
基于GA-SVR的地铁隧道沉降预测
2021-03-26 12:16:46周立俊王思捷吴壮壮
地理空间信息 2021年3期
周立俊,黄 腾,王思捷,吴壮壮
(1.河海大学 地球科学与工程学院,江苏 南京 210000)
为了保障地铁的安全运营,对隧道结构进行长期的变形监测和预测具有重要意义。由于受到多种随机性、不确定性因素的影响,地下隧道数据存在非线性、复杂性、多模态性等特点,导致沉降预测存在诸多困难[1]。针对变形预测,许多专家和学者提出了多种模型,如卡尔曼滤波模型、灰色系统理论模型、人工神经网络模型、回归分析法等。由于变形量的随机性和非线性,不同模型的适用性也不同,需对各种模型进行改进和完善。张士勇[2]、姜刚[3]等研究了小波神经网络模型在地铁沉降预测中的应用,得出了组合模型比单一预测模型准确度高的结论;高彩云[4]等利用遗传算法(GA)对地铁沉降预测模型参数进行了搜索,得出GA能有效获取极限学习机网络优化的初始权值和阈值的结论;陈柚州[5]等研究了人工蜂群优化小波神经网络模型在变形预测中的应用,得出经人工蜂群算法优化后的小波神经网络模型精度更高的结论。
神经网络的方法虽然考虑了多种影响因素,但易产生局部最优解;样本较少时精度较低,样本较多时易过度学习,导致模型泛化能力较低[6]。支持向量回归(SVR)能较好地实现小样本、高维度、非线性的预测,并能有效克服神经网络陷入局部最优、过学习现象以及对样本处理依赖经验等缺点[7]。GA是一种启发式全局优化算法,具有很好的全局寻优能力[8]。因此,本文利用GA优化SVR模型的参数,从而构建基于GA-SVR的地铁隧道沉降预测模型,并通过实例验证了模型的可行性。
1 SVR的原理
SVR是支持向量机(SVM)在回归问题上的推广。SVM建立在统计学习理论的基础上,通过最大化分类间隔控制学习机器的容量,以实现结构风险最小化原则;并通过核函数将样本从输入空间映射到高维特征空间,以实现在高维空间中的推广[9]。
假设对于给定的训练数据(x1,y1),(x2,y2),…,(xn,yn)∈Rn×R,通过一个非线性映射φ将数据映射到高维特征空间,从而将非线性回归转化为高维特征空间的线性问题,即

式中,φ(x)为将样本点映射到高维空间的非线性变换;w为权值矢量;b为阈值。
引入不敏感损失函数ε作为损失函数,定义为:
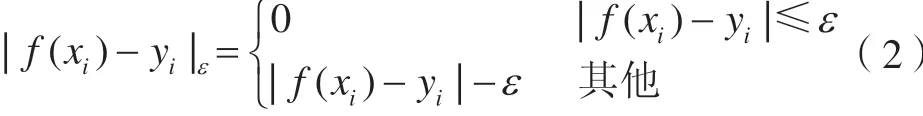
引入非负松弛变量ξi、ξi*,并综合考虑拟合误差,可得到线性回归估计的优化问题,即为训
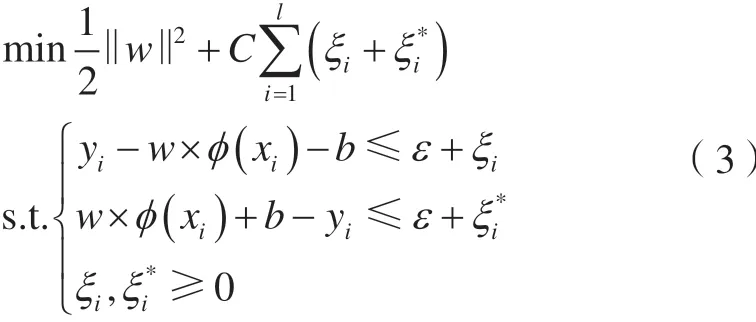
引入拉格朗日函数,并对拉格朗日函数求鞍点,可得该优化问题的对偶问题,即
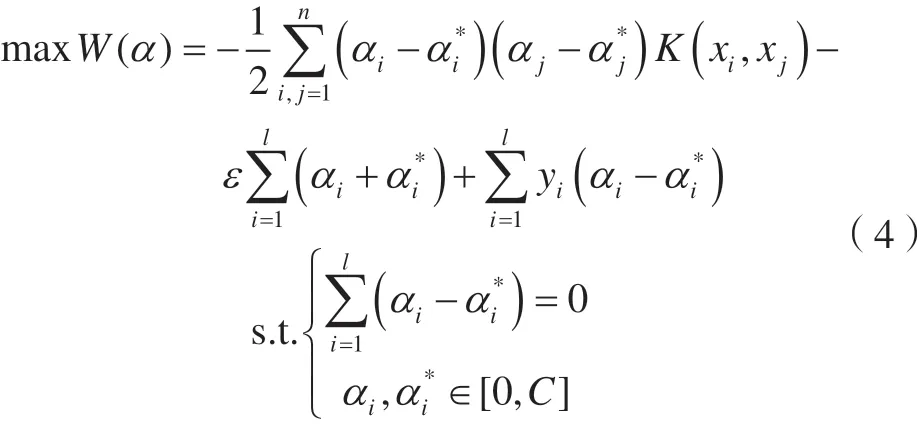
通过引入核函数,可无需知道从低维输入空间到高维特征空间非线性映射φ(x)的具体形式,而利用原空间中的核函数实现高维空间中要进行的计算,从而得到对应的决策函数。
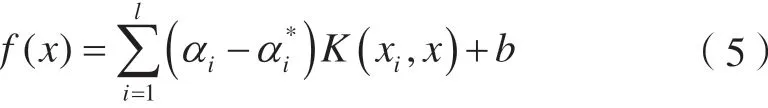
常用的核函数包括多项式核函数、径向基核函数和Sigmoid核函数,本文选用径向基核函数,表达式为:
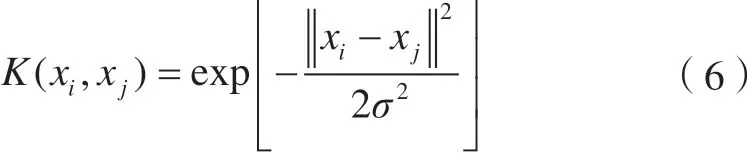
式中,σ为核函数参数,为简便计算,令γ=1/2σ2。
SVR 模型的预测效果依赖于其模型参数(惩罚参数C、核函数参数γ、不敏感损失函数参数ε等)的选择[10]。
2 GA-SVR模型
GA是一种模拟生物在自然界中的遗传机制和进化过程而形成的自适应全局搜索最优解的算法,具有良好的并行性、鲁棒性和全局最优性[11]。因此,本文利用GA优化SVR模型的参数,从而构建基于GA-SVR的地铁隧道沉降预测模型。
GA寻优的具体参数设定:种群个数为100,最大进化代数为200,C的搜索范围为[0,100],γ的搜索范围为[0,100],ε的搜索范围为[0,1]。采用间接二进制编码,每条染色体长度为54个基因,设置交叉概率为0.8,变异概率为0.01。GA参数寻优的具体步骤(图1)为:
1)初始化种群。随机产生100个长度为54个基因的染色体(每个基因由0或1构成),前20个基因表示C的搜索范围,中间20个基因表示γ的搜索范围,最后14个基因表示ε的搜索范围。
2)计算各染色体的适应度。以训练样本的留一交叉验证结果生成的均方误差(MSE)的均值作为适应度函数,表达式为:
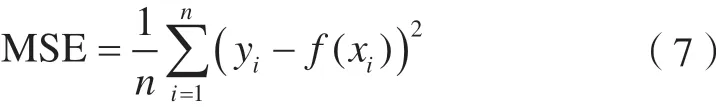
式中,i为样本个数;xi为参考模型的实际值;f(xi)为通过SVM计算得到的预测值。
3)选择操作采用轮盘赌的方式,即适应度越大的染色体被选中的概率越大。
4)交叉操作采用单点交叉的方式,即在染色体中随机选定一个交叉点,发生交叉的两条染色体在该点前后进行部分互换,以产生新的个体。
5)变异操作。由于是二进制编码,随机选择发生变异的基因,该基因若为0,则变异为1;反之,则变异为0。
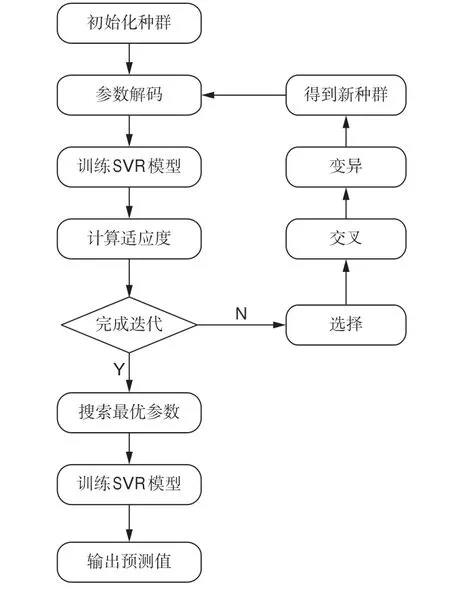
图1 GA参数寻优流程图
3 工程实例应用与分析
本文以南京地铁2号线汉油段的结构监测项目为例,该段隧道全长12.026 km;沉降监测高程系统采用吴淞高程系,设有沉降监测点1 200余个,其中包括3个控制网基准点和11个工作基点;采用严密平差的方法,按距离倒数定权,平差由科傻系统自动进行水准闭合差计算、平差、精度评定以及成果表格的输出。目前,该项目的垂直位移监测已进行36期,历时9 a,每3个月一期。本文选取莫愁湖至汉中门上行隧道内某点的全部36期高程观测数据,将前31期分为21个训练样本,每个训练样本中有11期观测数据,前10期作为输入,11期作为前10期的标签;训练结束后,对后5期进行预测。根据上述算法和实例应用,基于Python语言,在Jupyter Notebook环境下,调用Scikitlearn中的SVR工具箱编写GA-SVR程序。
GA参数寻优过程如图2所示,可以看出,经过150次迭代后基本达到最优,迭代200次后终止,GA优化后C=1.135 83,γ=0.011 92,ε=0.001 95。将寻优所得的参数代入SVR模型对样本训练集进行训练,训练后各训练样本的预测值与实测值具有很好的拟合度,如图3所示。训练集的预测值与实测值的最小绝对误差为-0.002 mm,最大绝对误差为3.00 mm,绝对误差平均值为0.12 mm,训练集的样本MSE为1.63 mm2。
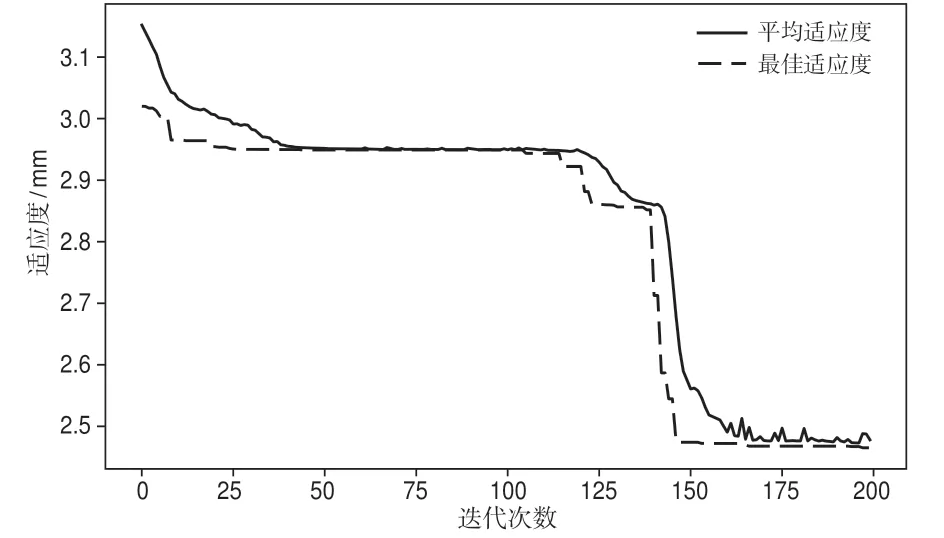
图2 GA参数寻优过程
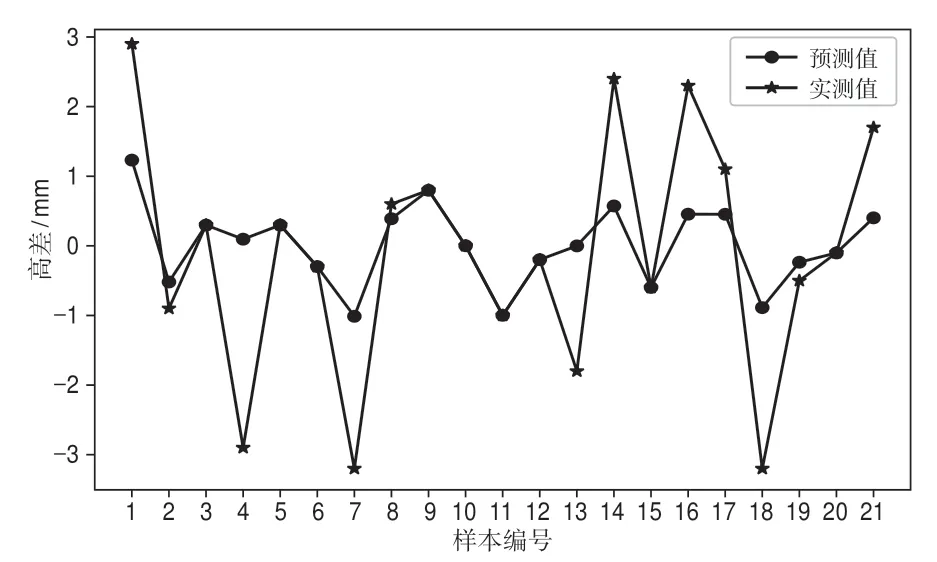
图3 训练样本预测结果对比
利用训练好的SVR模型对测试集样本进行预测,结果如图4所示。预测值与实测值的最小绝对误差为0.02 mm,最大绝对误差为1.22 mm,绝对误差平均值为0.38 mm,测试集的样本MSE为0.43 mm2。结果表明,基于GA-SVR的地铁隧道沉降预测具有一定的实用性,其精度能满足实际工程要求。
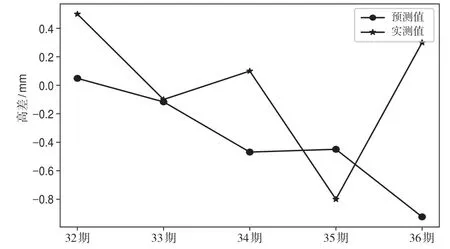
图4 测试样本预测结果对比
4 结 语
地铁隧道沉降受众多随机、不确定因素影响,监测数据存在非线性、复杂性等特点。基于结构风险最小化的SVR模型能很好地解决在拟合地铁隧道沉降数据时出现的随机性、非线性等问题;但SVR模型的拟合效果依赖于模型中3个参数。GA作为自适应全局搜索最优解的算法,在SVR模型的最佳参数组合方面表现出优异的搜索性能。本文从时间序列的角度对地铁隧道沉降进行了预测,构建的GA-SVR模型能对地铁隧道沉降变形进行较为准确的预测,其精度能满足工程实际要求。
猜你喜欢
课堂内外(小学版)(2023年4期)2023-09-22 09:35:18
中学生数理化·高一版(2021年2期)2021-03-19 08:32:00
科技创新与应用(2020年6期)2020-02-29 10:39:27
小读者(2019年24期)2019-01-10 23:00:37
知识经济·中国直销(2018年8期)2018-08-23 09:16:16
数学学习与研究(2017年3期)2017-03-09 18:12:42
小天使·四年级语数英综合(2016年11期)2016-11-29 14:46:09
北京理工大学学报(2016年6期)2016-11-22 11:17:22
电视技术(2016年9期)2016-10-17 09:13:41
系统工程与电子技术(2016年7期)2016-08-21 13:59:00
