
基于机器视觉的路面裂缝病害多目标识别研究
2021-04-07 07:58:30章世祥张汉成李西芝
公路交通科技 2021年3期
章世祥,张汉成,李西芝,胡 靖
(1. 华设设计集团,江苏 南京 210014;2. 东南大学 土木工程学院,江苏 南京 211189;3. 东南大学 计算机科学与工程学院,江苏 南京 211189;4. 东南大学 智能运输系统研究中心,江苏 南京 211189)
0 引言
裂缝是路面结构的主要病害类型,尤其是半刚性基层结构引起的反射裂缝对道路设施的正常运营造成极大隐患,裂缝若得不到及时维养将发展为坑槽病害,对行车安全性极其不利。有效的裂缝检测技术对维持路面服役水平、保障车辆行驶安全至关重要,传统的路面病害检测主要依靠人工巡检方式,其存在效率低、主观性强且成本较高等缺陷,随着图像处理技术的不断发展,基于病害图像的识别与分析为路面裂缝检测提供了高效方法,但其识别精度依赖于病害图像质量。因此,研究提出了一种基于机器视觉的路面裂缝识别技术,为路面结构的病害评估提供基础。
传统的图像识别技术主要通过图像灰度值等特征定义病害区域,如大津法OTSU、边缘检测与区域生长算法等[1-3],对于具有简单背景且灰度差异较大的病害图像具有较好的识别效果,但复杂背景下识别错误率较高。对于路面裂缝病害的识别,分割算法相对而言具有较好的正确率,但其处理速度较慢[4]。利用图像纹理并考虑亮度和连通性来识别裂缝,或采用动态阈值方法均只能获得较为粗糙的裂缝形态[5]。此外,基于Canny边缘检测的裂缝识别也较易出现误识别情况,可见传统图像识别技术普遍问题在于准确度低,误报率高,无法对病害进行像素级的识别,需要手动提取特征,且预处理的方法直接影响到识别效果等[6-7]。对于深度学习框架而言,卷积神经网络(CNN)被认为对复杂背景下病害的识别具有极大的优势。AlexNet模型证明了CNN 网络能够提升图像分类的效果,随后GoogleNet、 VGG与ResNet等均表明了CNN网络在图像识别中的有效性[8-9]。近年来,基于深度学习的图像识别技术逐渐用于工程结构的病害检测,Zhang等提出了基于深度卷积神经网络的道路裂缝检测系统,使用了整流线性单元(ReLU)作为激活函数,提高模型在训练时收敛的速度[10]。Xu等在全卷积神经网络(FCN)的基础上建立了FCNN模型,其语义分割效果较好但训练时间相对较长[11]。Jiang等采用无人机实时获取裂缝图像并进行识别,同时可以获取裂缝的宽度值[12]。Maeda等建立了一个大型路面病害数据库,并基于MobileNet等轻量级模型对裂缝进行识别,实现了对病害的快速推理,但是牺牲了部分的准确度[13]。Ni等将GoogLeNet和ResNet20组合用于识别裂缝,取得了良好的效果。但是对于尺寸较小的裂缝识别效果不佳,并且识别速度较慢[14]。Cha等使用滑动窗口基于CNN辨识裂缝,但无法确定最佳滑动窗口大小,且处理速度较慢[15],而采用Fast R-CNN模型识别裂缝有效提高了速度,但是无法输出裂缝的掩码,同时也无法统计出裂缝的大小[16]。综上所述,基于深度学习模型对于病害的检测问题主要还是集中在图像分类,或者按图像块进行分类,最终为图像产生块检测结果,而不是针对病害像素产生检测结果,更进一步的研究也只停留在语义分割的层次上。部分研究实现了对于像素级的分类,然而并不能实现实例分割,当在一个图像中出现多个同种病害时,无法将其区分识别[17]。此外,部分基于深度学习的模型推理速度过慢,难以在工程中实现高效应用。
本研究提出一种基于深度卷积神经网络的自动化道路病害的检测模型,基于Mask R-CNN框架[18],用以实现对路面的裂缝进行实例分割的目的。相对于以往的自动化病害检测模型相比,该模型实现对裂缝的实例分割,可对裂缝病害开展有效的识别、检测、定位与多裂缝目标分割。同时,扩展的主干网络有效提高了模型的识别性能与精度,具备像素级别的识别效应,减少模型对于路面切割缝的误识别,增强模型的鲁棒性。
1 多语义机器视觉识别模型
1.1 基于Mask R-CNN的识别模型框架
卷积神经网络(CNN)常用于实现目标物检测、语义分割与定位[19],由于其具备较好的识别精度,因此在隧道等工程结构的病害研究中得到了一定应用,而在CNN基础上发展得到的R-CNN与Faster R-CNN显著地提升了检测效率[20]。研究引入Mask R-CNN开展路面裂缝病害的识别,并且实现病害体的实例分割。Mask R-CNN在Faster R-CNN的基础上,增加了第3个支路以输出每个目标物的Mask。同时,为了建立深层卷积神经网络以解决训练时梯度消失的问题,采用ResNet-50和ResNet-101两个模型作为主干网络提取图片的特征[21],其网络结构如表1所示。
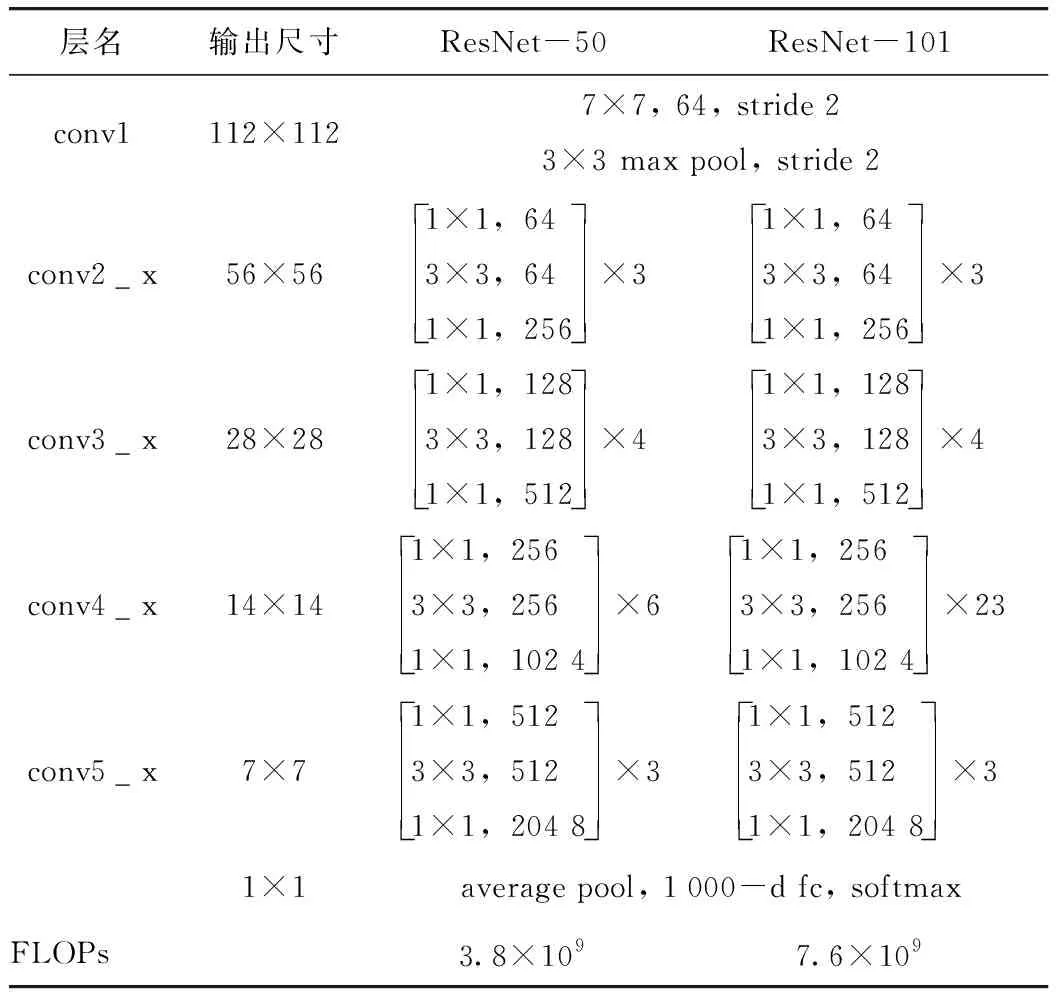
表1 ResNet-50与ResNet-101模型结构Tab.1 Structure of ResNet-50 and ResNet-101 models
裂缝病害具有较大的长宽比,其像素面积相对背景而言较小且不同裂缝尺寸存在差异。因此,需要在卷积神经网络中尽可能地利用深层网络与浅层网络数据信息,分别提取用于裂缝病害检测与分类的语义、几何特征。研究选用Feature Pyramid Networks(FPN)提取各层次维度的裂缝特征,为了提高模型的性能,构建了多尺度的特征图,如图1所示。采用多尺度特征融合的方式,将主干网络每个stage的特征图输出,深层特征通过上采样和低层特征融合,且每层特征均为独立预测。
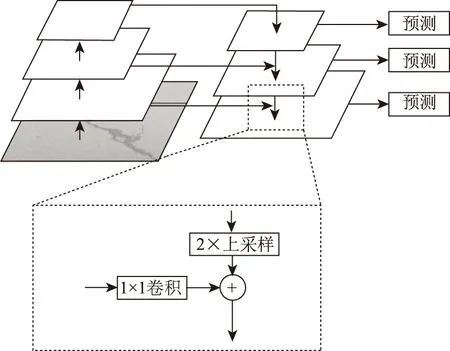
图1 特征金字塔网络模型Fig.1 Feature pyramid network (FPN)
本研究所建立的识别模型框架如图2所示。模型结构分为两部分,第1部分的主干网络由ResNet-50、ResNet-101的FPN层组合而成,主干网络的主要作用是提取图片的特征。第2部分的网络处理输入的特征图并生成候选区域,即有可能包含一个目标的区域,再分类候选区域并生成边界框和掩码,从而实现采用相同的识别模型对不同路面裂缝的像素级识别与实例分割。
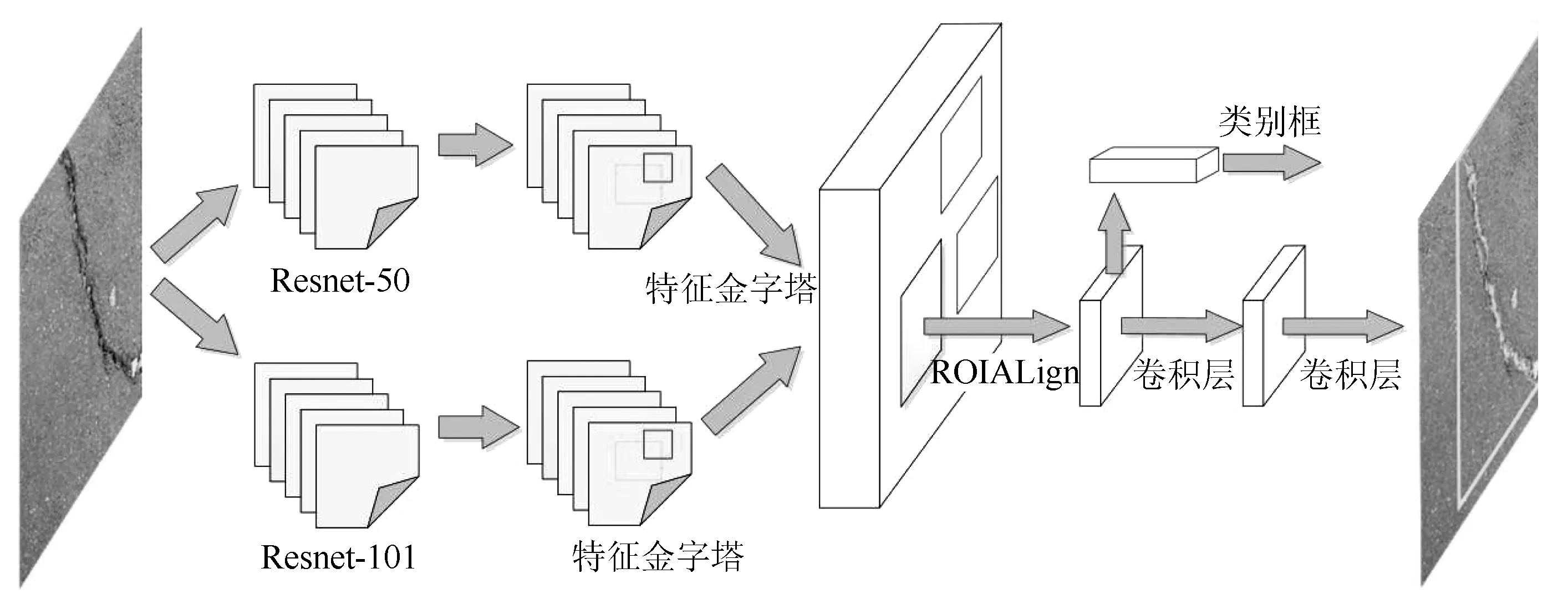
图2 提出的识别模型结构Fig.2 Proposed structure of identification model
已有研究成果表明,增加网络的深度或宽度不会降低网络性能,因为可以在当前网络上增加卷积层而不改变特征图的尺寸,得到的新模型应具有更强的特征提取能力[21]。这表明较深的模型所产生的误差不应该比较浅的模型高[22]。为了进一步提高模型的性能,将ResNet-50、ResNet-101两个主干网络的FPN层按层次分别叠加在一起,通过将输出的特征图直接相加以此来增加FPN层每一层的语义信息和几何信息。如表2所示,ResNet-50和ResNet-101输出的特征图大小的尺寸是一致的,因此不需要进行额外的升采样或降采样等处理。

表2 性能评价指标Tab.2 Performance indicators
1.2 模型损失函数优化
裂缝病害的长宽比值较大,其在图像中的像素数远小于背景像素。因此,若采用Mask R-CNN框架的经典损伤函数将导致裂缝像素误识别为背景像素。本研究构建新的损伤函数以提高裂缝的识别正确率,病害图像通过识别模型后计算出预测值,该预测值与真实值间的差距可采用函数进行量化:
Loss=LossCls+LossBox+LossMask,
(1)
式中,LossCls为病害类型分类误差;LossBox为病害位置误差;LossMask为掩模真实值误差。
其中LossMask可由以下公式进行计算:
LossMask=-∑[λ·W·yi·lnσ(xi)+(1-yi)·
lnσ(1-xi)],
(2)
式中,λ为权重系数,其值越大表明对分类错误的裂缝像素惩罚值越大;W为背景像素数与裂缝像素数的比值;yi为第i个像素的真实值;xi为第i个像素的预测值;σ为Sigmoid函数。
研究所建立的模型采用随机梯度下降算法(SGD)进行训练[23],每次从训练集中随机选取一个样本进行学习以加快训练效率,同时采用冲量算法Momentum加速损失函数的收敛性[24]。对于随机采的m组数据,可计算其平均损失梯度为:
(3)
式中,f(x;w)为学习器;wi-1为第i-1次训练时的参数,模型训练更新速度与计算参数更新值分别为:
vi=βvi-1-αΔw,
(4)
wi=wi-1-vi,
(5)
式中,β为动量参数;vi-1为第i-1次训练时的更新速度;α为学习率。
1.3 识别模型训练
为了解决数据集的缺乏导致的模型泛化能力不强、模型训练时间过长、函数无法收敛等问题,研究采用了基于迁移学习的模型训练方案[25],采用在ImageNet数据库中预先训练的ResNet-50,ResNet-101模型,将基础网格模型与特征图金字塔网络FPN层冻结,只训练剩余的部分以确保模型具备较好的训练速度与准确率。此外,为避免与裂缝类似的干扰影响,将明显的干裂图像作为困难样本(Hard Example)加入到训练集中对模型进行训练,这样可以提高模型对于裂缝识别的准确度,减少对于切割缝等干扰物的误识别。
本研究对裂缝病害的识别可划分为如图3所示的4项内容,图3(a)为病害分类,即判断图像中是否存在裂缝病害,属于二分类问题;图3(b)为位置检测,判断裂缝在图像中的位置并用Box选中;图3(c)为语义分割,将图像中裂缝病害进行像素级分割;图3(d)为实例分割,将同一张图片中的多个裂缝进行像素级的分割。

图3 裂缝识别步骤Fig.3 Steps of crack identification
训练集输入的图像数据分辨率为768×1 024,batchsize设置为2,学习率为0.001。为了使损失函数更好收敛,使用学习率指数衰减让学习率随着学习进度降低以达到更好的训练目的。识别模型的构建使用pytorch 1.3.1版本在ubuntu18.04上部署了建模环境,并使用i9-9900k和RTX2080ti来进行模型的训练和测试。
2 路面裂缝病害训练数据标注与参数学习
为了训练与测试识别模型,收集了不同分辨率的路面裂缝图像1 290张,其中横向与纵向裂缝1 128 张、网状裂缝162张。随机选取1 144张图像作为训练集,选取146张图像作为测试集,训练集中水泥路面与沥青路面裂缝病害图像分别为778张与366张。为便于计算,压缩不同路面裂缝图像至统一分辨率768×1 024。为了获取图片像素级的标注,先对原图进行灰度化和二值化预处理,并且调整灰度阈值及去除多余的噪点,典型病害标记如图4所示。

图4 识别模型训练集标注Fig.4 Labeling training set of identification model

图5 不同损失函数的对比Fig.5 Comparison different loss functions
将病害图像按照9∶1分为训练集与测试集,并采用翻转、对称与随机调整亮度、对比度实现训练集数据增强并扩充4倍,以实现训练模型具备更好的泛化能力与鲁棒性[26]。
识别模型的性能采用PIXACC,PIXAP,PIXREC,IOU开展像素级别评估,并使用COCO数据集中的评价指标AP50,AP75对模型实例分割的能力进行详细的性能评估[27]。此外,识别模型在输出裂缝Mask的同时还会输出包含裂缝Box,因此使用AP和REC来评价模型的裂缝检测能力。
如前所述,裂缝像素和背景像素的数量存在显著的不平衡,如果使用Mask R-CNN框架的传统损失函数计算方法,在训练中为了降低Loss值,模型会更倾向于将更多的裂缝像素分类为背景像素。为缓解正负样本数量上的失衡问题,研究在训练LossMask时使用平衡二值化交叉熵(Balanced binary cross entropy)计算mask分支上的Loss数值。
图5对比了平衡二值化交叉熵与传统方法在裂缝识别中的区别,可见前者具有较为显著的识别优势,不会影响模型对于裂缝的目标检测。平衡二值化交叉熵方法的应用效果受权重参数λ的影响较为显著,有必要对最优权重参数的取值开展对比分析。
图6说明了权重参数λ变化对性能评价指标的影响,由图6(a)可知,随着权重参数λ的增加,不同性能评价指标变化趋势有所区别:PIXACC,PIXAP与IOU均随着权重参数λ的增加而逐渐减少,其中PIXACC对权重参数λ的变化并不敏感;PIXREC的变化呈现相反趋势,即随着权重参数λ的增加而逐渐增大。通过试算可知,一定范围内权重参数λ越大,识别模型中对于裂缝像素的错误分类惩罚值越大,则识别模型更偏向于将像素分类为裂缝像素,此时PIXREC越大且PIXAP越小。识别模型需要达到有效识别裂缝的目的,因此PIXREC与PIXAP需要取得平衡,即在确保较高PIXREC的前提下尽可能提高PIXAP数值。图6(b)为不同权重参数λ下PIXAP与PIXREC的变化情况,可见当权重参数λ取得0.3时符合要求。
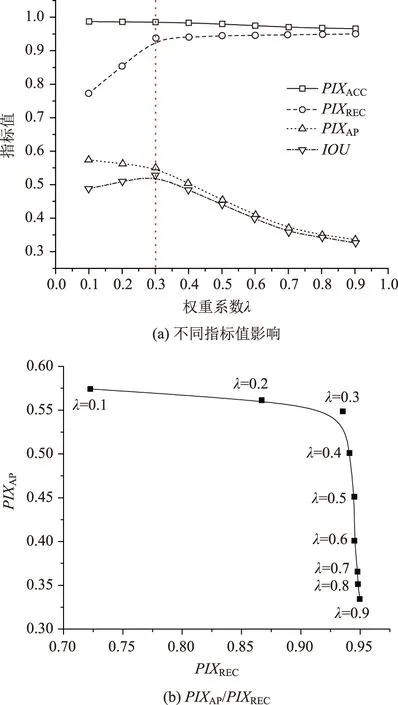
图6 权重参数λ取值影响Fig.6 Influence of weight parameter λ value
3 研究成果讨论
3.1 识别效果分析
本研究所建立的识别模型共迭代30 000次,迭代次数每满1 000次将会评估识别模型对于验证集的验证效果,识别模型的损失函数随迭代次数的变化如图7(a)所示,为进一步对比不同主干网络的损失函数变化规律,将不同的主干网络训练结果进行对比,如图7(b)所示。
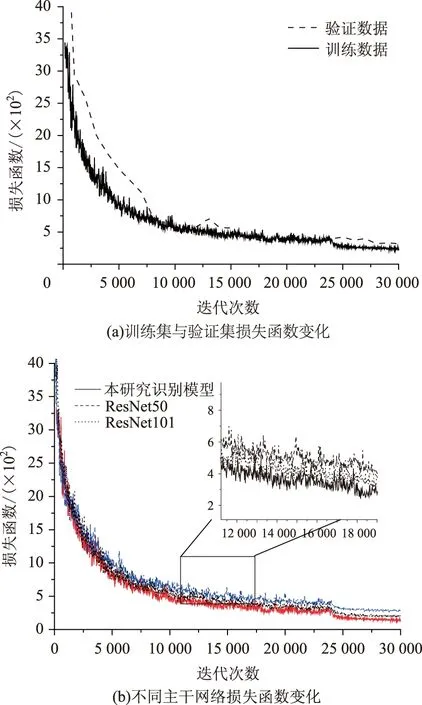
图7 识别模型损失函数变化规律Fig.7 Change rule of loss function of identification model
训练与验证结果均表明了所建立识别模型具备有效的泛化性能,训练过程中未发生过拟合现象,训练后的模型能够精确地识别路面裂缝病害。由图7(a)可知,损失函数随着迭代次数的增加在逐渐减小,表明其识别精度逐渐提高。在迭代次数小于10 000 时,其减小速率较大,随后趋于平缓。图7(b)显示了不同主干网络中损失函数的变化规律,可见其变化趋势相似,在相同迭代次数下,所建立的识别模型的损失函数更小,具备更好的识别精度。本研究所用测试集共146张图片,包含162条裂缝,识别模型成功识别160条裂缝,成功识别出93.6%的裂缝像素,同时正确分类了98.9%的裂缝病害。裂缝数据集区别于其他传统的实例分割的数据集,标注时难以精确区分裂缝的界限,因此数据集中存在因标注产生的误差像素。
如图8所示,所建立的模型实际上可以较好地实现裂缝识别,然而裂缝轮廓细节相对难以精确描述,存在着大量的孔隙且人工标注会漏掉部分裂缝的细节。所以,PIXAP,IOU,AP50,AP75在裂缝识别中会因为训练集图像本身难以精准标注的问题受到影响。

图8 典型病害图像识别效果Fig.8 Result of typical diseases image recognition
以测试集数据为基础,表3列出了本研究识别模型与主干网络为ResNet-50、ResNet-101的Mask R-CNN模型以及全卷积神经网络FCN模型的性能指标对比,可见优化后模型框架与损失函数具备相对较好的综合指标,满足复杂背景下路面裂缝病害的识别与提取。

表3 识别模型的性能指标Tab.3 Performance indicators of recognition model
3.2 识别效果对比
由前述分析可知,识别模型由于扩充了主干网络,其在裂缝识别的性能指标得到了优化,针对裂缝检测与识别的指标AP与REC有所提高。为了与常用的语义分割模型开展对比,本研究选用以VGG-Net为主干网络的FCN模型以相同的病害数据开展训练,并在测试集中进行验证[28],同时也列出了常见的自适应阈值与Canny边缘检测算法识别效果,如图9所示。
由图9可以看出,识别模型在裂缝识别的问题中表现相对较好,通过合并ResNet-50和ResNet-101增加主干网络宽度可以在一定程度上进一步提高模型的性能。如图9(a)与图9(b)所示,所建立的识别模型能较好地识别裂缝形貌,并且对于同一张图片中的多条裂缝与细微裂缝均可实现有效识别与实例分割,针对非裂缝病害的路面接缝等结构也能达到有效过滤的目的。此外,对于复杂的网状裂缝也具备一定的识别能力。作为对比,全卷积神经网络FCN的识别效果如图9(c)所示,其对微小裂缝的细节描述能力较弱,且由于模型结构设计的不同导致其只有语义分割的功能,在识别网状裂缝方面效果较差。图像阈值化是从灰度图像中分离目标区域和背景区域的基本方法,然而仅仅通过设定固定阈值很难达到理想的分割效果。自适应阈值通过计算像素的局部平均强度确定其应该具有的阈值,进而保证图像中各个像素的阈值会随着周围邻域块的变化而变化。自适应阈值在识别沥青路面的裂缝时效果不佳,主要是由于沥青路面颜色、纹理、光影的变化过于剧烈,易将其他低灰度值物体识别为裂缝,如图9(d)所示。Canny边缘检测是基于估计高斯平滑图像每个像素的梯度作为边缘强度的指标,可见其识别效果也无法满足要求,且与自适应阈值类似,均不能实现非裂缝构造的辨识,如图9(e)所示。
本研究所建立的识别模型通过组合ResNet-50与ResNet-101的FPN层来获得更好的特征提取能力。对于传统的卷积神经网络,网络层次越深,特征图的尺寸越小,其在输入图的映射范围越大,因此针对图像中细小裂缝所处位置的描述能力会下降。

图9 裂缝病害识别效果对比Fig.9 Comparison of crack disease identification results

图10 FPN层的特征图Fig.10 Feature images of FPN layers
图10所示为识别模型中不同FPN层的病害图像特征状况,可见低层的病害特征图主要表现为背景、裂缝的纹理、轮廓等细节信息,如图10(a)所示;随着分析层次的逐渐增加,特征图的响应逐渐变得抽象,轮廓等细节信息逐渐缺失,如图10(b)~图10(d)所示。然而,高层特征图通过与低层特征图进行叠加,依然保留了裂缝的几何信息,提升了识别模型检测尺寸不同裂缝的能力。本研究所建立的识别算法对横向、纵向与网状裂缝均具有较好的识别效果,并且达到每秒处理20张病害图像数据,有效实现对病害图像或视频数据的高效处理。
4 结论
本研究针对路面结构常见的裂缝类病害,基于Mask R-CNN框架扩展并优化了识别模型,实现了裂缝病害的图像分类、位置检测、语义分割与实例分割,通过与其他传统与深度学习识别算法的成果对比,得到如下结论:
(1)基于深度学习的识别模型能够开展病害图像的语义分割,并对同一张图像中的不同裂缝进行了实例分割,提高了识别模型的可扩展性。
(2)通过合并ResNet-50与ResNet-101的FPN层可以显著提高主干网络提取病害图像特征的性能,本研究模型对裂缝病害类型的辨识正确率达到98.9%,并可精确识别93.6%的裂缝类像素。
(3)利用平衡二值化交叉熵计算函数数值,并对裂缝像素的错误分类设置更高的惩罚值,可有效缓解裂缝像素和背景像素数量上失衡导致的召回率下降。
(4)识别模型训练过程中引入迁移学习框架,提高了模型训练的收敛性,极大减少了训练时间成本,实现用较少的数据集训练得到较为精确的识别模型。
猜你喜欢
艺术家(2023年8期)2023-11-02 02:05:28
今日农业(2022年3期)2022-06-05 07:12:02
小哥白尼(军事科学)(2022年2期)2022-05-25 13:19:30
今日农业(2021年8期)2021-11-28 05:07:50
烟台果树(2021年2期)2021-07-21 07:18:28
今日农业(2020年19期)2020-11-06 09:29:38
疯狂英语·新悦读(2019年11期)2019-12-18 05:14:16
红领巾·萌芽(2019年8期)2019-08-27 15:30:15
CHIP新电脑(2016年3期)2016-03-10 14:22:03
专用汽车(2015年4期)2015-03-01 04:10:02
