
基于反馈式文本分类技术自动识别项目标签
2021-04-05 08:04谢波何凤
现代信息科技 2021年17期
谢波 何凤

摘 要:为对广东省投资项目在线审批监管平台积累的近40万个固定资产投资项目的产业类别进行分类,利于政府内部统计管理。在专家识别的人工打标签的方法基础上,进一步采用了线性支持向量机等分类算法,并基于反馈式文本分类机器学习原理再次识别了所有项目的标签类别,项目标签分类准确率由82%提升到91%。结果表明,反馈式文本分类技术,显著提高了项目分类的准确性。
关键词:项目标签;文本分类、词向量;分类器;线性支持向量机;反馈学习
中图分类号:TP181 文献标识码:A 文章编号:2096-4706(2021)17-0100-04
Abstract: In order to classify the industry categories of the nearly 400,000 fixed assets investment projects accumulated by the online approval and supervision platform for investment projects in Guangdong Province, it is conducive to the governments internal statistical management. Based on the manual labeling method recognized by experts, classification algorithms such as linear support vector machines are further adopted, based on the feedback text classification machine learning principle, the label categories of all items are recognized again, and the accuracy of project label classification has been improved by 82% to 91%. The results show that the feedback text classification technology significantly improves the accuracy of project labels classification.
Keywords: project label; text classification; word vector; classifier; linear support vector machine; feedback learning
0 引 言
长期以来,固定资产投资一直是推动经济增长最重要的驱动力,固定资产投资项目的分类统计是宏观经济运行状况的重要监测指标。广东省发展和改革委员会牵头建设的广东省投资项目在线审批监管平台,是投资项目统一办理登记赋码、在线审批、专项申报等服务的平台,自2018年上线使用,截至2021年7月底,积累了近40万个固定资产投资项目的赋码信息,包括项目名称、申报单位名称、规模及描述、国民经济行业类别,意向投资额等。这些项目信息由项目单位填报,难以准确的按领域、行业、产业等类别进行分类,不利于政府内部统计管理。并且固定资产投资分类统计一直较传统,主要基于国民经济行业,由于国民经济行业包括20个门类,类别较多,较难从宏观层面判别项目所属投资领域,有必要新增符合新时代特点的可灵活调整的投资分类标签,但是对40万个项目人工打标签,工作耗费低,本文将采用多类别文本分类技术,快速识别众多投资项目的标签类别,为项目自动打上基础设施项目、公共服务项目、产业工程项目、房地产项目、工业投资项目等一级标签,并对一级标签进行细分,形成标签体系。通过文本分类机器学习在投资项目领域的应用,不仅快速准确地为投资项目打上了标签,还可结合项目的其他数据特征,持续监测广东投资意向情况和相关行业投资运行情况,为完善投资宏观管理提供了决策支持。
1 研究方法概述
文本分类技术主要采用文本特征判断所属类别。对项目打标签,主要利用項目名称等文本信息判断项目所属类别。早期的文本分类方法主要为专家规则分类,通过匹配简要关键词或大量推理规则,判别文档所属类别。随着统计学习方法和机器学习方法不断改进,逐渐形成了将文本信息转换为空间向量模型,抽取特征工程,根据分类算法判断文本类别的方法。如文献[7]基于 word2vec词模型对中文短文本分类方法进行了研究,发现此方法可以有效进行短文本分类,最好情况下的F-度量提高45.2。文献[9]采用朴素贝叶斯对中文文本进行了,发现朴素贝叶斯在中文本分类方面有较好的分类效果和时间效率,平均准确率达81.4%。文献[12]基于SVM对中文文本分类反馈学习技术进行了研究,发现反馈学习是一种有效的学习方法,在少量反馈基础上,能较快提高分类性能。
由于在广东省投资项目在线审批监管平台中,仅省重点项目具有明确的项目分类标签,但这些分类标签不具有普遍适用性,难以适用于所有投资项目。为满足学习语料的充足性和适用性,需扩大样本数量,本文首先使用专家规则识别了大量项目作为训练和测试集,再采用逻辑回归、多项式朴素贝叶斯、线性支持向量机、随机森林等分类算法,构建最优的标签识别分类器,自动识别项目标签。这些分类算法本质上都是寻找最佳分类超平面,用差别对给定的一个数据进行分类,都属于监督学习算法,需根据已知类别学习分类模式用来判断新样本所属类别。但它们也有区别,逻辑回归是一个参数统计方法,朴素贝叶斯根据先验概率和后验概率判断样本属于某个类别的概率,SVM是一个几何的非参数统计方法,通过少数点学习分类器。随机森林是包含多个决策树的分类器,用规则判断所属类别。
2 基于文本分类的项目标签识别
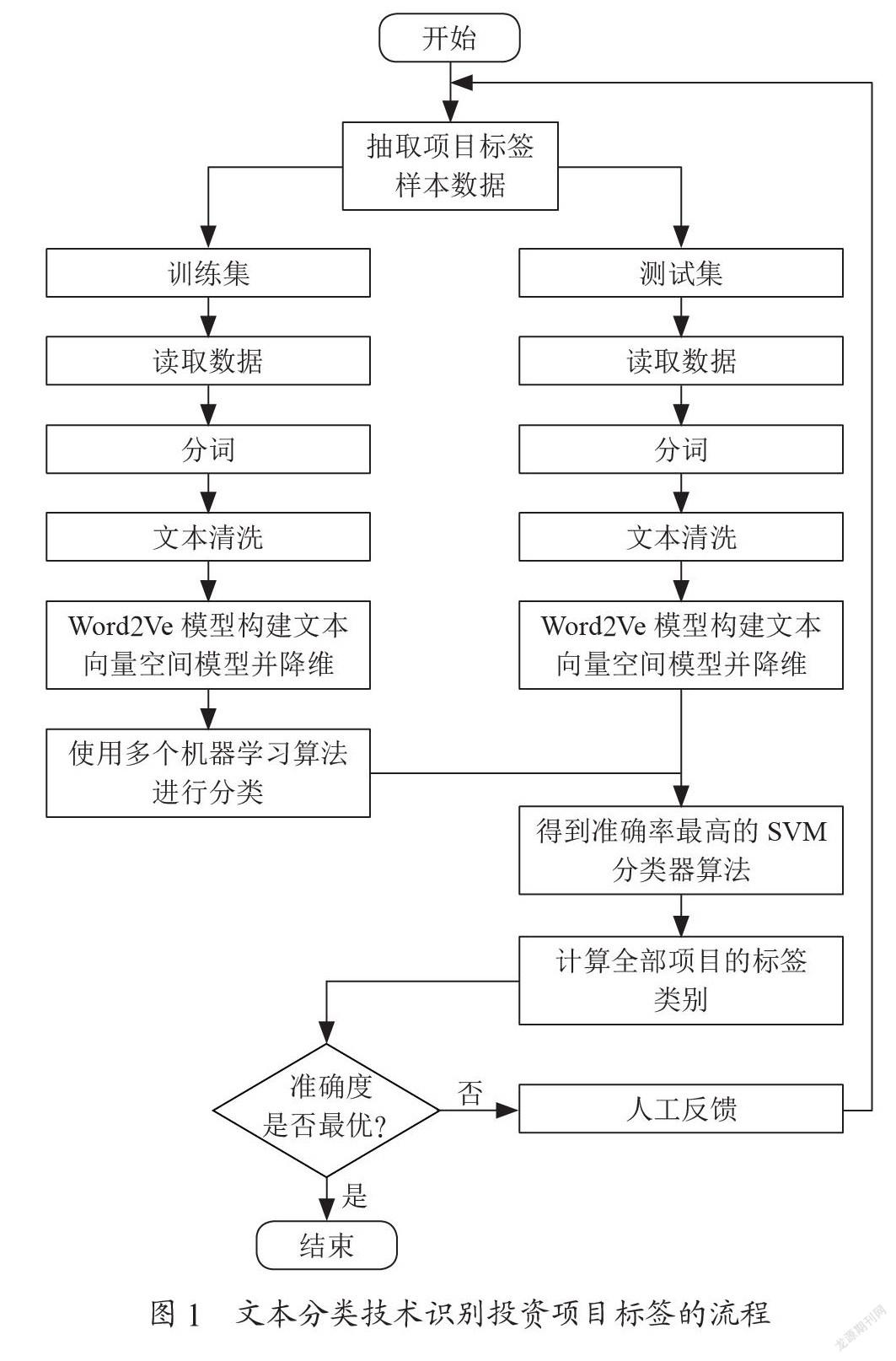
2.1 基于文本分类技术识别投资项目标签的流程
使用文本分类技术识别投资项目标签的具体流程如图1所示,首先通过专家规则法,识别了二十多万个投资项目的标签类别,以此作为样本数据。将其中的三分之二项目作为训练集,三分之一项目作为测试集,读取数据,进行分词、文本清洗后,将文本信息转换为向量空间模型并降维,再利用逻辑回归、朴素贝叶斯、支持向量机等分类算法构建项目标签识别模型,并通过比较获得了项目分类效果最好的算法。通过保存模型,识别全部项目标签后,再人工判断反馈,再次训练、测试,比较模型准确度是否有提升,获取分类准确度最高的模型,以此预测其他项目的标签类别。
2.2 项目标签分类器的具体构建过程
2.2.1 抽取项目标签样本
根据少量已知标签的项目信息,如项目名称、规模描述和建设单位名称,统计分析各类型项目的高频关键词,根据高频关键词、组合词和负面词等构建专家规则判断全部非个人投资项目的标签类别,再经人工甄别,共获得了216 826个样本,其中2 241个产业工程项目,34 925个房地产项目,70 169个工业投资项目,24 292个公共服务项目,85 199个基础设施项目,虽然项目类别分布不均衡,但适用于各类文本分类算法。将其中三分之二的项目数据作为训练集,三分之一作为测试集,采用不同分类算法构建项目标签识别模型,最后通过交叉统计验证,使用准确性最高的算法应用于全部投资项目和新项目的标签识别。
2.2.2 项目文本信息分词和文本清洗
为简化项目标签的机器学习过程,本文只采用项目名称这单一信息识别项目标签。第一步,先去除停用词,包括一些副词、地理信息词、形容词及其一些连接词。然后采用JIEBA分词技术,对清洗后的文本进行分词,提取项目的基本特征,构建特征向量。如项目名称为“粤西天然气主干管网茂名-阳江干线项目”,通过分词和文本清洗后只剩4个特征,为[天然气'','主干','管网','干线',],最大程度提炼文本主干信息,降低向量维度,从而减少分类计算难度,提升模型训练速度。
在对所有类别的项目进行分词后统计,发现各类别之间的关键词差异较大,组内一些關键词具有关联性,如基础设施项目主要为污水处理、道路修建,环节整治、改造和提升等关键词。工业投资主要为技术改造、生产线、年产、光伏、生产等关键词。房地产主要为花园、社区、装修、地块等关键词、公共服务主要为校区、学校、医院、中心等关键词,产业工程项目主要为现代农业、智慧、产业园等关键词。各类型项目文本特征较明显,相关关键词可组合使用,提升识别概率,从项目名称着手,能较好地建立分类算法识别项目类别。
2.2.3 构建文本向量空间模型并降维
对项目文本提取特征值后,如果将所有特征都放进分类器用于判别文本类别,由于维度过高,过于稀疏,模型的效果并不佳。特别是在分类速度上,由于经过多个特征值的组合,特征空间将无限扩大,模型需要学习的参数数量也增加,导致耗时过多。本文采用卡方检验提取特征,卡方检验的目的是计算每个特征对分类结果的相关性,相关性越大则越有助于分类器进行分类,否则就可以将其作为无用特征抛弃。
经过对21.7万样本数据进行分词后,通过卡方检验共获取了53.6万个特征,并用卡方检验找出了每个分类中关联度最大的两个词语和两个词语对。如:与“基础设施”关联度最大的2个词语为整治和道路,最有关的2个关联词语对为[综合、整治]、[污水、处理厂]。与“工业投资”关联度最大的2个词语为生产线、技术改造,最有关的2个关联词语对为[光伏、发电]、[分布式、光伏]。与“房地产”关联度最大的2个词语为商业楼、花园,最有关的2个关联词语对为[老旧、小区]、[小区、改造]。与“公共服务”关联度最大的2个词语为医院、中学,最有关的2个关联词语对为[学生、宿舍楼]、[人民、医院]。 与“产业工程”关联度最大的2个词语为智慧、产业园,最有关的2个关联词语对为[冷链、物流园]、[现代农业、产业园]。
找出特征后,为了方便统计计算各类别之间的距离,需要将文本信息转换为词向量空间模型表示的数字格式,早期的词袋模型,将所有文本的所有词表示为向量维度,词越多,维度越大,向量模型为每个文档词的频率。且词袋模型不考虑词的语义和语序,会损失一些语义上的特征信息。为了克服词袋模型无法表示文本语义的缺陷和维度灾难,文本采用Word2Ve模型,将文本信息转化为向量空间模型。该模型采用单层神经网络将高维度的向量转换成低维度的词向量,将每个词转化为词向量,能够较好地考虑上下文语义信息,同时可以避免维度“灾难”问题。
2.2.4 构建多类别标签识别算法
将各类投资项目的项目名称转换为词向量空间模型后,分别使用逻辑回归、多项式朴素贝叶斯、线性支持向量机、随机森林4个分类算法构建项目多类别标签识别模型,经测算后,线性支持向量机的分类算法模型准确度最高为74.7%,其次为逻辑回归73.7%,多项式朴素贝叶斯为69.3%,随机森林的准确率最低为39.3%。最终采用线性支持向量机模型对预先抽取的三分之一样本进行测试,模型准确度为82.9%,分类效果良好,特别是工业投资、公共服务和基础设施标签的分类准确度,达85%左右,实际项目数和预测项目数如表1所示,支持向量机模型的预测准确性如表2所示。
2.3 关于反馈学习后文本分类效果分析
通过对最初的216 826个样本进行人工反馈,剔除了8个测试项目,最后只剩下216 818个样本。并规范了标签分类的定义,如燃气管、供水管的铺设属于基础设施项目,燃气发电、水生产属于工业投资,消防、公园、卫生站的建设属于公共服务,旧村改造、加装电梯、新建楼盘属于房地产等,结合规则和机器学习判别的项目标签,共反馈修正了4万个项目的原始标签,产业工程项目由之前的2 241个,反馈后为2 181个;房地产项目由之前的34 925个,反馈后为21 191个;工业投资项目由之前的70 169个,反馈后为65 270个;公共服务项目由之前的24 292个,反馈后为35 132个;基础设施项目由之前的85 199个,反馈后为93 044个。
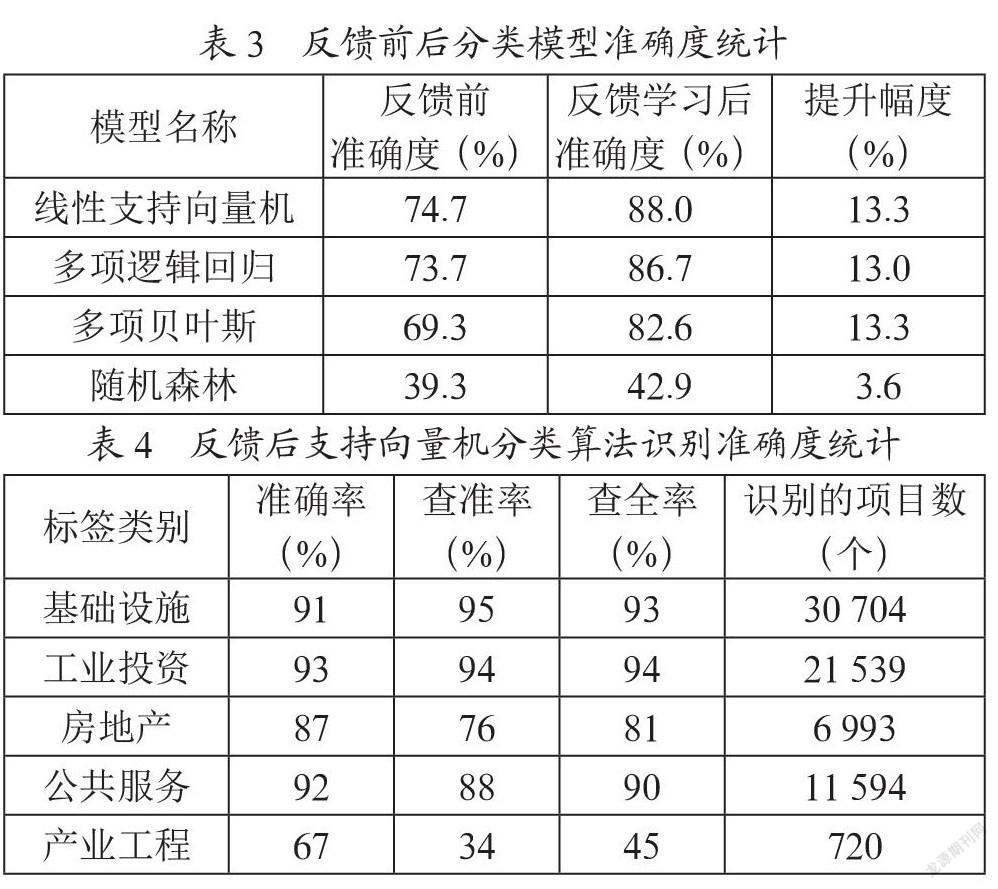
使用逻辑回归、多项式朴素贝叶斯、線性支持向量机、随机森林4个分类算法重新构建项目多类别标签识别模型后,模型的准确度变化如表3所示。
通过实验发现,反馈学习有效提高了文本分类的准确性,通过对少量项目的标签反馈和修正,模型的分类性能显著提升,线性支持向量机的分类算法由74.7%提升至88%,提升了13.3%。将模型训练的分类规则应用至测试样本,支持向量机在样本反馈后的表现如表4所示。
经反馈学习后,再使用线性支持向量机分类算法判别项目标签,各类别的准确率都有显著提升,特别是房地产,标签识别准确度由77%提升到87%,基础设施、工业投资和公共服务的识别准确度,目前已提高至90%以上。由于产业工程的项目数量较少,易被判别到其他标签,识别难度较大,准确率由65%仅提升至67%。后续过程中将进行有效反馈,持续提升标签识别准确度。
3 结 论
综上所述,本文基于文本分类技术研究了固定资产投资项目的分类,以多个标签分类为例分析了固定资产投资项目分类模型的实际效果,结果表明,利用数据分析技术、分词分析法等进行投诉工单文本挖掘,突破了既有分类模糊不清的限制。
经测算,投资项目的文本信息使用线性支持向量机算法进行标签分类效果最佳,目前测试样本总体识别准确率达90%以上。
本次在人工反馈的基础上,模型准确度由74.7%提升至88%,在后续工作应用中,将继续把人工反馈的信息增加至样本集中,以修正学习源,训练出更加准确的规则,提高模型准确度,经过不断反馈学习,实现分类的最大提升。
在实现项目大类标签的识别后,将再次对各类标签进行细分,划分为各领域各类型的二级标签,同样适用机器学习的训练模式不断识别、反馈、提升,快速识别各类二级标签,为研究项目的细分领域提供分析维度。
参考文献:
[1] 苏金树,张博锋,徐昕.基于机器学习的文本分类技术研究进展 [J].软件学报,2006(9):1848-1859.
[2] 杨丽华,戴齐,杨占华.文本分类技术研究 [J].微计算机信息,2006(15):209-211.
[3] 汪家成,薛涛.基于FastText和关键句提取的中文长文本分类 [J].计算机系统应用,2021,30(8):213-218.
[4] 于游,付钰,吴晓平.中文文本分类方法综述 [J].网络与信息安全学报,2019,5(5):1-8.
[5] 马思丹,刘东苏.基于加权Word2vec的文本分类方法研究 [J].情报科学,2019,37(11):38-42.
[6] 孙桂煌.基于大数据技术的中文多标签文本分类方法研究 [J].齐齐哈尔大学学报(自然科学版),2020,36(6):39-43.
[7] 高明霞,李经纬.基于word2vec词模型的中文短文本分类方法 [J].山东大学学报(工学版),2019,49(2):34-41.
[8] 方秋莲,王培锦,隋阳,等.朴素Bayes分类器文本特征向量的参数优化 [J].吉林大学学报(理学版),2019,57(6):1479-1484.
[9] 潘忠英.朴素贝叶斯中文文本分类器的设计与实现 [J].电脑编程技巧与维护,2021(2):37-39+70.
[10] 刘硕,王庚润,李英乐,等.中文短文本分类技术研究综述 [J].信息工程大学学报,2021,22(3):304-312.
[11] 栗征征.中文文本分类概述 [J].电脑知识与技术,2021,17(1):229-230.
[12] 孙晋文,肖建国.基于SVM的中文文本分类反馈学习技术的研究 [J].控制与决策,2004(8):927-930.
作者简介:谢波(1983—),男,汉族,湖南常德人,投资项目部部长,高级工程师,硕士,主要研究方向:电子政务建设、信用体系建设、投资项目管理;何凤(1988—),女,汉族,湖南汨罗人,信息系统项目管理师,高级工程师,硕士,研究方向:信息系统项目管理、数据分析和挖掘、数据治理、数据可视化。
猜你喜欢
计算机时代(2022年9期)2022-11-03
现代电子技术(2022年15期)2022-07-28
电子产品世界(2022年4期)2022-04-21
软件导刊(2017年4期)2017-06-20
高中生学习·高三版(2017年6期)2017-06-12
计算机应用(2016年12期)2017-01-13
电子技术与软件工程(2016年22期)2016-12-26
数字技术与应用(2016年9期)2016-11-09
电脑知识与技术(2016年23期)2016-11-02
科教导刊·电子版(2016年23期)2016-10-31
