
基于计算机图像识别的垃圾智能分类
2021-04-05 07:25李天千陈志鑫黄桂鑫温森荣黄思琪
现代信息科技 2021年17期
李天千 陈志鑫 黄桂鑫 温森荣 黄思琪

摘 要:为提高垃圾分类效率,应对日益繁杂的垃圾分类工作,使垃圾分类智能化,高效化。运用卷积神经网络解决垃圾分类问题,对YOLOv3基础算法进行研究改进,并制作垃圾种类数据集,结合参数迁移学习训练垃圾分类识别模型。实验表明样本多的种类识别准确率较高,而对于样本少的种类,准确率就下降了。相较于现有常用的垃圾分类识别算法,所提出的垃圾分类识别算法,识别性能更优,更适合广泛推广应用。
关键词:垃圾检测;数据集制作;YOLOv3算法
中图分类号:TP181 文献标识码:A 文章编号:2096-4706(2021)17-0092-04
Abstract: In order to improve the efficiency of garbage classification, deal with the increasingly complicated garbage classification work, and make garbage classification intelligent and efficient. Use convolutional neural network to solve the garbage classification problem, research and improve the basic algorithm of YOLOv3, and make a garbage type data set, combined with parameter transfer learning to train the garbage classification and recognition model. Experiments show that the recognition accuracy of the types with a large number of samples is higher, while for the types with a small number of samples, the accuracy is reduced. Compared with the existing commonly used garbage classification and recognition algorithms, the proposed garbage classification and recognition algorithm has better recognition performance and is more suitable for wide promotion and application.
Keywords: garbage detection; data set production; YOLOv3 algorithm
0 引 言
垃圾分類是推动我国新型城镇生态文明水平提高的一大重要举措。党的十九届五中全会擘画了党和国家未来五年乃至更长时期各项事业发展的宏伟蓝图,明确了发展的目标和路径,其中对垃圾分类问题提出了新的要求,表现垃圾处理正处于一个新的台阶,2021年是“十四五”开局之年,针对垃圾类问题如何再有新突破,是我们共同面对的社会性问题。对此,垃圾分类重在按一定规定或标准,将垃圾分类储存、投放和搬运,使其变为一种公共资源的做法,而人们在处理生活垃圾分类时对垃圾类型问题处理不当,将会导致分类处理垃圾工作效率低下,甚至造成超出预期的经济损失和环境破坏。
对此,在大数据环境下,结合当前的计算机视觉知识,本文对垃圾识别进行了一定的研究。基于深度学习的目标检测算法的基本原理是利用大量卷积运算实现检测算法自主对目标图像的特征进行抽象和提取,并且对检测到的特征进行训练从而总结出其他的特征,在检测计算机数字图像上发挥着重大的作用。深度学习检测算法主要分成两种,两步检测法和单步检测法,两步检测法主要代表为基于区域的卷积神经网络(Region-based Convolution Neural Networks, R-CNN)算法以及对其改进的算法如:Fast R-CNN和Faster R-CNN。而单步检测算法是将区域选择和检测判断结合在一起,构成一体化的检测网络,单步检测法的主要代表为:SSD(Single Shot multibox Detector)算法和YOLO (You Only Look Once)检测算法。深度神经网络结构复杂,目前对检测效率的要求较高,深度学习构架内的许多算法都在进行改进,本文及研究主要用YOLO系列检测算法,在YOLO系列算法中,YOLOv3算法超越了YOLO和YOLOv2在各方面都相对进行了改进,如:运行速度、网络学习深度、检测准确率等。本文基于图像目标检测对生活垃圾进行识别,主要运用了性能更好的YOLOv3检测算法。如今生活处处充满人工智能,科技结合环卫,在大数据时代,拍照识别搜索是生活常态,本文针对垃圾分类技术对目标检测技术进行研究,主要用YOLO检测算法实现目标检测识别,致力于实现垃圾分类识别,提高垃圾分类工作的效率和准确度。
1 YOLOv3算法
1.1 YOLOv3模型结构
YOLOv3是YOLO系列算法中在YOLOv1与YOLOv2的基础上的改进版本,在精确度与速度的权衡中发展出来。YOLOv3仅使用卷积层,可以说是一个全卷积网络。
YOLOv3其网络结构图如图1所示,该网络借鉴了darknet-53的前52层,去除了最后的全连接层,大量的使用了残差的跳层连接。在之前的网络中,采样是使用size为2×2,stride为2的max-pooling或average-pooling进行降采样。但在这网络中,使用的则是stride为2的卷积来降采样。与此同时,还在网络中使用了上采样、route操作等,并且在一个网络中进行了3次检测。
为了保证分类加检测的效果更好,且由于网络的深度与其所表达的特征是相辅相成的,所以我们需要采用残差的跳层连接来提高网络的深度,使得网络在更深的情况下继续收敛下去,并使得模型能够继续训练。而在最后残差中的1×1卷积,使用的是network in network的想法,该想法减少了每次卷积的channel数,这起到了减少参数量和减少工作的计算量。
网络中作者分别在32倍降采样,16倍降采样,8倍降采样时进行了检测,这样在多尺度的feature map上检测跟SSD有点相似。
在网络中使用上采样是因为,直接使用下采样的浅层特征来检测,其表达效果不如先用下采样后用上采样的深层特征。因为越深的网络其表达效果就越好。像比如在进行16倍降采样时,使用五次下采样后的32倍降采样,其深层特征比较小不好使用,这时候给它进行布長为2的上采样后得到的16倍降采样特征,会比直接使用四次下采样后的16倍降采样特征的表达效果更好。同理8倍降采样也是对16倍降采样进行一次步长为2的上采样,这样得到的深层特征就可以用来detection。
YOLOv3利用上采样可以使得16倍降采样和8倍降采样使用深层特征。而直接进行四次下采样的16倍降采样和直接进行三次下采样的8倍降采样的浅层特征与采用了上采样的深层特征的feature map大小是一样的。为了能够利用这些浅层特征,YOLOv3诞生了route层,它把上采样后的16倍降采样的feature map与直接四次降采样的feature map在channel那里进行拼接。同理8倍降采样也是如此操作。这样做的好处是使得网络能够同时学习浅层特征和深层特征,其表达效果会更好。
1.2 边界框预测
预测类别时,为了满足多标签对象这一条件,在预测类别时,使用了logistic回归代替softmax回归。softmax回归的前提是各类别分类是相互独立的,这种前提在某些时候是没有意义的,因此YOLOv3使用logistic回归来预测。通过logistic预测每个类别得分并使用一个阈值来对目标进行多标签预测,而阈值高的类别是该边界框的真正类别。为了减少后续计算量,logistic回归在进行predict前,去掉了不必要的anchor。而如何去除不必要的anchor,首先logistic回归会对anchor所包围区域都进行目标性评分(objectness score),评分低的anchor将会被淘汰。因此即使被淘汰的anchor区域的值高于我们所设定的阈值,我们也不会对它进行predict。不同于faster R-CNN的是,YOLOv3只会对最佳的模板框进行操作。而logistic回归在这一过程中的作用便是:从9个anchor priors里选出objectness score(目标存在可能性得分)最高的那一个。
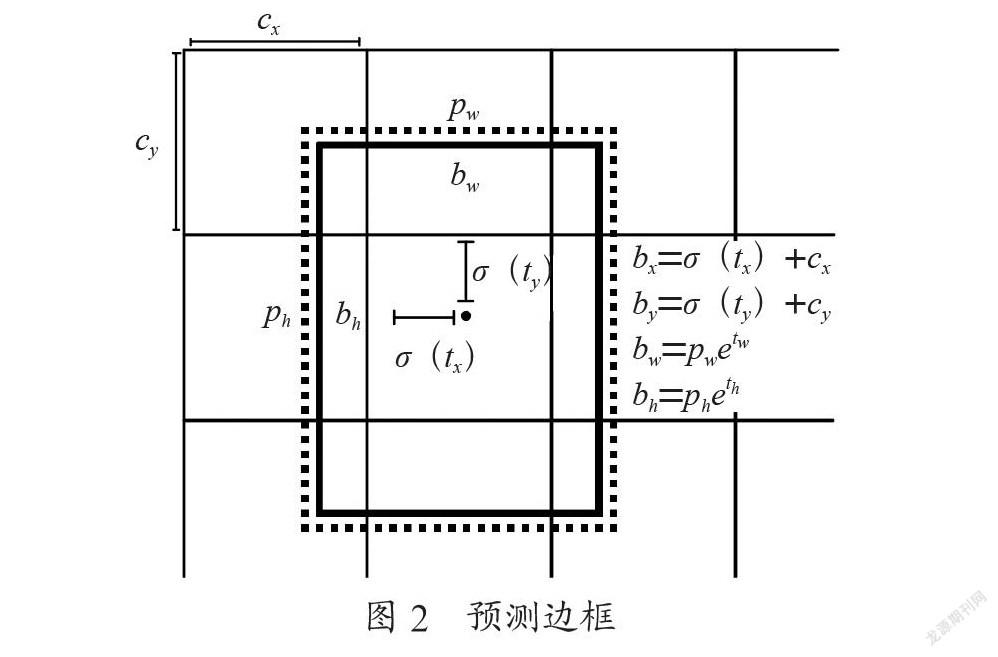
YOLOv3的bounding Box由YOLOv2又做出了更好的改进,如图2所示。在YOLOv2和YOLOv3中,都采用了对图像中的物体进行k-means聚类。 特征图中的每一个cell都会预测3个bounding box,总共有(52×52+26×26+13×13)×3=10 647个预测框。每个bounding box都会预测三个东西:(1)每个框的位置,即中心坐标为(tx,ty),框的高和宽分为别bh和bw。(2)一个objectness prediction。(3)N个类别,coco数据集80类,voc20类。
由于三次检测所对应的感受野不同,而最大的32倍降采样的感受野适合检测大的目标,因此当输入为416×416时,每个cell所对应的三个anchor box分别为(116,90),(156,198),(373,326)。由于16倍适合一般大小的物体,所以anchor box为(30,61),(62,45),(59,119)。而8倍的感受野最小,适合检测小目标,因此anchor box为(10,13),(16,30),(33,23)。
YOLOv3对(4+1+c)×k个大小为11的卷积核进行卷积预测,其中,每个参数都有其特定的意思。k为预设边界框(bounding box prior)的个数,其值默认为3;c代表着预测目标的类别数;4k个参数则用来检测目标边界框的偏移量;k个参数用来预测目标边界框内包含目标的概率;最后,用ck个参数则来预测这k个预设边界框所对应的c个目标类别的概率。图2展示了目标边界框的预测过程。图中的虚线部分为预设边界框,通过网络预测的偏移量计算得到的预测边界框为实线矩形框。中心坐标为(cx,cy),预设边界框的宽和高分别为(pw,py),(tx,ty,tw,th)分别为网络预测的边界框中心偏移量(tx,ty)以及宽高缩放比(tw,th),而最终所预测的目标边界框则为(bx,by,bw,bh)。
2 基于Tensorflow2的YOLOv3算法垃圾识别
2.1 图像数据的获取
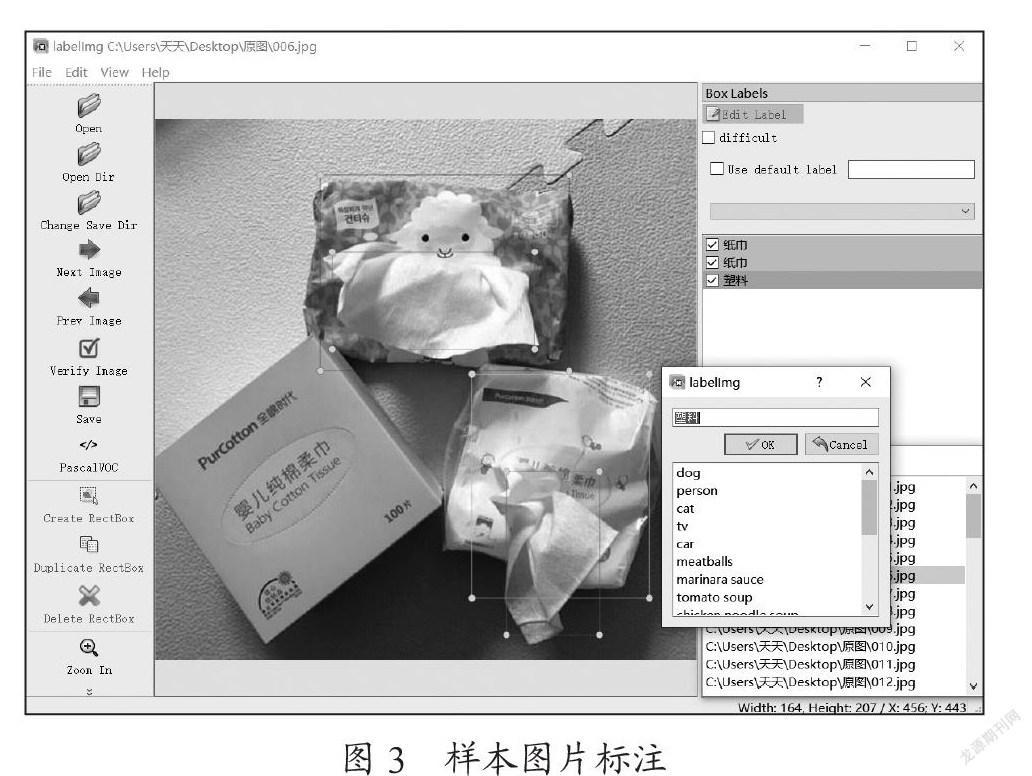
本次实验将垃圾分为四大类:厨余垃圾,可回收垃圾,有害垃圾。具体采集方法,利用网络爬虫技术在各大图片搜集网站搜索所需的图片,并对图片进行自动排序命名为0001.jpg、0002.jpg……,在进行手工筛选的同时,对这些图片进行预处理,由于收集到的图片中,有些受天气等外界影响较大,需对得到初始数据集后进行去噪和增强处理,使得图片中的特征更加明显,最后利用labellmg对样本进行手动标记。
2.2 数据集标注
通过利用labellmg对爬取的样本图片进行标注,如图3所示。并将所标记图片依次保存为XML文件。由于仪器设备的限制,本次我们主要对可回收垃圾进行样本标注,在这些样本中纸巾和塑料的占比大,其他类型占比小。
3 结 论
经过实验,发现没有检测框的图片,均是数据集中样本类型较少的可回收垃圾,而有检测框的可回收垃圾的图片中,样本数较多的纸巾辨识度较高。
因此可知:(1)数据集的数量对目标检测有影响。(2)训练时的迭代次数增加可降低loss,对目标检测有影响。(3)在运行代码过程中发现,适当调整置信度和IOU,能够影响图像检测的检测框。
参考文献:
[1] 刘智嘉,汪璇,赵金博,等.基于YOLO算法的红外图像目标检测的改进方法 [J].激光与红外,2020,50(12):1512-1520.
[2] 林红兵.“十四五”时期垃圾分类的机遇与展望 [N].中国建设报,2020-11-16(8).
[3] 郝楠.基于深度学习的公路障碍物检测的研究 [D].成都:电子科技大学,2019.
[4] 张奇.基于改进YOLO的小目标检测算法应用研究 [D].长春:吉林农业大学,2020.
[5] 彭伟航,白林,商世为,等.基于改进InceptionV3模型的常见矿物智能识别 [J].地质通报,2019,38(12):2059-2066.
[6] 单宇翔,龙涛,楼卫东,等.基于深度学习的复杂场景中卷烟烟盒检测与识别方法 [J].中国烟草学报,2021,27(5):71-80.
作者简介:李天千(2000—),女,汉族,陕西渭南人,本科在读,主要研究方向:深度学习、图像处理。
