱与评论内容作为多源数据,并使用不同算法对数据进行处理,根据用户-项目的历史交互信息,提出了一个动态融合推荐模型,简称为REME(rippleNet and word2vec fusion Model)。
2)在评论文本知识处理上,利用深度学习模型word2vec[13]+FM(factorization machine)[14]算法计算用户-项目相似度,得到一个用户点击预测值。
3)将REME与当前流行推荐算法CKE(collaborative knowledge based embedding)[6],DKN(deep knowledge-aware network)[15]和PMF(probabilistic matrix factorization)[16]算法在真实数据集上进行对比实验,验证所提算法的各方面性能。
1 相关工作
知识图谱在各个领域中得到广泛应用,研究人员尝试利用知识图谱来改进推荐系统的性能。现有基于知识图谱的推荐系统分为以下2类:1)基于嵌入(embedding)的方法[4,15,17]。此类方法使用知识图谱嵌入(knowledge graph embedding,KGE)[18]算法预处理KG,并将学习到的实体嵌入到推荐系统框架中。基于嵌入的方法利用KG辅助推荐系统提升算法的灵活性,但是上述方法采用的KGE算法更适用于链路预测而不是推荐系统[18]。2)基于路径的方法[19-20]。此类方法探索KG中各实体之间的关联模式,作为推荐系统的额外辅助信息。基于路径的方法以更直观的方式使用KG,但是会严重依赖于人工设定的元路径,通用性无法保障,不同的应用场景需要设定不同的元路径。此外,实体和关系不在一个领域内的某些场景(例如新闻推荐)中是无法人工设计元路径的。
文献[21]较早将图嵌入技术应用于推荐领域。将Movielens中电影与用户信息嵌入(embedding)到同一个向量空间,进而计算用户与电影之间的空间距离,生成推荐列表。Wang等[22]将医学知识图谱、疾病&患者二部图、疾病&药物二部图分别嵌入低维向量空间,为病患推荐更为安全的药物治疗方式。通过加权平均将知识图谱与二部图结合生成包含更加细粒度属性信息的患者和药物向量,最终生成对给定患者的药物top-k列表。
Ostuni等[23]融合KG路径中隐含的语义反馈信息,提出基于隐式语义反馈的路径算法SPrank。基于路径特征对数据集进行挖掘,以捕获项目之间的复杂关系。SPrank的主要思想是探索语义图中的路径,以便找到与用户感兴趣项目相关的项目。通过分析路径,提取基于路径的特征,利用随机森林与渐变增强回归树相结合的学习算法来生成推荐结果。
为了解决上述方法的局限性,Wang等[20]提出了一个将KG应用到推荐系统的RippleNet算法,用于网页点击率的预测。RippleNet的基本思想是基于用户偏好的传播,对于每个用户,Ripple-Net将其历史记录作为KG的种子集,沿着KG链路迭代地传播用户的兴趣爱好,进而发现用户对于商户的潜在兴趣等级。RippleNet结合了上述2种方法的优点:1)基于偏好传播将KGE应用到推荐系统中;2)可以自动发现用户历史记录的商户到候选商户的可能路径,而无需任何人工操作。
本文提出的基于深度学习的推荐系统如图1所示,包含输入层,模型层以及输出层。输入层的数据和传统的推荐系统相似,主要是用户的显式反馈以及隐式反馈数据,以及用户画像和项目内容。深度学习层使用深度学习算法模型,如:自编码器AE[24]、受限玻尔兹曼机RBM[25]、卷积神经网络CNN[26-28]、循环神经网络RNN[29]等。最后,在输出层利用学习到的相应隐表示,通过内积、softmax、相似度计算等方法为用户提供推荐。

图1 基于深度学习的推荐系统框图
深度学习被广泛应用于推荐系统中,结合传统推荐系统,将基于深度学习推荐算法分为:1)深度学习结合协同过滤的推荐系统。获取并使用用户和项目的交互数据,通过使用深度学习方法学习得到用户和项目的隐向量,预测用户对于目标项目的评分或感兴趣程度等信息。2)深度学习结合基于内容的推荐系统。获取并使用用户画像、用户的显式以及隐式反馈数据、项目内容数据以及相应的用户生成内容,通过使用深度学习方法学习用户和项目的隐向量,为用户提供精准推荐。
当前大多数社交媒体网站和电子商务系统允许用户发表文本评论。文本蕴含着丰富的信息,可以找到用户潜在的兴趣点,将其应用于推荐系统可以提高推荐系统的准确性。基于深度学习的word2vec模型不仅应用在自然语言任务,而且被应用于推荐系统和广告推荐上。Word2vec[13]是基于Skip-gram或CBOW(continuous bag-of-words)的词嵌入模型。在没有词性标注的情况下,word2vec能够从原始语料学习到单词的向量表示,比较单词间的语义、句法的相似性。本文利用word2vec对文本进行处理,将一个用户对所有商户的评论合成代表用户信息的文本数据,同理,将一个商户接受到的所有用户的评论集成为商户的文本数据,提取出用户和项目的文本潜在特征,根据其特征进行匹配,最终进行合理推荐。
RippleNet算法仅使用了用户的历史点击记录与结构化知识构成的知识图谱,没有考虑蕴含丰富知识的用户和项目评论数据,基于这一考虑,本文所提算法利用word2vec提取出用户以及商户的隐特征,通过Factorization Machine(FM)[14]算法处理隐特征,进而计算得到用户点击概率值。通过加入一个动态参数,将RippleNet算法所得值与word2vec+FM所得值结合,最终获得点击率预测数值。本文所提REME模型在真实数据集上进行大量实验,实验结果表明融合多算法的REME推荐框架相比现有推荐算法,具有更高的推荐准确性。
2 REME推荐框架
本节分别介绍RippleNet模型、word2vec和FM的算法原理,进而给出一种动态结合上述算法(即RippleNet模型结合word2vec+FM)的优势,生成本文提出的REME模型,利用随机梯度下降算法进行模型求解。REME模型框架如图2所示。

图2 REME模型
如图2所示,REME算法首先通过数据库中所有用户-商户评论的信息,基于用户和商户形成2个文件,通过word2vec算法分别对2个文件进行向量化处理,以此向量作为FM算法的输入;在已有用户点击历史的情况下,与知识图谱相结合(在知识图谱上搜寻出与用户对应的商户)作为RippleNet算法的输入;通过计算得到FM算法与RippleNet算法的输出后,利用2.3节动态融合方法将2个输出进行有效结合,获得了一个预测分数,基于预测分数进而为用户提供个性化推荐列表。
2.1 RippleNet
本节将介绍REME的第一步关键操作Ripple-Net算法,其主要思想为:通过用户的历史点击项目信息,找出在知识图谱上与其相连的项目,进而获得用户的潜在兴趣传播方式。下面对于算法进行形式化描述。
假设U={u1,u2,…,un}和V={v1,v2,…,vn}分别表示用户集与项目集,m表示用户数量,n表示项目数量。用户/项目交互矩阵定义为Yuv={yuv|u∈U,v∈V},其中yuv的值为1和0,当取值为1时,表示用户u和项目v存在历史交互,即用户u曾经点击观看过项目v。
除了用户-项目交互矩阵外,包括大量关系-实体三元组(h,r,t)的知识图谱G。其中h∈E,r∈R,t∈E,分别代表着头实体、关系、与尾实体。E和R分别代表着知识图谱G中的实体集合和关系集合。在实际推荐情景中,一个项目v可能和知识图谱中的其他多数实体相连。
RippleNet的目标是在已有交互矩阵Y和知识图谱G的情况下,得到用户u和待定项目v的点击预测评分。即将用户u和项目v作为输入,输出用户u会点击项目v的概率。
首先给出算法中的主要概念,形式描述如下。
定义1(关联实体)已有交互矩阵Y和知识图谱G,用户u的第k个关联实体定义为:
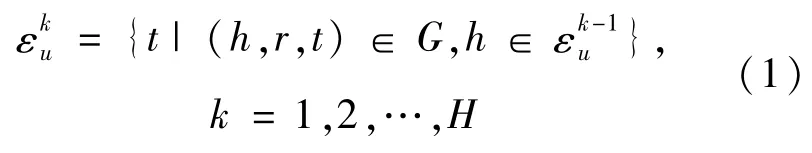
基于定义1给出波纹集的定义。用户u在G上的第k跳(k-hop)波纹集,其关联三元组定义如下。
定义2(波纹集)波纹集形式定义为:

“波纹”的含义包括:
1)将用户的历史点击视为一个个水滴,滴在知识图谱水面上形成了很多波纹,波纹的传播可以用于表示用户的潜在兴趣传播路径。
2)用户的潜在兴趣程度随着k的增大而变小,即传播距离越远,与初始项目的相似性越小。
“波纹集”如图3所示。图3中三角形代表的是用户最初点击的“种子集”,方块代表的是与种子集直接相连的第一跳波纹集(Hop1),实心圆则代表的第二跳波纹集(Hop2),第h跳波纹集皆以此类推。
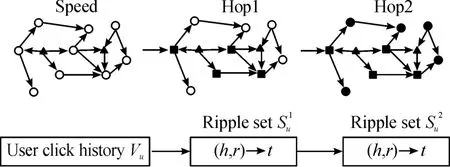
图3 波纹集
对于每个项目v对应创建一个d维的嵌入向量v。项目嵌入向量通常是基于one-hot ID[30],分布、词袋等特征信息表示的一个项目。在已有用户u的Hop1波纹集与项目嵌入向量v的条件下,的每一个三元组(hi,ri,ti)与v的相关系数为:

式(3)中:Ri表示关系ri的嵌入,是一个d×d的矩阵;hi表示头实体hi的嵌入,是一个d维的向量;相关系数pi表示项目v与头实体hi在关系Ri上的相似程度。在获得相关系数pi后,对于的尾实体ti计算加权和得到向量为:
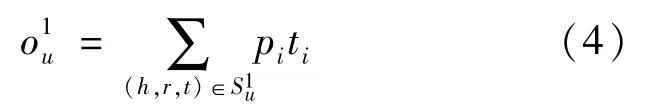
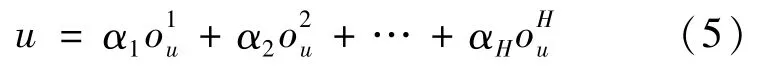
式(5)中,αi是正项(αi>0)可训练混合参数,且其和为1。
基于上述公式,基于u和v输出预测点击概率为:

根据式(6)得到损失函数为:
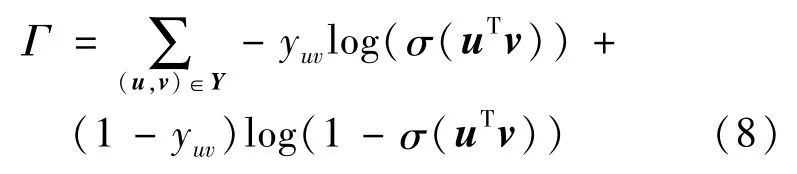
式(8)中,yuv更表示用户u与项目v的交互历史,值为1和0,当取值为1时,表示用户u和项目v存在历史交互,即用户u曾经点击并观看过项目v。式(8)定义的损失函数用于训练和调节参数。
为了得到更好的实验效果,在损失函数中加入了L2正则化参数(限于篇幅,省略这部分内容),参数的相关设置会在实验部分进行说明。
2.2 Word2vec+FM模型
本节将对word2vec与FM算法进行描述,下面将介绍其主要思想及理论基础。
Word2vec可以视为一个神经网络,其主要作用为将自然语言中的每个词通过一个三层神经网络训练成为一个词向量。其很好地解决了传统词袋模型 (bag-of-words,BOW)无法表示文本上下文语义信息以及造成的维数灾难的问题,使得语义上相似的词具有相似的向量表示。Word2vec主要包括2种预测模型:skip-gram和CBOW(continuous bag-of-word model)以及2种训练模型Hierachical softmax(huffman树,HS)和negtive sampling(权重采样负例,NS)。其常用的组合分为4种:CBOW-HS、CBOW-NS、Skip-Gram-NS、Skip-Gram-NS。
本文主要目标是使用word2vec分别获得用户以及项目的特征词向量,基于特征词向量使用FM模型获得用户与商户的相似度(预测评分)。
CBOW与skip-gram的结构如图4所示。本文使用的是CBOW-HS模型,且CBOW与skip-gram模型相似,因此这里仅介绍CBOW模型。CBOW是根据已知的上下文单词来预测中心词的后验概率,模型结构如下:1)输入层,上下文词向量context(w);2)投影层,将输入层的2c个context(w)词向量相加;3)输出层,输出中间词向量。
CBOW的训练函数为:
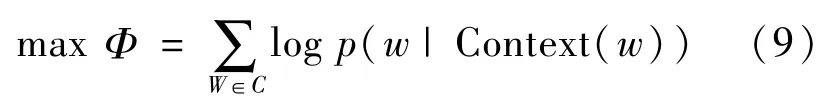
下面对FM算法进行介绍,首先给出使用FM算法的理由如下:1)特征组合是机器学习建模过程中遇到的问题,如果对特征直接建模,很可能忽略特征与特征之间的关联信息,因此可以通过构建新的交叉特征组合方式提高模型的效果。2)高维的稀疏矩阵是真实应用中常见的问题,直接应用会导致计算量过大、特征权值更新缓慢的问题。

图4 连续词袋模型与Skip-gram模型
首先介绍FM算法的输入:基于Word2vec构建出用户与商户的特征向量,公式如下:

式(10)(11)中:Tu、Tv分别表示用户u与商户v的评论;tu与tv为相对应的用户和商户特征向量。

式(12)中:·表示向量点乘操作;zuv是u与v之间的相关系数向量。
笔者经过大量实验发现:通过FM算法将特征两两组合,引入交叉项特征,可以提高模型的准确性,FM应用的主要公式为:
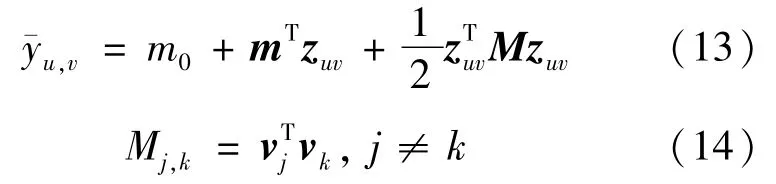
式(13)、(14)中:m0表示全局偏差项;m是潜在特征向量zu,v的系数向量;M是二阶交互的权重矩阵,其对角元素为0;vj、vk是与zu,v的维度j和k相关的v维隐向量。
最后,使用平方损失作为参数优化的目标函数,定义为:
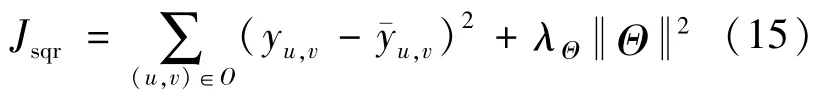
式(15)中:O表示观察到的用户-项目评分对集合;yu,v与式(8)中的yuv的含义相同,都是用户-项目交互;Θ表示的是所有参数。其中,式(15)中的第二项是为了防止模型过拟合。
2.3 动态融合方法
本节介绍如何将前面所述的RippleNet和word2vec+FM进行动态融合,使2个算法可以起到相互促进的作用。因为融合方法中参数可以自动调节,所以本文所提出的融合算法成为动态融合算法。
上述RippleNet算法、word2vec+FM算法分别从评分和文本2个不同的信息源获得隐特征。为了使这2个隐特征的整合可以相互补充并产生更好的预测结果,加入了一个线性插值α,参数α主要用于有效结合2个组件。然而,将这2个模型与静态α线性融合可能不是评级预测的合适选择,因此这里加入的是动态参数α,其动态变化方式主要为当基于评论的组件预测的分数高于基于交互的组件时,参数α变大。
当用户给予某个项目高分评价时,可能会是由于某些特定的偏好特征,而此项目其他特征对于用户选择的影响则可忽略。因此这里引入了一种动态加权方案,主要方式为通过优先选择具有更高预测评分的组件(即来自评论的知识或结构化知识)来搜寻更符合用户个人喜好特征的项目[31-33]。
在式(6)和式(10)的基础上得到:

2.4 REME参数优化
本节介绍模型REME的参数优化方法,主要是采用随机梯度下降与反向传播的方法对式(8)(9)(15)的参数进行优化。REME算法如下所述。
算法1REME模型参数优化。


算法1首先为每一个用户统计出其波纹集与这个用户的所有评论的集合,使用word2vec算法将评论集合文件转化为对应的用户特征向量(第2~4行)。在预设好的迭代次数T内,基于式(1)~式(8)使用随机梯度下降算法与反向传播算法更新参数{αi,i=1,2,….,H}(第5~6行)。利用计算用户特征向量相同的操作,为每一个项目计算出对应的项目特征向量(第7~9行)。在计算出所有用户-项目特征向量后,遍历出测试集的用户-商户对,计算出用户-项目相关系数向量zuv(第10~11行),并在基于FM算法使用随机梯度下降算法与反向传播算法更新参数Θ(第12~13行)。最终输出参数{αi,i=1,2,….,H}与 Θ。
2.5 算法时间复杂性分析
为了说明REME算法在提高算法准确性的同时,仍具有着较好的时间性能,本节将分析REME算法的时间复杂性,并与其他经典算法的时间复杂性做对比。
首先创建用户特征向量:计算用户波纹集的时间复杂度为O(a×m),其中m为用户数量,a是一个常数;word2vec算法的时间复杂度为O(a log(n)),n为项目数量。综合上述步骤,创建用户特征向量的时间复杂度为O(a(m+log(n))),因为n的值远大于m,所以近似为O(log(n))。与创建用户特征向量相似,创建项目特征向量的时间复杂度为O(log(n))。计算用户特征与项目特征的交叉向量的时间复杂度为O(log2(n)),综上,REME的算法时间复杂度为OREME(log2(n))。
PMF,DKN与CKE算法的时间复杂度分别近似为OPMF(mn),ODKN(m2+n2)和OCKE(log2(n))。REME算法的时间复杂度与上述算法相比,ODKN(m2+n2)>OREME(log2(n))≈OCKE(log2(n))>OPMF(mn)。以此可以发现,REME算法在提升推荐能力的同时,所牺牲的时间效率在可接受范围之内,且其时间复杂性优于DKN算法,略逊色于PMF算法。
3 实验及算法性能分析
3.1 数据集描述
在实验中使用通用的Yelp数据集进行推荐性能分析。本文抽取Yelp数据集中亚利桑那州(AZ)与南卡洛来纳州(SC)2个不同地区的餐馆数据,包含用户的评论数据以及商家的属性数据集。在用户的评论数据中主要包含用户的评论,评分等信息。在实验中将用户评论视为签到一次。在商家的属性数据集中主要包含了商家的ID,名称,位置(地区、城市、经纬度等),餐馆种类以及标签等信息。实验利用Microsoft Satori来为Yelp商户建立知识图谱。
对于筛选完后的2个地区的数据集,其统计信息如表1所示。
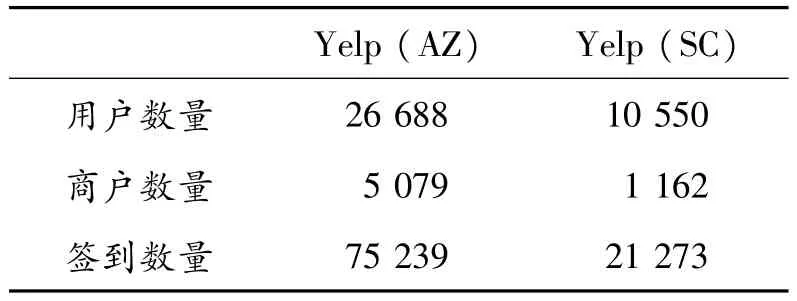
表1 数据集的各项统计信息
从表1中可以发现,AZ的用户数量是SC的2倍左右,然而商户数量是SC的5倍,因此带来了数据稀疏性的不同,从而导致最终的实验结果有着一定的差异。
3.2 实验参数设置
在Ripplenet中,将其波纹跳数即式(4)中的H设置为2,根据实验结果证明大量的波纹跳数不会提高性能,相反会增加额外的计算开销。
实验完整的参数设置为:商户和知识图谱的嵌入维度d=16,学习率 η=0.02,正则化参数λ1=10-7,λ2=0.01,H=2。
对于word2vec,设置其所得嵌入向量维度为也为d。通过验证数据集上的AUC曲线来确定超参数。
为了取得更好的实验结果,对于每个数据集进行训练,训练、评估、测试集的比例为6∶2∶2。每个实验重复5次,取其平均值作为最终数据。
本文采用如下2个评价指标,评价算法的性能:
1)对于点击率(CTR)预测,本文使用ACC(accuracy)与AUC来评估CTR预测的性能。
2)对于top-k推荐,本文采用的是recall@k作为评价指标,recall@k的定义如公式:

式(18)中:recall@k表示的是在top-k推荐列表中的召回率,即用户在推荐列表中点击的概率;hit表示的是测试集中的用户点击推荐列表中的餐馆的次数;recall代表测试集的签到总次数。
在本文中主要对比如下3个经典推荐算法:
1)CKE[6]:CKE主要将协同过滤与结构知识,文本知识和图像知识结合在一个统一的框架中进行推荐。
2)DKN[13]:DKN将实体嵌入和字嵌入视为多个通道,并将它们组合在CNN中以进行CTR预测。实验中使用商户标签作为DKN的文本输入。
3)PMF[24]:PMF主要是利用了用户的签到信息,将“用户-兴趣点”的签到矩阵分解为用户隐式因子矩阵和兴趣点隐式因子矩阵,利用这些隐式因子矩阵预测用户对于兴趣点的评分,进而为用户生成推荐列表。
3.3 算法性能对比分析
不同算法的top-k推荐与CTR预测的结果如图5、图6以及表2所示。实验结果表明:
1)在不同数据集上,SC的实验效果总是比AZ的好,这是因为2个地区的数据稀疏度有着差异,AZ的每个商户的平均流量比SC的更少。
2)CKE在这里只使用了结构化知识,因此其效果相比RippleNet来说较差。RippleNet与其他模型相比结果较好,但是其仅考虑了知识图谱,没有有效利用评论文本信息等数据,因此推荐效果没有REME好。DKN的实验结果并不好,因为这里仅使用了标签信息,没有考虑其他的有效信息。
3)无论在哪个数据集中PMF的推荐效果总是最差的,因为用户的签到数据是稀疏的。此外,PMF算法没有融合其他的内容数据信息。
4)如图5,图6及表2所示,REME都取得了最好的推荐效果,其分别在AZ和SC2个数据集AUC上相比于其他基线提升了7.8%~19.3%和4.9%~20%,同时在recall@k的测试中也取得了最佳效果。以此可以说明REME推荐能力优于仅使用结构化知识的CKE与RippleNet,更优于未使用知识数据的PMF算法。这意味着额外使用文本知识可以提高推荐性能,并说明了REME框架将不同的知识组合在一起以增强推荐性能。
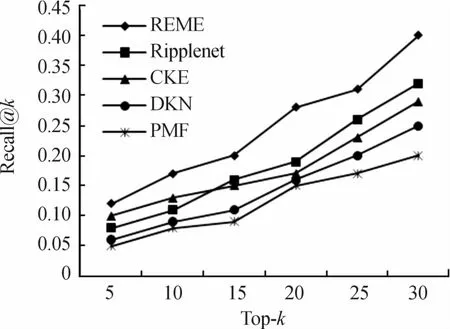
图5 南卡洛来纳州不同模型的召回率对比

图6 亚利桑那州不同模型的召回率对比
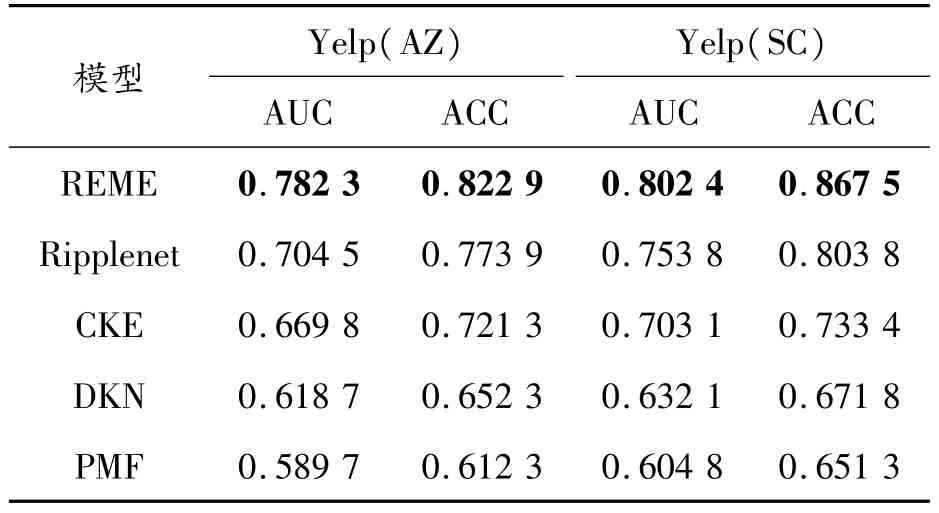
表2 点击率预测中AUC与Accuracy结果
综上,REME模型相比于现有典型模型,在有效融合多种数据的情况下,明显提升了推荐效果,且在数据稀疏的情况下可以得到不错的推荐效果,表明REME模型可以有效解决数据稀疏对于推荐结果所带来的负面影响。

表3 各模型的运行时间 min
实验结果如表3所示,在实际应用中,推荐模型的运行时间往往是重要的评价指标之一,如果模型的运行时间超过了可接受范围,那么这个模型的实用性就会受到限制。因此该实验主要在2个不同数据量的数据集中进行效率评估实验。由表3可以看出,在提升了推荐能力的同时,随着数据量的增大,REME算法的运行时间也是呈现稳定增长的趋势,这说明REME算法其所增长的时间是在可接受范围内。
REME算法分为2个组件,其中基于Ripple-Net算法的组件是以知识图谱为输入数据,不需人工专门设计元路径,可以适用于各类行业;另外一个基于Word2vec算法的组件主要是以用户评论为输入,目前用户-项目评论数据普遍存在于各类社交网站以及电子商务系统中。可以看出,REME算法的输入数据是可以直接获取到的,获取难度低,应用场景众多。基于之前所做的效率评估实验,可以看到REME算法在随着数据增大的同时,其时间开销的增长是在可接受范围之内的。综上所述,REME算法在实际应用中,提升了推荐能力的同时,其实现成本是相对较低及可行的。
4 结论
在推荐系统领域,知识图谱与深度学习结合近年来成为研究热点,本文通过运用2种不同的算法分别对于结构化知识以及文本信息进行动态融合(即RippleNet和word2vec+FM算法),提出了一种新的融合推荐模型REME。在真实数据集上对不同模型进行实验,结果表明本文所提出的算法相比于已有算法有着更好的效果。在数据稀疏性不同的实验数据集上的实验结果表明:本文所提模型可以有效缓解数据稀疏性对推荐算法带来的负面影响。
猜你喜欢
北京航空航天大学学报(2021年6期)2021-07-20
少先队活动(2020年12期)2021-01-14
金融周刊(2018年13期)2018-12-26
四川党的建设(2018年21期)2018-12-05
中成药(2017年3期)2017-05-17
学与玩(2017年5期)2017-02-16
时代金融(2016年19期)2016-09-10
领导科学论坛(2016年9期)2016-06-05
杂草学报(2012年1期)2012-11-06
中国经贸(2010年16期)2010-10-25
