
改进的轻量型网络在图像识别上的应用
2021-04-11 12:49:20肖振久杨晓迪唐晓亮
计算机与生活 2021年4期
肖振久,杨晓迪+,魏 宪,唐晓亮
1.辽宁工程技术大学软件学院,辽宁葫芦岛 125105
2.中国科学院海西研究院泉州装备制造研究所,福建晋江 362200
随着AlexNet[1]在图像分类领域ImageNet 竞赛中取得优异的成绩,卷积神经网络(convolutional neural network,CNN)开始广泛应用在计算机视觉领域中。至此以后,各种新型的网络结构不断被提出,如ConvNet[2]、VGG[3](visual geometry group)和ResNet[4]等。这些网络结构大多使用卷积层与池化层的组合提取图像的特征并使用全连接层(fully-connected layer,FC)对图像进行分类,但采用传统卷积方式会带来较大的计算成本,而用全连接层训练的模型会消耗较大的存储空间。通常,一种解决这些问题的方式是对训练好的模型进行网络剪枝、网络蒸馏[5]等,最终使得模型具有轻量且准确度高的网络。另一种是直接设计出轻量级的神经网络架构[6]。在第二种方法上,有些学者通过压缩卷积过滤器,提出了SqueezeNet[7]及SqueezeNext[8]方法,并使用了Batch Normalization[9]来加快训练网络时的收敛过程。有些学者从特征提取的角度出发,利用深度可分离卷积提出了MobileNet[10]。类似设计轻量化卷积结构的方法还有Inception[11]、Xception[12]、ShuffleNet[13-14]和ThunderNet[15]等。从而使得深度可分离卷积在人脸识别[16]、目标检测、图像分割[17]等领域得到广泛应用。
但这些方法都是针对特征提取模块的改进,Lin等[18]提出NIN(network in network)网络,采用全局平均池化(global average pooling,GAP)替换全连接层用于控制模型规模,但全局平均池化严重依赖于特征提取模块输出特征图的质量,若特征图包含的特征较多,全局池化会丢失许多有用信息,同时也会造成模型训练收敛速度降低等问题。吴进等[19]提出用卷积层直接替换全连接层的方法,并用多个小卷积逐层缩小特征图的方法达到了一定的压缩效果。Zhou 等[20]提出了克罗内克积(Kronecker product,KP)的方法应用于分类器模块,在SVHN和ImageNet数据集上能够实现10倍的压缩率,且精度只有1%的损失。Jose 等[21]提出了一种克罗内克循环单元(Kronecker recurrent units,KRU)用于分解循环神经网络(recurrent neural network,RNN)中的权重矩阵,这种方法在降低参数量的同时还能在一定程度上解决网络训练过程中梯度消失和梯度爆炸问题。Thakker 等[22-23]为应用于移动互联网设备,进一步利用克罗内克积压缩循环神经网络,取得了38 倍的压缩率,同时可以有效解决自然语言处理(natural language processing,NLP)任务中模型规模大的问题。
为解决上述只单一优化特征提取模块或分类器模块带来的局限性,本文侧重在分类器模块上运用克罗内克积方法,同时在特征提取模块上结合深度可分离卷积、ResNet 残差结构,旨在图像分类任务中更大限度降低计算量及存储空间。通过大量实践,设计了一个能够实现端到端的称为sep_res18_s3 的网络架构,该架构用克罗内克积方法设计了3 层separable 模块,并在特征提取模块上设计了一层卷积和一个18 层的深度可分离残差模块。实验结果表明,该网络结构相比只用ResNet 残差结构或只用深度可分离卷积网络,可以在分类任务中更好权衡网络模型的精度和存储空间。
1 提出方法
在这一部分,首先介绍在分类器模块中用克罗内克积方法替换全连接层权重矩阵的实现原理,然后介绍了在特征提取模块设计可分离残差模块的原理,最后介绍了权衡网络宽度、深度进一步改进网络结构的方法,并给出了一系列可以实现端到端训练的网络架构。
1.1 克罗内克积替换全连接层权重矩阵原理
深度神经网络的一个全连接层可以理解为输入向量到输出向量的映射。考虑到一个输入样本的情形,若输入向量X∈ℝm×1,输出向量为Y∈ℝn×1,全连接层可以表示为:

其中,W∈ℝn×m和b∈ℝn×1分别表示权重矩阵和偏置,σ(∙)表示非线性激活函数,权重矩阵W的大小由输入向量和输出向量共同决定。全连接某层的参数量r和浮点运算次数(floating point of operations,FLOPs)o可以表示为:

当全连接层输入向量X∈ℝm×1与输出向量Y∈ℝn×1的维度很大时,容易导致网络参数爆炸问题。如VGG16 有三层全连接层,整个网络架构中有90%的参数都源自于此。为了缓解多层感知机参数量大的问题,提出了一种分离全连接权重矩阵的方法。这一方法将权重矩阵W∈ℝn×m分解为两个较小权重矩阵,并且W等于两个小参数矩阵的克罗内克积:

且满足n=n1n2,m=m1m2,由式(1)、式(2)可知:
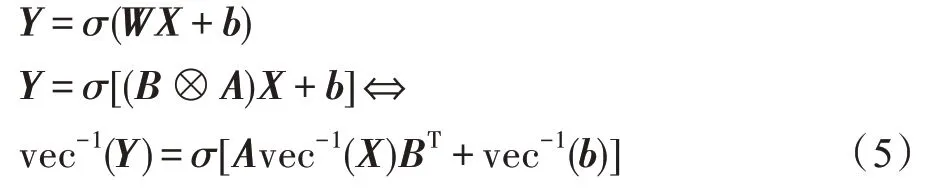
其中,vec-1(*)为把一个列向量转化为对应的矩阵操作,因此,可以将式(1)全连接层改写为式(5)中输入矩阵vec-1(X)∈与两个小参数矩阵A∈和BT∈的乘积再加上一个偏置矩阵vec-1(b)∈,小参数矩阵可以用反向传播算法学习。为对比需要,在公式或表格中用FC 表示全连接层,把替换全连接层的这种方式称为separable 层。vec-1(Y)∈是separable 层的输出,vec-1(X)∈是separable层的输入,vec-1(b)∈是可学习的偏置。
图1 为式(5)第一行的全连接层替换为第三行separable层的过程。

Fig.1 Schematic diagram of replacing fully connected layer with separable layer图1 全连接层替换为separable层示意图
因此,一层separable的参数量为n1m1+n2m2+n1n2,一层FC 的参数量为n1m1×n2m2+n1n2。若两者均不考虑偏置参数带来的影响,参数之比可以表示为:
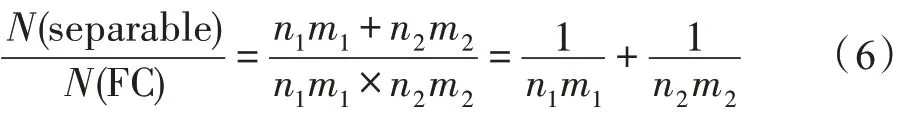
因为n1,n2,m1,m2≫1,可推知,因此separable层相比FC 层可以极大程度降低参数量。
由于一个separable 层包含两次矩阵乘法运算,运算复杂度为O(m1×m2×n1+m2×n2×n1),而一层全连接层的运算复杂度为O(m1×m2×n1×n2),两者运算复杂度之比可以表示为:

因为n2,m1≫1,由式(4)可推知separable 层相比FC 层可以在降低参数量的同时降低运算成本。
当m1=m2=n1=n2,如VGG16 第二层全连接权重矩阵为W1∈ℝ4096×4096,可以分解为A1∈ℝ64×64和B1∈ℝ64×64的克罗内克积,则使用separable 层替换该层全连接可分别使参数量和计算量减少99.95%和96.88%。
1.2 深度可分离残差模块
深度可分离卷积是一种应用于特征提取模块的轻量化结构,自从在MobileNet 网络架构中大量运用此结构后,这种较新的网络结构不断被应用于各种领域,如目标检测[24]、图像语义分割[25]等。图2(a)黄色部分为传统的标准3D 卷积核,图2(b)、(c)绿色部分为深度可分离卷积组成结构。分别将标准3D 卷积核分解成一个逐通道处理的二维(2D)卷积核和一个跨通道的1×1 大小的3D 卷积核。如果不考虑偏置参数,根据图2(a),标准3D 在某一卷积层进行卷积的参数量R1和计算量分别为:
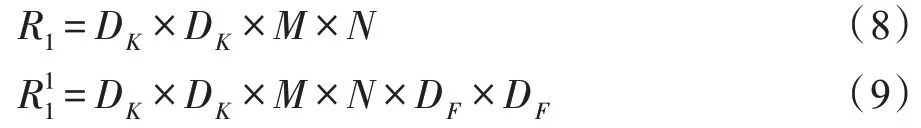

Fig.2 Comparison between traditional convolution filters and depthwise separable convolution filters图2 传统卷积核与深度可分离卷积核对比
其中,DK×DK为卷积核尺寸;M为输入通道数;N为输出通道数;DF×DF为输入分辨率。而根据图2(b)、(c),深度可分离卷积在某一层进行卷积的参数量R2和计算量分别为:

因此,深度可分离卷积相比传统卷积的参数量和计算量可表示为式(12)的形式。

由式(12)可知,在一层卷积中,采用深度可分离卷积相比传统3×3 卷积在参数量和复杂度上具有相同的压缩效果,压缩幅度仅与输出通道数N和卷积核的尺寸DK有关。例如当某一层输入输出通道数均为64 时,传统3×3 卷积的参数量为36 864 个;深度可分离卷积的参数量仅为4 672 个,参数量相比传统3×3 卷积压缩了87.33%。同理计算量同样减少了87.33%。
为增加网络特征提取能力,在网络卷积层上借鉴了残差网络结构。图3(a)为残差模块,这种结构可以表示为:

x、y分别表示残差块的输入和输出,F(x,ω)表示经过可学习的参数ω线性变化后的输出。通过跳跃连接相加,可以实现不同特征的结合,浅层网络包含低级语义的特征,而深层网络有高级语义特征,因此通过特征映射(feature map),可以将前面层学习到的特征直接传到后面层中。当输入输出特征图分辨率不同时,这种跳跃连接还可以融合不同分辨率的特征,使得残差结构拥有更好的特征提取能力。

Fig.3 Two types of residual modules图3 两种残差模块
本文受深度可分离卷积结构和残差结构的启发,通过将两种结构结合的方式,在深度可分离卷积的基础上引入残差结构。图3(b),在输入输出通道数不变的情况下,采用一层逐通道的(2D)3×3 卷积和一层跨通道的(3D)1×1 卷积替换了图3(a)中传统(3D)3×3 卷积,可知,这种深度可分离残差模块相比残差模块,可以进一步降低训练所需的计算量和存储空间,相比只使用深度可分离卷积,这种网络结构又可以融合不同尺度上的空间信息,同时也可以在训练过程中有效防止梯度消失问题。
1.3 SepNet分类器结构
在分类器模块中,使用三层separable 构建了一个SepNet 分类器网络结构,该结构相当于对标准VGG16 网络中两层4 096 个神经元和一个Softmax 分类器全连层的替换。表1 和表2 分别列出了VGG16和SepNet分类器的网络结构。

Table 1 VGG16 network structure of classifier module表1 VGG16 分类器模块网络结构

Table 2 Network structure of SepNet classifier module表2 SepNet分类器模块网络结构
实验将表1 中FC1 输入向量X∈ℝm×1reshape 为表2 中Sep1 的输入矩阵X1∈,然后,SepNet 分类器的输入与两个定义好的小参数矩阵A和B进行矩阵乘法运算,通过逐层训练,在Sep3 中得到一个ℝ1×n的输出,并经过Softmax 层后用于分类(n为分类类别数)。与输入输出元素个数相同的全连接层相比,SepNet 分类器的网络参数和运算成本更少,更适合应用于移动终端设备等智能场景中。
1.4 整体改进网络结构设计
在特征提取模块中,参考了EfficientNet[26]网络的设计思路。EfficientNet 研究了模型尺度缩放,发现均衡网络的深度、宽度和分辨率可以获得更好的性能。基于此提出了一种新的缩放方法,使用一个简单而高效的复合系数来均匀地标度深度、宽度、分辨率的所有维度,并采用神经架构搜索(neural architecture search,NAS)控制模型规模,在给定的资源条件下最大化模型精度。
本文借鉴了EfficientNet 部分思想,综合考虑特征提取模块中的网络深度、宽度,通过手工设计优化网络结构,训练出了一系列效率更高、参数更少的网络。图4(a)为最终设计的sep_res18_s3 网络结构,该网络在特征提取模块上由一层卷积和18 层的深度可分离残差模块组成。图4(b)、(c)、(d)分别为在(a)的基础上设计的对比网络,分别称为sep18_s3、cov_res18_s3、sep_res18_fc。其中图4(b)去掉了所有残差结构,用于对比验证残差结构的重要性,图4(c)替换了所有深度可分离卷积而用传统3×3 卷积,用于对比验证深度可分离卷积的重要性,图4(d)替换了三层separable 而直接用一层全连接,用于对比验证克罗内克积方法的有效性。图4 中的sep、cov 分别表示深度可分离卷积模块和传统3×3 卷积模块,跳跃连接实线部分为恒等映射(identical mapping),可以直接进行Concat 操作,因此不需要增加额外参数量。虚线部分为保证输出特征图尺寸不变而用步长为2的1×1 卷积。
2 实验结果及分析
2.1 实验评估方法及数据集介绍
在图像分类任务中,往往将分类结果准确率作为参考依据,而在各种轻量化网络模型中,除了考虑准确率以外,网络模型的存储空间和计算量也是很重要的参考因素,因此本文结合各种轻量化网络结构评估方法,主要对比各网络结构在各数据集上的分类精度、模型参数量、计算量、训练收敛速度等,作为分析网络性能的依据。
MNIST 数据集来自美国国家标准与技术研究所(National Institute of Standards and Technology(NIST))。训练集(training set)包含60 000 个样本,测试数据集(testing set)包含10 000 个样本,每张图片由28×28 个像素点构成。
CIFAR-10 是由Hinton 的学生Alex Krizhevsky和Ilya Sutskever 整理的一个用于识别普适物体的小型数据集,分为10 个类别,一共有60 000 个32×32 彩色图像,每个类有6 000 个图像。分为50 000 个训练图像和10 000 个测试图像。
作为两种比较典型的小数据集,用于图像分类任务上对比各网络结构的性能指标具有一定的代表性。
CIFAR-100 数据集有100 类,每类包含600 张图片,其中有500 个训练图片和100 个测试图片,图片的大小和格式与CIFAR-10 相同。由于CIFAR-100 每类训练样本和测试样本都只有CIFAR-10 的1/10,因此识别难度更大。
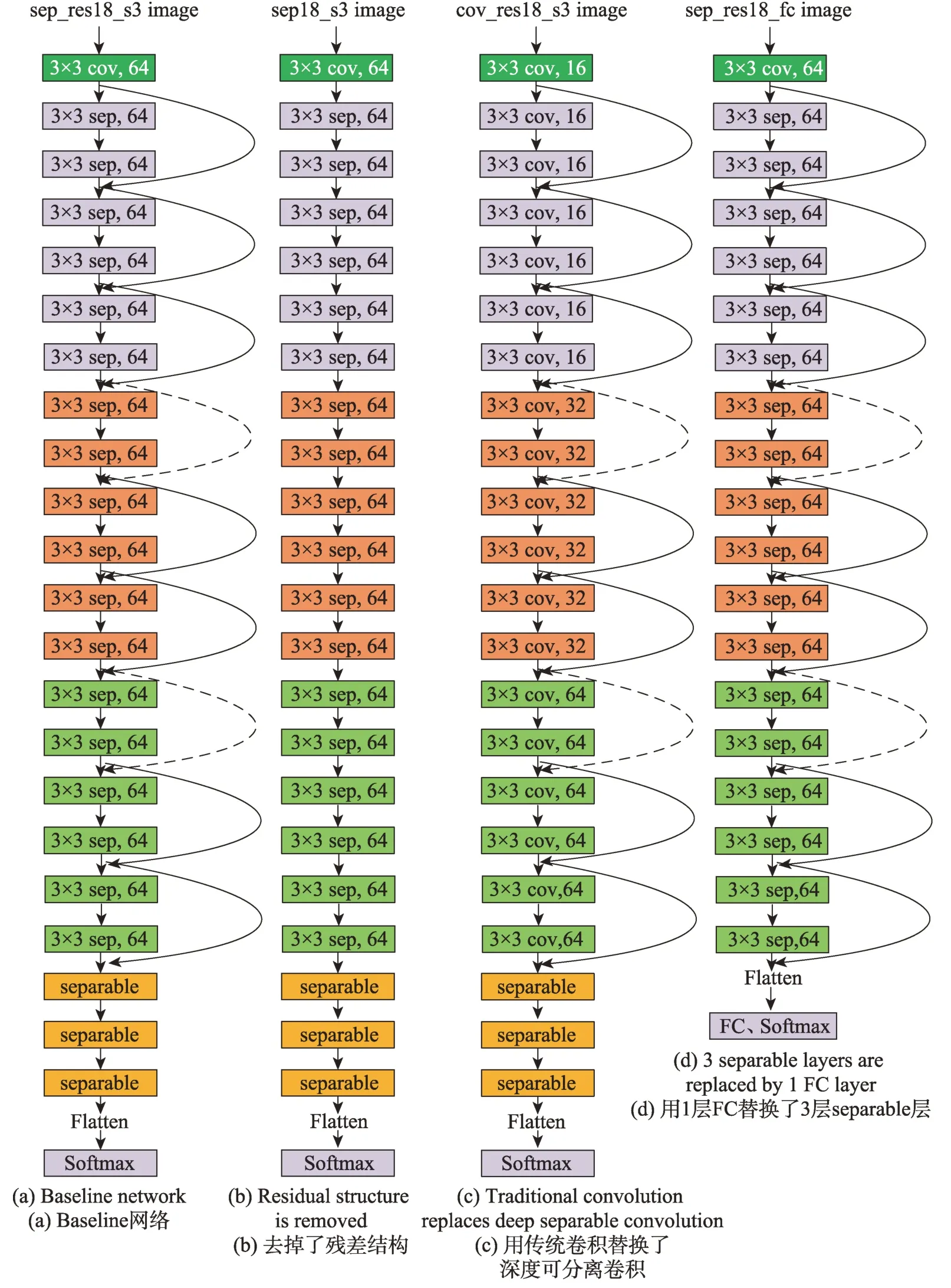
Fig.4 4 kinds of baseline network structures图4 4 种网络结构
2.2 实验环境及参数说明
本实验用到的硬件环境为CoreTMi7-6700CPU@3.40 GHz、GeForce GTX1080 Mobile 显卡,主要用到的软件为pycharm2019.2 及anaconda3-5.3.1。用于配置的虚拟环境基于python3.6,用到的深度学习框架为keras2.2.4,并用tensorflow1.14 作为后端。采用matplotlib3.1.1 作为绘图工具。
为了便于对比,在训练各数据集时,使用Keras框架自带的数据增强对输入样本进行了轻微的预处理。由于训练数据的不同,训练CIFAR-10 和CIFAR-100时统一采用学习率0.001,训练MNIST 时统一采用学习率0.000 5,每次在epoch数为80、120时,将当前学习率降低90%,并都以Adam 优化器训练150 个epoch。
2.3 克罗内克积有效性验证
为了对比验证separable 层替换全连接层的有效性,用VGG16 变体作为对比网络,对比实验首先保证特征提取模块网络结构不变,以验证分类器模块的性能。由于VGG16 原本用于大图像分类,因此适当降低VGG16 网络的宽度和深度以适应小数据集的分类任务。
表3 和表4 分别为缩小后的VGG16 特征提取网络结构和分类器结构,称为VGG10。表中一共用7层卷积层和3 层池化层以及3 层全连接层,其中Filter size 为卷积核尺寸,Filter num 为对应卷积核的数量,同时也为该层卷积层的输出通道数。Strides为步长。

Table 3 Feature extraction module of VGG10表3 VGG10 特征提取模块
同时在分类器模块,将VGG16 全连接层的4 096个神经元替换为1 024 个神经元,见表4。

Table 4 VGG10 network structure of classifier module表4 VGG10 分类器模块网络结构
X为经过Faltten 之后的输入,W为权重矩阵,组合表3 和表4,最终形成缩小后的VGG10 网络结构,同时通过用3 层separable 结构替换了VGG16 的3 层全连接层,组合表3 和表2,最终形成SepNet网络。
分别在MNIST、CIFAR-10、CIFAR-100 数据集上训练VGG10 和SepNet网络。表5 列出了各网络结构分别在每个数据集上的精度、参数量及浮点运算次数(FLOPs)。由表5 可以看出,采用MNIST 数据集训练,SepNet结构在分类准确度上与VGG10 相近,但参数量和运算量相比VGG10 网络分别降低了91.89%和92.59%。采用CIFAR-10 数据集训练,使用SepNet结构在分类准确度上略好于VGG10 网络结构,而且参数量和计算量相比VGG10 均降低了94.09%。采用CIFAR-100 数据集训练,使用SepNet 结构在精度上高出VGG10 近6 个百分点,而且参数量和计算量相比VGG10 均降低了94.07%。实验结果表明,在保证分类精度不降低的情况下,使用separable 层替换全连接层可以极大程度降低参数冗余和计算成本,证实了克罗内克积方法的有效性。

Table 5 Comparative results on VGG10 and SepNet表5 VGG10 和SepNet对比实验结果
为了进一步探究VGG10 和SepNet 训练MNIST、CIFAR-10 和CIFAR-100 的表现,图5 展示了VGG10和SepNet 网络在训练CIFAR-10 时各自的训练结果,分别为训练集准确率和验证集准确率、训练集损失函数和验证集损失函数之间的对比曲线。
从图5 可以看出,在训练集准确率acc 上,图5(b)不如图5(a),且损失值loss 相比图5(a)更大,主要是由于VGG10 参数量较多,能够学习更复杂的特征,因此图5(a)在训练集上表现得更好。但由图5(a)可以看出,在第15 次迭代后,验证集上的准确度并没有随着训练集准确度上升而上升,而是趋于平稳。这一过程在验证集损失值val_loss 上表现出不能很好地收敛,并在第20 次迭代之后损失值开始不断轻微增大,由此可以判断出现了一定程度的过拟合现象。而由图5(b)可以看出,通过采用SepNet 结构,验证集准确度曲线基本可以“一直跟随”训练集曲线上升,并且验证集上的损失值可以很好地收敛。
为了对比VGG10 和SepNet 训练不同数据集收敛速度和损失值下降过程的表现,图6 分别展示了VGG10 和SepNet 在MNIST、CIFAR-10 和CIFAR-100各自的训练结果。其中图6 各子图上方为验证集准确率对比曲线,下方为验证集损失函数的对比曲线。
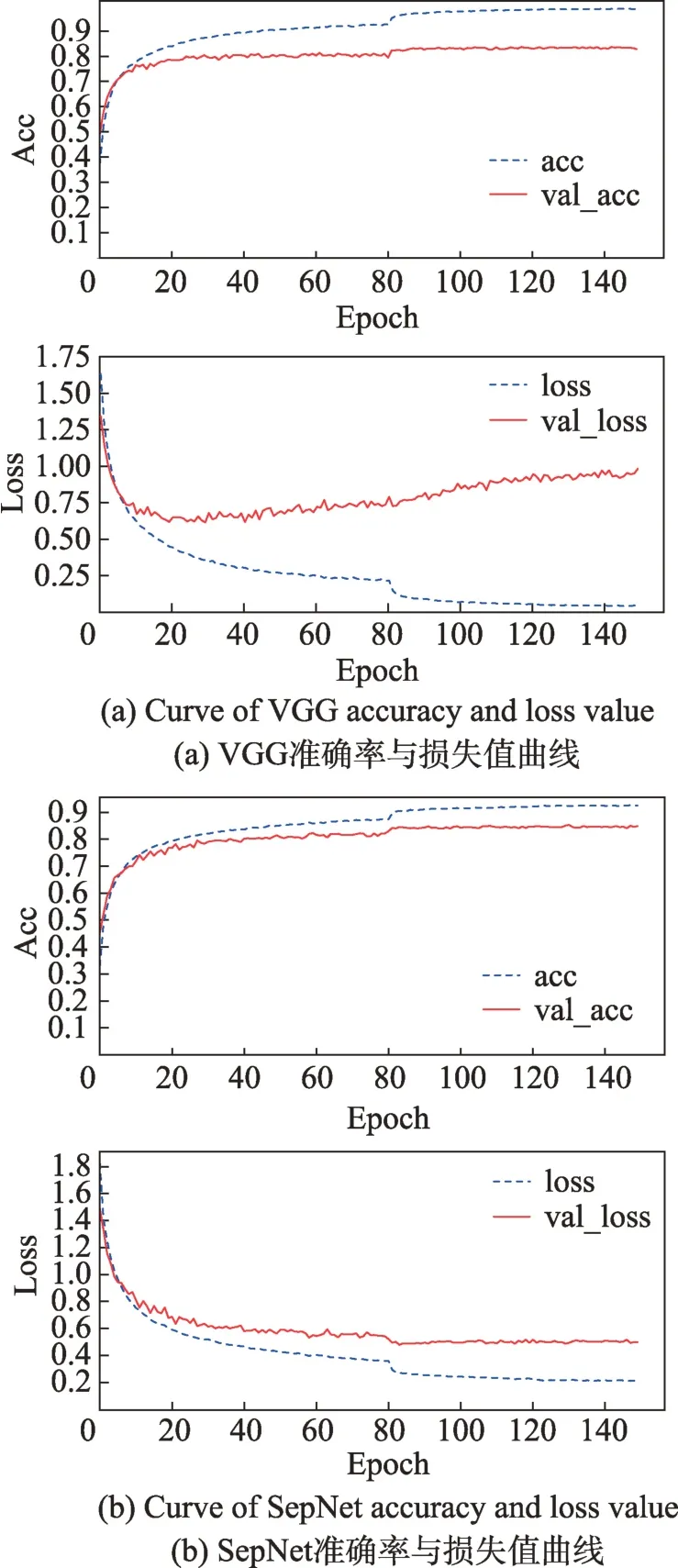
Fig.5 SepNet and VGG10 training curve图5 SepNet与VGG10 训练曲线
实验表明,在MNIST 数据集上,如图6(a),SepNet 和VGG10 的收敛速度区别不大,主要是MNIST易于训练。在CIFAR-10数据集上,如图6(b),VGG10 在20 次epoch 之前的收敛速度快于SepNet,但是在20 次epoch 之后,由于VGG10 参数量过多导致过拟合现象,最终使得SepNet 的分类精度高于VGG10,同样在图6(c)中,这一现象在更难训练的CIFAR-100 数据集上表现更为明显。实验结果表明,在MNIST、CIFAR-10 和CIFAR-100 数据上,SepNet比VGG10 具有更高分类精度,且更容易防止过拟合。
为了探究SepNet 和VGG10 在同一数据集上的训练速度,表6 列出了SepNet和VGG10 分别在GPU、CPU 上训练CIFAR-10 的每个batch 平均训练时间。
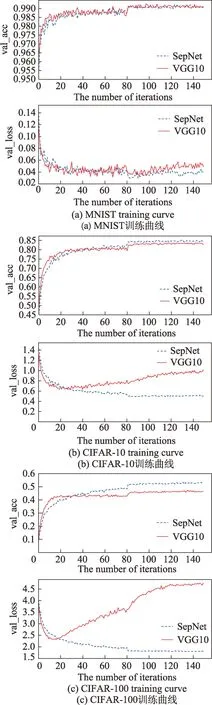
Fig.6 Comparison training curve between SepNet and VGG10图6 SepNet与VGG10 对比训练曲线

Table 6 Comparison of running time of CIFAR-10表6 CIFAR-10 的运行时间对比 ms
实验结果表明,SepNet 在GPU 上的训练时间与VGG10 相当,这主要是用separable 替换全连接层后,虽然运算量降低了,但是每层separable 需要依次进行两次矩阵乘法运算,增加了更多必要的串行运算。而在CPU 上,主要采用串行运算的方式,由于没有了并行运算的优势,因此SepNet 在CPU 上的运行时间则明显低于VGG10。
综合对比可以发现,SepNet 方法相比VGG10 更不容易发生过拟合,在拥有更小的参数量和计算量的前提下仍能达到更高的精度,且在CPU 上的训练速度更快,更能满足部署在移动设备等智能场景中。
2.4 Baseline网络与其他网络的对比
2.3 节验证了用separable 层替换全连接层的有效性,为了进一步改进网络结构,在特征提取模块上设计了一个深度可分离残差模块,见图3(b)。在MNIST、CIFAR-10 数据集上训练图4 中的4 个网络模型,表7 为在各网络的训练准确率、参数量及计算量(FLOPs)对比。图7 为对应网络结构在CIFAR-10 上的训练集准确率及验证集准确率的对比曲线。
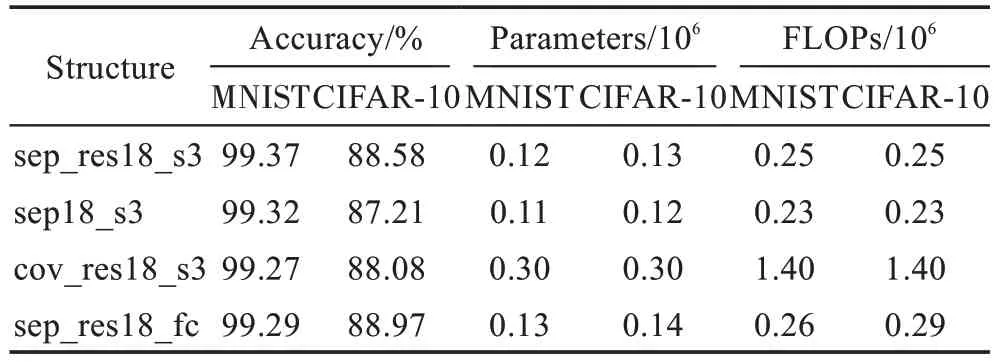
Table 7 Comparison results of each network on MNIST and CIFAR-10 datasets表7 各网络在MNIST、CIFAR-10数据集上的对比结果
结果表明,在MNIST 数据集上,sep_res18_s3 训练准确率均高出其他3 个网络的准确率,在CIFAR-10 数据集上,由图7 可以看出,各网络的训练结果无论是在训练集准确率还是在测试集准确率上,分类精度基本相同。

Fig.7 Test set accuracy of each network on CIFAR-10图7 各网络在CIFAR-10 上的测试集准确率
结合表7 可以发现,sep_res18_s3 训练准确率仅低于sep_res18_fc,准确率减少了0.39 个百分点,但同时参数量和计算量相比sep_res18_fc 分别降低了11.10%和10.93%,这说明相比目前较流行只用一层全连接来做分类的方法,用separable 层替换全连接层的方法在一定程度上仍然可以进一步降低参数,并保证训练准确率。对比sep_res18_s3 与sep18_s3,sep_res18_s3 在两个数据集上训练准确率均高于sep18_s3,在CIFAR-10 数据集上高出了sep18_s3 网络1.37 个百分点。但sep18_s3 参数量和计算量相比sep_res18_s3 分别降低了7.92%和9.73%,参数增加的部分来自sep_res18_s3 网络“跳跃连接”的虚线部分,这说明残差结构可以付出额外很小的存储空间来进一步提升准确率。对比sep_res18_s3 与cov_res18_s3,sep_res18_s3 网络在CIFAR-10、MNIST 上的准确率均高于cov_res18_s3,且参数量和计算量相比cov_res18_s3 分别降低了58.33%和81.82%。这说明在ResNet 残差结构中使用3×3 卷积仍然存在较大的参数冗余,在小数据集的分类任务中,采用深度可分离卷积相比传统的3×3 卷积可以在保证训练准确率的同时极大降低参数量。
为与其他网络对比,在训练CIFAR-100 时增加了网络的特征提取能力以提升一定的精度,在特征提取模块采用ResNet18 结构,将每层的通道数设置为64。在分类器模块上仍然用表2 的3 层separable 层,形成的网络结构称为ResNet18+s3,表8 列出了各网络结构在CIFAR-100 上的参数量和训练精度,实验结果表明,ResNet18+s3 在保持较低参数量的同时仍然可以达到更高的精度。同时,设计的sep_res18_s3、sep18_s3 在参数量上相比X-KerasNet[27]等网络仍具有较大优势。
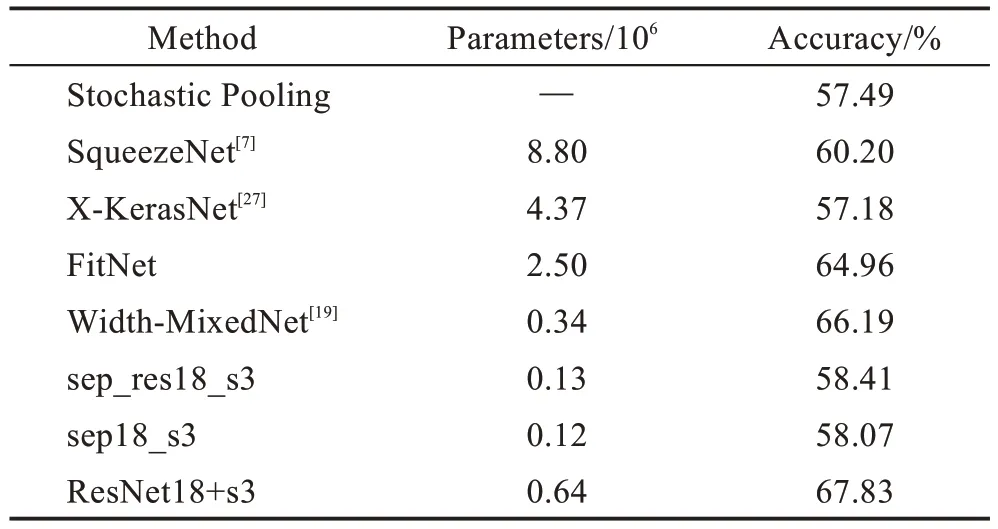
Table 8 Training accuracy and number of parameters on CIFAR-100表8 CIFAR-100 训练精度及参数量
3 结束语
本文提出了一种用于替换多层感知机全连接层和改进特征提取模块传统卷积层的方法,该方法首先用克罗内克积解决了传统类似VGG 网络全连接层参数量大,且在训练过程中容易过拟合的问题,然后结合在特征提取模块上设计的深度可分离残差模块,既解决了类残差网络用传统3×3 卷积冗余度高的问题,又保证了深度可分离卷积层与层之间的信息流通。实验结果表明,通过权衡网络深度、宽度,同时结合深度可分离卷积、残差结构及克罗内克积方法,形成的sep_res18_s3 网络能够实现图像分类任务中精度和存储空间的平衡,可以进一步应用到移动设备或嵌入式设备等智能视觉场景中。
由于本文只是在MNIST、CIFAR-10、CIFAR-100这样的小数据集分类任务上验证了sep_res18_s3 网络的有效性,对网络性能的验证仍有一定的局限性,在下一步工作中,将按照同样的方法改进网络结构以适应图像识别任务中更多小数据集及大数据集样本的分类,并考虑结合网络剪枝、参数量化等压缩方法,训练出冗余度更小的模型。
猜你喜欢
网络安全与数据管理(2022年3期)2022-05-23 13:26:48
北京航空航天大学学报(2020年10期)2020-11-14 09:26:02
自动化学报(2019年6期)2019-07-23 01:18:32
电子制作(2018年19期)2018-11-14 02:37:08
自动化学报(2017年11期)2017-04-04 02:52:58
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27 06:31:53
管理现代化(2016年3期)2016-02-06 02:04:41
管理现代化(2016年3期)2016-02-06 02:04:13
智能系统学报(2015年4期)2015-12-27 09:37:52
河南科技(2015年8期)2015-03-11 16:23:52
