
基于LSTM网络的语音特征信号分类技术研究
2021-03-28 04:43代巧利张朝亮
电子元器件与信息技术 2021年12期
代巧利,张朝亮
(1.武警湖北省总队参谋部,湖北 武汉 430000;2.海军工程大学电气工程学院,湖北 武汉 430033)
0 引言
随着机器学习与人工智能技术的飞速发展,语音识别在通信、智能家居、医疗、军事等方面逐渐得到了广泛运用。在语音信号识别中应用非常广泛的一种方法是梅尔倒谱系数[1]。它基于一组非线性的特征参数,能有效结合语音机理,通过计算分析语音波形及行为特征的语音参数进行有效的判断。而识别方法应用比较广泛的有隐马尔可夫模型、高斯混合模型、支持向量机模型和神经网络等。人工神经网络通过模仿生物神经网络的行为特征原理,以类似大脑处理信息的方式建立数学模型[2],输出值能够相当逼近真实值或给出逻辑判断。
深度学习是神经网络研究的热点,包含多种有效的方法,如深度置信网络DBN、循环神经网络RNN、卷积神经网络CNN等。而长短期记忆模型循环神经网络LSTM[3]可以算是RNN网络的代表,在处理像序列语音信号数据[4-5]时能够取得非常好的效果。在深度学习算法实验时需要编写大量的代码,为避免重复、提高研究效率,优秀的研究者们将代码整合成框架发布,其中比较优秀的有Tensorflow、Caffe、Torch和PyTorch等。
本文基于Tensorflow框架,采用LSTM网络,开展了语音特征信号分类研究。
1 语音通信与特征分类
语音识别分类过程主要包括,信号采集与预处理、特征提取、识别与分类等步骤。
语音信号采集是将声音通过麦克风等设备输入计算机,预处理对信号进行滤波进而滤除噪声。语音信号特征参数提取,常采用线性预测系数、感知线性预测、梅尔频率倒谱系数(MFCC)等[6]。两种线性预测的特征参数反映声道的响应特性。而梅尔频率倒谱系数的特征参数反映人的听觉特性,具有广泛的应用。
根据人耳听觉机理的研究发现,人耳对不同频率的声波有不同的听觉敏感度。所以,从低频到高频这一段频带内按临界带宽的大小由密到疏安排一组带通滤波器,对输入信号进行滤波,将每个带通滤波器输出的信号能量作为信号的基本特征,进一步处理后就可以作为语音的输入特征。由于其不依赖于信号的性质,对输入信号不做任何的假设和限制,又利用了听觉模型的特点,所以更符合人耳的听觉特性,且当信噪比降低时仍具有较好的识别性能。
梅尔倒谱系数是在Mel标度频率域提取出来的倒谱参数,Mel标度描述了人耳频率的非线性特性,它与频率的关系可用公式1近似表示:
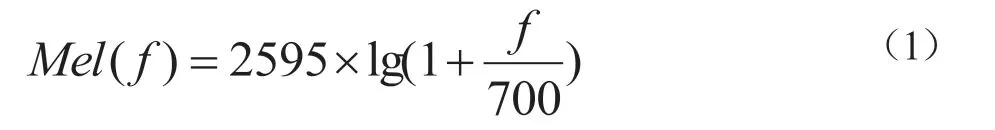
式中f为频率,单位为Hz。
2 神经网络和深度学习
在传统语音识别模型中,基于参数模型的隐马尔可夫模型能够根据观测的序列估计出想要得到的目标序列,数据量大时能够取得较好的效果。现代的神经网络模型类似人脑,可以通过训练学习来达到较高的识别准确率。
循环神经网络(Recurrent Neural Network,RNN)是一种用于处理序列数据的神经网络。相比一般的神经网络来说,他能够处理序列变化的数据。比如某个单词的意思会因为上文提到的内容不同而有不同的含义,RNN就能够很好地解决这类问题。
长短期记忆(Long short-term memory,LSTM)是一种特殊的RNN,主要是为了解决长序列训练过程中的梯度消失和梯度爆炸问题。简单来说就是相比普通的RNN,LSTM能够在更长的序列中有更好地表现[7-9]。
人工智能对互联网期刊等数字出版领域的各个环节都会具有极大的推动作用。王晓光等学者认为,未来人工智能在内容生产方面,甚至于发展到根据用户特征实时生产个性化内容。在内容编辑方面,要充分发挥人工智能采集信息和组织内容的作用以及对文字进行规范化处理的能力,减少繁琐、简单的工作任务压力,提升期刊社对内容质量把控的能力等。在内容发行传播方面,要利用人工智能实现对用户进行个性化定制与推送服务。
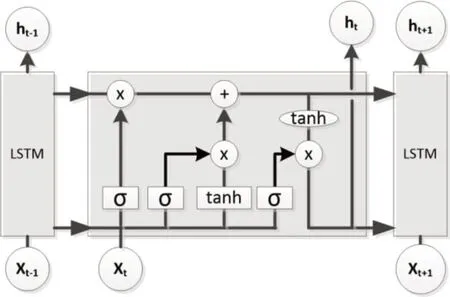
图1 LSTM 结构
Tensorflow是由Google开发的开源数学计算软件,使用数据流图(Data Flow Graph)的形式进行计算[10-11]。Tensorflow目前支持Python、C++、Java、Go、R等,使用C++ Eigen库,可在ARM架构上编译和优化,所以其灵活的架构能让用户在一个或多个CPU、GPU的单机及服务器、移动设备上部署自己的训练模型[12-13]。因此本实验选择Python语言和Tensorflow框架进行识别分类的实现。
3 模型实现与验证
为了验证验算法的有效性,实验数据是从某通信工程项目子系统中选取的四组不同类型的语音通信数据。采用python开发实现,进行仿真实验,仿真电脑配置参数:操作系统为win10,显卡为Nvidia Geforce RTX2080,内存为32GB,处理器为intel Core i9 2.3GHz。
3.1 算法结构
根据前面的理论分析,本文采用的通信特征识别算法结构如图2,
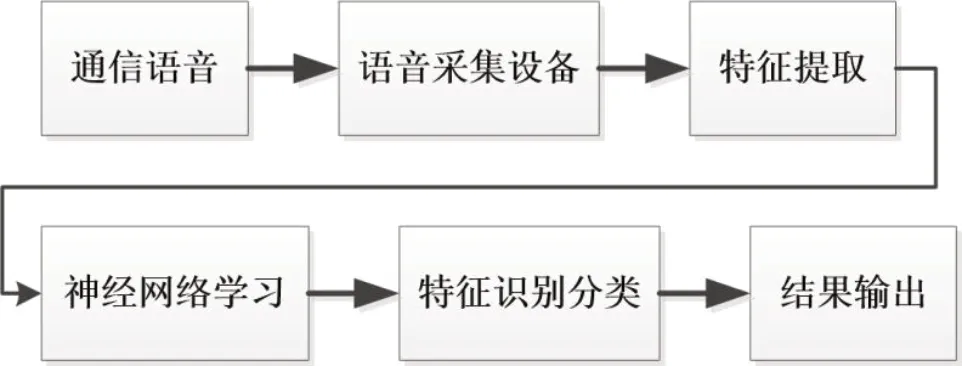
图2 通信特征识别算法结构
3.2 特征数据
对于获取到的4类通信语音,用倒谱系数法将每类语音各提取400组24维的MFCC特征信号,共2000组数据。将提取出的4类语音的信号特征绘制成曲线,如图3所示。

图3 MFCC 特征信号
3.3 实验结果分析
实现过程中,将四类2000组特征信号合并之后,从中随机选取1500组作为训练数据,500组作为测试数据,并进行了归一化处理。语音类别标识采用onehot方式。
为了对比实验效果,本文首先采用了BP神经网络进行了识别,神经网络结构为24-25-4,对神经网络权值和阈值采用随机初始化。
如图4为其中一次实验的识别错误分布图,横坐标为测试的数据顺序,范围从0~500;纵坐标为分类结果,1为本次数据分类正确,0为本次数据分类错误。
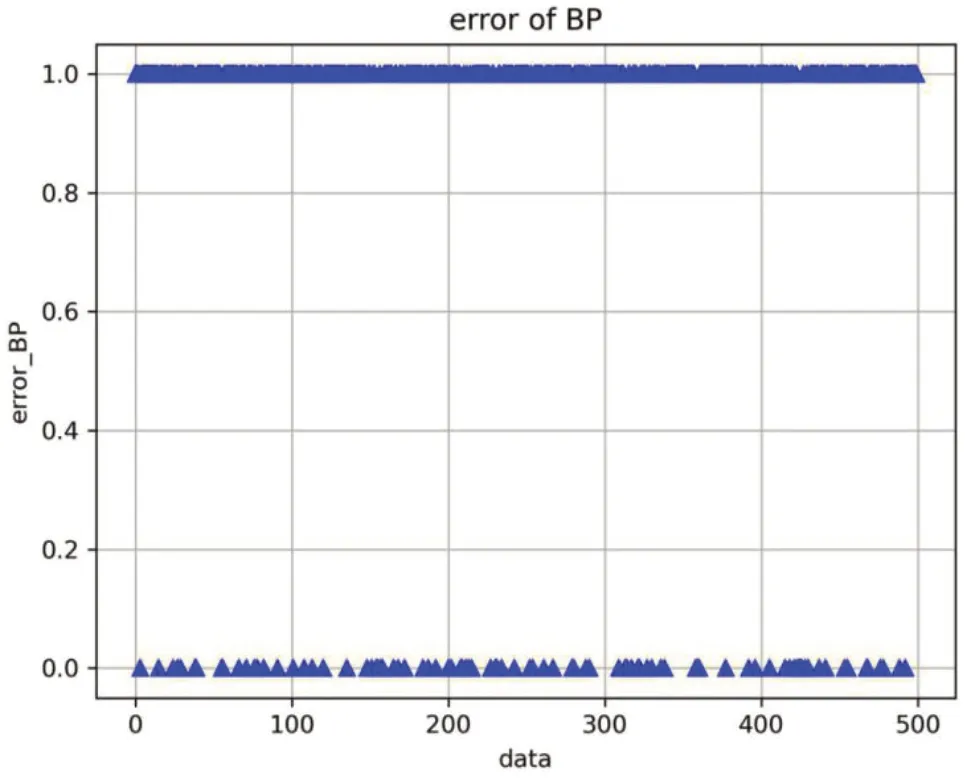
图4 BP 神经网络识别结果
接下来采用LSTM算法进行识别,基本参数如表1所示,包括学习样本、测试样本个数、学习率设置,dropout设置等。

表1 基本实验参数
表2中显示了12轮实验所选取的参数、学习准确率(Learning accuracy,LA)和结果测试准确率(Test accuracy,TA)。
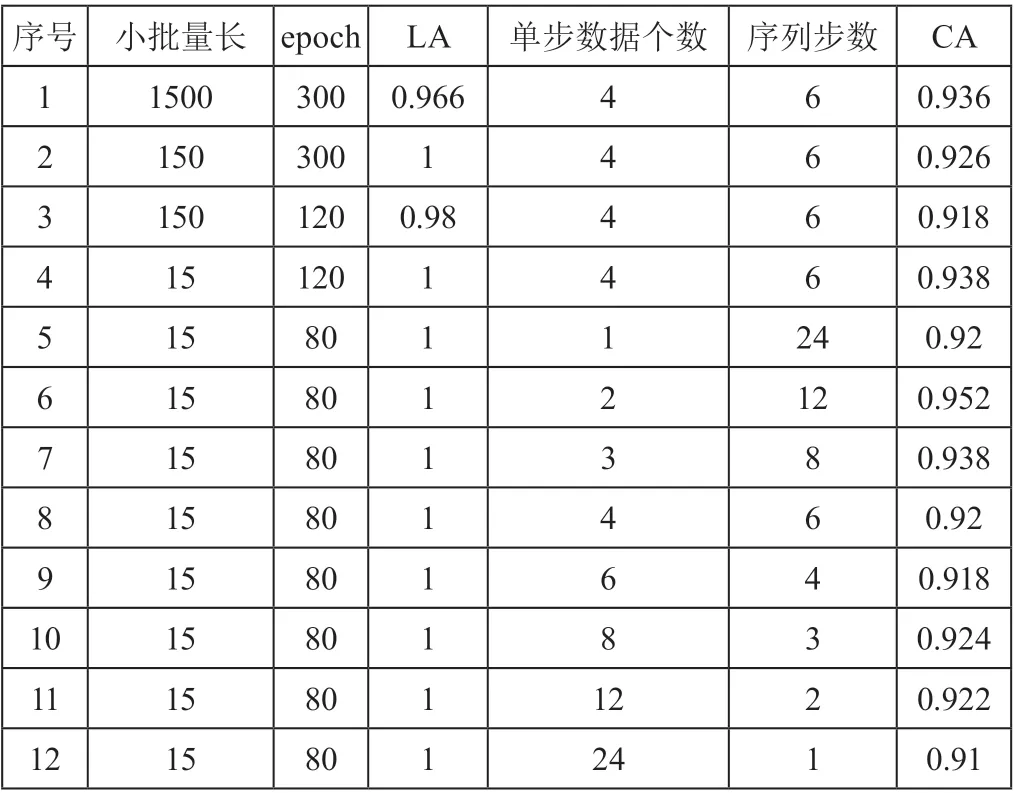
表2 主要实验数据
由于LSTM网络在使用时涵盖了序列步数的概念,因此在本轮实验中,选取了不同的序列步数值,以观察分类效果。其中单步数据个数乘以序列步数为24,即MFCC特征的维数。在12轮测试中,学习准确率基本维持在1或接近1,即表示网络已完成了对样本的学习。小批量长度也选取了3种数值,由于样本数据量不大,此时的小批量长度对最后的分类结果和学习速度影响不是特别明显。而epoch也根据小批量长度的不同,进行了相应的修正。从多次测试结果值看,测试准确率平均在0.927。通过改变相关的参数,在第6次识别中准确率达到了最高0.952。
如图5为其中一次实验的识别错误分布图,横坐标为测试的数据顺序,范围从0~500;纵坐标为分类结果,1为本次数据分类正确,0为本次数据分类错误。
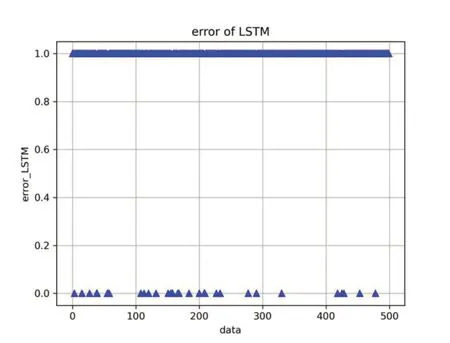
图5 LSTM 网络识别结果
通过多次实验的参数对比发现,适当选取参数对识别准确率有较大的影响,但LSTM网络的识别效果优于BP神经网络,且通过适当调整参数,仍可以使得LSTM准确率有所提高。
如图6是在小批量长度150,序列步数为6的情况下,选取不同的epoch对识别准确率的影响曲线。可见在其他参数确定的情况下,增加epoch可以使得准确率有所提高,但到达一定程度之后,再增加epoch时对准确率的提高有限,而此时要防止过度拟合。

图6 不同的epoch 对识别准确率的影响
如图7是在选取小批量长度为15,epoch为80时,多次测试中,LSTM网络参数序列步数的选取对识别准确率的影响曲线。
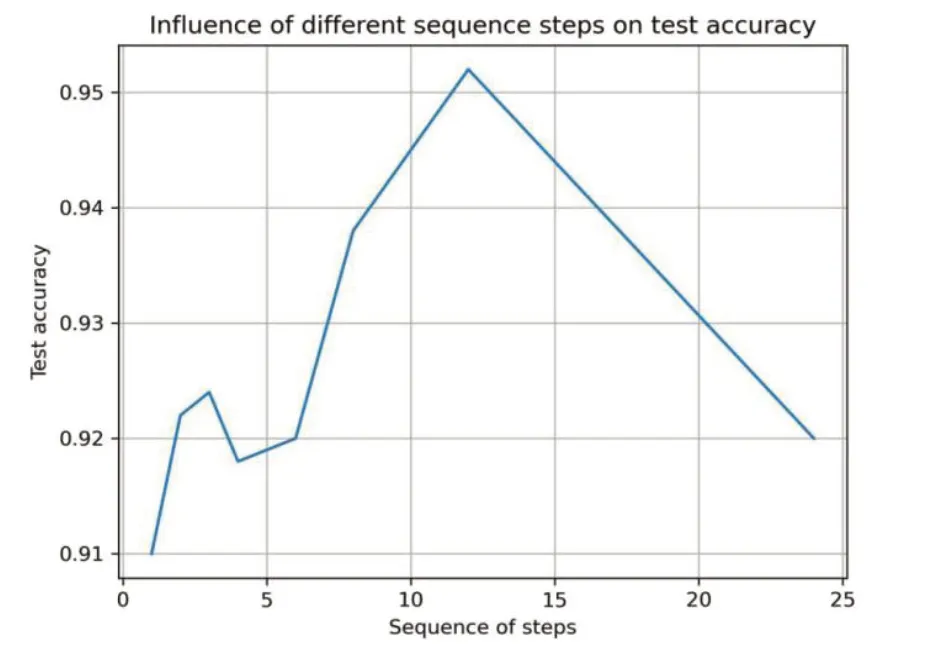
图7 不同的序列步数对识别准确率的影响
可见,在其他参数确定后,根据原始数据维数的不同,应适当选取LSTM序列步数参数,使得识别准确率具有较大提高。
4 结语
本文针对语音通信数据的序列特点,选取LSTM网络进行了特征识别与分类。深入分析了参数选择对分类准确率的影响,并与传统BP神经网络分类效果进行了对比,实验结果表明,本文所设计的方法具有良好的识别准确率和稳定性,对于语音通信识别具有较好应用价值。在实际应用中,有些语音的通信数据量较小,如何结合本文方法,在学习数据量更小的情况下获得较高的识别率是一个较好的研究方向。
猜你喜欢
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
电子制作(2019年19期)2019-11-23
阅读(快乐英语高年级)(2019年5期)2019-09-10
电子制作(2019年14期)2019-08-20
电子制作(2019年9期)2019-05-30
小说界(2018年5期)2018-11-26
中国交通信息化(2018年5期)2018-08-21
重型机械(2016年1期)2016-03-01
