
基于深度神经网络的噪声环境下对话行为分类模型
2021-04-07 06:29申屠相镕秦会斌
测控技术 2021年3期
申屠相镕, 秦会斌
(杭州电子科技大学 新型电子器件与应用研究所,浙江 杭州 310018)
在现代化的脚步不断向前迈进的今天,人们对于计算机的依赖程度与日俱增,如何用计算机方法来处理人类的自然语言也成了热门的研究内容。对话行为分类是实现与数据库的自然语言对接的一项重要任务,因为说话者的意图可以用对话行为(与语境无关的语义和依赖于语境的谓语)[1]来表示。
为了解决对话行为分类中的模糊问题,过去20年来学者们提出了各种机器学习模型。文献[2]研究了稀疏建模方法来改善对话行为分类,提出稀疏对数线性模型,相对于基于规则的基线模型获得了19.7%的相对改善,并且超过了先进的支持向量机(Support Vector Machines,SVM)模型2.2%。文献[3]研究了多核SVM模型来处理对话行为识别问题,提出了一种改进的多核SVM模型并在一些开放分类任务和中文对话行为识别任务上进行测试。文献[4]研究了对话法分类,提出了一种新的生成神经网络体系结构,在循环神经网络框架的基础上结合了一种新的注意技术和序列学习的标签-标签连接。文献[5]证明使用高斯过程(Gaussian Process,GP)的贝叶斯优化超参数可进一步改进结果,并且缩短计算时间。文献[6]对使用提示短语作为对话行为分类的基础进行了调查,通过提示短语来定义含义,并描述如何从手动标记的对话语料库中提取它们。但以上文献均采用实验室环境中纯净的原始语音作为测试样本,实际的对话环境中常常存在噪声的干扰,因此需要建立一个能够有效应对噪声环境的对话行为分类模型。
本文提出了一个使用快速噪声估计谱减法、卷积神经网络(Convolutional Neural Network,CNN)和长短期记忆(Long-Short Term Memory,LSTM)网络的对话行为分类模型。该模型先将原始话语进行语音增强,再通过使用卷积神经网络将输入话语概括为嵌入向量,然后通过基于长短期记忆网络的上下文信息关联,使用对话行为标签来标注话语序列。在测试阶段,将分别用文献[2]与文献[4]的算法对包含噪声的语音样本进行测试并对比结果。
1 基于快速噪声估计的谱减法
快速噪声估计频谱相减的基本原理是在短期平稳语音信号和加性噪声之间彼此独立的假设前提下,将噪声的功率谱从包含噪声的语音功率谱中减去,从而得到更加纯净的语音频谱[7]。假设s(n)是纯语音信号,d(n)是噪音信号,y(n)是包含噪音的语音信号,那么可以得到以下表达式:
y(n)=s(n)+d(n)
(1)
Y(k),S(k)和D(k)分别表示y(n),s(n)和d(n)的离散傅里叶变换结果,如下所示:
Y(k)=S(k)+D(k)
(2)

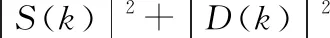
(3)
由于噪声信号与语音信号是彼此独立的,而且D(k)是服从E(D(k))的高斯分布,所以可以得到以下等式:
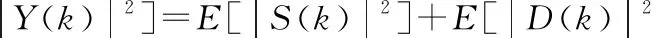
(4)
对于一个具有短时静止特性的语音信号来说,可以得到:

(5)

(6)
式中,|S(k)|为增强后的语音信号幅度。
在语音频谱中第k个频谱分量的增益函数定义为
(7)
并且后验信噪比的定义为
(8)
所以可以得到:
(9)
值得注意的是,当γ(k)>1且G(k)<0时,方程将变得无意义。为了避免这种情况,不妨进行以下改写:
(10)
式中,ε为一个大于0的常数。
从以上方程中可以得出, 频谱相减的本质是给噪声的每个含有噪声的频谱分量乘以一个系数G(k),G(k)的值与噪声呈正相关。在高信噪比的情况下有效语音信号的比重较大而噪声占比较小,因此G(k)是较小的。而在低信噪比的情况下G(k)较大。通过式(1)~式(3)将包含噪声的语音信号进行快速傅里叶变换,再通过式(4)~式(6)完成噪声参数估值,通过式(7)~式(10)可以计算获得语音增强后的增益,最后通过快速傅里叶逆变换即可得到增强后的语音信号,具体的流程框图如图1所示。
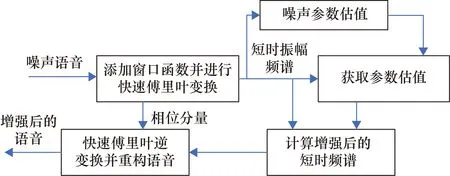
图1 快速噪声估计频谱相减的结构图
2 基于CNN和LSTM的语音分类模型
为了处理增强后的语音信号,笔者提出了一个使用卷积神经网络[8]和长短期记忆网络[9]的语音识别模型。模型利用卷积神经网络将输入话语转化为嵌入向量,然后利用基于长短期记忆神经网络的上下文信息匹配法对话语行为标签和话语行为序列进行注释。
设C1,n为一个包含n个对话的对话集,设S1,n为对话集内的一个语义,P1,n是一个包含了C1,n中谓语的集合。从而可以建立以下公式:
DA(C1,n)=argmaxS1.n,P1,nP(S1,n,P1,n|C1,n)
(11)
可以假设一句话的语义和一个谓语是相互独立的[10]。基于这个假设,将式(11)简化为
DA(C1,n)=argmaxS1.n,P1,nP(S1,n|C1,n)P(P1,n|C1,n)
(12)
式(12)又可以通过以下两个假设简化为式(13):
① 一阶马尔可夫假设,即当前类别(即当前语义或当前谓词)依赖于前一类别(即先前的语义或先前的谓语);
② 条件独立假设,即当前类别仅依赖于当前话语的观察信息。
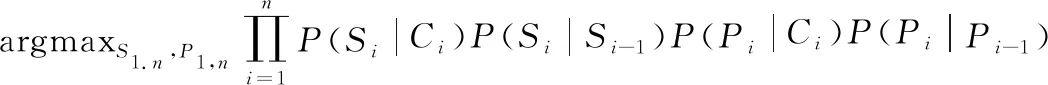
(13)
在式(13)中,由于说话人在真实对话中根据个人语言意义使用各种句子表面形式表达相同的内容,所以不可以直接计算P(Si|Ci)和P(Pi|Ci)。为了克服这个问题,本文使用CNN模型将说话人的话语概括为嵌入向量,如图2所示。
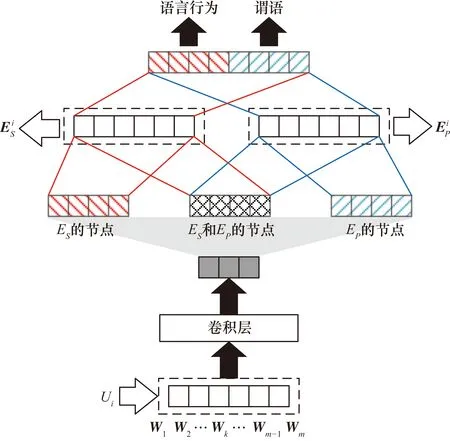
图2 使用CNN的语言嵌入

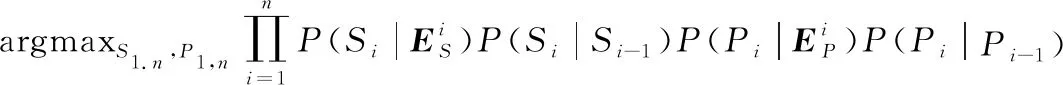
(14)
为了获得最大化方程(14)的序列标签S1,n和P1,n,本文采用LSTM模型,如图3所示。

图3 使用LSTM进行序列标记
3 实验与仿真
为了进行实验,测试人员收集了例如行程安排、日常活动、娱乐交际等方面的中文日常对话并加入初始语料库中[14]。通过删除初始语料库中日常对话的感叹词和错误表达来获得对话语料库。在对话中,一位参与者作为一个“用户”,随便地询问另一位参与者关于其每天的日程安排的问题,另一位参与者担任回答问题的“系统”,使用初始语料库提前提供的信息进行回答。共有4名测试人员扮演“系统”的角色。
获得的对话语料库由956组对话和21336句话语组成(每个对话22.3句话语)。用语义(11种)和预测(47种)在对话中手动注释每句话语。为了使用所提出的模型进行实验,将注释的语料库分成训练语料库和测试语料库,比例为9∶1,然后进行10倍交叉验证。
采用4种评估方法:准确率(Accuracy)、宏观精确率(Macro Precision)、宏观召回率(Macro Recall)和宏观F1度量(Macro F1-Measure)来评估所提出模型的性能。准确率是返回正确值的比例;宏观精确率是每个类别返回的正确值的平均比例;宏观召回率是每个类别正确返回值的平均比例;宏观F1度量将宏观精度和宏观召回率与以下形式的等量加权相结合:F1=(2.0×宏观精确率×宏观召回率)/(宏观精确率+宏观召回率)。
本文使用TensorFlow 1.4.0来实现模型训练,训练和预测都是以句子为最小单位完成的。将图3中每个Word2Vec嵌入向量的大小设置为50,训练长度为300个周期。通过小批量随机梯度下降法来寻找最佳模型,每个小批量包含15个句子,学习率固定为0.001。
测试用的实验电路由以下模块组成:输入前置放大器、增益调节为0~40 dB的校准电路、步进为5 dB的线性输出衰减器,以及范围为0~100 dB的SPL、50 Wclass-T数字功率放大器、PIC18F2550微控制器、一个2行×20个字符的显示器和一个键盘。
测试环境中包含两个位于45°处(测试人员的左侧和右侧)的麦克风和一个位于测试人员180°用于产生竞争噪声的扬声器,在两侧的麦克风处各放置一个录音设备,将测试人员发出的自然语言录下,用以分析。具体如图4所示。
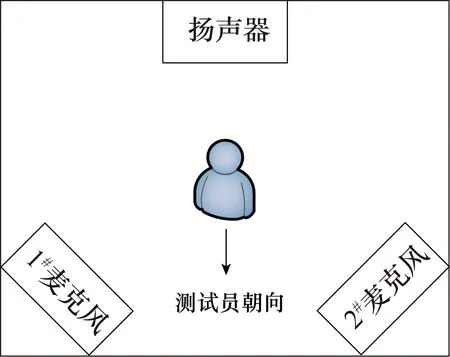
图4 测试环境
识别测试包含3种情况:
① 无噪声环境下的语句列表;
② 信噪比为0 dB噪声环境下的语句列表;
③ 信噪比为5 dB噪声环境下的语句列表。
将1号麦克风收集到的语音信号经过处理后输入给本文提出的语言分类模型,将2号麦克风收集到的语音信号经过处理后输入给先前文献的模型。对无噪声(对照)的测试结果与噪声在0 dB和5 dB比率下的准确率、宏观精确率、宏观召回率和宏观F1度量进行分析和比较。
4 结果分析
实验中的讲话部分在安静的环境中用麦克风记录,内容是“我下午去跑步”。通过16 ms采样的PCM编码将语音定量为数字信号,数据长度为12000 bit。得到了输入信噪比(0 dB和5 dB)与高斯白噪声成比例混合的噪声语音,然后利用128 bit交替的256 bit长(16 ms)汉明窗函数得到256 bit长的语音帧。在实验中分别采用普通谱减法与基于快速噪声估计的谱减法得到的降噪语音,比较模拟结果如图5和图6所示。
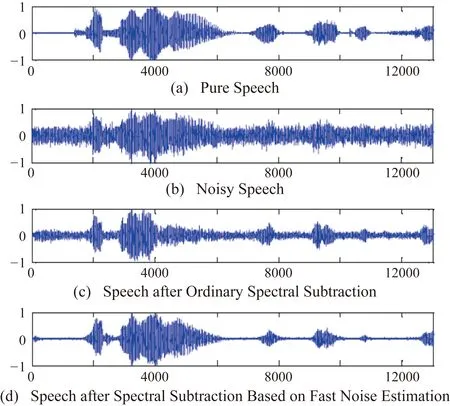
图5 输入信噪比为0 dB的信号时的模拟结果
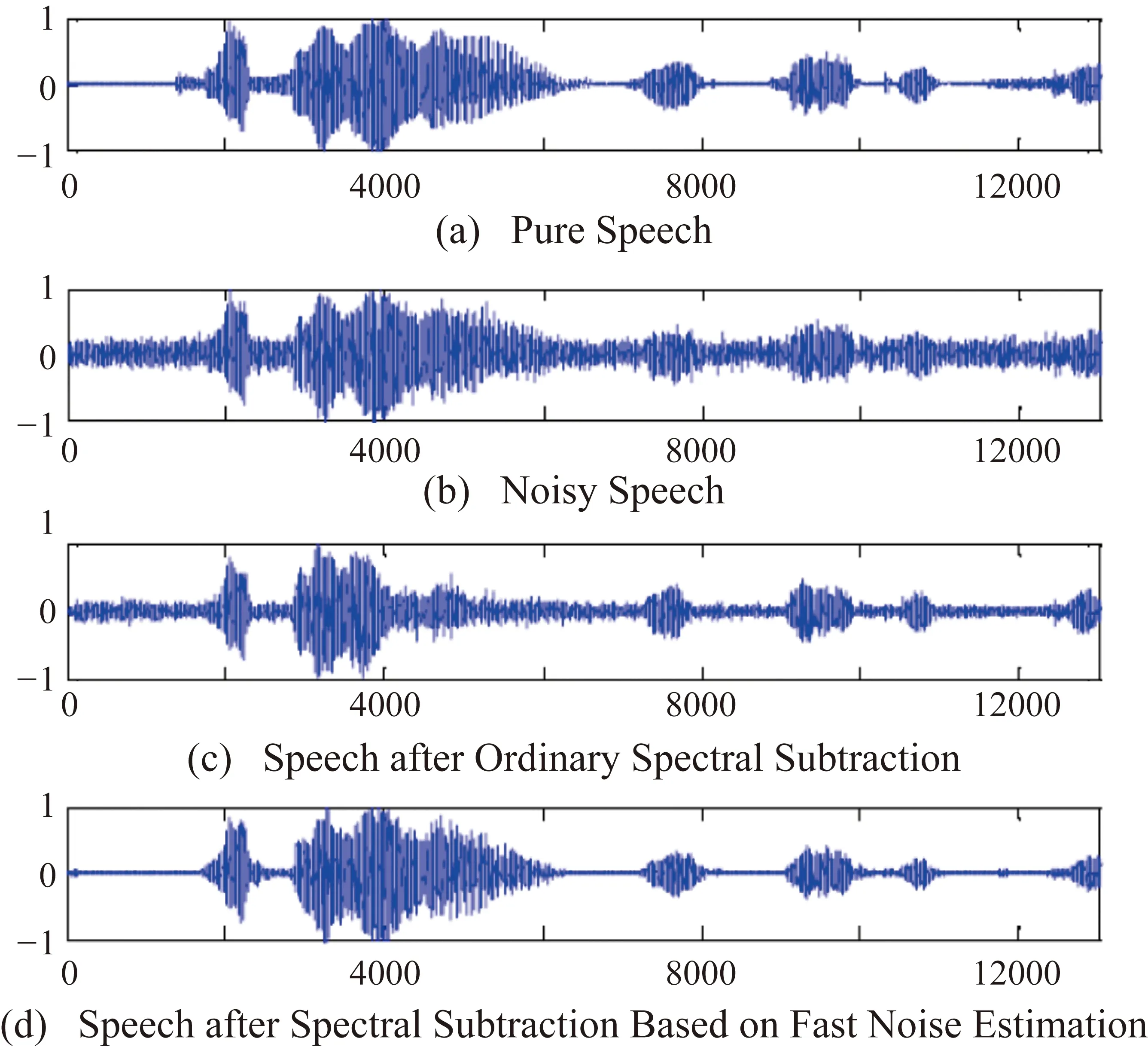
图6 输入信噪比为5 dB的信号时的模拟结果
与普通谱减法相比,基于快速噪声估计的谱减法显着提高了语音质量。它可以在背景噪音抑制中获得好的结果。它具有易于实施和计算量少的优点。该算法能够很好地估计非平稳环境下的噪声功率谱。
通过使用相同的训练和测试语料库比较不同信噪比的噪声环境对本模型性能的影响,结果如图7和图8所示。
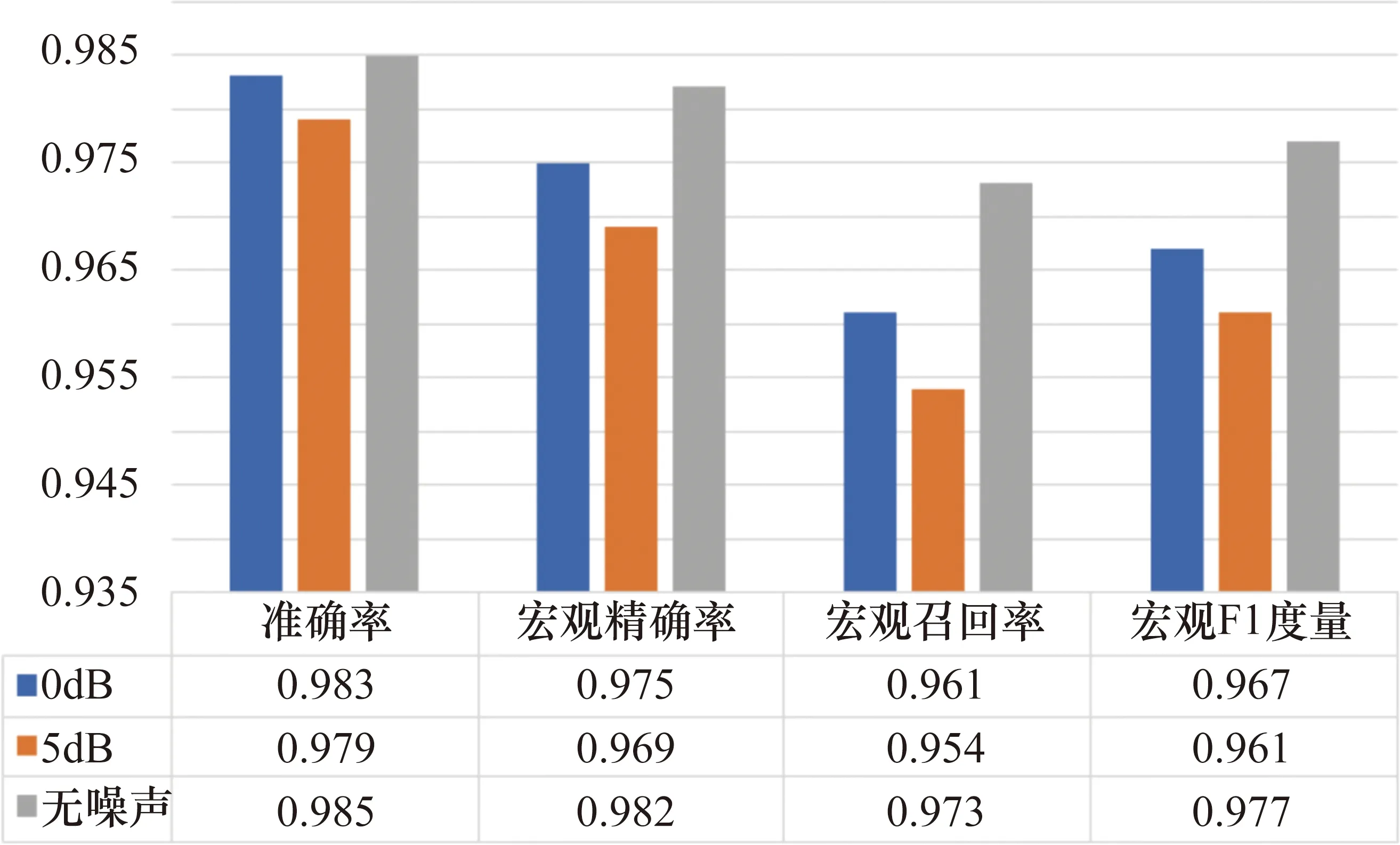
图7 模型在不同噪声环境下语义分类的表现
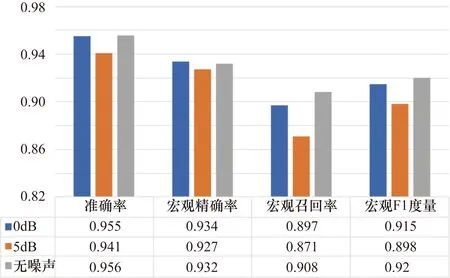
图8 模型在不同噪声环境下谓语分类的表现
在图7所示的语义分类中,噪声对宏观召回率的影响比较大,无噪声与5 dB信噪比环境之间产生了0.019的概率差,但在准确率方面噪声对模型产生的影响较小。图8所示的谓语分类结果则表现出模型具有较强的抗噪声能力,0 dB信噪比环境对模型产生的影响很微小,而在5 dB信噪比环境下也有较好的表现。
在0 dB信噪比环境下使用相同的训练和测试语料库将本文提出的模型与先前的模型进行比较。图9和图10显示了本文提出的模型和以前的模型之间的性能差异。
在图9中,文献[3]提出的模型是一个基于SVM的模型,其中最佳特征用于言语行为分类。在图9和图10中,文献[2]提出的模型是一个基于SVM的分类模型,其中通过使用相互再训练方法增加了语义识别和谓语识别的性能。文献[4]提出的模型是一个基于神经网络的综合模型,其中谓语识别的结果被用作语义识别的输入。如图9和图10所示,所提出的模型表现出比以前的模型更好的性能,并且没有进行任何特征工程。此外,本文提出的模型虽然没有采用任何二次训练方法来缓解语义与谓语之间的独立性假设,但其表现优于文献[2]提出的模型。这一结果显示出所提出的CNN体系结构(即与公共节点的部分连接)为缓解独立性假设提供了一些帮助。
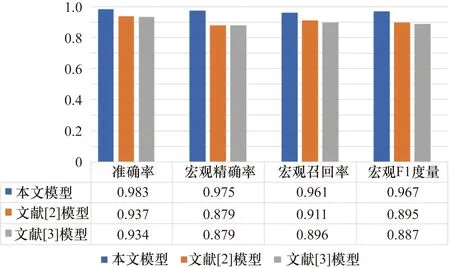
图9 0 dB噪声环境下语义分类的表现比较

图10 0 dB噪声环境下谓语分类的表现比较
5 结束语
本文为对话行为分类提出了一种深度神经网络模型。所提出的模型使用基于快速噪声估计的谱减法来进行语音增强;使用基于CNN的新的语言嵌入方法,以缓解语义和谓语之间的独立性假设;使用基于LSTM的序列标注方法来标注话语序列。在中文日常对话语料库的实验中,本文提出的模型在没有进行任何特征工程和二次训练的情况下,表现出了优于先前文献所提出模型的性能。
猜你喜欢
疯狂英语·初中天地(2022年1期)2022-07-07
疯狂英语·初中天地(2020年9期)2020-10-28
天津外国语大学学报(2020年1期)2020-03-25
中国机电工业(2016年5期)2016-12-01
湖南工业职业技术学院学报(2016年6期)2016-04-17
河南电力(2016年5期)2016-02-06
语言与翻译(2015年4期)2015-07-18
中国机电工业(2015年5期)2015-02-28
时代英语·高三(2014年5期)2014-08-26
中国工程咨询(2014年1期)2014-02-16
