
基于深度学习的行人重识别算法设计
2021-03-28 04:43覃嘉辉
电子元器件与信息技术 2021年12期
覃嘉辉
(深圳市鸿捷源自动化系统有限公司,广东 深圳 518028)
0 引言
随着信息科技的快速发展,由于社会安全问题,对监控图像及视频的研究成了一个重要方向,包括对目标的检测、识别、追踪等,可与行人检测/跟踪技术相结合,广泛应用于智能视频监控、智能安保等领域[1]。
1 行人重识别相关技术
1.1 卷积神经网络(CNN)
卷积神经网络是一种前馈神经网络,它的人工神经元可以响应一部分覆盖范围内的周围单元,对于大型图像处理有出色表现。
CNN主要有卷积层、池化层和全连接层。
卷积层通过对原始图像进行卷积计算得到一个特征层,特点是参数共享及局部连接,降低了网络参数,提高性能。
池化层对得到的特征层进行降维操作,降低了计算量,扩大感受野。
全连接层用于分类任务中最后层级,该层神经元个数即为网络类别数,当前层的所有神经元与前一层全部连接。
1.2 行人重识别技术难点
摄像头的不同,同时行人兼具有刚性和柔性的特征,外观易受穿着、尺度、遮挡、姿态和视角等影响,还涉及行人隐私问题。
1.3 常用数据集和评价指标
用于行人重识别任务常用的数据集有以下几种:
(1)Market1501数据集。拍摄于清华大学,6个不同的摄像头拍摄的行人图像32217张。
(2)DukeMTMC-ReID数据集。来自Duke大学,8个不同的摄像头含1812个行人的图像36441张。
(3)CUHK03数据集。共有2个摄像头所拍摄的行人图像14067张,拍摄于香港中文大学。
通用的评价指标有以下几种:
(1)第一匹配率(Rank-1)
Rank-1是指首位命中的概率,公式表达为:
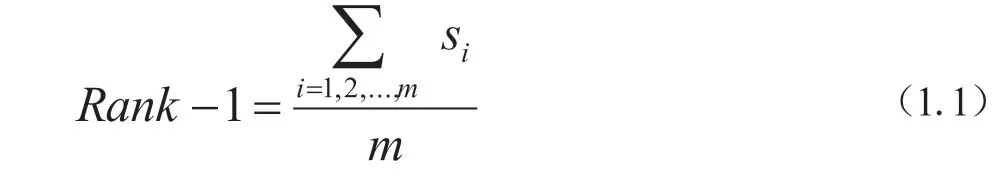
m为查询集中的行人图片总数,Si=1代表对于查询集中的第i张行人图像,恰好为同一行人图像,结果越高,性能越好。
(2)第k匹配率(Rank-k)。Rank-k代表的是排序后若前k张图像存在有查询目标图像,称为Rank-k命中,通常将Rank-k与k值作成曲线图,横坐标为k值,纵坐标为Rank-k值,称为累计匹配特征CMC曲线,整体越高,性能越好。
(3)平均精度均值(mAP)。mAP(mean Average Precision)这一概念的提出,计算了所有正确图像结果在排序中的先后位置,mAP值越高,算法的性能越好。
2 基于表征学习和度量学习的算法
2.1 基于表征学习的算法
最开始的一种算法:基于表征学习的算法。训练集中行人的ID数即为网络的类别数,最后计算一个softmax损失。它不直接学习两张图像的相似性,仅有分类损失的网络也称为IDE网络。

2.2 基于度量学习的算法
度量学习的目的是直接学习两张图像的相似性,通过构造一个度量损失函数,使得同一行人图像之间的距离减小,不同行人之间的距离增大。

本文用到的用于行人重识别任务的度量损失有
Triplet loss和TriHard loss。
2.2.1 三元组损失(Triplet loss)
三元组损失每次输入三张图像,一张固定图片a(Anchor),一张它的正样本p(Positive),一张它的负样本n(Negative),即每次输入一对正样本a和p,一对负样本a和n三张图片,三元组损失公式为:

3 基于局部特征的算法
当同一行人图像中噪声区域较大时,经过网络得到的全局特征差异较大,计算图像相似度时可能会分辨成不同行人导致结果出错。为解决该问题,将两幅图像中行人的局部区域进行对比,提出了基于局部特征的方法,常用的有水平切片、姿态分割等。下面介绍一种基于水平切片算法:AlignedReID算法[2]。
3.1 AlignedReID
AlignedReID是一种基于局部特征的行人重识别算法。将原始行人图像水平分割成八份,然后将分割成的八个局部区域进行对齐,这里采用的是DMLI(Dynamically Matching Local Information)的思想,自动地将局部区域进行对齐,找出两者之间的最短路径作为度量依据。
计算局部特征之间的距离采用欧氏距离:

原始图像经过CNN后得到了一个特征,然后分别送入到两个分支中。一个是全局分支,经过全局池化后得到的是全局特征,可以计算一个分类损失(softmax损失);另一个是局部分支,进行水平池化后得到的是局部特征,再引入DLMI思想进行局部特征的自动对齐。最后利用全局特征找到的准样本,计算出TriHard loss。
3.2 引入随机擦除的改进算法
针对行人重识别中存在遮挡的问题,引入了随机擦除的思想,对数据集进行增广以提升网络的泛化性能。
方法是在训练阶段,以一定的概率p对训练数据进行随机擦除处理,对于大小为W×H的输入图像I(其面积为S=W×H),若生成的概率值小于p,则进行随机擦除操作:随机选取一块矩形区域面积为Se,且矩形区域的纵

4 实验内容及结果分析
4.1 数据集
本文采用Market1501数据集,下载Market1501数据集后,里面共有五个文件夹,本次实验用到其中的三个:训练集bounding_box_train,测试阶段的查询集bounding_box_test,候选集query。
4.1.1 训练集
训练集中的图片在bounding_box_train文件夹中,共有行人图片12937张,包括751个行人类别,每个行人的图片数量不等。
4.1.2 查询集
查询集的图片在bounding_box_test文件夹中,提取了候选集中750个行人的不同的区域作为待检索图像。
4.1.3 候选集
测试阶段的候选集中的图像在query文件夹中,需要注意的是候选集中的750类行人完全不同于训练集中的751类行人,这也是我们在表征学习训练阶段必须舍弃最后一个FC层的原因所在。
上述测试集和训练集中的图片的标签是以文件名的形式命名的,如0005_c1s1_001351_00,0005是行人的ID数,ID数不连续,c1代表拍摄的摄像头标号(从0到5),s1代表研究视频ReID时用到的序列标号,001351代表在序列中的第几帧,00表示该序列中的第一段。
4.2 网络模型
本文采用的模型为残差网络ResNet50。先将原始图像(224,224,3)经过五层堆叠的卷积层,得到(7,7,2048)维的特征,再经过大小为7×7的窗口进行全局平均池化操作得到2048维的特征向量,最后经过一个分类层,即神经元个数为1000的FC层,计算softmax损失,进行1000类的分类任务[3]。
对于行人重识别任务,需要对上述的ResNet50结构进行改进,首先输入图像大小变为(256,128,3),由于经过卷积层后需要进行水平池化操作且训练集行人ID数为751,所以将原始ResNet50中最后两层去掉。
4.3 训练与测试方法
首先对所有图片进行预处理,将训练集的图片进行图像大小的缩放、水平翻转、转化为Tensor、归一化操作;将测试集的图片进行大小的缩放、转化为Tensor、归一化操作。
表征学习分类数为训练集行人的ID数751,所以在上述改进的ResNet模型后还需要加一个维数为751的FC层,最后计算softmax损失。
训练好模型后,在测试阶段,舍弃最后的FC层,通过前一层输出的特征进行测试,对于查询集中的每一张图像,与候选集中所有图像计算欧式距离,可以对结果进行排序,从而计算出mAP、Rank-1、Rank-5、Rank-10和Rank-20。
5 结语
行人重识别现已成为计算机视觉的一个热门研究方向,本文简要就行人重识别的几个深度学习算法进行研究。应用到具体的视频场景,这对算法的精度和效率有较高要求。目前行人重识别大部分算法是与行人检测相对独立的,能否实现从端到端的网络也是行人重识别必然的发展方向。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
数学小灵通·3-4年级(2021年5期)2021-07-16
意林(2021年5期)2021-04-18
电子制作(2019年11期)2019-07-04
扬子江(2019年1期)2019-03-08
今日农业(2019年15期)2019-01-03
北京航空航天大学学报(2018年1期)2018-04-20
小天使·一年级语数英综合(2017年6期)2017-06-07
汽车与安全(2016年5期)2016-12-01
广西民族大学学报(自然科学版)(2015年3期)2015-12-07
