
一种基于FPGA 的高性能卷积神经网络加速器的设计与实现
2021-04-02 07:22曹学成廖湘萍李盈盈丁永林
智能物联技术 2021年5期
曹学成,廖湘萍,李盈盈,丁永林,李 炜
(中国电子科技集团公司第五十二研究所,浙江 杭州 311100)
0 引言
近年来,在人工智能相关的机器学习研究领域中, 卷积神经网络 (Convolutional Neural Network,CNN)相比传统算法有了很大的进步[1]。特别是随着计算机处理能力的不断提高,卷积神经网络作为人工智能研究和发展的新方向,已成为机器学习领域的热点[2]。 卷积神经网络是一种受动物视觉皮质(Visual Cortex)结构形式启发,而形成的一种前馈神经网络(Feed-Forward Artificial Neural Network)。同时,卷积神经网络也是一种多层神经网络,在图像分类、机器视觉和视频监控等领域具有重要的应用价值和研究意义[3-5]。
常用卷积神经网络的网络模型在计算量上达到了十亿量级, 在参数量上达到了上百兆量级,需要消耗很大的算力[6-9]。 同时, 受制于中央处理器(Central Processing Unit,CPU)的串行处理方式,目前CNN 的软件实现方式效率并不高, 难以满足许多实时应用的需求[10]。 为了提高CNN 的计算性能,使用图像处理器 (Graphic Processing Units,GPU)、专用集成电路(Application Specific Integrated Circuit,ASIC) 和 现 场 可 编 程 门阵 列 (Field Programmable Gate Array,FPGA) 硬 件 平 台 是 实 现CNN 加速器常用的方式[4,11]。 GPU 拥有大量计算单元, 其运算速度虽然较快, 但功耗很高, 而且在CNN 推理阶段,因数据量的限制,GPU 不能充分发挥其高带宽、多计算核心的特点。ASIC 只适用于一类固定算法[12-13],当算法发生改变时,原有的ASIC芯片不能够再次迭代使用。 FPGA 因其高度并行计算和可重构的特性, 被广泛应用到CNN 算法推理阶段的加速器实现中[14]。
CNN 加速器的计算过程中大部分是卷积操作,而卷积操作需要非常大量的乘累加运算。 对于基于FPGA 实现的CNN 加速器, 其中乘累加运算单元的工作频率直接影响CNN 加速器的性能。 本文采用FPGA 内部数字处理单元 (Digital Signal Processor,DSP)的级联、卷积核数据的“乒-乓”使用,提升DSP 的工作频率,来提高CNN 加速核的计算能力。 同时采用多通道并行、特征图及卷积核数据的复用等方法, 提升数据的使用率, 来提高CNN 加速核的吞吐能力。 最后,以VGG16 模型为例验证了本方案的吞吐量和计算性能,结果表明本方案取得了较好的效果。
1 相关工作介绍
1.1 卷积神经网络
卷积神经网络(CNN)是人工神经网络中的一种,它是图像识别和语音识别领域的研究热点。 它相对于其他的神经网络的特点是权值共享,使得网络的复杂度降低, 容易收敛。 CNN 通常包括卷积层、池化层、全连接层等,图1 为CNN 基本结构示意图。首先,对输入原始图像进行预处理,将处理后的图像作为CNN 的输入特征图;其次,输入特征图经过多层卷积层、池化层等处理,得到越来越复杂的特征图,之后进入全连接层;最后,计算特征图的卷积值,通过Softmax 函数计算概率值,进行归一化操作并排序, 概率最大的节点将作为预测目标,输出分类结果。
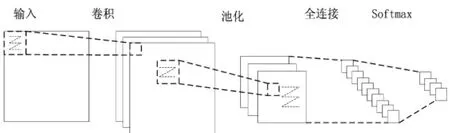
图1 CNN 基本结构示意图Figure 1 Basic structure of CNN
卷积层主要使用训练阶段训练好的卷积核对输入数据进行滤波处理, 然后提取所需的图像特征。 卷积操作后常跟随有非线性激活函数,如常用的 ReLU(Rectified Linear Unit)和 Leaky ReLU 等。
池化层也是卷积神经网络中常见的网络层,它的主要作用是对卷积层的输出进行子抽样。在卷积层进行特征提取后,输出的特征图像会被传递到池化层进行特征选取和信息过滤。常见的池化算子有最大池化和平均池化。
全连接层可看作是一种特殊的卷积运算。全连接层中的每个神经元与上一层的神经元全部有关,这样使其的卷积核很大,具有权值参数数据量大的特点。
当前, 卷积神经网络趋向于卷积核大小更精简、网络层数更深的方向发展。 随着网络深度的加深, 网络性能的退化问题将越明显, 而残差网络(Resnet)的提出,可以很好的解决该问题。 残差网络的特点为每两层卷积层增加一个捷径,进行叠加构成一个残差块。
1.2 硬件加速器
目前用于卷积神经网络加速的加速器主要分为三种:GPU、ASIC 以及 FPGA[4,11]。 其中 FPGA 是一种可自定义编程的硬件电路结构,具有更大的并行度、可重复配置性、更好的灵活性、较低的门槛和较短的开发周期,非常适合于神经网络多变的网络结构。
FPGA 能够进行实时流水线运算,对卷积神经网络的处理能够达到较高的实时性。Wang 等[15-16]提出一种采用流水线内核的高效硬件架构,并使用不同的硬件参数测试AlexNet 和VGG 网络模型,以进行设计空间探索,其设计方案在性能密度、资源利用率方面取得了显著改善。Perri 等[17]提出了基于FPGA 的二维卷积单元并行化结构来发掘卷积运算内在的数据和指令级并行,进而加速二维卷积的计算。 为了获得1 cycle/pixel 的数据吞吐率,这些卷积运算单元需要在单个时钟周期内完成对K2个输入图像像素值的同时访问,但这极大增加了对存储带宽的需求。Qiu 等[18]在嵌入式FPGA 平台上,对图像网络分类中低端存储空间和带宽问题进行了深入研究, 在设计CNN 加速时主要关注两个方面——计算引擎和优化内存系统,并提出了一种动态精度数据量化流程, 在保证可比精度的前提下,减少内存占用和带宽需求。
以上工作虽然都在CNN 硬件加速器架构优化方面做出了很大贡献, 但是对于模型复杂度高、计算量大的CNN 算法, 由于FPGA 的工作频率的限制,在其上实现的加速器仍显得性能不高。同时,开发人员将深度学习算法和数据完全映射在有限的FPGA 资源上的难度越来越大[5],甚至造成不可实现的局面。 针对这些问题, 本文利用FPGA 内部DSP 资源的特点, 通过DSP 级联、 卷积核数据的“乒-乓”使用,同时通过多通道并行、特征图及卷积核数据的复用等方法,设计了一种基于FPGA 的高性能卷积神经网络加速器。该加速器适用于多种网络模型。 最后, 本文在 Xilinx 公司的 Virtex7 VX690T 平台上,验证了所设计的加速器的性能。
2 加速器的FPGA 设计与实现
2.1 硬件系统设计
硬件系统的整体结构如图2 所示,主要包括主控处理器(CPU)、DDR(Double Data Rate)主存设备以及FPGA 实现的 CNN 加速器。CPU 作为Master,利用PCIe 接口总线对FPGA 实现的CNN 加速器进行配置及控制, 可以配置CNN 加速器运行的网络结构以及参数;同时下发输入图像数据,以及对CNN 加速器的结果进行后处理等操作。

图2 硬件系统结构图Figure 2 Basic structure of hardware system
FPGA 实现的CNN 加速器主要由5 个部分组成, 分别为 CNN 加速核、PCIe 接口核、DDR 接口核、AXI 数据通道总线以及AXI-Lite 配置通道总线。 CNN 加速核是卷积网络的基本处理模块,PCIe接口核是与CPU 控制、数据交互接口模块,DDR 接口核是卷积神经网络运算过程中数据在片外缓存的接口模块,AXI 数据通道总线是片内数据交互的总线,AXI-Lite 配置通道总线是CNN 加速核的控制以及状态信息查询总线。
系统工作原理如下。CPU 将CNN 的网络结构、权重等信息通过PCIe 总线接口发送给FPGA,并存储到FPGA 的外部存储器DDR 中, 完成网络结构的初始化。 CPU 将需要处理的输入图像通过PCIe 总线接口不断发送给FPGA, 并存储到FPGA的外部存储器DDR 中,启动FPGA 内部的CNN 加速核;CNN 加速核完成对输入图像的多次卷积等运算,并将得到的输出特征值存储到FPGA 的外部存储器DDR 中;CPU 通过查询FPGA 的内部状态,通过PCIe 总线接口读取运算完成的输出特征值。最后CPU 执行Softmax 等后处理函数,得到最终的图像处理结果。
2.2 CNN 加速模块设计
由于目前神经网络的规模越来越大,层数也越来越深,而受限于FPGA 上的存储资源,必须借助外部存储器DDR 才能完成整个网络的运行, 而大量的存储器读写会严重影响CNN 加速器的吞吐率和增加能量消耗。本设计提出一种特征图及卷积核数据复用的方案,架构如图3 所示。 CNN 加速模块有卷积运算单元(Computing Cell)、池化运算单元(Pool Cell)、卷积核权重缓存阵列(Weight RAM Array)、输入特征图缓存阵列(IFmap RAM Array)和输出特征图缓存阵列(OFmap RAM Array)组成。
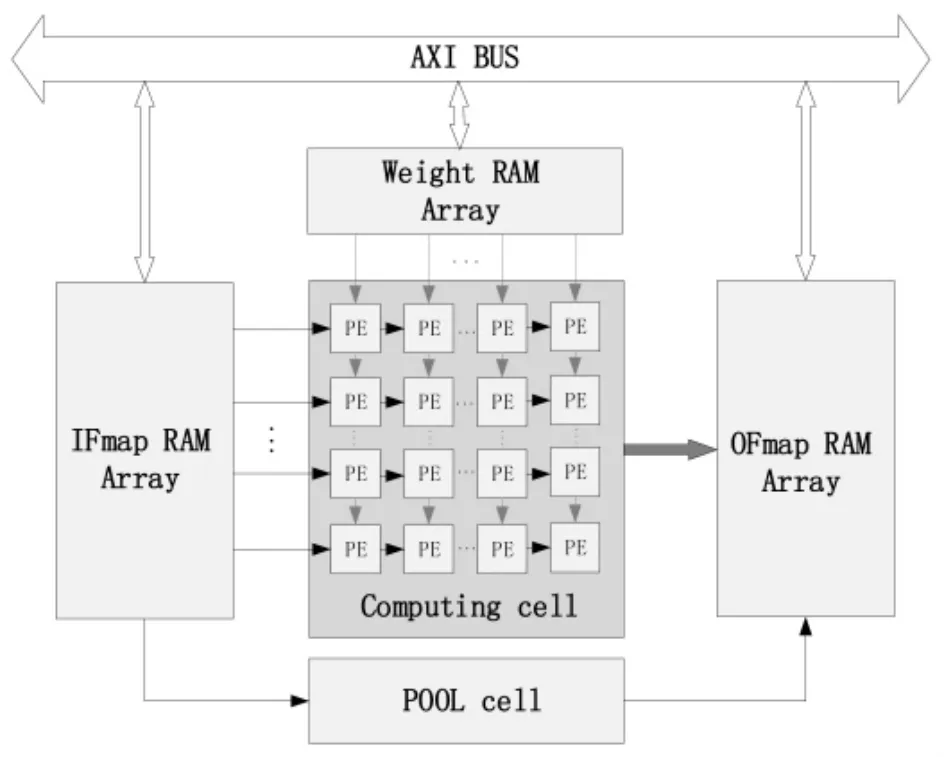
图3 CNN 加速器架构图Figure 3 Basic architecture of CNN accelerator
卷积运算单元由计算单元(PE)阵列组成,卷积核权重缓存阵列的数据从上往下流水给不同的PE,实现卷积核数据的复用;输入特征图缓存阵列的数据从左往右流水给不同的PE, 实现特征图数据的复用。池化运算单元完成最大池化或平均池化的多通道平行计算。输出特征图缓存阵列完成运算单元输出结果的缓存及格式处理,即可以作为下一层特征图输入的格式。
CNN 加速器进行一次完整的卷积运算过程如图4 所示。假设该卷积层的卷积核权重数据的大小为 W×H×C×N;其中,W 表示卷积核的宽,H 表示卷积核的高,C 表示通道数,N 表示卷积核组数。 同时进行M 张输入特征图的计算, 一次完成的卷积运算后得到M 张输出特征图的一个点的所有通道的数据;输出特征图的通道数为卷积核的组数N。 卷积运算的顺序为一次并行计算与卷积运算单元的PE 数量相匹配的卷积核权重数据组数, 通过多次循环完成全部的运算。
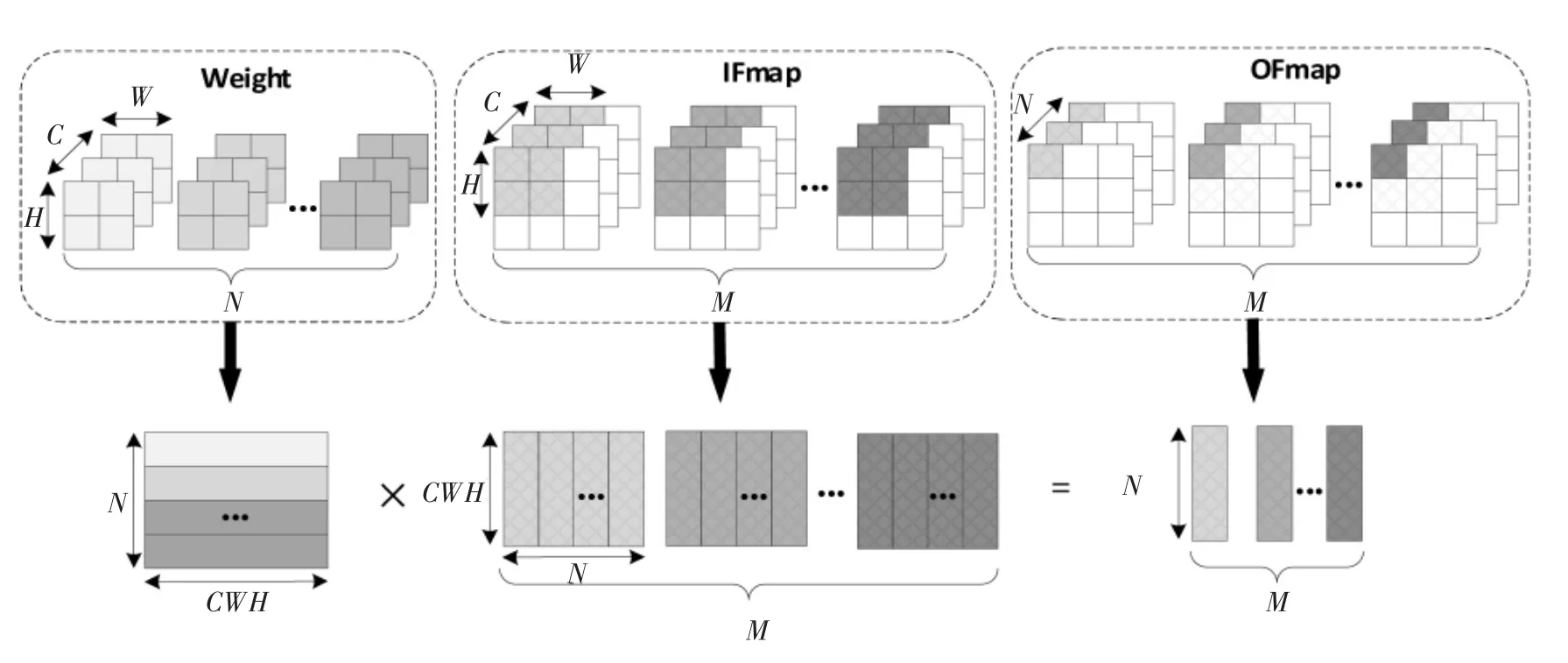
图4 卷积运算示意图Figure 4 Schematic diagram of convolution operation
全连接层的运算过程与上述卷积层相同,这时输入特征图的大小与一组卷积核权重的大小相同。池化层的运算过程与上述卷积层相似,但池化层的运算不需要卷积核权重数据,同时没有输入特征图数据通道间的累加运算。
2.3 计算单元设计
计算单元是CNN 加速器的核心部分, 直接决定了CNN 加速器的性能。 由于卷积神经网络的计算过程中大部分是卷积操作,而卷积操作需要非常大量的乘累加运算,本设计提出一种乘累加计算单元 (Multiply Accumulation Cells,MACs) 的级联方案,结构如图5 所示。

图5 PE 单元内部结构图Figure 5 Internal structure of PE unit
MACs 级联链可以流水的完成多通道并行乘累加计算。FPGA 内部的DSP 单元内部包含乘和加功能, 所以PE 单元的MACs 实际就是FPGA 内部的DSP, 这样极大地减少了额外加速器的使用,降低PE 单元的逻辑资源使用。 同时MACs 之间的级联使用DSP 的专用级联走线,降低PE 单元的走线资源使用。
MACs 的级联尾部有累加器(Accumulator,ACC),用于一次卷积运算需要流水多次使用MACs的级联链运算时的结果累加。 xReLU 使用了FPGA的DSP 实现乘法,支持各种类型的ReLU 计算。
PE 单元运算示意图如图6 所示。每个PE 单元完成一组卷积核权重数据,即C×W×H 的数据量的乘累加运算。 数据计算顺序为C→W→H, 即每个PE 单元的MACs 级联链优先完成一个像素点所有通道的乘累加计算,然后完成水平方向所有像素点的乘累加计算,最后完成垂直方向所有像素点的乘累加计算,得到结果。
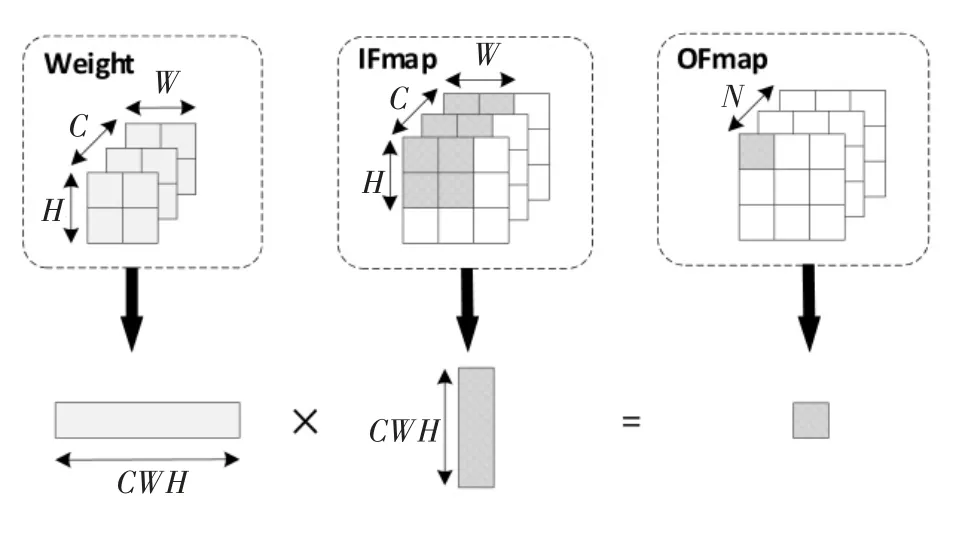
图6 PE 单元运算示意图Figure 6 Schematic diagram of PE unit operation
2.4 乘累加单元设计
由于FPGA 内部资源有限,用于乘累加运算的DSP 单元也是有限的,DSP 使用效率的高低直接影响FPGA 加速器的运算速率。 在本文设计过程中,为了更有效使用DSP 和提高整个加速器的性能,MACs 单元对卷积核权重数据采用“乒-乓”处理结构,如图7 所示。

图7 MACs 单元“乒-乓”结构图Figure 7 Ping-Pong structure of MACs unit
MACs 单元的“乒-乓”结构,使得 FPGA 内部DSP 单元的工作时钟频率是其他逻辑单元时钟频率的2 倍。 “乒-乓”结构的核心思想是利用Xilinx公司的FPGA 中DSP 的特点, 提高DSP 的工作时钟频率。 在主时钟域下,一个时钟周期内对应完成B×A+PCINPing和 B×D+PCINPong两次乘累加运算。 这样,在设计中使用相同数量的DSP,采用DSP 倍频之后加速器理论上的整体性能翻一倍。
3 实验结果与分析
3.1 实验环境
本文是在Xilinx 公司的Virtex7 VX690T 平台上完成设计与实验的,采用FPGA 内部DSP 级联、卷积核数据“乒-乓”使用方法,同时采用多通道并行、特征图及卷积核数据的复用等方法。 使用硬件开发环境Vivado2018.2 对整个设计进行综合布局和布线,其中CNN 加速核模块资源消耗情况如表1 所列。
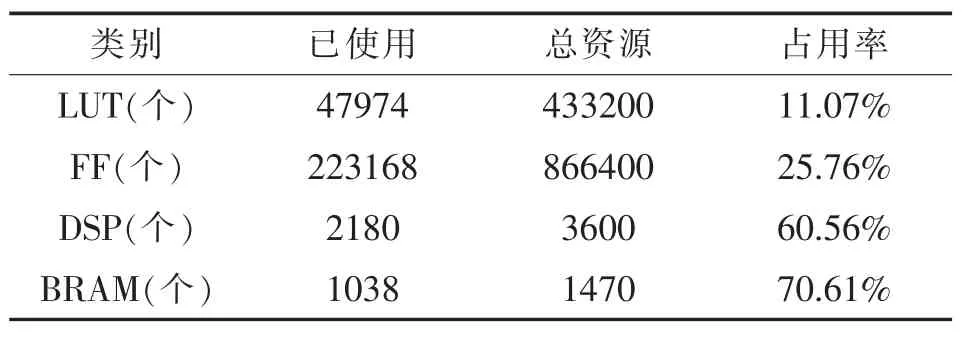
表1 CNN 加速核模块资源消耗Table 1 Resources occupied Of CNN accelerator
本文使用了VGG16 网络模型进行实验。VGG16网络模型包含13 层卷积层、5 层最大池化层、3 层全连接层。 每个卷积层都有激活函数(ReLU)处理,具体的网络参数如表2 所列。 该模型输入特征图尺寸为227×227×3,全连接层用于分类判别,对应的运算量为 29GOPs(Giga Operations Per Second)。

表2 VGG16 网络参数Table 2 VGG16 network parameters
3.2 实验结果分析
本文设计的CNN 加速器由于采用FPGA 内部DSP 级联、卷积核数据“乒-乓”结构,提升了DSP 的工作频率, 在时序收敛的情况下,DSP 的工作频率能达到400MHz。 同时,本设计采用多通道并行、特征图及卷积核数据的复用等方法,提升了FPGA 内部缓存数据的利用率, 降低了与外部缓存DDR 之间的带宽需求。 本设计在 Xilinx 公司的 Virtex7 VX690T 平台使用了2048 个DSP 用于卷积的乘累加运算,理论算力为1.6TOPs。 基于VGG16 网络模型进行实验, 实测处理一帧图像延迟为21.7ms,对应图像处理性能为46FPS,实测有效算力(吞吐量)为 46×29=1334GOPs=1.334TOPs,计算单元(PE)的利用率达到83.4%。 在吞吐量方面将本文方案与其他方案进行对比,结果如表3 所列。
根据表3 可知, 在同等规模的设备平台上,本方案的吞吐量是其他设计方案的1.9 至21.6 倍,性能指标上明显优于其他设计方案。 这说明本设计采用FPGA 内部DSP 级联、卷积核数据“乒-乓”结构,提升了DSP 的工作频率,具有较高的计算性能。
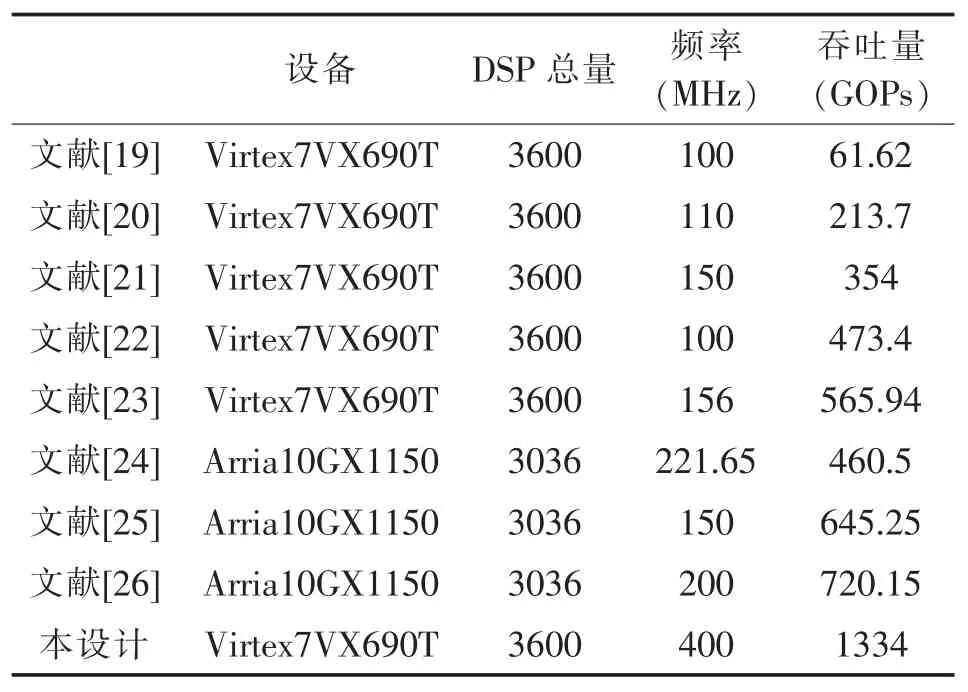
表3 本文方案实验数据与其他方案的对比Table 3 Comparison of experimental data with other schemes
本文设计的CNN 加速器资源消耗如表1 所示。 在使用相同设备平台实现CNN 加速器时,在LUT 资源、DSP 资源消耗方面将本文方案与其他方案进行对比,结果如表4 所列。 所用方案都是基于Xilinx 公司的 Virtex7 VX690T 平台。
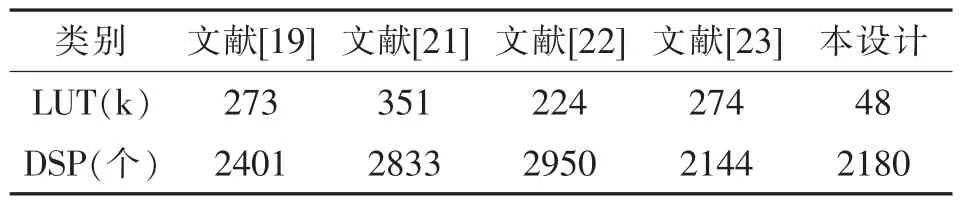
表4 资源消耗对比Table 4 Comparison of resources occupied
根据表4 可知, 这些方案的DSP 资源消耗量相当, 但本方案的LUT 资源使用量是其他设计方案的13.7%至21.4%。 这说明本设计采用的充分利用FPGA 中DSP 单元内部包含的乘和加功能,以及DSP 级联方式的方案, 减少了额外加速器资源的使用,在降低资源使用量方面是有优势的。
4 结论
FPGA 器件内部资源有限,高效利用FPGA 资源获得较高的计算性能是基于FPGA 实现CNN 加速器设计的重点。 本文提出了一种高性能、资源消耗少的CNN 加速器设计方案, 结合 FPGA 内部DSP 资源的特点, 通过DSP 级联、 卷积核数据的“乒-乓”结构,同时通过多通道并行、特征图及卷积核数据的复用等方法, 实现了一种理论算力为1.6TOPs 的高性能CNN 加速器。 实验结果表明,与其他设计方案相比,本文方案具有较高的计算性能和较少的资源消耗。 为了进一步提高CNN 加速器的性能, 今后尝试将工作方向主要集中在DDR 带宽和PE 单元利用率上,将池化运算单元放在卷积运算单元后流水执行, 减少数据与外部缓存DDR的交互, 同时避免池化运算时卷积运算单元的空闲,进一步提升加速器性能。
猜你喜欢
现代装饰(2022年5期)2022-10-13
小哥白尼(趣味科学)(2022年5期)2022-08-15
核安全(2022年3期)2022-06-29
北京航空航天大学学报(2021年9期)2021-11-02
少先队活动(2021年6期)2021-07-22
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
汽车与新动力(2014年4期)2014-02-27
原子能科学技术(2011年10期)2011-07-30
