
一种简单快速的人声语音自动提取方法
2021-03-26 03:29屈宏峰于津罗一平
电子元器件与信息技术 2021年11期
屈宏峰,于津,罗一平
(同方电子科技有限公司,江西 九江 332000)
0 引言
在数字化静噪控制应用领域,由于数字化增益控制影响下,在有用信号消失后,噪声信号被放大,从而极大地影响收听者的听感。所以目前的接收机电台多采用电平静噪的方式来清除噪声对听感的影响[1-2]。在电平静噪系统的控制下,可由操作者主动下发静噪参数,并根据静噪参数计算出一定的识别门限,来区分有用信号和无用的噪声信号,从而将噪声信号剔除,只对外播放有用信号,达到过滤噪声的效果[3]。本文针对数字化电台接收机中的人声语音信号,给出一种无需操作员设置参数即可达到自动滤除噪声信号的自动静噪算法。有计算量小,无需额外的硬件支持,较好的环境适应度,无人员技术要求,操作简单等优点。
1 人声语音信号的识别
1.1 人声语音的特征
人声语音:人声语音是指由人通过口腔声带震动所发出的声音,本质上是一种机械波。在一定的期间内,波长短则音调高,反之波长长则音调低。一般男性声音低,波长长,女性声音高,波长短。被称为语音音频,其体现在频率体系上有其独特的音频特征,和固定的频率范围。人声语音中话音中的大部分能量集在固定的音频区间,这和普通的噪声以及其他物理声音有明显的区别。
如图1所示:横坐标为时间轴,纵坐标为频率轴。仔细观察该频谱瀑布图可以看到在没有人声说话的时间段内。0-8K的频率范围内噪声的能量分布是基本平滑的,基本是从低频段向高频段缓慢下滑的过程,而有人声语音的时间段内,我们可以看到在2000Hz以内有大量的突出的黄色色块,这表示较高的能量凸起,表示在这个频段内有能量较高的机械波出现,也就是有人声话音的出现。
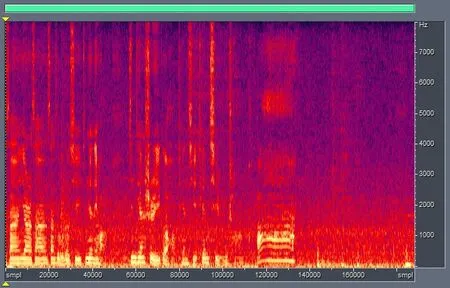
图1 一段人声的频谱瀑布能量显示图
从这个瀑布图中我们可以发现,人声语音在频谱的分布上绝大部分能量集中在300Hz~2000Hz的频谱范围内。这是一个非常明显的数据特征,在经过大量数据的对比之后我们确定。此数据图特征并非为孤例数据,而是真实反映出人声语音特点的统计结论。
1.2 利用能量分布规律判别语音
具有其独特的音频特征,其话音中的大部分能量集在固定的音频区间,这和普通的噪声有明显的区别,有这个特性,我们在区分噪声和人声语音的时候可以不采用复杂的识别算法,转而采用简单的特征识别方法,对输入的声音文件进行实时快速傅里叶变化,根据在固定区域内声音能量的占比,通过多次判定,就可以快速的得出信号是否为语音信号的判断[4-5]。
因此我们可以设计一个算法,通过对声音信号的数字化频谱的能量分布统计,来识别人声语音信号和其他噪声。具体的算法流程如图2所示。
如图2流程图所示:算法的起始为数字化的音频信号的输入,在实际程序中采用的输入音频的频率为16KHz。在获得了数字化的音频信号后,我们需要对输入的音频信号进行实时的快速傅里叶变化,这就用上了快速傅里叶变化函数。实际程序中采用64点的一帧的快速傅里叶变化,针对16KHz的音频进行频谱分析,即每次快速傅里叶变化的时间为:64/1600=4ms。整个识别程序建立在每4ms一次的傅里叶变化的频谱数据上。
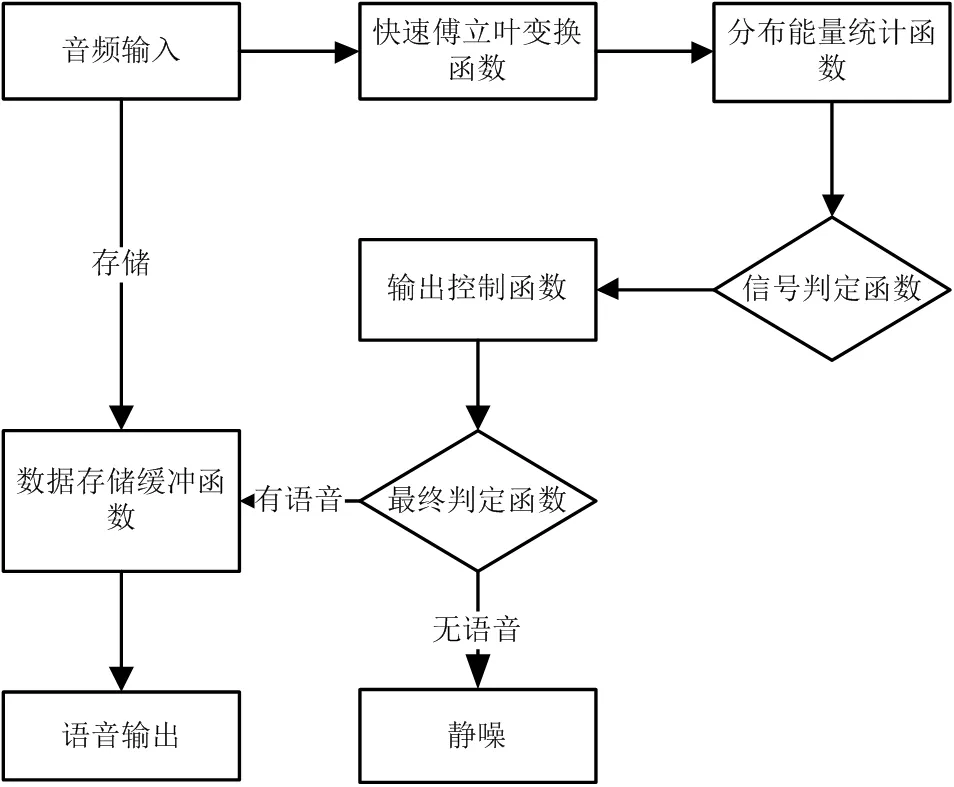
图2 算法流程图
在获得了傅里叶变化的频谱数据后,就需要用上分布能量统计函数对傅里叶变化后的频谱数据进行分布能量统计计算,将其结果送入信号判定函数进行判定和分辨。由于每帧傅里叶变化的频谱数据占时较短,误判的可能性较高,所以在这个函数中计算完成谱数据能量统计后,需要进行多次结果的缓冲平滑工作,用以减少误判,增加成功率[6]。
判定的结果送入输出控制函数,输出控制函数需要持续从信号判定函数获取判定数值,当持续一段时间判定值均为某个信号时,输出控制函数将通过最终判定函数控制语音信号的输出和关断。
由于判定结果需要多次判定才能最终得出结果,所以输入的人声语音持续的时间有一定的要求,不能低于200ms,即0.2秒时长。时间过短会被程序认定为突发噪声而略过。
1.3 算法的实际使用效果
此方式的算法可以兼顾识别的效率和速度,在快速傅里叶变化和缓冲平滑判断等算法都有成熟的计算库的情况下,编程极为简单,实际的调试的过程需要花费一定的时间,在针对地设置好各项参数后,通过输出控制函数的累积判定方式也可以最大限度地降低误判。
实际软件完成后,设置了各种长度的人声语音各100段的数据下进行测试,测试的数据包括在各种长度的人声语音情况下的提取成功率,以及提取的语音数据前后是否完整,提取的语音数据前后预留的缓冲噪声的时长是否稳定等等,测试结果的简表见表1所示。
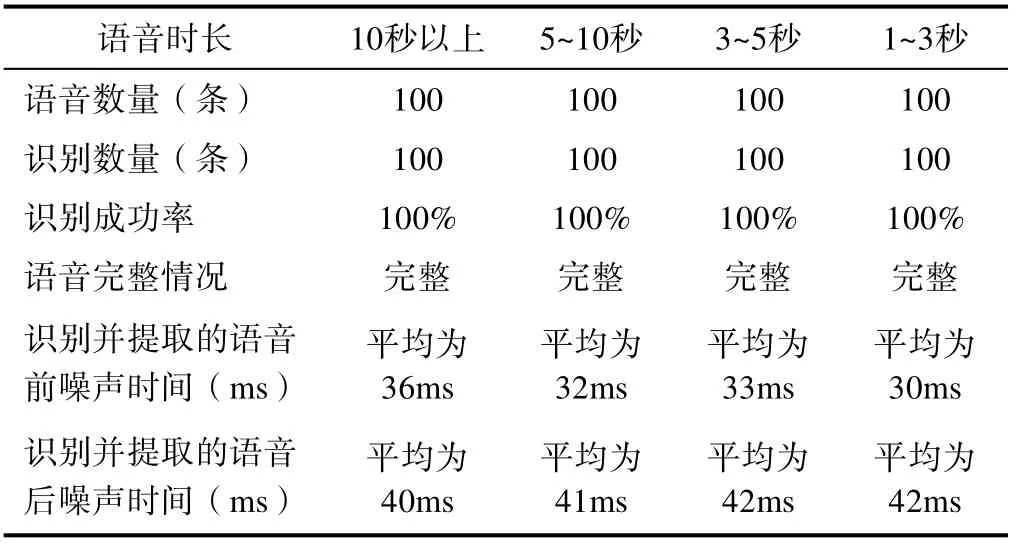
表1 语音识别效果表
此算法由于采用的是能量占比的特征识别,其并不需要人声语音信号有太高的信噪比,也不需要较高人声信号的清晰度,实际实验证明,在较低的信噪比和语音清晰度下,此算法仍然能准确地提取出语音部分的数据。图3上方为得低信噪比和低语音清晰度的语音在噪声环境的频谱瀑布图,图3下方为经过算法后中被提取出来的频谱瀑布图:
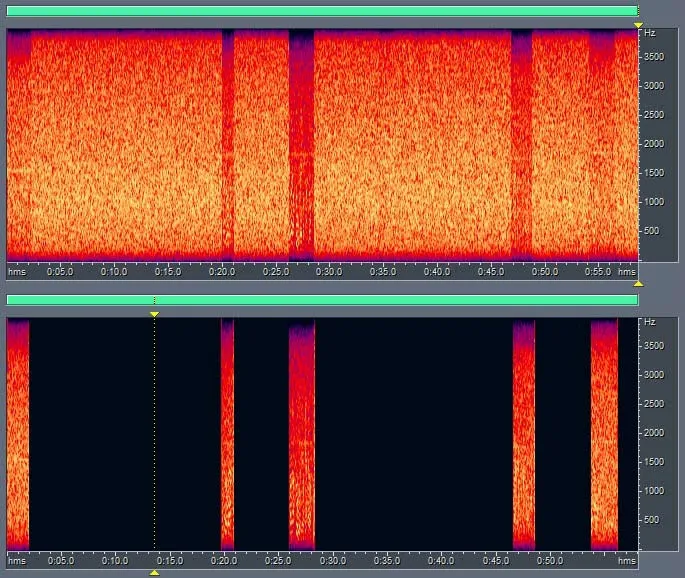
图3 低信噪比和低清晰度下的人声语音提取效果
通过各种长度的人声语音各100段的识别效果,和低信噪比和低语音清晰度情况下的识别效果,可以看出是此算法对人声语音的识别成功率极高,识别出的人声语音的前置缓冲保持时间和后置缓冲保持时间比较稳定,适合作为提取音频素材。
2 结论
本文通过对人声语音信号的识别实现了数字化人声语音的提取算法,能有效的提高监听人员的听感,降低长时间噪声对监听人员的听力损坏,能有效的提高监听的语音识别度,对于各种需要在长时间的监控数据中提取人声语音的场合来说具有相当的便捷,从实验测试结果来看,所设计的提取算法,灵敏度高,成功率高,表明用该方法提取数字人声语音是可行的。算法具有简单、计算量小的优点 ,便于程序的实现 。所使用的算法不需要额外的特征库和支持库,可以简单便捷地嵌入到各种应用程序中。
猜你喜欢
河北画报(2020年10期)2020-11-26
数学物理学报(2019年2期)2019-05-10
家庭影院技术(2018年11期)2019-01-21
测控技术(2018年7期)2018-12-09
电子制作(2018年19期)2018-11-14
民主(2017年3期)2017-05-12
电子制作(2017年9期)2017-04-17
舰船科学技术(2016年1期)2016-02-27
人间(2015年8期)2016-01-09
电测与仪表(2015年5期)2015-04-09
