
DSP处理器上的高效串匹配实现
2021-04-12 09:50:54顾乃杰林传文
小型微型计算机系统 2021年4期
叶 鸿,顾乃杰,林传文
1(中国科学技术大学 计算机科学与技术学院,合肥230027) 2(合肥学院 计算机科学与技术系,合肥230601)
1 引 言
串匹配,是一种在已给定的字符、符号序列(文本串)中查找某一特定字符、符号序列(模式串)所有出现情况的算法.它广泛应用于语音分析与识别,信息检索,生物检测等方向,是计算机领域研究的基础问题之一[1].随着移动互联与计算生物学的高速发展,信息查找、入侵检测、基因检索等涉及串匹配问题的应用对移动便携和功耗的要求越来越高,单一PC平台已经很难满足不同应用场景对性能的专业需求,移动化及手持小型化设备受到越来越多的关注[2].如何针对这些设备选取合适的处理芯片,并高效的实现串匹配算法,是当下研究的重点[3,4].
DSP处理器,兼具低功耗、高性能、易编程等特点,在信号及图像处理领域有着的天然优势,也因此在移动设备及小型设备处理中受到越来越多的关注.高性能 DSP 处理器不仅拥有强大的计算能力,还支持单指令多数据流(SIMD)、超长指令字(VLIW)等硬件技术,这使得串匹配并行化在DSP处理器上有着广阔的研究空间和使用价值.将复杂算法应用于DSP处理器并与通用处理器协同工作进行特征提取,当复杂的算法在DSP处理器上运行时,通用处理器可以专注于图像采集、用户界面和外围控制,这为移动设备的性能保证和场景推广提供了无限可能,在生物识别、移动检测等领域,有着重要的意义[5].
与此同时,在串匹配领域有很多优秀的算法可以进行高效匹配工作,算法逻辑思路也各不相同,但不可避免都会涉及大量不确定的判断与跳转.而基于哈弗体系架构的DSP处理器,非常擅长数据密集的高性能运算.但频繁的判断跳转,会带来流水线的停滞,预取指令槽的反复装入与排空,这会显著影响DSP处理器的运算效率.如何合理规避跳转,发挥处理器的运算能力,是实现高效串匹配算法的关键问题[6-8].
针对上述问题,该文提出了一种基于DSP处理器的改高效串匹配算法.这一算法采用位并行的思路,同时通过多种优化手段,提高该算法对于DSP平台的适应性与执行效率,最终实现了一种针对HXDSP的高效串匹配算法VBNDM2(VectorizationBackward Nondeterministic Dawg Matching in 2-Grams).
2 背景介绍
串匹配算法在信息检索和信息分析相关的众多领域都有着众多应用.自1970年S.S.Cook从理论上证明单模式匹配问题可以在O(m+n)时间内解决以来,科学界已提出120种以上的字符串匹配算法[9].其中有50多种是在近10年内提出的,但真正实用且被广泛应用于各实践场景的寥寥.这是因为基于串匹配问题的研究存在着理论与实践间脱节的问题.目前,针对串匹配问题的研究主要分为两个方向,一是改进现有算法以适应目前超大数据量及高速网络环境;另一个是将现有算法应用到不同硬件环境上,并针对特定硬件结构特点来优化提高串匹配效率[10,11].
2.1 串匹配算法分析
由于各种模式的匹配算法都是由单模式串匹配算法拓展而来,单模式匹配是文本、符号处理等领域研究应用的基本组件.而为了获得针对单模式串匹配的确切匹配位置,精确单模式匹配也因此成为串匹配问题的核心和基础.所谓精确单模式匹配(Exact single pattern string matching),指的是对于给定字符集Σ(|Σ|=σ),Σ*为字符集Σ的一个Kleene闭包(下文简称闭包),给定文本串T=t0t1…tn-1和模式串P=p0p1…pn-1,其中T,P∈Σ*.从而求解集合:O={pos|P[j]=T[pos+j],for∀0≤j 传统串匹配算法中的单模式匹配,依照其搜索方式的特点可分为:前缀搜索方式、后缀搜索方式和子串搜索方式.前缀搜索方式的主要代表算法主要为KMP[12]算法、Shift-And算法和Shift-Or算法[13]等.前缀搜索的特点是采用自前向后的顺序判断模式与匹配串的对比情况,然后凭借已匹配成功的数据计算后续可后移的最大位数.而后缀搜索方式算法主要有BM算法[14]、Horspool算法[15]和Sunday算法[16]等.后缀搜索方式算法的思路与前缀相反,它在检索时采用从后向前的方式,首先从文本串的最后字符开始检索.基于后缀方式算法的优势在于检索匹配失败后可以获得一个较大的跳跃位数.最后,子串搜索则是基于自动机的执行方式,它的代表算法有BDM算法[17]、BNDM[18]算法和BOM算法和它的延伸算法等. 在充分利用设备存储器的字长且兼顾操作的内在并行性的条件下,基于位并行的串匹配算法是目前速度最快、效率最高的串匹配算法.但与此同时,基于位并行算法的效率也会受到实际串长度的限制.若模式串的实际长度不大于平台的机器字长时,可执行高效位并行匹配;反之,若模式串长度大于甚至远大于机器实际字长时,算法中字符拼接产生的损耗则会显著降低位并行算法的效率[19]. 位并行算法,指的是将多个值打包,存放在一个指定计算机字长空间中,并在每次匹配操作后自动更新所有比对值的技术.这一算法旨在将多个匹配值贮存在计算机的单字空间里,形成检索表.并采用简单的运算操作(例如位操作)更新和持续维护它们,如与操作(AND)、或操作(OR)和加法操作(ADD).而在实际过程中,最普遍的方法是对给定的模式串和匹配串生成一个二维数组用以暂存字符串中所有字符中的匹配与不匹配信息. 位并行算法可以将判断和处理压缩在位运算部分而减少判断,因此也更适合DSP处理器使用.常见的位并行串匹配算法有Shift-Or、Shift-And、BNDM等.其中,BNDM算法相对于Shift-Or、Shift-And算法有着较少的判断跳转和更好的平台适应性.基于BNDM算法,又有SBNDM、BNDM2等延伸算法[20]. BDM(Backward DAWG Matching)算法[17],是一种最早的子串跳跃型的串匹配算法.它主要基于后缀自动机的特点检索并识别所包含的所有子串.这一算法采用Trie有根树来执行有限状态自动机,自右向左倒序检索匹配窗,进而识别出匹配串中能够于子串部分相匹配的最长相同字符序列n.而当时间序列长度|n|大于等于实际窗口长度m时,执行判定匹配串与检索当前位置是否相同,相同则反回实际检索位置;若不同则代表着检索序列部分匹配,则匹配指针右移m-n个字符,继续执行匹配算.虽然BDM算法的理论最坏时间复杂度为O(mn),但它是第一个实现平均时间复杂度O(nlogσ(n/m))的算法,这对后续的检索算法的发展,有着重要的理论研究意义. BNDM算法[18]也是一种可以达到O(nlogσ(n/m))平均时间复杂度的算法,它的本质是BDM算法的位并行实现,且曾经是世界上效率最高,也最有实际应用价值的串匹配算法之一.时至今日,BNDM算法已成为一类专门的串模式匹配算法,在嵌入式串匹配领域有着重要的影响力.这一算法的理论基础是位并行的实现了一种不确定因子自动机的仿真过程,它模拟了一个不确定因子自动机所有前缀的识别过程.算法首先的预处理阶段构建了一个向量表B,这一形式类似于Shift-And算法的数据表,并通过在文本上滑动长为m的检索窗为来实现实际检索逻辑.其实际执行过程中会先对齐检索窗,并采用向后检索的方式扫描窗口同时相应更新自动配置.而当算法检索到一个P的后缀(即P的前缀)并设置D和B[C]的第m位时,算法记录实际窗口位置.而当D变为零(即找不到P的进一步前缀)或算法执行了m次迭代(即找到匹配)后,尝试结束并移动窗口至可识别的、最长适当前缀的起始位置.BNDM算法的空间和时间复杂度分别为O(δ「m/w⎤)与O(「m2/w⎤). 基于串匹配的算法研究,首要任务即是处理串匹配的等概率模型.等概率模型问题,是指针对确定的模式串和文本串,各字符元素出现的概率互相独立,并且各自相同的体系模型.自上世纪70年代姚期智证明在等概率模型的条件下,精确单模式字符串匹配的最差、最优以及最优平均时间复杂度分别为O(n)、O(n/m)、O(nlogσ(n/m))以来,各时间复杂度已被相应算法证实[21].然而在实际应用场景中,文本串与模式串普遍会满足某些特定的概率分布,这使得实际匹配算法只能接近而很难达到最优或最差的时间复杂度.因此,当样本数据量足够大、模式串足够长的时候,平均时间复杂度对串匹配的最终性能影响最大[22].而提高串匹配的方法,主要有结合硬件结构、减少循环次数、缩短循环体、提高跳跃距离等. 与通用PC处理器相比,基于SIMD和VLIW架构的DSP平台有着更低的功耗和更高专业运算效率的特点.SIMD架构的分簇特点,可以通过一条指令使相同算法在多个分簇运算单元(FU)上同时运算.但不同于单纯的线程并行,SIMD架构需要在不同FU上同一时刻进行相同的操作,这也因此对并行运算的判断流程提出更高要求.对于特定情形如并行执行时部分分簇需要进行跳转,而剩余部分不需跳转的问题,需要详尽、严密的判定逻辑.与此同时,DSP处理器的VLIW架构,可将多条指令整合在同一发射槽中同步执行.这使得DSP处理器对于算法中部分指令执行顺序并非那么敏感,甚至可采用部分以空间换时间的策略,额外增加同一指令发射槽中的指令数量,以解决部分逻辑跳转问题.最后,对在处理器执行过程中,数据在完成访存写入后再次读出,需要间隔相应的时钟周期.因此,为保证流水线执行更加高效,适当进行循环展开与指令改写,对算法效率提升有很大帮助. DSP处理器普遍采用哈佛架构(Harvard),它的主要特点是数据和程序段存储在不同的空间中,可以分别独立编码和寻址.这使得DSP处理器有着高效的访存模式,但在逻辑判断方面,并不具有优势.HXDSP平台包含两组分支预测流水线,但因为串匹配算法匹配跳转执行步长普遍较短,往往难以满足分支预取的指令执行需求.因此若预测成功,顺序执行效率较高;若预测分支失败,处理器则需排空流水线,重新预取、并载入未来所执行的指令.由于这一指令流转的过程会产生大量的额外时钟开销,为减少分支跳转中排空流水线过程所产生的时钟开销,应当尽量减少分支跳转的频度.而在当代高效串匹配算法的实现中,可采用Q-grams的思想来解决上述问题.即采用同时读入多个字符的形式,将这些字符作为整体进行检索和匹配.通过整体查找的方式,降低查找频次,提高准确度,从而提高效率. 最早提出将多个字符同时读入字符串的人是K.Fredriksson[23],他发现在实际模式匹配如英文语料、基因查询等检索过程中,实际匹配成功的概率远小于产生非匹配状态并跳转的概率.因此,Q-grams结构的核心思想即是更快地迭代搜索过程,继续提高非匹配的概率,并跳过它. Q-grams策略在检索匹配状态时,不同于传统串匹配的逐字比较,它可以同时读入连续的q个字符.基于这一策略,当进行中的匹配当前位置没有Q个字符连续组合时,会立即跳过,这使得指令流更加简单,检索更加快捷,看似为跳转增加了负担.但也因为实际循环体因此被尽可能的缩短,算法因此可以更高效地推进及跳跃(这一跳跃距离通常为m-q+1).其实际匹配结构为: B[ti]&(B[ti+1]<<1)& …&(B[ti+q-1]<<(q-1)) 不同于BNDM算法采用Last变量来存储和标记找到的前缀位置,Q-grams策略采用变量i(一般指向Pm-q+1的位置)来直接更新跳转位置,这令循环更加简洁同时也使得算法更加高效. 与此同时,单纯的Q-grams策略同样存在不足,由于q-grams没有采用变量存储最后一个所找到的前缀,而是通过变量i指向Pm-q+1的计数器位置的方式直接更新结构.其实际策略即将普通单字节的字符集,组合成连续多字节的大规模字符集.故基于Q-grams策略的算法相对于传统单字结构占用更多的存储空间,这同时会带来Cache命中问题.此外,不同平台系统对于Q-grams策略串匹配算法的硬件支持程度的不同,也决定了q值本身并非越大越好,连续的读取会涉及数据对齐问题.Kalsi等人的测试表明[24],相对于对齐读取,未经对齐的内存读取在x86平台上的速度损失可以达到70%.而大量数据因读取的未对齐,其本身连续访问或跳转执行效率也受到严重影响,这对大q值Q-grams算法的执行也产生了制约.而在传统DSP平台上,硬件大多支持双字读写,并为双字处理提供了大量灵活指令与操作,这使得DSP处理器上两个相邻寄存器的数据既可以组成一个数组进行共同运算,也可以灵活地单独运算.这一结构为2-grams策略提供了稳定而高效的硬件支持. 以数理逻辑的角度分析串匹配算法,为提高其性能效率,势必要缩短循环体,减少循环次数,增大跳跃距离.而基于缩短循环体的角度提高检索效率,则可对模式匹配的检索首部进行处理.其代表性算法如Shift-Or或BNDM等基于位并行的算法,它们通过构建辅助向量表B,利用比特位掩码序列D去进行匹配运算,检索不匹配则立即跳转. 这一策略体现在实际算法执行过程中时,首先考虑将比特位掩码序列D起始置零,并按照既定规则,移位并进行逻辑操作.假设即将进行的匹配模式串最后一位T[pos]=M,由于该掩码序列初始值为全0,进行第一次移位操作读入的模式串字符后,掩码序列D=B[M].在这一操作过程中,算法需在循环体末将掩码序列D置零,并在下一次循环首部与模式串序列进行逻辑运算.这样的操作显然存在冗余和重复,可二者合一缩小循环体.同时,如果将这一整合操作提前至循环首部,并作为单独循环,若检索前端便匹配失败,即可快速进行跳转跃迁,以提高检索速度. 上述优化策略的核心思想是跳过检测中的最长前缀部分,将循环更多地压缩在前序过程中,使得内层算法变得更加简洁.因此这一策略虽然增加了循环数量,但实际减少了平均移动长度,可带来实际执行过程中的算法性能提升. 基于VLIW与SIMD的DSP处理器,相对于传统的PC平台,其指令跳转与分支预测是处理器的弱项.尤其是在基于并行处理的串匹配应用过程中,由于指令并行并非线程并行,对于不同的分簇及运算单元,在同一指令下,必须完成同样的工作. 但在实际应用场景中,串匹配的过程是不确定的,并行执行的判断过程,跳转也有先后.这就导致了在分支跳转的过程中,往往会出现部分分簇需要跳转,而部分分簇又顺序执行的情况.由于DSP的硬件架构无法处理这样的跳转问题,流水线也会因此紊乱.这一问题,是限制DSP处理器的串匹配算法高效执行的最重要问题之一. 在并行执行串匹配算法时,实际上同一指令发射槽,需要执行的指令数较少.此时可选择横向并行再执行一组甚至多组串匹配算法,但在这一环境下,判断跳转变得更加复杂.进行代码级的跳转分类,无疑增加了算法的复杂性,且无法带来实际意义的性能提升. 另一种思路是,将判断比较等算法通过逻辑与、或的方式融入流水线执行过程中.并采用扩大、复杂算法的方式,以类似“空间换时间”的策略,将部分跳转取代为逻辑、数学运算.考虑到超长指令字架构下同一指令发射的指令槽使用较为空闲,这一思路,有较强的可执行性. 在通用的BNDM算法[18]中的while循环体内,包含另一while循环体.可以看出,串匹配算法在代码执行时由于大量循环、判断、跳转,会长期处于流水线预取装载的过程中,而对运算部件的需求量较小.DSP芯片庞大且高效的数学运算部件,在大多数时间都是闲置的.对于DSP芯片的分支预取结构,在完成代码执行后,流水线会分别装入跳转与顺序执行两种情况的未来指令.而执行完循环后,又需要重新进行流水线的排空和装入,造成流水线的停滞,从而降低检索速度. 如算法1所示,改写后的算法将外层循环提出、展开后并入内层循环,可将双层循环算法整合成一个单循环算法.从传统算法优化的角度,外层循环的部分代码额外执行了很多次,对于算法性能提升是起反作用的.但在基于VLIW结构的HXDSP上,图中所有额外操作,可以并行在指令行的其他发射槽中执行,并未增加额外时钟开销.如LAST&&True,(m-j) &&True等操作,可以在循环体内提前计算与准备,最终更新其参数值时,依然只需要一个时钟周期的运算. 通过VLIW结构将逻辑判断转为数学运算,这是一种利用空间换时间的算法优化思路.将判断跳转用额外的数学运算代替,可以减少指令的分支预取与跳转可能.对于串匹配算法这种不适合多路并行,指令发射槽和运算部件使用率较低的算法应用,有着显著的性能提升效果. 该文算法的具体实现平台为HXDSP处理器.HXDSP是国内某研究所研制的第2代高性能超长指令字(VLIW)DSP芯片,其结构如图1所示.它是一款32位静态超标量处理器,内部集成2个新一代处理器核eC104+,工作主频为 800MHz~1GHz.采用16纳米工艺,16 发射、SIMD架构,通信带宽为252Gbps,存储容量105Mbit,运算性能可达134GFLOPS. 图1 HXDSP104x系统架构Fig.1 Architecture of HXDSP104x system HXDSP采用哈佛体系结构,有独立的程序总线和数据总线.HXDSP处理器有宽度为512bit的指令总线和非对称全双工的内部数据总线.它包括4 个基本执行宏(element operation macro),每个执行宏由 8 个算术逻辑单元(ALU)、8 个乘法器(MUL)、4 个移位器(SHF)、1 个超算器(SPU)以及 128个通用寄存器组成. 该文提出一种基于HXDSP的改进算法,其算法伪代码如算法1所示.由于这一算法为基于BNDM算法在HXDSP平台上的向量并行优化算法,包含提前启动、Q-grams(Q值在此取2)、VLIW逻辑转化等优化策略,故简称为VBNDM2算法. HXDSP处理器访存可支持双字读写,同时访问并读取连续的Tpos和Tpos-1位数据与单字读取Tpos所花费的时钟周期数相同,因此基于双字读写策略,可以有效提高检索的访存效率.而采用G-grams方式的2-grams访存方式读取,既可以充分发挥处理器的硬件特点,又利用了算法的优势,可以有效提升效率.若将参数Q的形式扩大至3、4,在带来额外的硬件开销的同时,因访存形式不同,效率并不高. 此外,基于快速启动策略,也并非必须对每个分支都展开循环体进而合成.对前几位进行快速检索,一旦不匹配直接跳转,便能有效减少匹配,提高命中率,这同样也是减少跳转和预取的方式之一.因此最终算法包含双重循环,内层为2个循环. 在这样的循环算法中,需要对最后一个j==0的if判断进行优化去除.通过逻辑运算如X=j& 1和Y=X^1等,即可将if判定转为指令并行.同时对检索的记录过程采用分别记录而非频繁跳出的形式,也对算法的流畅并行起到了良好支撑. 算法1.VBNDM2算法 输入:Pattern P of length m,Test T of length n 输出:All position of P in T 1.Preprocessing;%预处理部分; 2.ForEachc∈∑do[C]=0m; 3.Forj=1tomdo 4.k ← 1 << m-j;B[Pj]=B[Pj]| k; 5.Endfor 6.j=0; 7.WhileP[0…j]==P[m-1-j…m-1]doj++; 8.StringMatching%串匹配部分; 9.pos=0;moveshift=m-j;pos=m-1; 10.Whilepos≤ndo 11.D ←(B[Tpos]<<1 & B[Tpos-1]) 12.While(D==0)&&(pos 13.pos ← pos + m-1$;D ←(B[Tpos]<<1 & B[Tpos-1]); 14.Endwhile 15.j=m-2;D ← D<<1; 16.pos ← pos-2;D ← D & B[Tpos]; 17.WhileD && jdo 18.j--;D ← D<<1;pos--;D ← D & B[Tpos]; 19.Endwhile 20.If(j==0)then 21.output p at position;pos ← pos + moveshift; 22.Endif 23.pos ← pos + m 24.Endwhile 该文基于HXDSP平台,选取KMP[12]算法、Shift-Or[13]算法、Horspool[15]算法、ESO算法和EPSO算法作为VBNDM2算法的对比算法,并分别对不同的匹配串长条件下英文语料与DNA序列的串检索开销进行数据对比.所选择的待匹配文本为Holy-bible.txt(703KB)和E.coliDNA[25]序列(Escherichia_coli_str_k_12_substr_mg1655,15,2143bp).对于每一种模式串长度,本实验在文本中随机抽取100个串作为样本.其中,KMP算法、Horspool算法、Shift-Or算法、ESO算法为基于HXDSP平台的向量化实现,EPSO算法与VBNDM2算法为基于HXDSP平台的并行化实现.考虑到HXDSP芯片主频为800MHz~1GHz,该文采用更精确的实际执行所消耗的时间周期数(cycle)做为数据对比单位.其具体的实验统计结果分别如表1与表2所示. 表1 DNA字符集下串匹配时钟开销(Cycle)Table 1 DNA character set string matching clock overhead 如表1、表2所示,表头横向为进行对比的各串匹配算法,表头纵向为字符串长度,表格各行列数据为算法执行所消耗的平均时钟周期数.时钟周期数越少,算法执行越快,效率越高.通过表1、表2可看出,Horspool算法与VBNDM2算法为不稳定算法,它们随着模式串长度的增加,效率有所提高.KMP算法、Shift-Or算法、ESO算法和EPSO算法为稳定算法,它们的实际检索时间受模式串长度影响不大. 表2 英文语料下串匹配时钟开销(Cycle)Table 2 English corpus string matching clock overhead 实验结果表明,当选取拥有152143个碱基对的大肠杆菌DNA序列作为文本串时,VBNDM2算法的性能随着字符串规模的增大逐渐提升.当字符串规模大于8时,其性能相对于EPSO算法有优势.而EPSO算法作为一种稳定算法,随着字符串规模的增大,其性能与VBNDM2算法有着差距逐渐增大. 而当测试集选取703KB大小的英文文本时,VBNDM2算法在任何情况下都有着更显著的性能.这一方面证明了基于BNDM算法的串匹配算法在英文语料检索中,有着更好的性能,另一方面也证明了基于快速启动、Q-grams和数学逻辑计算的VBNDM2算法,是一种非常适合HXDSP处理器的串匹配优化算法. 该文通过分析不同的串匹配算法及优化技术在DSP处理器上的执行效果,结合HXDSP处理器平台的体系架构特点和指令优势,提出了一种高效串匹配算法——VSBNDM2算法.该算法充分发挥了HXDSP处理器硬件特点与优势,有效提升了单模式串匹配算法的执行效率. 我国移动设备相对于国外,发展起步较晚,应用支持较为薄弱,应用场景较少.基于DSP处理器的串匹配算法的研究,有助于提升DSP处理器在网络安全、入侵检测和信息筛选等方面的使用价值.尤其是在移动设备及手持小型设备上,有着极其广阔的应用市场,对推动国产信息化与安全建设,有着重要的意义.我们接下来也会在当下研究工作的基础上,继续发掘HXDSP上并行的串匹配算法的优化潜力,并将模式匹配的方向拓展到多模式匹配、模糊匹配等领域.2.2 基于比特位并行的串匹配算法
2.3 BDM与BNDM算法介绍
3 基于DSP处理器的串匹配优化方法
3.1 DSP下串匹配的特点
3.2 Q-grams与提高最大跳跃距离
3.3 提高前序启动与判断过程
3.4 通过VLIW结构将逻辑判断转为数学运算
4 实现平台介绍
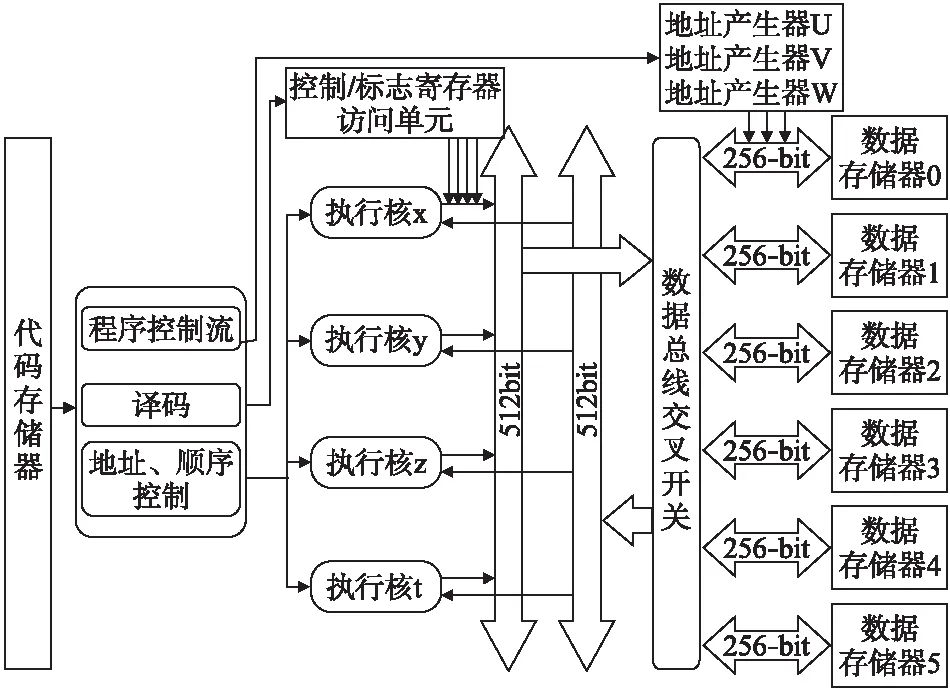
5 算法实现
6 实验结果与分析
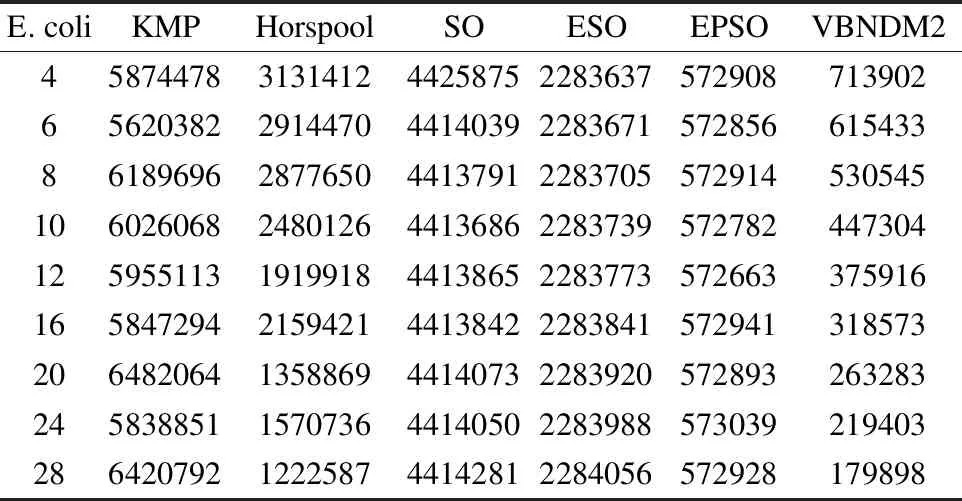
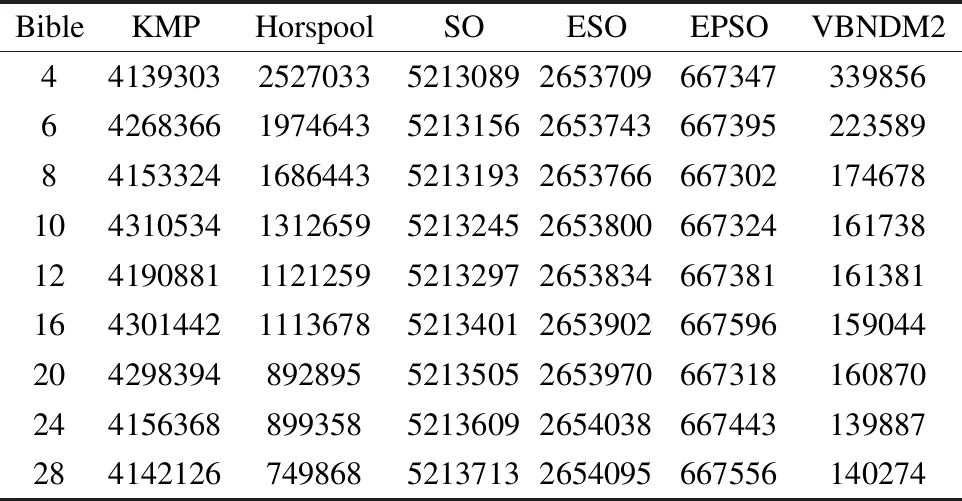
7 结 论
猜你喜欢
科普童话·神秘大侦探(2023年1期)2023-05-30 12:48:10意林图解作文(小学版)(2019年6期)2019-07-16 08:35:46测控技术(2018年5期)2018-12-09 09:04:26电子测试(2018年18期)2018-11-14 02:30:34专利代理(2016年1期)2016-05-17 06:14:36电子设计工程(2015年12期)2015-02-27 12:06:20汽车零部件(2014年1期)2014-09-21 11:41:11小青蛙报(2014年1期)2014-03-21 21:29:39机电信息(2014年27期)2014-02-27 15:53:56质量与标准化(2010年5期)2010-05-03 04:15:40
