
lmage Classification with Superpixels and Feature Fusion Method
2021-04-02 12:26
Abstract—This paper presents an effective image classification algorithm based on superpixels and feature fusion.Differing from classical image classification algorithms that extract feature descriptors directly from the original image,the proposed method first segments the input image into superpixels and,then,several different types of features are calculated according to these superpixels.To increase classification accuracy,the dimensions of these features are reduced using the principal component analysis (PCA) algorithm followed by a weighted serial feature fusion strategy.After constructing a coding dictionary using the nonnegative matrix factorization (NMF) algorithm,the input image is recognized by a support vector machine (SVM) model.The effectiveness of the proposed method was tested on the public Scene-15,Caltech-101,and Caltech-256 datasets,and the experimental results demonstrate that the proposed method can effectively improve image classification accuracy.
1.Introduction
Image classification is an important artificial intelligence task[1]-[4].As the number of images from the Internet increases,it is becoming increasingly difficult to recognize the correct categories of input images due to their differences in scales,viewpoints,rotations,and cluttered background.To solve these problems,many studies have introduced various efficient algorithms and models,such as the bag-of-words (BOW) model[5],sparse coding (SC)algorithm[6],[7],support vector machine (SVM) model[8],and deep learning (DL)[9]-[12].
Over the past ten years,the BOW model has been widely applied in image classification and many effective algorithms have been proposed.For example,Yanget al.introduced spatial pyramid matching using the sparse coding (ScSPM) model and applied the SC algorithm to calculate nonlinear codes[6].Yuet al.discussed a local coordinate coding (LCC) mechanism and localized SC[13],and Wanget al.changed the constraint from SC to locality,and feature vectors were mapped through linear coding[14].
During the past five years,DL models have seen significant progress because of their powerful learning abilities,especially when dealing with large datasets[15].For example,Zhanget al.proposed an image classification method based on a deep SC network[9],and Barat and Ducottet introduced deep convolutional neural networks(CNNs) with string representations for classification[16].
While BOW and DL models have unique limitations,other strategies have been introduced in recent years,e.g.,the heterogeneous structure fusion method[17]and multi-modal self-paced learning (MSPL) algorithm by Xuet al.[18].
In this paper,we propose an image classification algorithm with superpixels and feature fusion.Our primary contributions are summarized as follows.
1) Differing from most classical image classification algorithms that extract local features directly from the input image,the proposed method calculates the superpixels of the original image using the fast graph-based segmentation algorithm,and all features are extracted based on these superpixels.
2) The final representation features are constructed using a strategy of weighted serial feature fusion of global,texture,and appearance features.
3) Codebook is an important part in the BOW model.In most of the algorithms,the codebook is learned by one specific feature,such as the local feature of the scale-invariant feature transform (SIFT) and the global feature of GIST.In this paper,the codebook is learned using fused SIFT,GIST,and color thumbnail features.
The effectiveness of the proposed method was tested on the public Scene-15,Caltech-101,and Caltech-256 datasets,and the experimental results demonstrate that the proposed method can effectively improve image classification accuracy.
The remainder of this paper is organized as follows.Section 2 discusses the proposed image classification method in detail,and Section 3 discusses experiments conducted to evaluate the effectiveness of our algorithm.Finally,Section 4 concludes the paper.
2.Proposed Method
An outline of the proposed image classification method based on superpixels and feature fusion is shown in Fig.1.In the proposed method,the input image is first segmented into superpixels using a fast graph-based segmentation algorithm.Then,three different types of features are applied to these superpixels to extract the global,appearance,and texture features.To increase classification accuracy,the principal component analysis (PCA) dimension reduction method is applied to the calculated features,and the final feature descriptors of each superpixel are constructed via weighted feature fusion.According to the learned hybrid features,a codebook is constructed using the nonnegative matrix factorization (NMF)algorithm,and the input image is recognized using an SVM model after SC.
In the following,we will describe the proposed image classification method in detail.

Fig.1.Outline of proposed image classification algorithm.
2.1.Superpixel Extraction
The features in most image classification algorithms are extracted from the pixels of the input image.In the proposed method,the input images are recognized based on superpixels.
Superpixels are the sets of neighboring pixels with a homogeneous property in remote sense images.It is highly likely that all pixels in the same superpixel belong to an identical class in an image classification task.Therefore,superpixels well express the spatial contextual information of the original image.Superpixels can be obtained using a segmentation algorithm,e.g.,graph-based,normalized cut (NCut),Turbopixel,quick-shift,and simple linear iterative clustering (SLIC) algorithms.In the proposed method,superpixels are calculated based on the fast graph-based segmentation algorithm introduced by Felzenszwalb and Huttenlocher[19].
2.2.Feature Extraction
Feature extraction is a significant step in the BOW model,and many features have been widely used in different studies,e.g.,local features,histogram features,texton features,curvature features,SIFT features,and histogram of oriented gradient (HOG)features.In the proposed algorithm,we select three types of features to describe superpixels,i.e.,global,appearance,and texture features.The details of the selected features are shown in Table 1.As shown,the GIST feature is employed as the global feature,the dilated SIFT histogram feature is the texture feature,and the color thumbnail is the appearance feature.The GIST feature comprises three-channel red,green,blue (RGB) and three scales.The size of the color thumbnail is 8 × 8 pixels.The dimensions of the global,texture,and appearance features are 960,100,and 192,respectively.

Table 1:Superpixel features in proposed algorithm
2.3.Dimension Reduction
After features extraction,the calculated features contain useful information with strong representations and redundant information.Selecting a meaningful description of the input data and eliminating redundant components to achieve a compact expression of the data is a specific task in classification problems,and PCA is a common dimension reduction technique.The main idea of PCA is performing orthogonal transformation to the basis of correlation eigenvectors and projecting them into the subspace expanded by the eigenvectors corresponding to the largest eigenvalues[20].
We employ the PCA algorithm proposed by Kambhatla and Leen[20]to reduce the dimensionality of image features.
2.4.Feature Fusion
The feature fusion technique is widely used in many areas,e.g.,image processing and classification.Feature fusion attempts to extract the most discriminative information from several input features and eliminate redundant information.Feature fusion algorithms in the image classification area can be categorized into two basic classes,i.e.,serial feature fusion and parallel feature fusion.
Here,letX,Y,andZbe three feature spaces,Ωbe the pattern sample space,andξbe a randomly selected sample inΩ.In addition,α,β,and γ are the feature vectors ofξ,where α∈X,β∈Y,and γ∈Z,respectively.
According to the serial feature fusion strategy,the definition of a combined feature is given in (1),whereηis the serial combined feature.If the dimensions of α,β,and γ aren1,n2,andn3,respectively,then the dimension of η is given as (n1+n2+n3).

The parallel feature fusion strategy ofξcan be expressed by the complex vector given in (2),where i and j are imaginary units.If the dimensions of α,β,and γ are not equal,lower-dimensional features should be padded with zeros,so that all the features will have the same dimension prior to being combined.

In the proposed method,we modify the serial feature fusion strategy and attempt to combine three feature vectors using a weighted serial feature fusion algorithm.Specifically,we define the feature vectors of the global,appearance,and texture features after normalization as f1,f2,and f3,respectively.Then,the fusion feature F can be obtained by (3),wherew1,w2,andw3are the weights of f1,f2,and f3,respectively.

The values of weightsw1,w2,andw3are set by the single recognition rate of f1,f2,and f3,which are denoted byA1,A2,andA3,respectively.We calculatew1,w2,andw3using (4) to (6).

2.5.Codebook Learning
Codebook learning is an important step in the BOW model.It directly determines both the image representation quality and image classification accuracy.In the proposed method,we employ a relaxedk-means clustering algorithm,i.e.,the NMF algorithm according to the formulation defined in (7),where U is the collection of fusion feature descriptors,V=[v1,v2,…,vM]is the learned dictionary withMitems,B=[b1,b2,…,bN],biis anMdimensional binary vector,and ||⋅||Fis the Frobenius norm[21].

To reduce the information loss of SC,the NMF algorithm is an SC algorithm with a special constraint that makes all the decomposed components nonnegative[21].
2.6.Linear ScSPM Model for Classification
After feature fusion and codebook learning,the final feature vectors are obtained by using the SC algorithm and multi-scale spatial max pooling.Finally,the images are recognized using a linear SVM model[21].Here,we adopt the linear ScSPM model introduced by Yanget al.[6]to solve the optimization problem in (8):
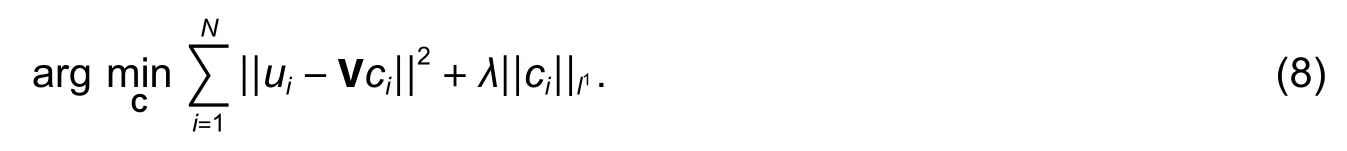
Here,C=[c1,c2,…,cN]is the cluster membership indicator,andis the sparsity regularization term to obtain a unique solution and significant less quantization error than the spatial pyramid matching (SPM)model[22].
3.Experimental Evaluation
We conducted image classification experiments on three widely tested public datasets,i.e.,the Scene-15,Caltech-101,and Caltech-256 datasets.
To evaluate the effectiveness of the proposed algorithm,we first tested the impact of each feature in Table 1,as well as the influence of the dimension reduction algorithm on the Scene-15 dataset.We also performed comparative evaluations with some state-of-the-art image classification methods on the Scene-15,Caltech-101,and Caltech-256 datasets.In order to achieve reliable and replicable results,experiments for all three datasets were tested 10 times by a random selection strategy.
3.1.Scene-15 Dataset
The Scene-15 dataset contains 4485 images in 15 categories.The average image size is 300 × 250 pixels,and the number of images in each category ranges from 200 to 400.Some examples of this dataset are shown in Fig.2 (a).
We first tested the impact of the features listed in Table 1,and then we investigated the influence of the dimension reduction algorithm.Finally,we compared the proposed method with existing methods on the Scene-15 dataset.
1) Impact of superpixel features.As shown in Table 1,three different types of features (global,appearance,and texture features) are used in the fusion.The classification accuracy of these features is listed in Table 2,where G,T,and A denote the global,texture,and appearance features,respectively.Note that the classification accuracy was obtained after applying dimension reduction using PCA.
2) Influence of dimension reduction.Additional experiments were conducted to test the efficiency of dimension reduction using PCA.The experimental results of models with and without PCA obtained on the Scene-15 dataset are shown in Table 3,where G+T+A denotes the proposed method without PCA,and G+T+A+PCA denotes the proposed method with PCA.

Fig.2.Example images from (a) Scene-15:(a1) bedroom,(a2) highway,and (a3) kitchen;(b) Caltech-101:(b1)airplane,(b2) brain,and (b3) ferry;(c) Caltech-256 datasets:(c1) bathtub,(c2) bulldozer,and (c3) grandpiano.

Table 2:Classification accuracy of superpixel features on Scene-15 dataset

Table 3:Experimental results of models with and without PCA on Scene-15 dataset
3) Comparison with different methods.To demonstrate the effectiveness of the proposed method,comparative tests were performed on the Scene-15 dataset.
Here,according to common experimental settings,the training set was constructed by randomly selecting 100 images from each category,and the remaining images were used as the testing set.The classification accuracy obtained by several classical image classification models on the Scene-15 dataset is shown in Table 4.Note that all algorithms were executed under the same experimental settings.As shown in Table 4,the proposed method outperformed the kernel spatial pyramid matching (KSPM) method by more than 7% and the baseline ScSPM by approximately 4.5%.In addition,the proposed method outperformed deep network methods,e.g.,the principal component analysis network (PCANet) and deep sparse coding network (DeepSCNet).However,we consider that there is room to improve the proposed method because the heterogeneous structure fusion method[17]outperformed the proposed method by 2.5%.

Table 4:Comparison with different methods on Scene-15 dataset
3.2.Caltech-101 Dataset
The Caltech-101 dataset contains 9144 images from 102 classes (one background class and 101 object classes).The classes in this dataset include leopards,wheelchairs,ferries,and pizza (examples are shown in Fig.2 (b)),and these categories exhibit significant variance in shape.The image resolution in this dataset is 300 × 300 pixels,and the minimum number of images in each class is 31.According to the classical experimental setup for Caltech-101[6],we performed training on 5,10,15,20,25,and 30 images per class,respectively,and the remaining images were used for testing.The final performance was obtained by calculating the average recognition rate of 102 classes[25].
The classification accuracy obtained by the proposed and existing methods is shown in Table 5.Note that all results were obtained with a codebook trained on 1024 bases.As seen in Table 5,the proposed method outperformed the ScSPM,locality-constrained linear coding (LLC),and parallel key SIFT analysis (PKSA) methods on most test results.The classification accuracy of two label consistentk-means singular value decomposition (LCKSVD) methods was greater than that obtained by the proposed method,when five training images were used per class.However,the proposed method outperformed these LC-KSVD methods when training was performed on 25 and 30 training images per class.

Table 5:Experimental results on Caltech-101 dataset
3.3.Caltech-256 Dataset
The Caltech-256 dataset is a more challenging dataset that contains 30607 images and 257 classes.Compared with the Scene-15 and Caltech-101 datasets,the Caltech-256 dataset comprises more images with greater variabilities in the object size,location,and pose.The number of images in each category is from 80 to 827,and the image size is less than 300 × 300 pixels.
Following the experimental settings in [6],the proposed method was compared with some classical image classification models under the codebook size of 2048.Here,15,30,45,and 60 training images were used per class,respectively.The results are shown in Table 6.

Table 6:Comparison results on Caltech-256 dataset
3.4.Performance Comparison
The classification performance of the proposed method and the baseline ScSPM method on the three datasets is shown in Fig.3.As can be seen,the proposed method enhanced the baseline method on all three experimental datasets between 1.5% and 4.5% in classification accuracy.

Fig.3.Comparison of classification accuracy obtained by the proposed and ScSPM methods.
4.Conclusion
In this paper,we proposed an image recognition method based on superpixels and feature fusion.In the proposed method,the input image is first segmented into superpixels,and then global,texture,and appearance features are extracted from the calculated superpixels.To improve the classification accuracy,the PCA dimension reduction method is applied to the features,followed by a weighted serial feature fusion algorithm.According to the learned fusion feature,a codebook is constructed using the NMF algorithm,and the input image is recognized using the ScSPM model.Experiments were performed on the Scene-15,Caltech-101,and Caltech-256 datasets,and the experimental results demonstrate that the proposed method outperformed the baseline method on all three databases.In addition,the experimental results also imply that further progress is required to improve the classification accuracy.
Disclosures
The authors declare no conflicts of interest.
 Journal of Electronic Science and Technology2021年1期
Journal of Electronic Science and Technology2021年1期
- Journal of Electronic Science and Technology的其它文章
- Annotation of miRNAs in the COVlD-19 Novel Coronavirus
- Molecules against COVlD-19: An in Silico Approach for Drug Development
- lmpact of Coronavirus Pandemic Crisis on Technologies and Cloud Computing Applications
- Identification of the Potential Function of circRNA in Hypertrophic Cardiomyopathy Based on Mutual RNA-RNA and RNA-RBP Relationships Shown by Microarray Data
- Bioinformatics Analysis on lncRNA and mRNA Expression Profiles for Novel Biological Features of Valvular Heart Disease with Atrial Fibrillation
- Signal Acquisition and Processing Method for Capacitive Electromagnetic Flowmeter